






技术介绍
文件中提到的技术细节主要围绕深度学习模型的优化,特别是针对英特尔平台的优化。以下是一些关键技术点的详细介绍:
1. 量化 (Quantization)
量化是一种减少模型大小和加速推理的技术。文档中提到了几种量化方法:
-
后训练量化 (Post-training Quantization): 包括静态量化和动态量化。
- 静态量化 (Static Quantization): 使用离线校准来收集数据集上的张量信息,然后根据这些信息量化输入和权重张量。
- 动态量化 (Dynamic Quantization): 在运行时收集每个批次的张量信息,不需要校准。
-
训练中量化 (During Training Quantization):
- 量化感知训练 (Quantization-Aware Training): 在训练过程中模拟量化的效果。
- 混合精度 (Mixed-Precision): 使用不同的数据类型,如bfloat16和float16,来训练模型。
-
权重仅量化 (Weight-Only Quantization): 仅对权重进行量化,而输入保持不变。这种方法在大型语言模型(Large Language Models, LLMs)领域很流行。
2. 量化公式
文档中讨论了两种量化类型:
- 对称量化 (Symmetric Quantization)
- 非对称量化 (Asymmetric Quantization)
并提到了量化的应用数据类型,如INT8, INT4, FP8。
3. 静态量化细节
文档提供了静态量化的数学公式和计算步骤,展示了如何在运行时计算量化权重和激活。
4. INT8在Intel Xeon平台的支持
介绍了AVX512和AVX512_VNNI指令集对INT8运算的支持,这些指令集可以提高INT8运算的性能。
5. SmoothQuant
