







CLion2023环境搭建配置:
-
CLion配置工程使用外部Linux编译器编译:https://blog.csdn.net/huamu_xingkong/article/details/136944830
-
在使用Clion通过SSH远程连接Linux,在本地工程上开发远程编译出现有关C++的相关头文件找不到,如下图所示,但是可以编译成功:解决办法

一、计算图
1.1 计算图定义
计算图(Computational Graph)是一种用于表示数学运算和数据流的图结构,在深度学习中,它用于描述神经网络中的操作及其依赖关系。计算图由节点和边组成,其中:
-
节点:表示操作(如加法、乘法、激活函数等)或变量(如输入、权重、偏置等)。
-
边:表示数据的流动,通常是张量(Tensor)在节点间传递。
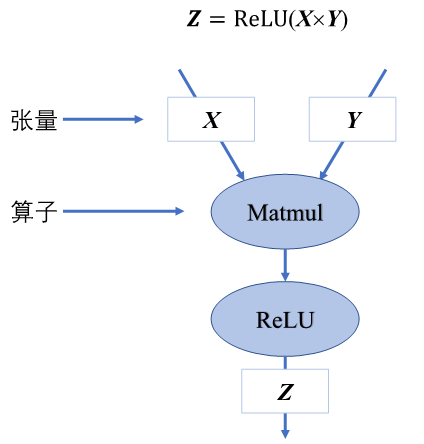
如上图所示,将下面的公式转为计算图表示。
Z
=
R
e
L
U
(
X
×
Y
)
Z= ReLU(X \times Y)
Z=ReLU(X×Y)
1.2 计算图的生成
在深度学习框架中可以生成静态图和动态图两种计算图。静态生成可以根据前端语言描述的神经网络拓扑结构以及参数变量等信息构建一份固定的计算图。因此静态图在执行期间可以不依赖前端语言描述,常用于神经网络模型的部署,比如移动端人脸识别场景中的应用等。动态图则需要在每一次执行神经网络模型依据前端语言描述动态生成一份临时的计算图,这意味着计算图的动态生成过程灵活可变,该特性有助于在神经网络结构调整阶段提高效率。
主流机器学习框架TensorFlow、MindSpore均支持动态图和静态图模式;PyTorch则可以通过工具将构建的动态图神经网络模型转化为静态结构,以获得高效的计算执行效率。了解两种计算图生成方式的优缺点及构建执行特点,可以针对待解决的任务需求,选择合适的生成方式调用执行神经网络模型。
1.2.1 静态计算图(Static Computational Graph)
也称为定义-运行(define-and-run)模式,静态计算图在程序开始时一次性构建,然后在执行阶段被多次使用。图结构固定,便于优化和加速,适合批处理任务。
- 优点
- 高效:由于图在构建时就确定,可以进行更深入的图优化,如内存优化、常量折叠等。
- 易于部署:可以将静态计算图导出为独立文件,用于生产环境中的高效推理。
- 缺点
- 不灵活:不适合处理动态变化的网络结构,特别是在处理可变长度的输入数据时。
1.2.2 动态计算图(Dynamic Computational Graph)
