先附上代码
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
#获取数据
iris = load_iris()
X = iris.data
# 数据可视化
# 散点图,plt.scatter(x(横轴数据),y(纵轴数据),c="颜色"
marker="点的形状"
labal="点的标签"
plt.scatter(X[:, 0], X[:, 1], c="black", marker='o',
label='see')
##设置 x,y 轴的名字
plt.xlabel('petal length')
plt.ylabel('petal width')
##设置图的名字
plt.title("Data")
##显示图像
plt.show()
#这里我们分成了3类
kmeans=KMeans(n_clusters=3)
kmeans.fit(X)
y_kmeans=kmeans.predict(X)
#可视化聚类后的结果
x0 = X[y_kmeans == 0]
x1 = X[y_kmeans == 1]
x2 = X[y_kmeans == 2]
plt.scatter(x0[:, 0], x0[:, 1], c="red", marker='o',
label='label0')
plt.scatter(x1[:, 0], x1[:, 1], c="green", marker='o',
label='label1')
plt.scatter(x2[:, 0], x2[:, 1], c="blue", marker='o',
label='label2')
plt.title("clustr before PCA")
plt.xlabel('petal length')
plt.ylabel('petal width')
plt.legend(loc=2)
plt.show()
y = iris.target
target_names = iris.target_names
#这里我们使用PCA降为2维
pca=PCA(n_components=2)
X_r=pca.fit_transform(X)
var=pca.explained_variance_ratio_
_cumvar=np.cumsum(var)#记得导入numpy
print("降维后方差分布为:{}".format(_cumvar))
plt.figure()
colors = ["navy", "turquoise", "darkorange"] # 绘图颜色
# 分别绘制降维后的 3 类 iris
for color, i, target_name in zip(colors, [0, 1, 2],
