







现代操作系统 第六章 死锁
本文为读书摘要(个人认为重要的知识点),穿插课后习题的选取(主要选取考察概念性的习题)
资源
为了尽可能使关于死锁的讨论通用,**我们把这类需要排他性使用的对象称为资源(resource)。**资源可以是硬件设备(如蓝光驱动器)或是ー组信息(如数据库中一个加锁的记录)。通常在计算机中有多种(可获取的)资源。ー些类型的资源会有若干个相同的实例,如三台蓝光驱动器。当某ー资源有若干实例时,其中任何ー个都可以用来满足对资源的请求。简单来说,资源就是随着时间的推移,必须能获得、使用以及释放的任何东西。
-
资源分为两类:可抢占的和不可抢占的。
-
可抢占资源(preemptable resource)可以从拥有它的进程中抢占而不会产生任何副作用,存储器就是ー类可抢占的资源。
有两个256MB内存的进程都想进行打印,由于进程A拥有打印机,而进程B占有了内存,两个进程都缺少另外一个进程拥有的资源,所以任何ー个都不能继续执行。 不过,幸运的是通过把进程B换出内存、把进程A换入内存就可以实现抢占进程B的内存。
-
不可抢占资源(nonpreemptable resource)是指在不引起相关的计算失败的情况下,无法把它从占有它的进程处抢占过来。
如果一个进程已开始刻盘,突然将蓝光光盘刻录机分配给另ー个进程, 那么将划坏蓝光光盘。在任何时刻蓝光光盘刻录机都是不可抢占的。
-
资源获取
- 对于数据库系统中的记录这类资源,应该由用户进程来管理其使用。 ー种允许用户管理资源的可能方法是为**每ー个资源配置ー个信号量。这些信号量都被初始化为1。 互斥信号量也能起到相同的作用。**上述的三个步骤可以实现为信号量的 down 操作来获取资源,使用资源,最后使用 up 操作来释放资源。
死锁
死锁的规范定义如下:如果ー个进程集合中的每个进程都在等待只能由该进程集合中的其他进程オ能引发的事件,那么,该进程集合就是死锁的。
- 在大多数情况下,每个进程所等待的事件是释放进程集合中其他进程所占有的资源。换言之,这ー死锁进程集合中的每ー个进程都在等待另ー个死锁的进程已经占有的资源。这种死锁称为资源死锁(resource deadlock),这是最常见的类型。
资源死锁的条件
1)互斥条件。每个资源要么已经分配给了一个进程,要么就是可用的。
2)占有和等待条件。已经得到了某个资源的进程可以再请求新的资源。
3)不可抢占条件。已经分配给ー个进程的资源不能强制性地被抢占,它只能被占有它的进程显式地释放。
4)环路等待条件。死锁发生时,系统中一定有由两个或两个以上的进程组成的一条环路,该环路中的每个进程都在等待着下ー个进程所占有的资源。
死锁建模
在图6-3a中,当前资源R正被进程A占用。
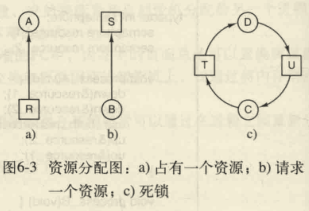
总而言之,有四种处理死锁的策略:
1)忽略该问题(鸵鸟算法)。也许如果你忽略它,它也会忽略你。
2)检测死锁并恢复。让死锁发生,检测它们是否发生,一旦发生死锁,采取行动解决问题。
3)仔细对资源进行分配,动态地避免死锁。
4)通过破坏引起死锁的四个必要条件之一,防止死锁的产生。
死锁检测和死锁恢复
第二种技术是死锁检测和恢复。在使用这种技术时,系统并不试图阻止死锁的产生,而是允许死锁发生,当检测到死锁发生后,采取措施进行恢复。
- 每种类型ー个资源的死锁检测 —— 拓扑排序问题

- 每种类型多个资源的死锁检测 —— 基于向量的比较