动态计算图在每次前向传播时动态构建,因此图的结构可以根据输入数据变化。其灵活性高,适合需要动态调整结构的任务,如循环神经网络(RNN)处理变长序列。
- 优点
- 灵活:可以处理动态结构和复杂控制流,适合实验和调试。
- 直观:图的构建与运行是同步的,易于理解和调试。
- 缺点
- 性能可能较低:由于图是动态生成的,难以进行高级优化。
- 部署复杂:动态生成的图不易导出为固定的模型格式,可能需要额外的工作来部署。
1.3 计算图功能
计算图在训练阶段和推理部署阶段的功能与实现存在显著差异。这些差异主要源于两个阶段对计算图的不同需求:训练阶段侧重于学习和优化模型参数,而推理部署阶段则侧重于高效地应用这些参数进行预测。
1.3.1 训练阶段
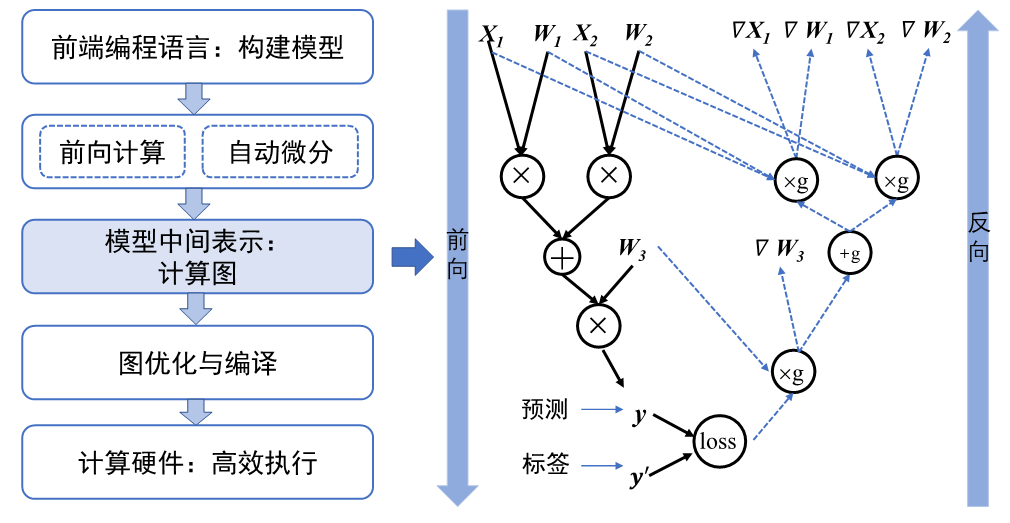
计算图在模型训练阶段主要有以下功能:
-
前向传播:计算输入数据通过网络的前向传播,生成预测结果。在训练过程中,前向传播不仅生成输出,还保存中间结果(如激活值),为反向传播计算梯度提供基础。
-
反向传播与梯度计算:计算
损失函数相对于每个参数的梯度,以指导模型参数的更新。计算图记录了前向传播过程中每个操作的梯度计算规则,通过链式法则自动计算各个参数的梯度。 -
参数更新:利用反向传播得到的梯度,通过优化算法(如SGD、Adam)更新模型参数。计算图通常不直接涉及参数更新,但优化器在图之外使用计算得到的梯度来更新参数。
-
计算图的动态性:支持动态计算图的生成与执行,允许模型结构在训练过程中根据输入数据进行调整。如在处理变长序列或需要动态调整网络结构的任务中,动态计算图能够灵活应对不同的输入数据。
-
正则化操作:添加正则化操作(如Dropout、L2正则化),防止模型过拟合。这些操作主要用于训练阶段,在推理时通常会被移除或替换。
-
图优化:在训练过程中,计算图框架可能会进行优化以加速训练过程,如操作融合、内存优化等。虽然优化重点不同,但一些优化(如操作融合)在训练和推理中都会应用。
-
数据增强与预处理:在训练过程中,计算图框架通常支持数据增强和预处理操作(如图像翻转、归一化等),以提高模型的泛化能力。这些操作通常只在训练时进行,不会在推理部署中使用。
1.3.2 推理部署阶段
-
前向传播:在给定输入的情况下,进行高效的前向传播以生成最终的预测结果。
推理阶段只需要进行前向传播,不涉及反向传播和梯度计算,因此执行更加高效。 -
图的冻结与优化:推理时使用冻结的计算图,去除训练相关的操作,优化执行路径以提高推理效率。冻结的计算图通常通过各种优化手段,如
常量折叠、操作融合、移除不必要的操作(如Dropout),确保推理的高效性。 -