target_names):
plt.scatter(
X_r[y == i, 0], X_r[y == i, 1], color=color,
alpha=0.8, lw=2, label=target_name
)
plt.title("PCA of IRIS dataset")
plt.show()
#使用降维后的数据进行聚类
pca_kmeans=KMeans(n_clusters=3)
pca_kmeans.fit(X_r)
y_pca_kmeans=pca_kmeans.predict(X_r)
x0_pca = X_r[y_pca_kmeans == 0]
x1_pca = X_r[y_pca_kmeans == 1]
x2_pca = X_r[y_pca_kmeans == 2]
plt.figure()
plt.scatter(x0_pca[:, 0], x0_pca[:, 1], c="red", marker='o',
label='label0')
plt.scatter(x1_pca[:, 0], x1_pca[:, 1], c="green", marker='o',
label='label1')
plt.scatter(x2_pca[:, 0], x2_pca[:, 1], c="blue", marker='o',
label='label2')
plt.title("clustr after PCA")
plt.legend(loc=2)
plt.show()
初始数据如图
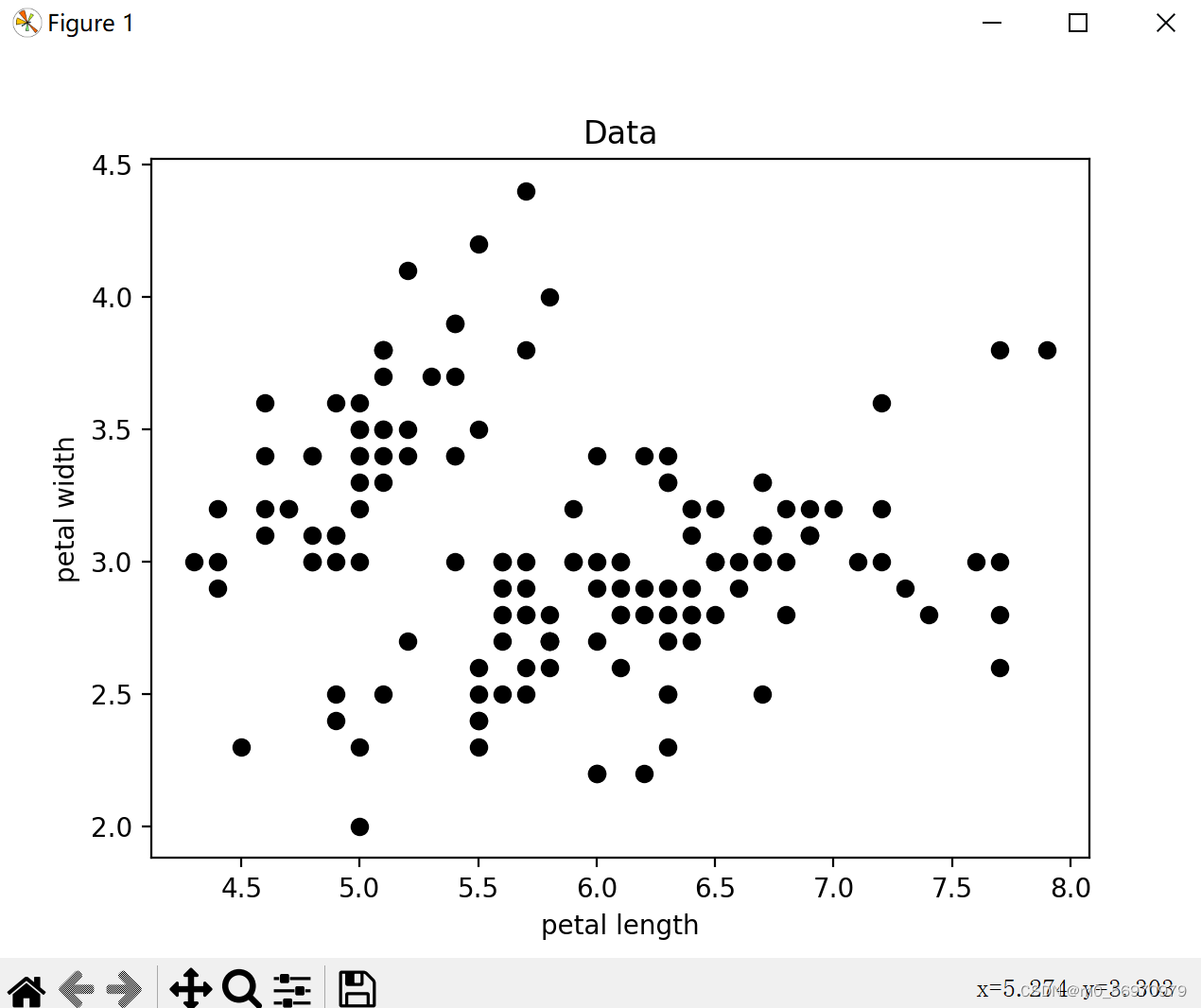
PCA处理前的数据
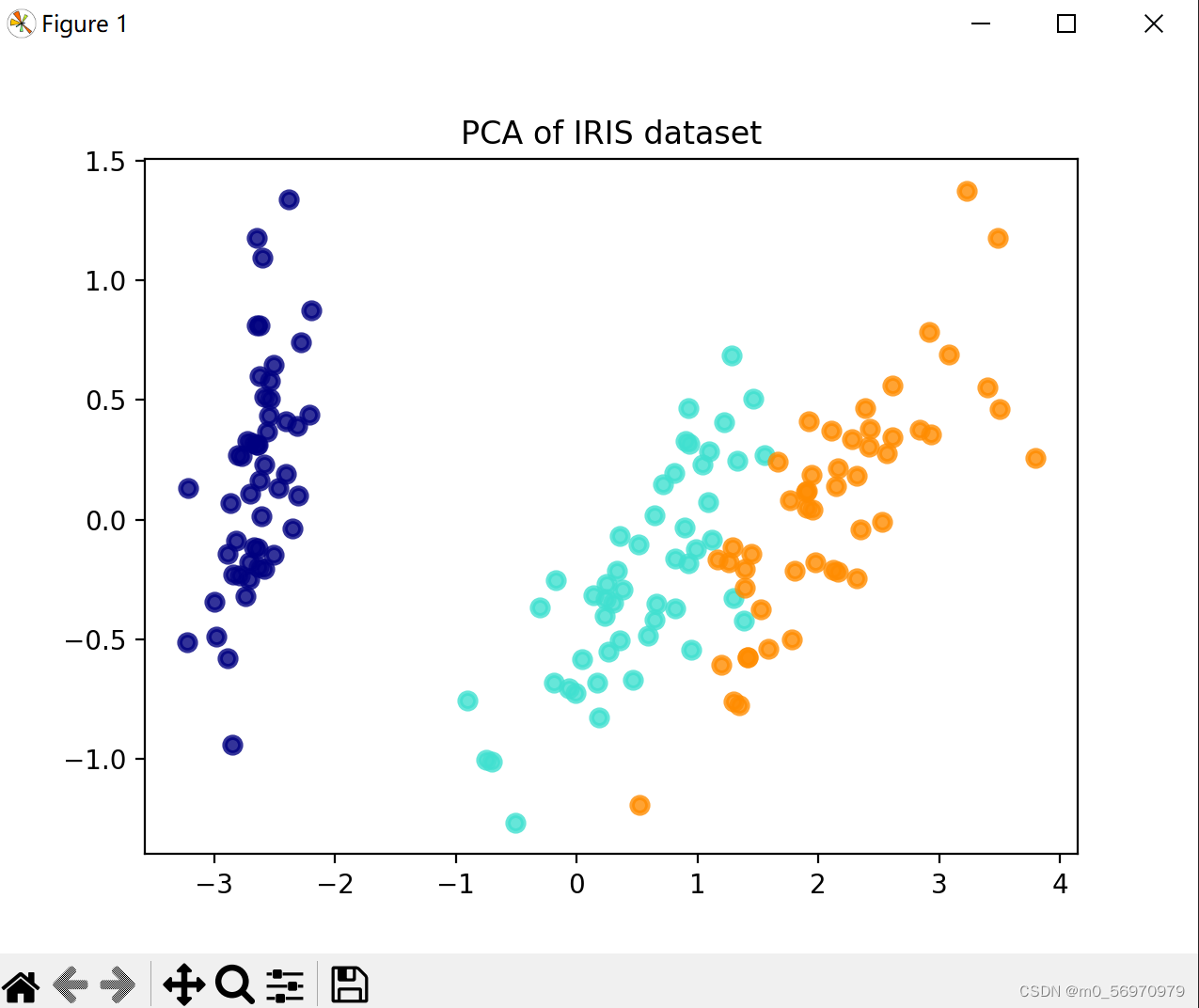
PCA处理后的数据
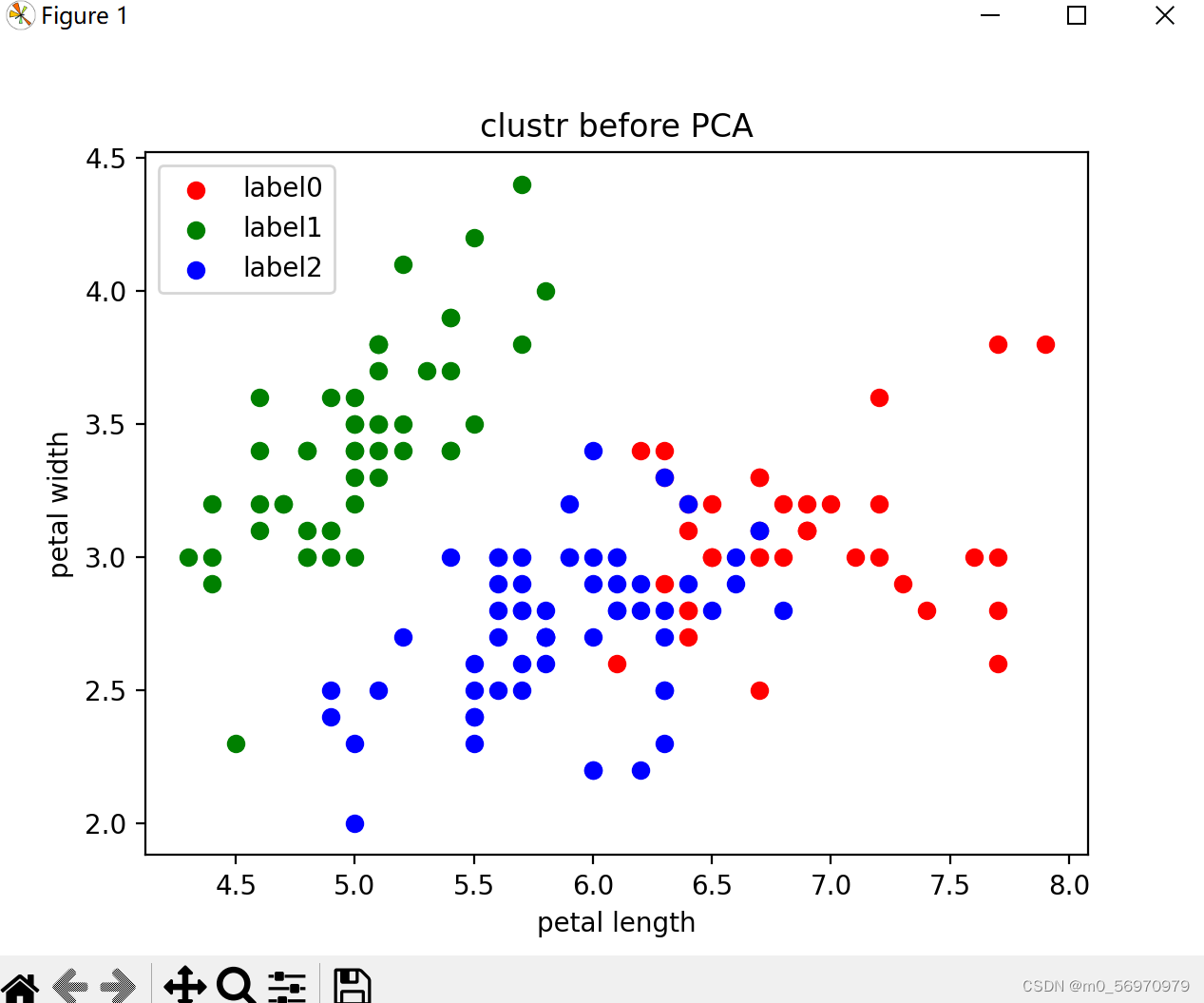
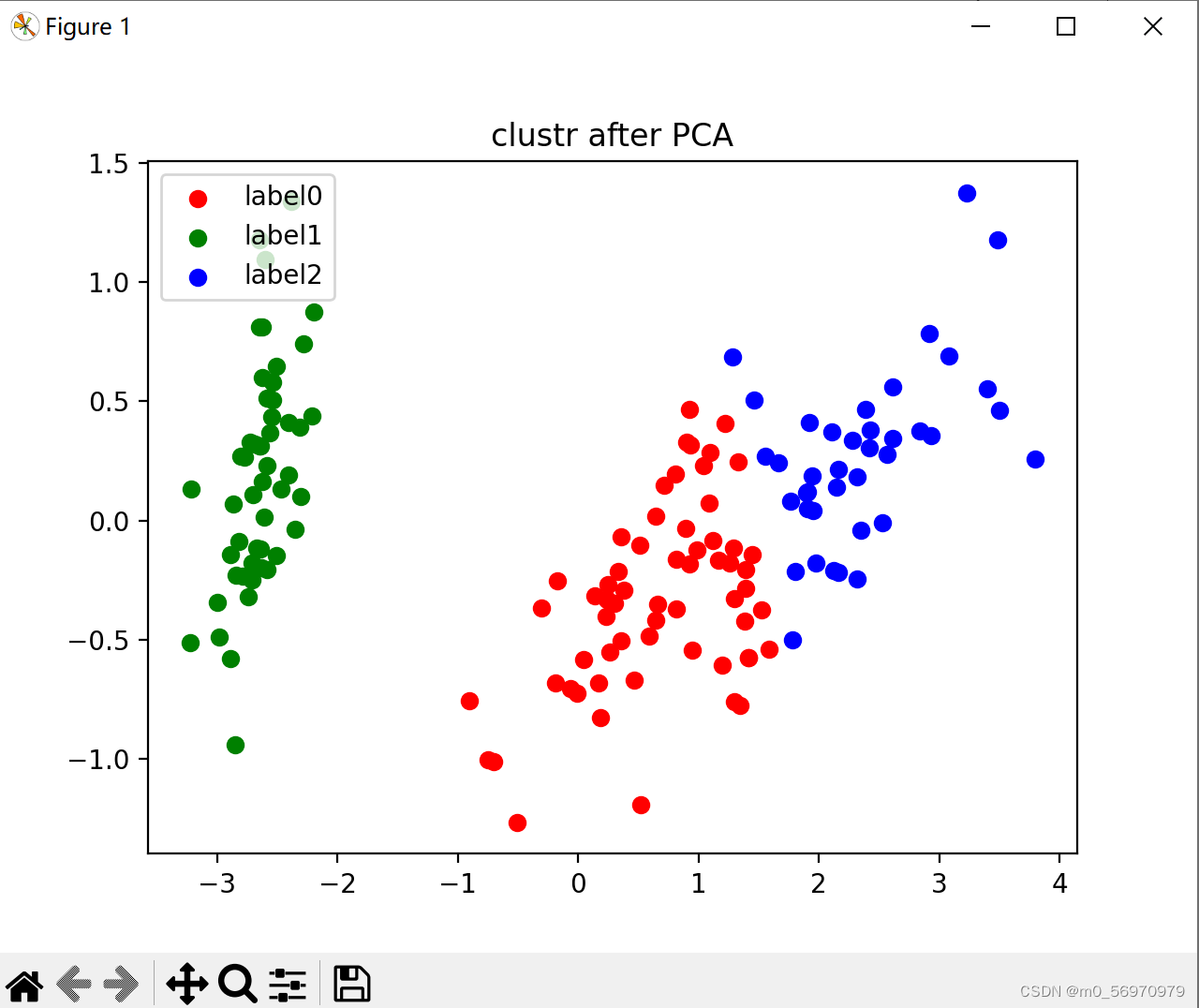
聚类效果如图







 本文介绍了如何使用Python中的Matplotlib、Numpy和Scikit-learn库对Iris数据集进行可视化,并通过KMeans算法进行聚类,然后应用PCA进行降维,展示了聚类效果在原始数据和降维后的变化。
本文介绍了如何使用Python中的Matplotlib、Numpy和Scikit-learn库对Iris数据集进行可视化,并通过KMeans算法进行聚类,然后应用PCA进行降维,展示了聚类效果在原始数据和降维后的变化。















 4419
4419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









