







一、排序定义及算法概述
二、排序算法
1、冒泡排序(Bubble Sort,稳定)
2、选择排序(SelectSort,不稳定)
3、插入排序(Insertion Sort,稳定)
4、希尔排序(Shell Sort,不稳定)
5、归并排序(Merge Sort,稳定)
6、快速排序(Quick Sort,不稳定)
7、堆排序(Heap Sort,不稳定)
8、计数排序(Counting Sort,稳定)
9、桶排序(Bucket Sort,稳定)
10、基数排序(Radix Sort,稳定)
一、排序定义及算法概述

排序:通过重新排列表中的元素,使表中的元素满足按关键字有序的过程。为了查找方便,通常希望计算机中的表是按关键字有序的。
比较类排序:通过比较来决定元素间的相对次序。
非比较类排序:不通过比较来决定元素间的相对次序,可以线性时间运行。
算法的稳定性:若待排序表中有两个元素R和R,若使用某一排序算法排序后, R仍然在R的前面,则称这个排序算法是稳定的,否则称排序算法是不稳定的。算法是否具有稳定性并不能衡量一个算法的优劣,它主要是对算法的性质进行描述。如果待排序表中的关键字不允许重复,则排序结果是唯一的,那么选择排序算法时的稳定与否就无关紧要。’
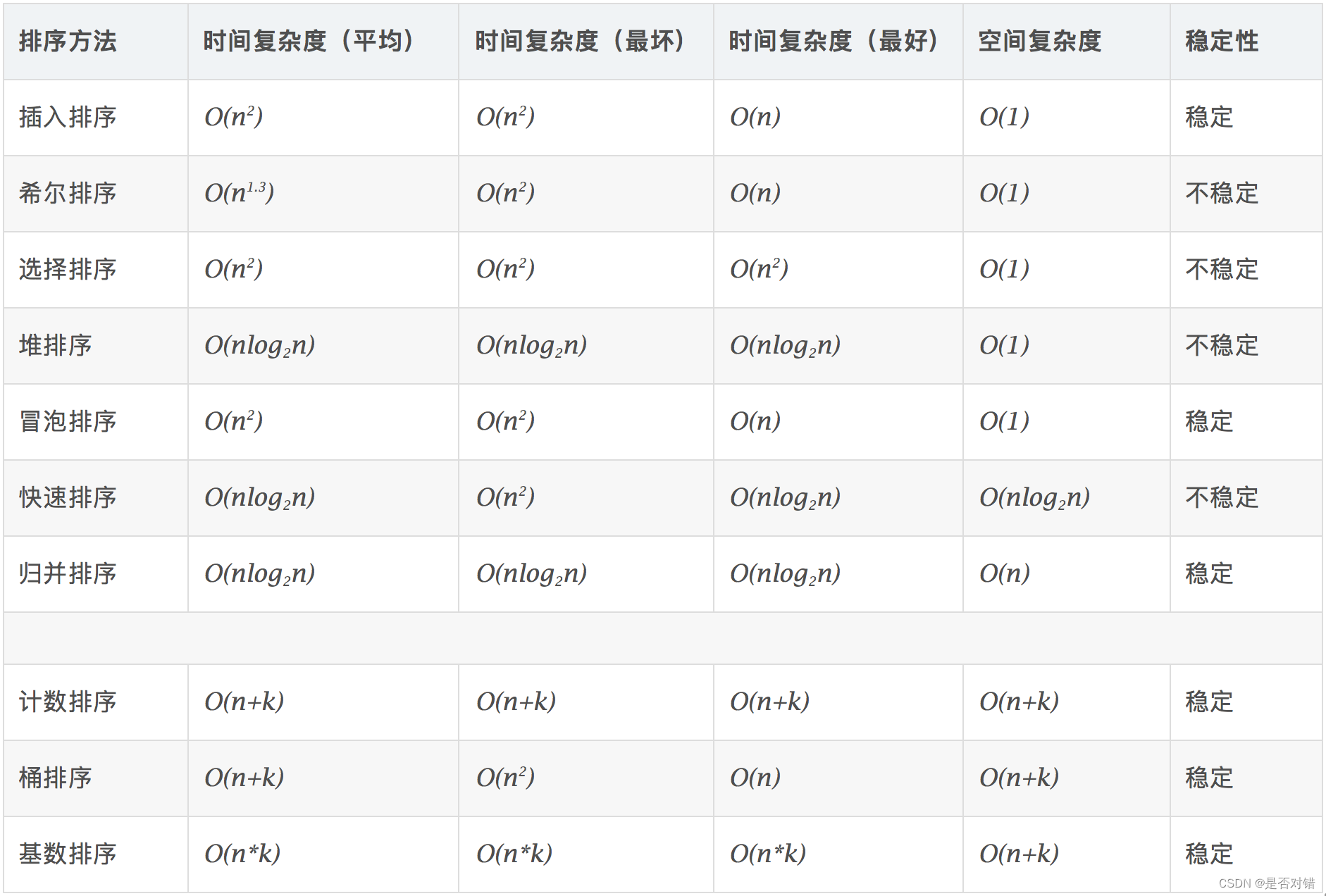
时间复杂度:是指算法中基本操作的执行次数。反映当n变化时,操作次数呈现什么规律。