为了解决大型语言模型中激活值的显著异常值问题,提出了SmoothQuant技术。这项技术通过将激活异常值转移到权重上来改善量化效果。
6. BF16数据类型
BF16(Brain Floating Point 16)是Google提出的一种数据类型,它具有与FP32相同的范围,但精度较低。文档中提到了BF16的优势,以及在Intel平台上的支持情况。
7. 权重仅量化 (Weight-Only Quantization)
文档讨论了如何通过权重仅量化减少大型模型的内存使用,特别是对于INT4和FP8数据类型。
8. GPTQ和AWQ
GPTQ和AWQ是两种量化算法,通常用于提高量化模型的准确性。
9. FP8数据类型
FP8是一种低精度浮点数格式,有两种变体:E4M3(4位指数和3位尾数)和E5M2(5位指数和2位尾数)。文档提到了Nvidia提出的延迟缩放技术,用于FP8的动态量化。
10. 剪枝 (Pruning)
剪枝是一种减少模型大小的技术,通过移除不重要的权重来实现。文档中提到了几种剪枝算法,包括基本幅度、梯度敏感性和模式锁定。
11. 知识蒸馏 (Knowledge Distillation)
知识蒸馏是一种优化技术,通过训练一个小型模型来模仿一个大型模型的行为,从而提高小型模型的性能。