硬件适配:根据推理平台的硬件特性(如CPU、GPU、TPU),进行图的调整和优化,以充分利用硬件加速能力。推理阶段的计算图更关注硬件加速的实现,通过图分割与调度、张量分配等技术,最大化硬件资源的利用。
-
模型量化与压缩:将模型中的
浮点数权重和激活量化为低精度整数,减少计算量和存储需求,提升推理速度。推理部署阶段通常会进行模型量化和剪枝,以减少模型大小,降低计算成本,适应资源受限的环境。 -
模型导出与跨平台部署:将训练好的模型导出为特定格式(PNNX或ONNX),以便在不同平台上进行部署。推理部署阶段需要确保模型在不同硬件和操作系统上的兼容性和性能。
| 训练阶段 | 部署阶段 | |
|---|---|---|
| 动态性 vs. 静态性 | 可能需要处理动态计算图,允许网络结构根据输入数据实时变化 | 通常使用静态计算图,以优化后的固定结构进行高效执行 |
| 计算复杂度 | 需要进行前向传播、反向传播和梯度计算,计算量大,内存占用高 | 只进行前向传播,无需计算梯度和更新参数,计算量相对较小,内存占用也较低。 |
| 优化目标 | 提高模型的收敛速度和准确性,通过梯度计算和参数更新来改进模型性能 | 最大化推理速度和资源利用率,确保模型在各种环境下的高效运行 |
| 操作内容 | 涉及反向传播、梯度更新、正则化等训练特有的操作 | 这些训练特有的操作通常被移除,图被简化为只包含必要的前向传播操作 |
| 内存与硬件资源使用 | 内存使用量较大,尤其是在处理大规模模型或分布式训练时,框架需要优化内存分配和使用。 | 内存使用相对较低,更多关注硬件加速和延迟优化,以满足实时或大规模并发推理需求 |
训练阶段关注模型的学习能力和优化过程,而推理阶段则重点在于如何将已经学习到的知识快速、准确地应用到实际数据中。
1.4 计算图的调度(执行)
模型训练就是计算图调度图中算子的执行过程。训练任务是由设定好的训练迭代次数来循环执行计算图,此时需要优化迭代训练计算图过程中数据流载入和训练(推理)执行等多个任务之间的调度策略。单次迭代需要考虑计算图内部的调度执行问题,根据计算图结构、计算依赖关系、计算控制分析算子的执行调度。优化计算图的调度和执行性能,目的是尽可能充分利用计算资源,提高计算效率,缩短模型训练和推理时间。
算子的执行调度包含两个步骤:
-
根据
拓扑排序算法,将计算图进行拓扑排序得到线性的算子调度序列; -
将序列中的算子分配到
指令流进行运算,尽可能将序列中的算子并行执行,提高计算资源的利用率。
计算图是一种由依赖边和算子构成的有向无环图,深度学习框架需要将包含这种依赖关系的算子准确地发送到计算资源,比如CPU、GPU、NPU上执行。针对有向无环图,通常使用拓扑排序来得到一串线性的序列。如下图所示一张有向无环图。

