







问:梯度下降法一定能求得最小值???
答:在某些情况下,梯度下降法可以找到函数的最小值,但并非总是如此。这取决于函数的形状和梯度下降法的参数设置。如果函数具有多个局部最小值,梯度下降法可能会收敛到其中一个局部最小值,而不是全局最小值。此外,如果步长太大或太小,梯度下降法的性能也会受到影响。因此,在使用梯度下降法时,需要进行适当的参数调整和实验,以确保找到函数的最小值。
名词介绍
首先,要明确梯度是一个向量,是一个n元函数f关于n个变量的偏导数,比如三元函数f的梯度为(fx,fy,fz),二元函数f的梯度为(fx,fy),一元函数f的梯度为fx。然后要明白梯度的方向是函数f增长最快的方向,梯度的反方向是f降低最快的方向。
原理举例
梯度下降法(Geadient descent)是一种常用的一阶优化算法,是求解无约束优化问题最简单、最经典的方法之一,并且其在机器学习中使用非常非常广泛,不管是神经网络中的参数优化还是Boosting模型的构造中,都离不开梯度下降法,我们可以毫不夸张的说,梯度下降法是现代机器学习的血液。所以要想学好机器学习,就必须熟练掌握梯度下降算法。
梯度下降法优化线性回归主要是对损失函数进行优化。首先来看这么一个问题,有两组数据,分别表示自变量和因变量,让我们找到一条最合适的直线方程来反映两组数据之间的关系,我们想到了一元回归,那么一元线性回归的方程多种多样,其通用的形式可以表示为:
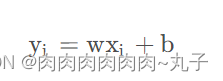
上述的w是自变量的系数,b是截距,我们需要找到最合适的w和b,使得该直线最优,那么如何定义最优呢?下面又引入了一个Loss函数:

只要找到使得上述的Loss函数最小的参数w和b,我们就能找到最优的回归直线,而找到这条直线的方法就是梯度下降法。如果令损失函数为L,则对于此Loss函数的偏导为:

为了简化计算,那么可以将上述的两个偏导式合并起来迭代,也就是通过在矩阵中加一行常数列来进行矩阵计算 
即通过梯度下降法找到了最优的参数,其实整个过程就是一个不断迭代的过程,在不断迭代中寻找最优参数w和b。
算法总结
梯度下降法作为一个非常经典的优化算法,是入门机器学习必须要掌握的算法之一。在很多前沿的机器学习算法中都能看到梯度下降法的身影,算法使用的是一阶收敛,运行速度较慢,后面还会接触到牛顿法,这是一个二阶收敛算法,运行速度要比梯度下降法快很多。
















 1387
1387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