空间复杂度:是指算法在计算机内执行时所需存储空间的度量,它也是数据规模n的函数。
算法复杂度
二、排序算法
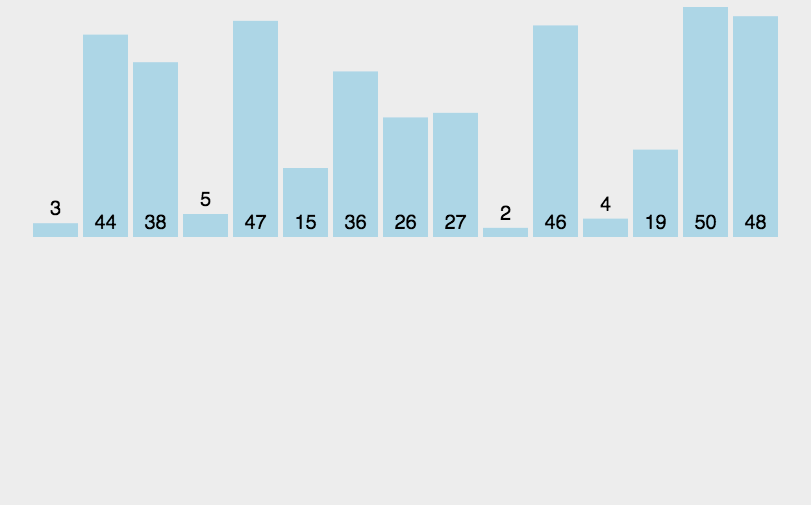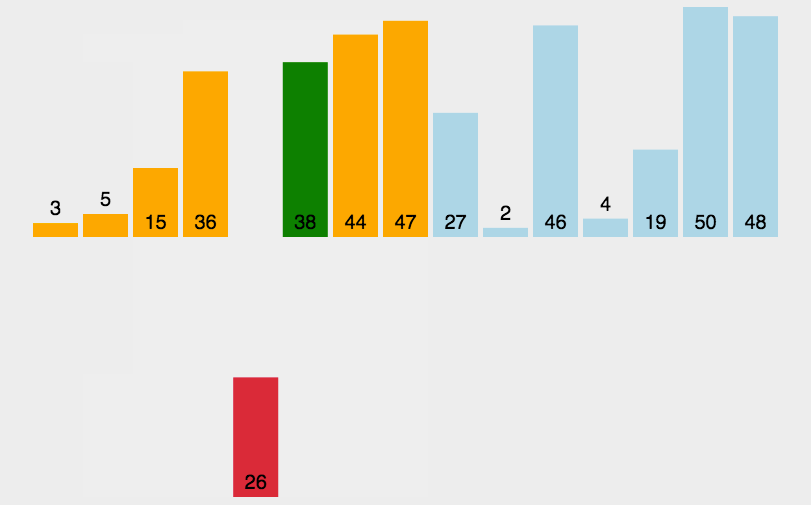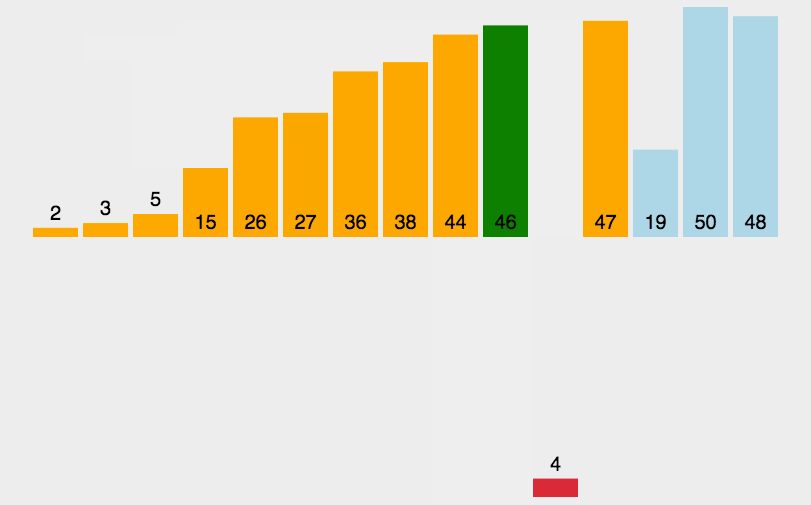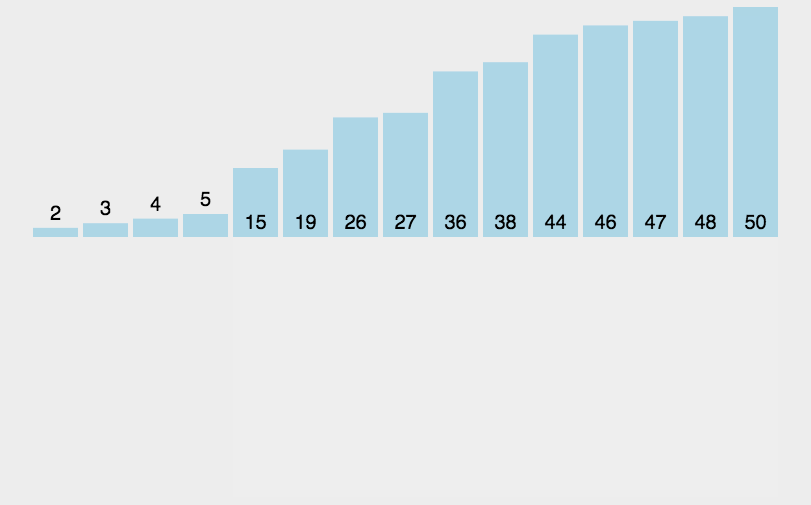
1、直接插入排序(InsertSort,稳定)
插入排序是一种简单直观的排序方法,其基本思想是每次将一个待排序的记录按其关键字大
小插入前面已排好序的子序列,直到全部记录插入完成。
算法描述:
1.将第一个数当作有序序列,后面的数字当作无序序列;
2.从第二个数开始往前面依次比较,如果该数大于新数则将该数移到新数的下一个位置,小于则向前寻找,直到找到比该数小于或者等于的新元素的后面位置并插入;
3.将排列好的序列认定为有序序列,重复上述操作
算法优化:折半插入排序,①从前面的有序子表中查找出待插入元素应该被插入的位置;②给插入位置腾出空间,将待插入元素复制到表中的插入位置
动图演示
代码实现
void InsertSort(ElemType A[],int n)
{
int i,j;
for(i=2;i<=n;i++) //依次将A[2]~A[n]插入前面已排序序列
{
if(A[i]<A[i-1]) { //若A[i]关键码小于其前驱,将A[i]插入有序表
A[0]=A[i] ; //复制为哨兵,A[0]不存放元素
for(j=i-1;A[0]<A[j];--j) //从后往前查找待插入位置
A[j+1]=A[j]; //向后挪位
A[j+1]=A[0]; //复制到插入位置
}
}
}
void InsertSort(ElemType A[],int n){ //优化:折半插入
int i,j,low,high,mid;
for(i=2;i<=n;i++){ //依次将A[2]~A[n]插入前面的已排序序列
A[0]=A[i]; //将A[i]暂存到A[0]
low=1;high=i-1; //设置折半查找的范围
while(low<=high){ //折半查找(默认递增有序)
mid= (low+high)/2; //取中间点
if (A[mid]>A[0]) high=mid-1; //查找左半子表
else low=mid+1; //查找右半子表
}
for(j=i-1;j>=high+1;--j)
A[j+1]=A[j]; //统一后移元素,空出插入位置
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 514
514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