图中包含了a、b、c、d、e五个节点和a->d、b->c、c->d、d->e四条边(a->d表示d依赖于a,称为依赖边)。将图的依赖边表达成节点的入度(图论中通常指有向图中某点作为图中边的终点的次数之和),可以得到各个节点的入度信息(a:0、 b:0、 c:1、 d:2、 e:1)。拓扑排序就是不断循环将入度为0的节点取出放入队列中,直至有向无环图中的全部节点都加入到队列中,循环结束。例如,第一步将入度为0的a、b节点放入到队列中,此时有向无环图中c、d的入度需要减1,得到新的入度信息(c:0、d:1、e:1)。以此类推,将所有的节点都放入到队列中并结束排序。
生成调度序列之后,需要将序列中的算子与数据分发到指定的GPU/NPU上执行运算。根据算子依赖关系和计算设备数量,可以将无相互依赖关系的算子分发到不同的计算设备,同时执行运算,这一过程称之为并行计算,与之相对应的按照序贯顺序在同一设备执行运算被称为串行计算。这里就不过多讲解。
小结:计算图的基本数据结构是张量,基本运算单元是算子。计算图是一个有向无环图,图中算子间可以存在直接依赖和间接依赖关系,或者相互关系独立,但不可以出现循环依赖关系。计算图的生成可以分为静态生成和动态生成两种方式。静态图计算效率高,内存使用效率高,但调试性能较差,可以直接用于模型部署。动态图提供灵活的可编程性和可调试性,可实时得到计算结果,在模型调优与算法改进迭代方面具有优势。利用计算图和算子间依赖关系可以解决模型中的算子执行调度问题。
二、PNNX计算图
2.1 PNNX介绍
不同的深度学习框架,如Tensorflow、PyTorch、MindSpore等,都定义了自己的模型的数据结构(计算图),推理系统需要将它们转换到统一的一种数据结构上。开发神经网络交换协议**(Open Neural Network Exchange,ONNX)正是为此目的而设计的。ONNX支持广泛的深度学习运算符集合,并提供了不同训练框架的转换器,例如TensorFlow模型到ONNX模型的转换器、PyTorch模型到ONNX模型的转换器等。模型转换本质上是将模型这种结构化的数据**,从一种数据结构转换为另一种数据结构的过程。进行模型转换首先要分析两种数据结构的异同点,然后针对结构相同的数据做搬运;对于结构相似的数据做一一映射;对于结构差异较大的数据则需要根据其语义做合理的数据转换;更进一步如果两种数据结构上存在不兼容,则模型转换无法进行。
ONNX具有表达PyTorch模型的能力,并且它是一个开放标准。人们通常使用 ONNX 作为 PyTorch 和推理平台之间的中间表示。然而ONNX仍然存在以下致命问题:
-
ONNX 没有用户可读和可编辑的文件表示形式,这使得用户很难轻松修改计算图或添加自定义运算符。