实验过程
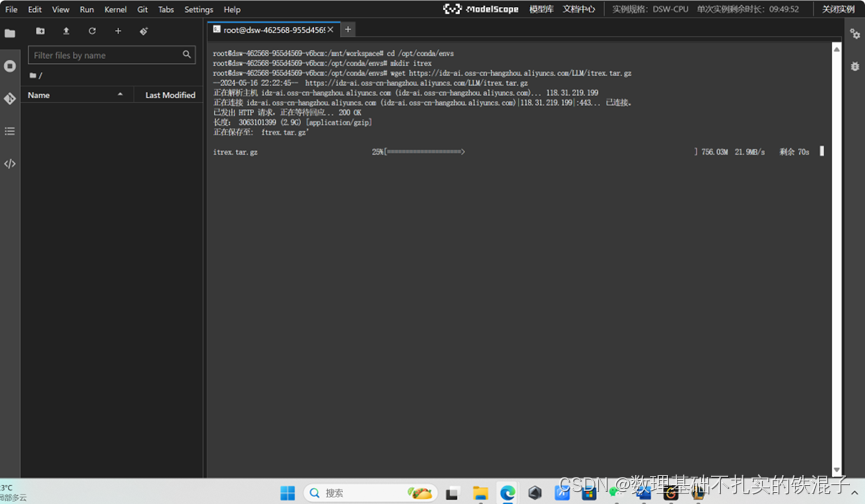
首先新建文件夹,拷贝镜像文件。
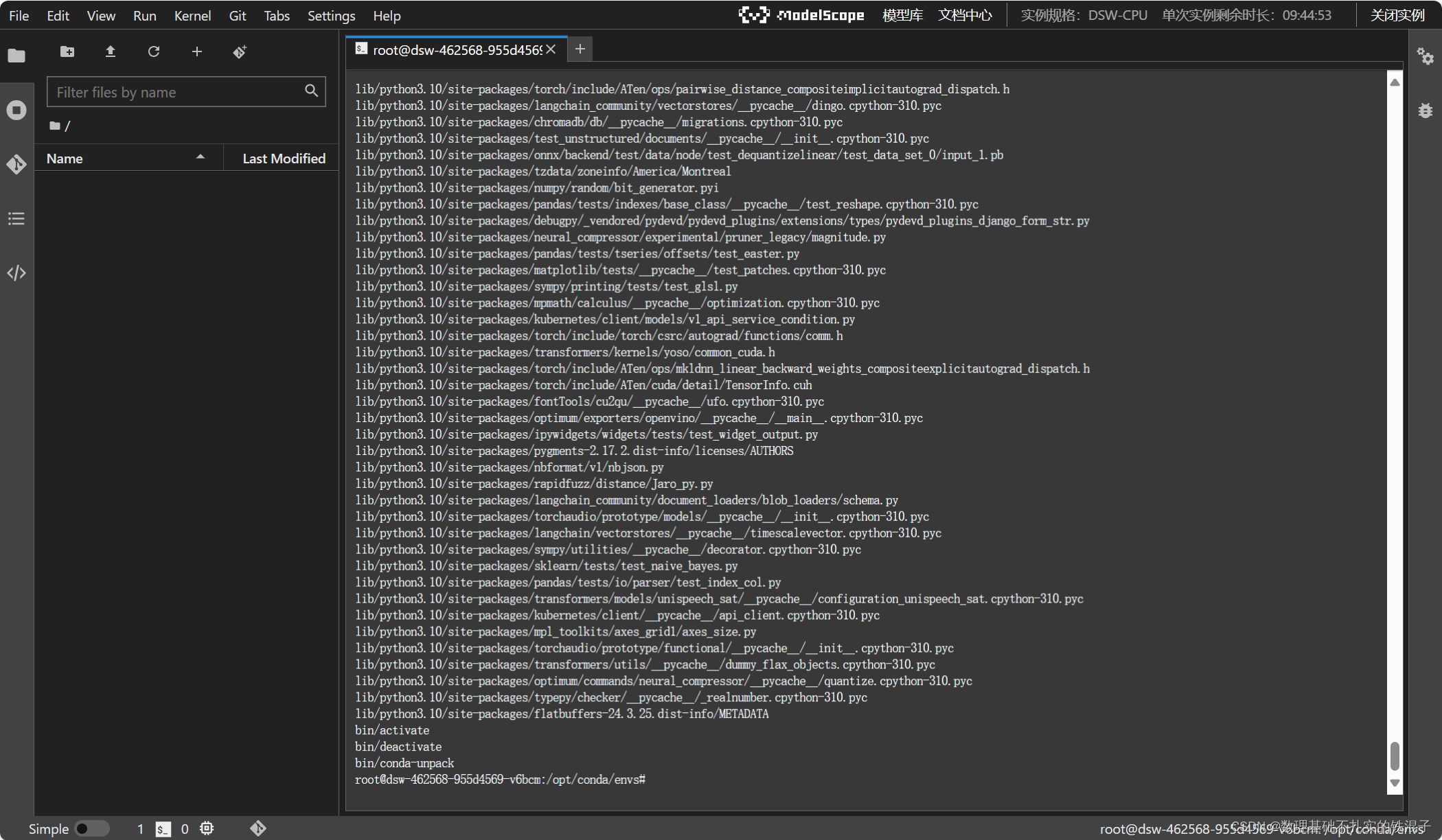
然后解压,
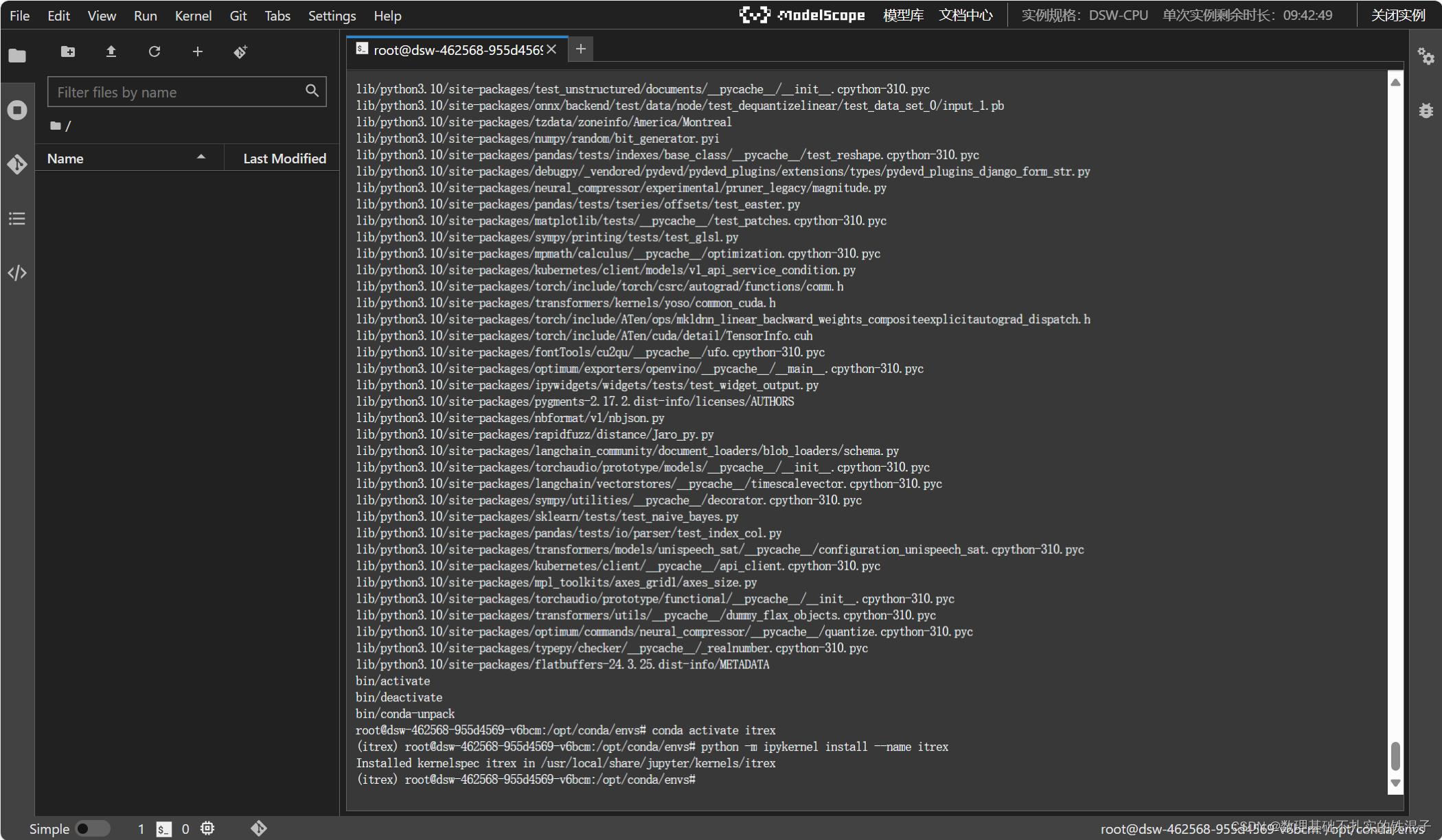
并激活环境。
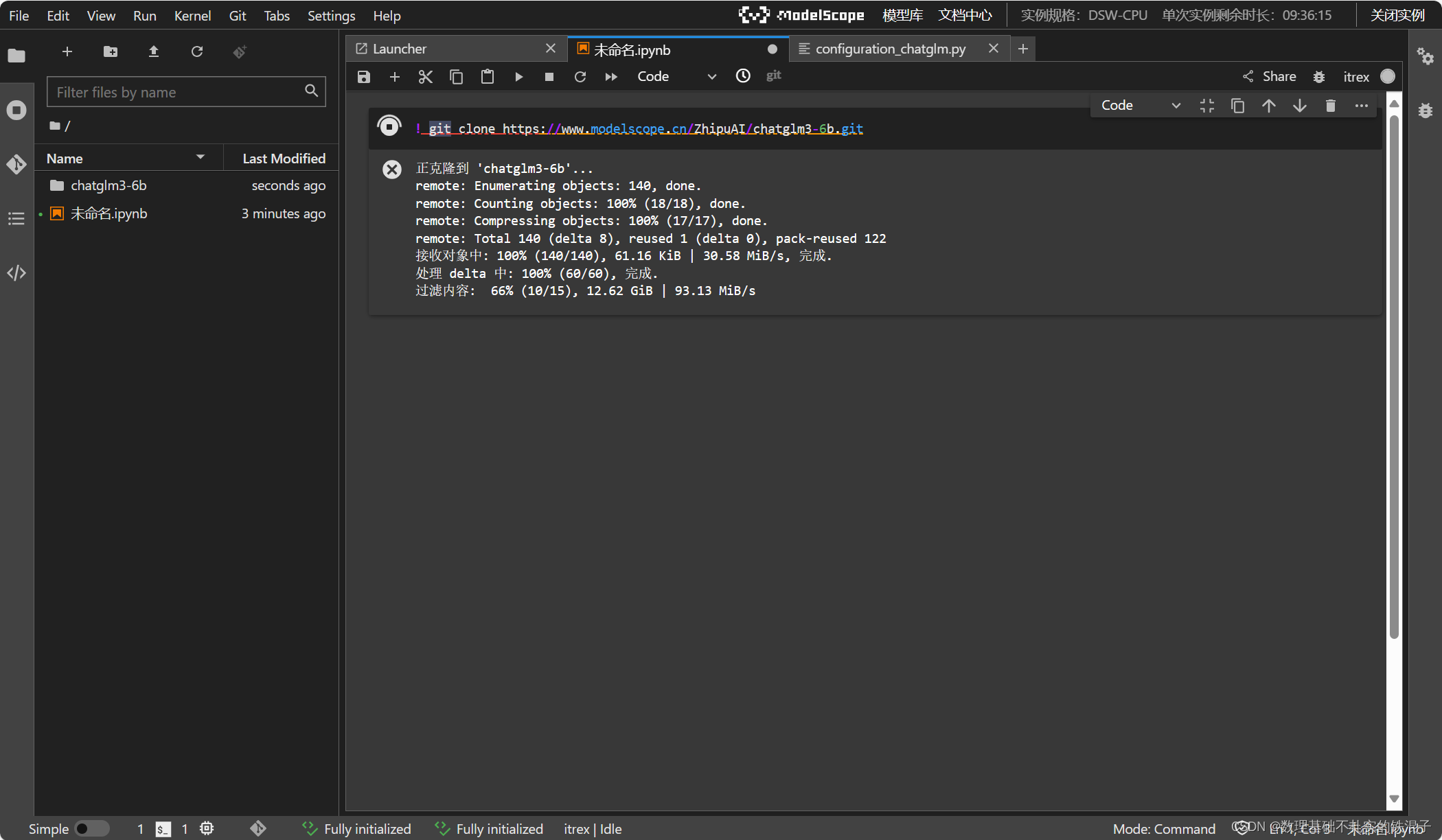
在基于itrex kernel新建的notebook中下载大模型以及embeding模型。