问题在于何时去检测它们。
- ー种方法是每当有资源请求时去检测, 毫无疑问越早发现越好,但这种方法会占用昂贵的CPU时间。
- 另ー种方法是每隔 k 分钟检测ー次,或者当CPU的使用率降到某ー域值时去检测。考虑到 CPU 使用效率的原因,如果死锁进程数达到ー定数量,就没有多少进程可运行了,所以CPU会经常空闲。
-
从死锁中恢复
-
利用抢占恢复
**在不通知原进程的情况下,将某ー资源从一个进程强行取走给另ー个进程使用,接着又送回,**这种做法是否可行主要取决于该资源本身的特性。用这种方法恢复通常比较困难或者说不太可能。若选择挂起某个进程,则在很大程度上取决于哪ー个进程拥有比较容易收回的资源。
-
利用回滚恢复
周期性地对进程进行检查点检查(checkpointed)o进程检査点检査就是将进程的状态写入一个文件以备以后重启。
一旦检测到死锁,就很容易发现需要哪些资源。为了进行恢复,要从ー个较早的检查点上开始,这样拥有所需要资源的进程会回滚到ー个时间点,在此时间点之前该进程获得了一些其他的资源。
-
通过杀死进程恢复
ー种方法是杀掉环中的ー个进程。如果走运的话,其他进程将可以继续。如果这样做行不通的话,就需要继续杀死别的进程直到打破死锁环。
另ー种方法是选ー个环外的进程作为牺牲品以释放该进程的资源。在使用这种方法时,选择ー个要被杀死的进程要特别小心,它应该正好持有环中某些进程所需的资源。
有可能的话,最好杀死可以从头开始重新运行而且不会帯来副作用的进程。
-
死锁避免
问题是:是否存在ー种算法总能做出正确的选择从而避免死锁?答案是肯定的,但条件是必须事先获得一些特定的信息。
安全状态和不安全状态
-
如果没有死锁发生,并且即使所有进程突然请求对资源的最大需求,也仍然存在某种调度次序能够使得毎ー个进程运行完毕,则称该状态是安全的。
-
值得注意的是,不安全状态并不是死锁。从图6∙10b出发,系统能运行一段时间。实际上,甚至有ー个进程能够完成。
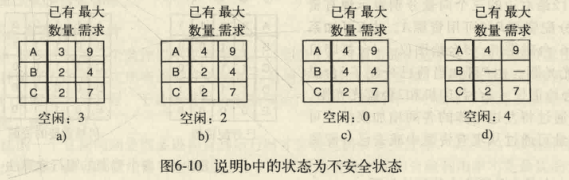
如果没有死锁发生,并且即使所有进程突然请求对资源的最大需求,也仍然存在某种调度次序能够使得毎ー个进程运行完毕,则称该状态是安全的。
因而,安全状态和不安全状态的区别是:**从安全状态出发,系统能够保证所有进程都能完成,**而从不安全状态出发,就没有这样的保证。
单个资源的银行家算法
- 银行家算法就是对每ー个请求进行检査,检查如果满足这ー请求是否会达到安全状态。若是,那么就满足该请求:否则,就推迟对这ー请求的满足。为了检査状态是否安全,银行家需要考虑他是否有足够的资源满足某ー个客户。如果可以,那么这笔贷款就是能够收回的,并且接着检査最接近最大限额的ー个客户,以此类推。如果所有投资最终都能被收回,那么该状态是安全的,最初的请求可以批准。
多个资源的银行家算法

图6-12最右边的三个向量分别表示现有资源E、已分配资源P和可用资源A
检査ー个状态是否安全的算法如下:
1)査找右边矩阵中是否有一行,其没有被满足的资源数均小于或等于A 如果不存在这样的行,那么系统将会死锁,因为任何进程都无法运行结束(假定进程会一直占有资源直到它们终止为止)。
2)假若找到这样一行,那么可以假设它获得所需的资源并运行结束,将该进程标记为终止,并将其资源加到向量A上。
3)重复以上两步,或者直到所有的进程都标记为终止,其初始状态是安全的,或者所有进程的资源需求都得不到满足,此时就是发生了死锁。