-
ONNX 的算子定义并不完全符合 PyTorch。将训练好的模型导出为
ONNX结构之后,模型中的一个复杂算子不仅经常会被拆分成多个细碎的算子,而且为了将这些细碎的算子拼接起来完成原有算子的功能,通常还需要一些称之为“胶水算子”的辅助算子,例如Gather和Unsqueeze等。过于细碎的计算图不利于推理的优化。另外,拆分的层次过于细致,也会导致算法工程师难以将导出的模型和原始模型进行结构上的相互对应。在导出一些 PyTorch 算子时,ONNX 往往会被动添加胶水算子,这使得计算图与 PyTorch 不一致,并可能影响推理效率。 -
ONNX 中的运算符定义中有大量附加参数,这些参数增加了硬件和软件推理实现的负担。
为了解决以上问题,我们选用NCNN推理框架的计算图格式之一PNNX(PyTorch Neural Network eXchange),PNNX 为 PyTorch 提供开放模型格式,PNNX 尝试定义一套与 PyTorch 的 python api 完全对接的算子以及简单易用的格式,使得 PyTorch 模型的转换和互操作更加便捷,它定义的计算图以及高级运算符,与 PyTorch 严格匹配。
通常⼀个网络模型文件从PyTorch 先经历了TorchScript(.pt文件)的导出,然后再转换为其它模型(ONNX、PNNX),经过 PNNX 的优化可以得到最终的模型文件,这里不用管最后导出为 NCNN 的部分。

1.PNNX 始终保留 PyTorch提供的算子操作
import torch
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.attention = nn.MultiheadAttention(embed_dim=256, num_heads=32)
def forward(self, x):
x, _ = self.attention(x, x, x)
return x
下面是 ONNX、TorchScript 和 PNNX 之间的 netron 可视化比较(TorchScript -->ONNX TorchScript --> PNNX ):
| ONNX | TorchScript | PNNX |
|---|---|---|
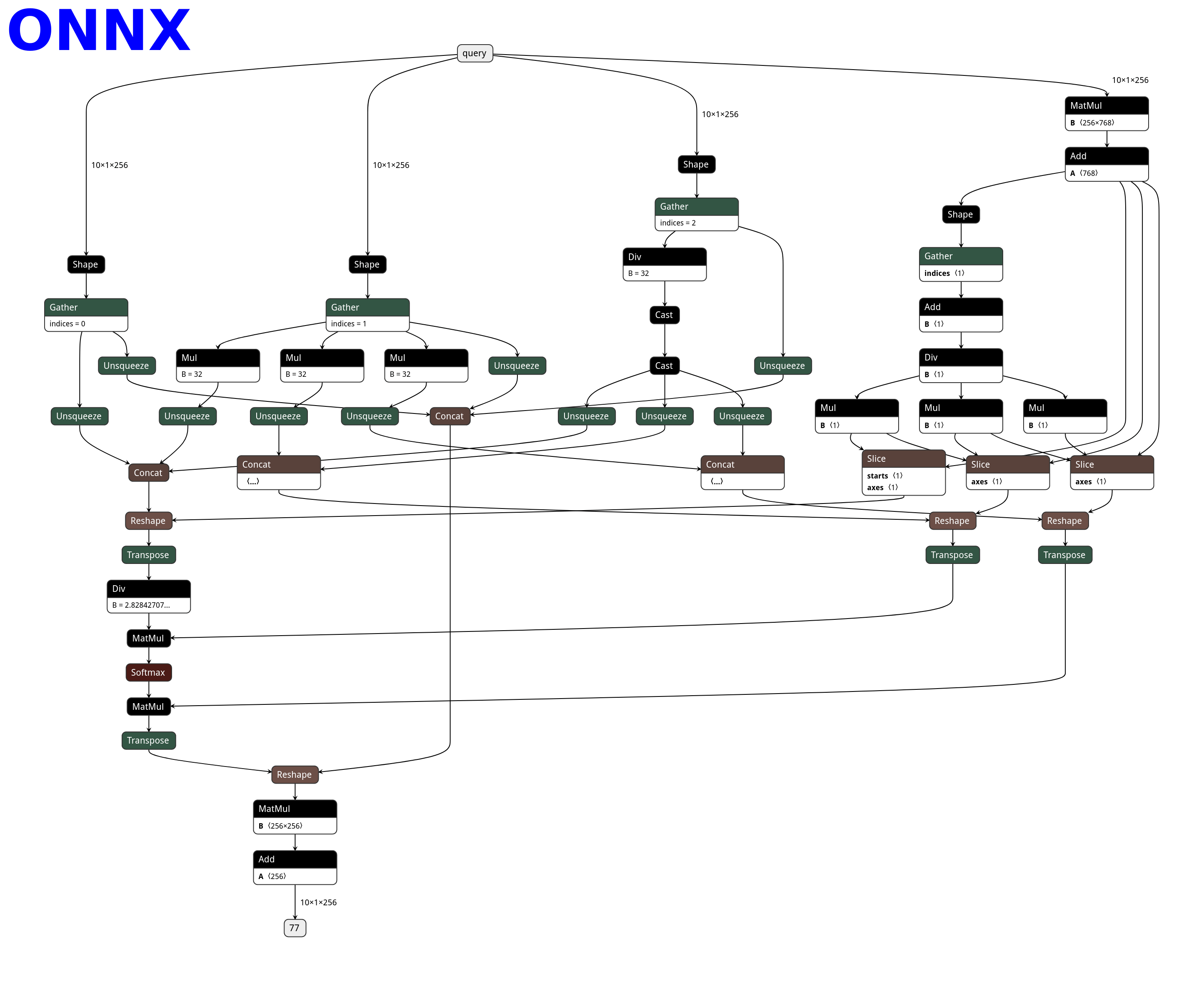 | 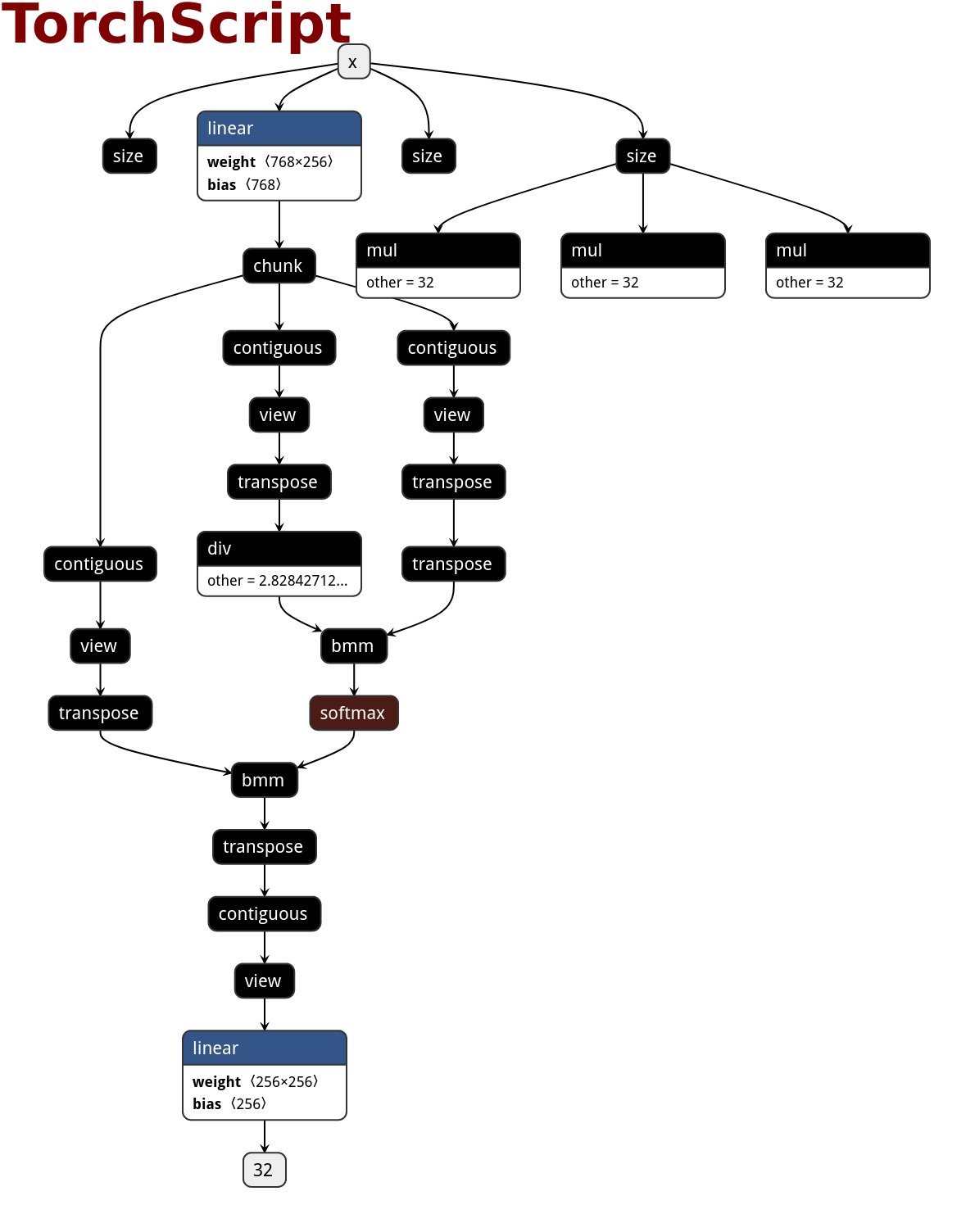 | 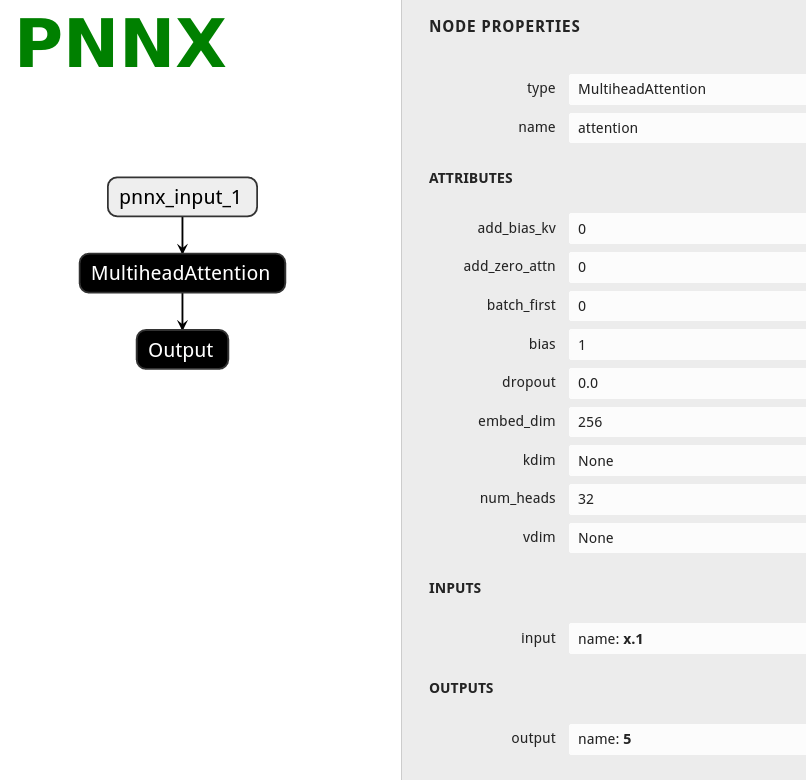 |
