







在当今数字艺术与图像处理的领域,风格迁移技术正引领着创新的潮流,尤其是自适应实例归一化(AdaIN)算法的提出,使得实时任意风格迁移变得更加可行和高效,本文将深入探讨 AdaIN 的原理、应用及其在实时风格迁移中的优势,揭示这一技术如何为创作者提供无限可能。
本文所涉及所有资源均在地址可获取
概述
与传统的风格迁移方法相比,AdaIN 不仅能够实现更灵活的风格融合,还能在保持图像内容的同时,赋予其独特的艺术风格,Gatys et al. 通过对卷积神经网络卷积核输出的特征图即feature map的二阶统计(Gram matrix)来描述一张图片的风格,虽然生成的视觉效果很好,但这种方法需要经历一个非常慢的迭代优化过程。
为克服这种缺点,后续方向使用前馈生成卷积网络来代替优化过程,即将图片输入网络直接快速生成Gatys et al.类似的结果,但缺点是模型一般绑定一种或多种固定风格不能适应任意风格,IN特征统计携带图片风格信息,对IN进行简单扩展,即调整内容图片feature map的均值和方差匹配风格图片feature map的均值和方差,可以实现实时任意⻛格迁移的效果,如下图所示:

从这篇 论文 当中我们也可以看到对图像迁移所使用的相关定义及推导过程:

代码逻辑
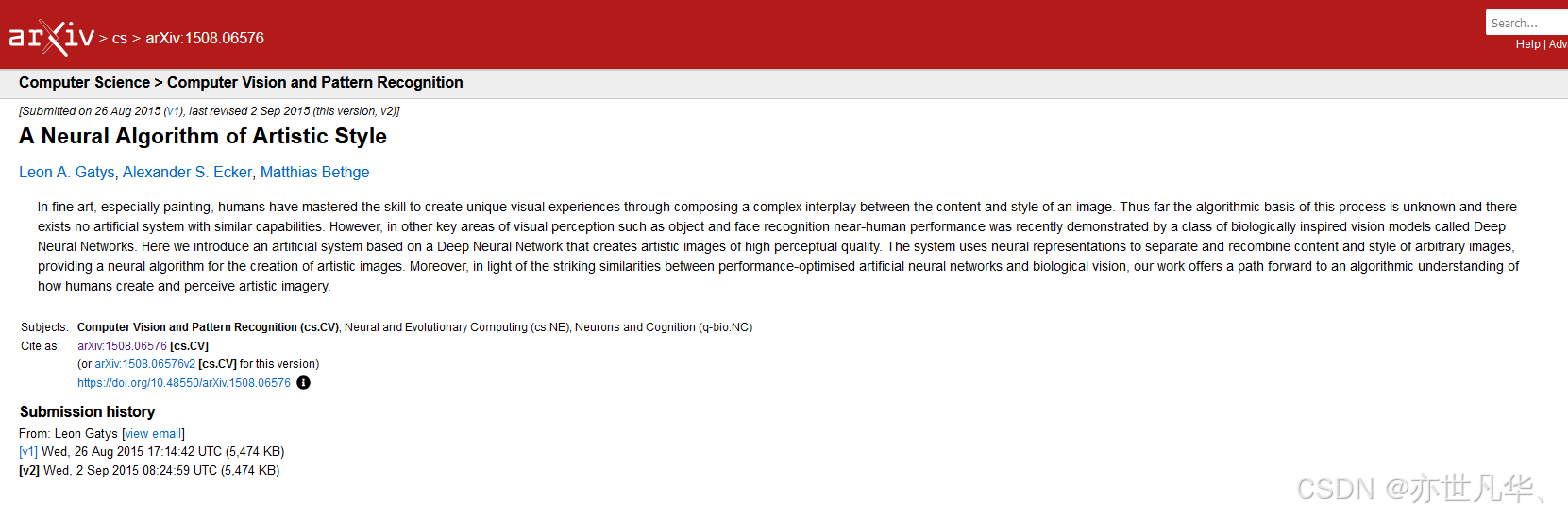
AdaIN在特征空间通过传递特征统计即每个通道的均值和方差来进行风格迁移。具体地,输入内容x和风格y的feature map,并简单地对齐x每个通道的均值和⽅差以匹配y的均值和⽅差,其对应的公式如下所示:
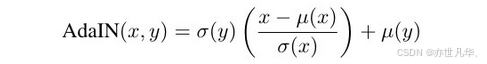
从下图的网络架构图我们可以知道整个网络架构T采用编码器-解码器架构,由编码器f,AdaIN层,解码器g组成:
编码器f:固定在预训练的VGG-19的前⼏层,训练时不更新该部分网络参数。输入内容图片c和风格图片s,经由编码器得到f(c)和f(s)即特征空间的feature map。
AdaIN层:该层将f的输出f(c)和f(s)进行均值和方差的对齐。得到结果t = AdaIN(f(c), f(s))。
解码器g: 在训练中主要更新参数的部分,随机初始化g的参数,将特征空间的值映射回图像空间得到最终风格迁移的结果图即T(c, s) = g(t)。
损失值:由公式 L = Lc + λLs 组成,具体如下所示
Lc:content loss,内容损失,定义为经由解码器g输出的图片g(t),输入到相同的编码器f得到的feature map和目标feature map的欧氏距离,目标feature map使用的是AdaIN输出t,而不是f(c)的原因是可以更快的收敛同时也能达到将t转化为风格迁移的图片的训练效果。
Ls:the style loss ,风格损失,定义为经由解码器g输出的图片g(t)和风格图片,两者输入到相同的编码器f,累积加和每一层输出的feature map均值和标准差的距离。
λ:the style loss weight,衡量内容损失和风格损失比例的权重。
具体代码实现:原论文使用了80000张图片进行训练,为了更加方便了解和实践该方法,使用小的数据集替代,最终实现效果可参考本次实验结果。
模型包含encoder,AdaIN,decoder三部分,encoder和decoder对应,采用vgg19网络结构。
AdaIN核心代码,如下所示:
# 计算channel-wise的均值和标准差
def calc_mean_std(features):
"""
Calculate the mean and standard deviation of the input features.
Args:
features (Tensor): Input features of shape [batch_size, c, h, w].
Returns:
features_mean (Tensor): Mean of the featur演示效果
本次 Huang et al.结果如下图所示,生成图像的结果质量和其他方法也是可比较的:

本次运行结果仅在10000张图片上训练得到效果,原论文接近80000张,测试输入图像大小为原尺寸,如下所示:

测试输入图片resize大小2000*2000:

写在最后
综上所述,AdaIN 实时任意风格迁移技术不仅在理论上推动了图像处理的边界,更在实际应用中展现了其独特的魅力。通过自适应实例归一化,艺术家和开发者能够轻松地将不同风格融入到图像中,创造出丰富多样的视觉效果。这种方法的高效性和灵活性使其在艺术创作、游戏开发及虚拟现实等领域拥有广阔的应用前景。随着技术的不断发展,未来我们有理由相信,AdaIN 将继续激发更多创新,改变我们与数字艺术互动的方式。
详细复现过程的项目源码、数据和预训练好的模型可从该文章下方附件获取。


















 1485
1485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