银行家算法最早由Dykstra于1965年发表。但很少有作者指出该算法虽然很有意义但缺乏实用价值,因为很少有进程能够在运行前就知道其所需资源的最大值。而且进程数也不是固定的,往往在不断地变化(如新用户的登录或退出),况且原本可用的资源也可能突然间变成不可用(如磁带机可能会坏掉)。
死锁预防
如果能够保证四个条件中至少有一个不成立,那么死锁将不会产生。
-
破坏互斥条件
-
避免分配那些不是绝对必需的资源,尽量做到尽可能少的进程可以真正请求资源。
-
破坏占有并等待条件
-
**ー种实现方法是规定所有进程在开始执行前请求所需的全部资源。如果所需的全部资源可用, 那么就将它们分配给这个进程,于是该进程肯定能够运行结束。**如果有一个或多个资源正被使用,那么就不进行分配,进程等待。
(类似使用银行家算法 进行 死锁避免前 需要知道所有进程获取的资源数) -
另一种破坏占有并等待条件的略有不同的方案是,要求当一个进程请求资源时,先暂时释放其当前占用的所有资源,然后再尝成一次获得所需的全部资源。
-
破坏不可抢占条件
-
破坏第三个条件(不可抢占)也是可能的,假若一个进程已分配到ー台打印机,且正在进行打印输出,如果由于它需要的绘图仪无法获得而强制性地把占有它的打印机抢占掉(打印机需要绘图仪),会引起一片混乱。但是,ー些资源可以通过虚拟化的方式来避免发生这样的情况。假脱机打印机向磁盘输出,并且只允许打印机守护进程访问真正的物理打印机,这种方式可以消除涉及打印机的死锁,然而却可能带来由磁盘空间导致的死锁。但是对于大容量磁盘,要消耗完所有的磁盘空间一般是不可能的。
-
破坏环路等待条件
-
ー种是保证每ー个进程在任何时刻只能占用ー个资源,如果要请求另外一个资源,它必须先释放第一个资源。
-
另ー种避免出现环路等待的方法是将所有资源统ー编号, 进程可以在任何时刻提出资源请求,但是所有请求必须按照资源编号的顺序(升序)提出。
该算法的ー个变种是取消必须按升序请求资源的限制,而仅仅要求不允许进程请求比当前所占有资源编号低的资源。

其他问题
两阶段加锁
两阶段加锁(two-phase locking)。
-
在第一阶段, 进程试图对所有所需的记录进行加锁, 一次锁ー个记录。
-
如果第一阶段加锁成功,就开始第二阶段,完成更新然后释放锁。在第一阶段并没有做实际的工作。
-
如果在第一阶段某个进程需要的记录已经被加锁,那么该进程释放它所有加锁的记录,然后重新开始第一阶段。
从某种意义上说,这种方法类似于提前或者至少是未实施ー些不可逆的操作之前请求所有资源。
在两阶段加锁的ー些版本中,如果在第一阶段遇到了已加锁的记录,并不会释放锁然后重新开始, 这就可能产生死锁。
不过,在一般意义下,这种策略并不通用。例如,在实时系统和进程控制系统中,由于ー个进程缺少ー个可用资源就半途中断它,并重新开始该进程,这是不可接受的。
只有当程序员仔细地安排了程序,使得在第一阶段程序可以在任意一点停下来,并重新开始而不会产生错误,这时这个算法オ可行。但很多应用并不能按这种方式来设计。
通信死锁
但是,根据标准的定义,在ー系列进程中,每个进程因为等待另外一个进程引发的事件而产生阻塞,这就是ー种死锁。相比于更加常见的资源死锁,我们把上面**这种情况(因消息丢失而互相等待消息)叫作通信死锁(communication deadlock)。**通信死锁是协同同步的异常情况,处于这种死锁中的进程如果是各自独立执行的,则无法完成服务。