PNNX使用模板匹配(pattern matching)的方法将匹配到的子图(一般在TorchScript中)用对应等价的大算子替换掉,例如可以将上图子图中的多个小算子(在TorchScript中被拆分的)重新替换为MultiheadAttention算子,可以看到onnx对算子拆分得更加的细致。
2.PNNX 会保留 PyTorch 所定义的表达式。
import torch
def foo(x, y):
return torch.sqrt((2 * x + y) / 12)
| ONNX | TorchScript | PNNX |
|---|---|---|
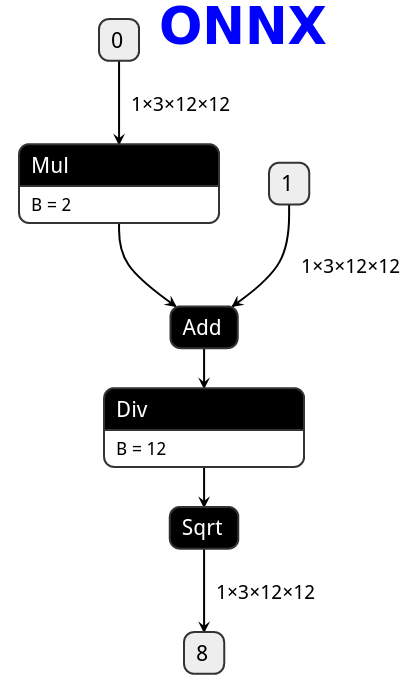 | 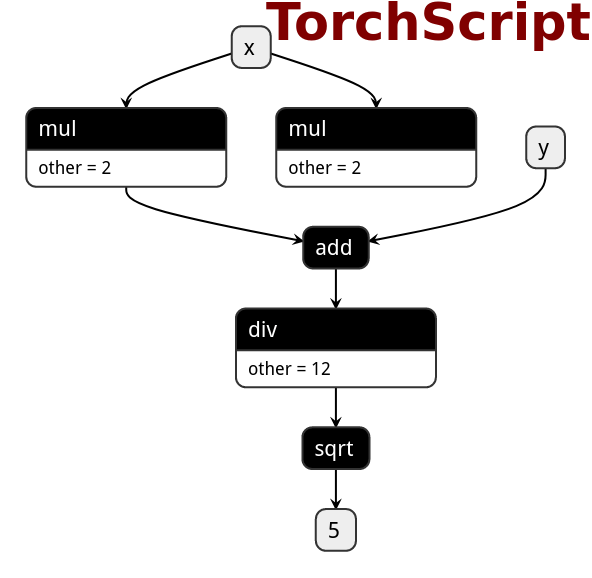 |  |
在PyTorch中定义表达式在转换为PNNX之后,会保留表达式的整体结构,而不会被拆分成多个小的加减乘除算子。例如表达式sqrt(div(add(mul(@0,2),@1,1),12))不会被拆分为两个mul算子、一个add算子、一个div和sqrt算子,而是会生成一个表达式算子Expression 。
3.PNNX 将 PyTorch提供的 torch 函数和 Tensor 成员函数保存为一个运算符。
import torch
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
def forward(self, x):
x = F.normalize(x, eps=1e-3)
return x
| ONNX | TorchScript | PNNX |
|---|---|---|
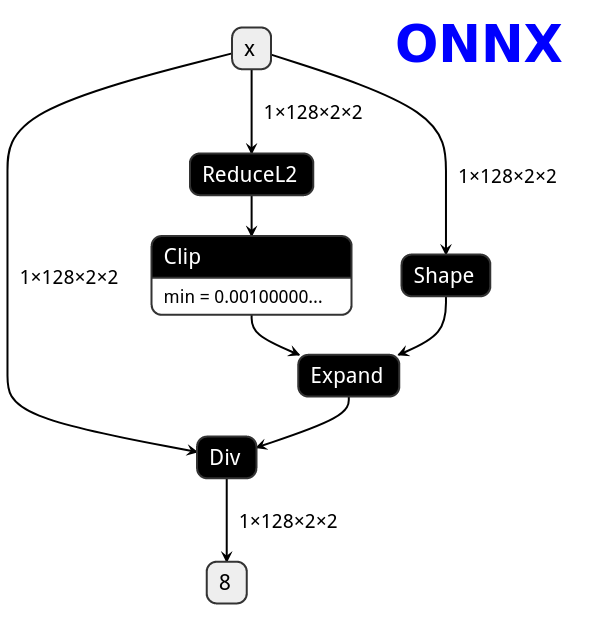 | 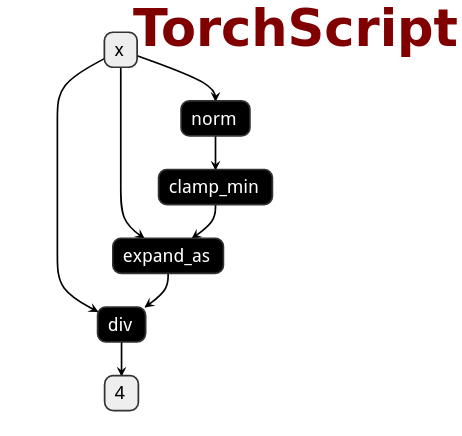 |  |
参考资料:https://zhuanlan.zhihu.com/p/427620428、https://github.com/Tencent/ncnn/tree/master/tools/pnnx#the-pnnxparam-format
2.2 PNNX计算图结构
在 PNNX 中,计算图的核心结构包括 Graph(图结构)、Operator(运算符)、和 Operand(操作数)。这些结构共同作用,构成了 PNNX 用于表示和优化神经网络模型的基础。
-
Graph:Graph是 PNNX 用于表示整个神经网络模型的计算图,由多个Operator串联得到的有向无环图,规定了各个计算节点(Operator)执行的流程和顺序。它包含了模型中的所有运算符(Operator)和操作数(Operand),并通过这些组件描述模型的计算流程。 -