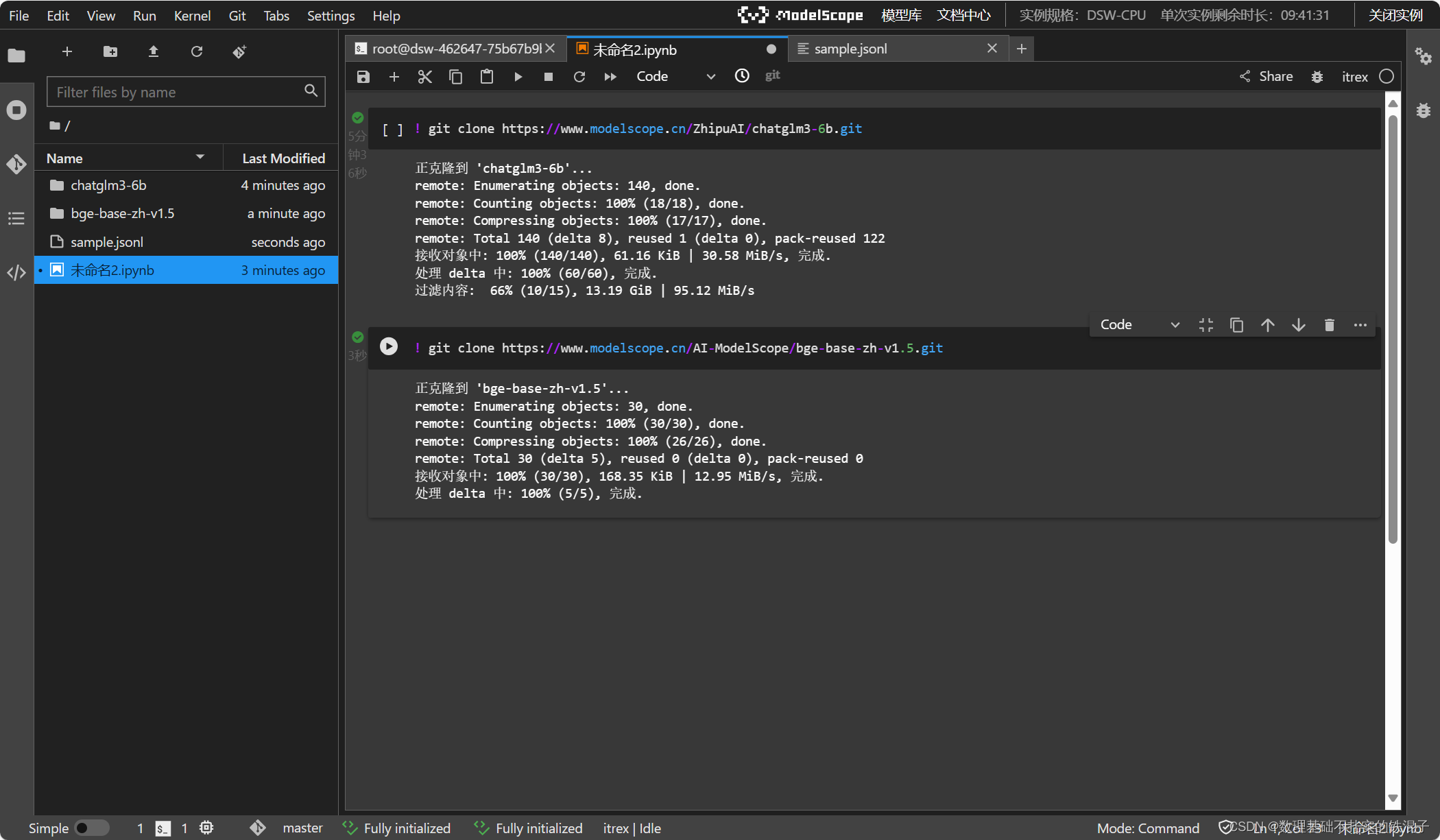
构建chatbot
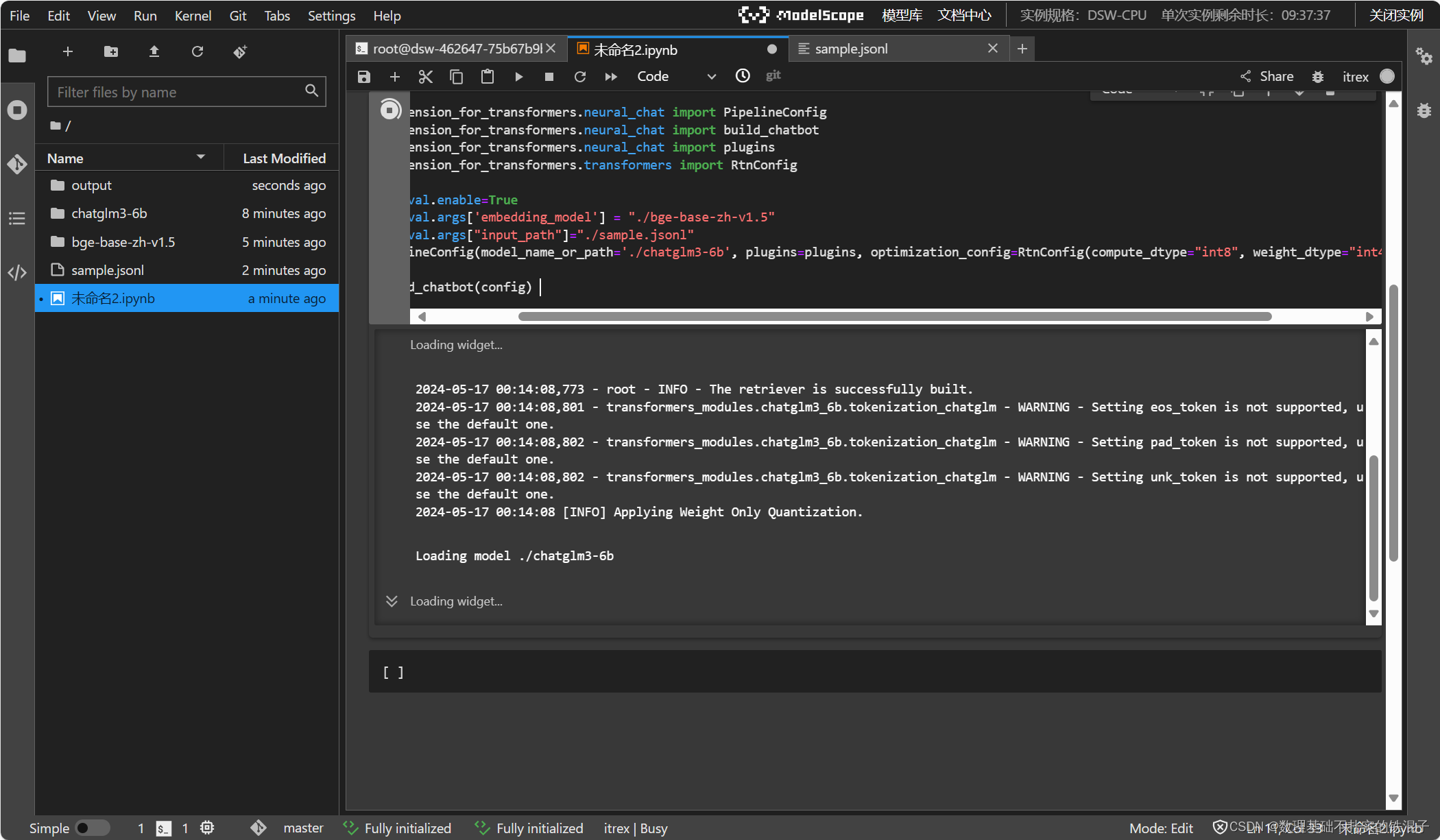
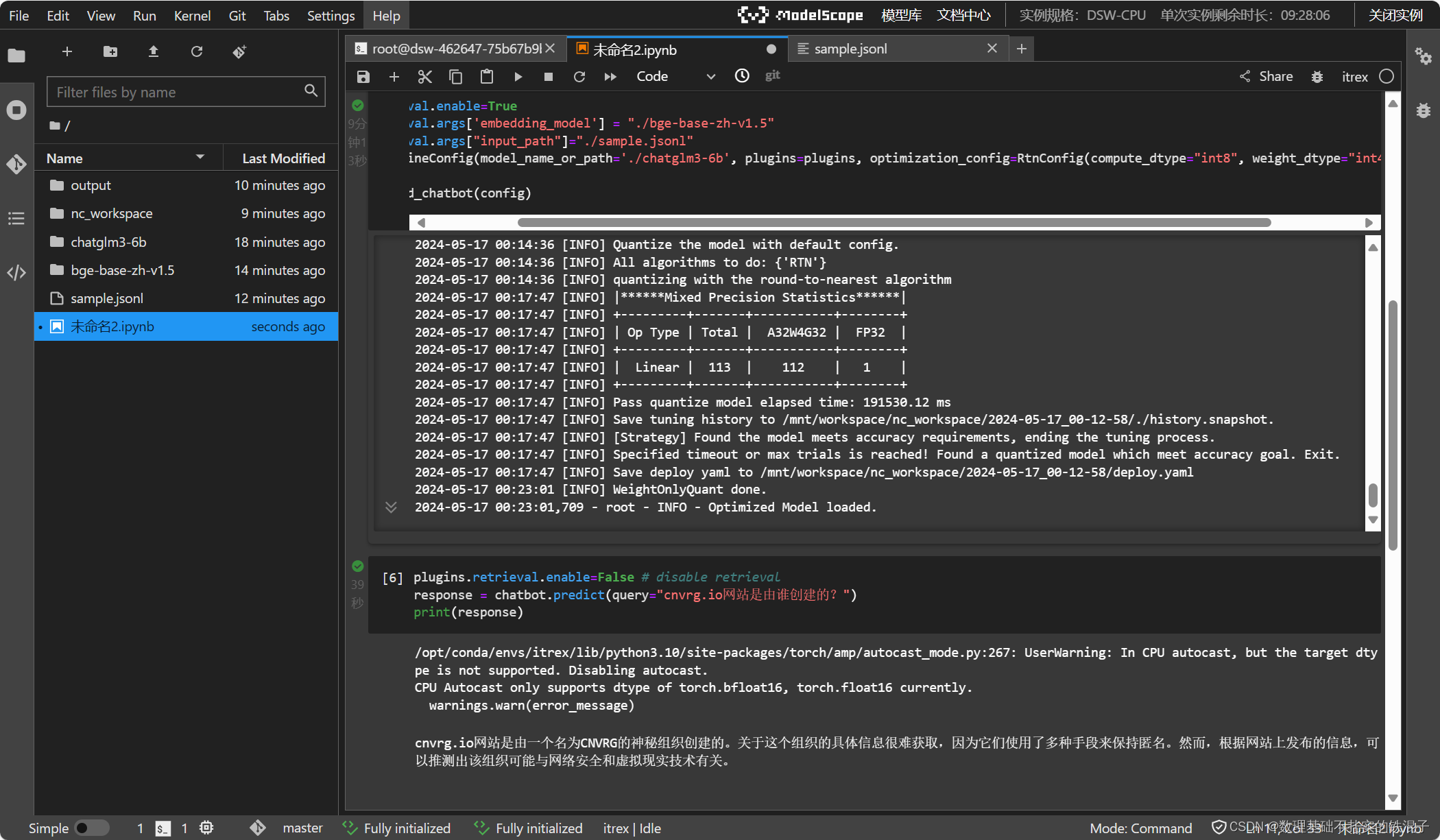
运行结果
个人心得
通过该次实验,学习了大模型前沿的加速技术,通过该实验也锻炼了自己部署大模型和chatbot的经验。















 1205
1205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