一种技术通常可以用来中断通信死锁:超时。
在大多数网络通信系统中,只要一个信息被发送至一个特定的地方,并等待其返回一个预期的回复,发送者就同时启动计时器。若计时器在回复到达前计时就停止了,则信息的发送者可以认定信息已经丢失,并重新发送(如果需要,则ー直重复)。通过这种方式,可以避免死锁。换种说法就是,超时策略作为ー种启发式方法可探测死锁并使进程恢复正常。这种方式也适用于资源死锁。
活锁 (活动的”死锁“)
**某些情况下,当进程意识到它不能获取 所需要的下ー个锁时,就会尝试礼貌地释放已经获得的锁,然后等待1ms,再尝试一次。**从理论上来说,这是用来检测并预防死锁的好方法。但是,如果另ー个进程在相同的时刻做了相同的操作,那么就像两个人在一条路上相遇并同时给对方让路ー样, 相同的步调将导致双方都无法前进。
很明显,这个过程中没有进程阻塞,甚至可以说进程正在活动,所以这不是死锁。然而,进程并不会继续往下执行,可以称之为活锁(livelock)。 (不停的尝试获取资源、释放已有的资源 而 无法向下进展)
活锁和死锁也经常出人意料地产生。在ー些系统中,进程表中容纳的进程数决定了系统允许的最大进程数量,因此进程表属于有限的资源。如果由于逬程表满了而导致一次fork运行失败,那么ー个合理的方法是:该程序等待一段随机长的时间,然后再次尝试运行fork。
现在假设ー个UNIX系统有100个进程槽,10个程序正在运行,每个程序需要创建12个(子)进程。**在每个进程创建了 9个进程后,10个源进程和90个新的进程就已经占满了进程表。10个源进程此时便进入了死锁——不停地进行分支循环和运行失败。**发生这种情况的可能性是极小的,但是,这是可能发生的!我们是否应该放弃进程以及fork调用来消除这个问题呢?
大多数的操作系统(包括UNIX和Windows)都忽略了一个问题,即比起限制所有用户去使用ー个进程、一个打开的文件或任意ー种资源来说,大多数用户可能更愿意选择一次偶然的活锁(或者甚至是死锁)(释放已有的资源)。如果这些问题能够免费消除,那就不会有争论。
但问题是代价非常高,因而几乎都是给进程加上不便的限制来处理。因此我们面对的问题是从便捷性和正确性中做出取舍,以及一系列关于哪个更重要、对谁更重要的争论。
饥饿
一些策略可能使一些进程永远得不到服务,虽然它们并不是死锁进程。
例如短作业优先可能导致长作业永远得不到执行。
习题
- ー个资源死锁的发生有四个必要条件(互斥使用资源、占有和等待资源、不可抢占资源和环路等待资源)。举ー个例子说明它们对于ー个资源死锁的发生不是充分条件。何时这些条件对ー个资源死锁的发生是充分条件?
不是充分条件
假设有 A、B、C 三个进程,以及 R 和 S 两种资源类型。进一步假设 R 有 1 个实例,S 有 2 个实例。
考虑以下执行场景: A 请求 R 并获取它; B 请求 S 并得到; C 请求 S 并得到它(有两个 S 实例); B 请求 R 并被阻塞; A 请求 S 并被阻止。 在这个阶段,所有四个条件都成立。 但是,没有死锁。 当 C 完成时,S 的一个实例被重新租用,分配给 A。现在 A 可以完成其执行并释放可以分配给 B 的 R,然后 B 可以完成其执行。 如果每种类型都有一个资源,这四个条件就足够了。















 6135
6135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