Operator:Operator是计算图中的节点,表示模型中的具体操作或层次,其包含type(表示操作的类型,例如卷积、ReLU等)、name(操作的名称)、params(参数)和attrs(属性)等字段。 -
Operand:Operand是计算图中的边,表示数据流动。它们通常是张量(Tensor), 用于存放多维数据,作为Operator的输入和输出,方便数据在计算节点之间传递。 -
Layer: 计算节点中运算的具体执行者,Layer类先读取输入张量中的数据,然后对输入张量进行计算,得到的结果存放到计算节点的输出张量中,不同的算子中Layer的计算过程会不一致。

上图中模型在PyTorch中的定义如下,其作用是对输入x进行线性映射(从32维到128维),并对输出进行sigmoid计算,从而得到最终的计算结果。
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear = nn.Linear(32, 128)
def forward(self, x):
x = self.linear(x)
x = F.sigmoid(x)
return x
Linear层有#0和#1两个操作数(Operand),分别为输入和输出张量,形状依次为(1, 32)和(1, 128);Linear层有两个属性参数:@weight和@bias,用于存储该层的权重数据信息,分别对应权重(即weight)和偏置(即bias)。可以看到这两个权重的形状分别为(1, 32)和(1, 128),在后续过程中可以根据需要进行权重加载。Linear层有三个属性:bias,in_features和out_features,分别表示是否使用偏置项、线性连接层的输入维度和输出维度。
2.3 Graph图结构
Graph在runtime文件夹ir.h中定义的(ncnn中在tools/pnnx/src/ir.h),用于描述神经网络模型的基本数据结构和操作。该文件定义了一个描述神经网络模型的中间表示**(IR)层次结构**。它包含了表示模型参数、属性、操作数和操作的类,以及操作这些类的方法。这些定义提供了一个抽象层,用于描述和操作神经网络模型。
class Graph
{
Operator* new_operator(const std::string& type, const std::string& name);
Operator* new_operator_before(const std::string& type, const std::string& name, const Operator* cur);
Operand* new_operand(const torch::jit::Value* v);
Operand* new_operand(const std::string& name);
Operand* get_operand(const std::string& name);
std::vector<Operator*> ops; // 运算符(算子)
std::vector<Operand*> operands; // 操作数
};
Graph的核心作用是管理计算图中的运算符和操作数。
Operator类用来表示计算图中的运算符(算子),比如Convolution, Pooling等算子;Operand类用来表示计算图中的操作数,即与一个运算符有关的输入和输出张量;Graph类的成员函数提供了方便的接口用来创建和访问操作符和操作数,以构建和遍历计算图。同时,它也是模型中运算符(算子)和操作数的集合。
2.4 Operator运算符
PNNX中的运算符结构Operator定义如下:
class Operator
{
public:
std::vector<Operand*> inputs;
std::vector<Operand*> outputs;
// keep std::string typed member the last for cross cxxabi compatibility
std::string type;
std::string name;
std::vector<std::string> inputnames;
std::map<std::string, Parameter> params;
std::map<std::string, Attribute> attrs;
};
在PNNX中,Operator用来表示一个算子,它由以下几个部分组成:
inputs:类型为std::vector<operand>, 表示这个算子在计算过程中所需要的输入操作数operand;outputs:类型为std::vector<operand>, 表示这个算子在计算过程中得到的输出操作数operand;type和name类型均为std::string, 分别表示该运算符号的类型和名称;params, 类型为std::map, 用于存放该运算符的所有参数(例如卷积运算符中的params中将存放stride,padding,kernel size等信息);attrs, 类型为std::map, 用于存放该运算符所需要的具体权重属性(例如卷积运算符中的attrs中就存放着卷积的权重和偏移量,通常是一个float32数组)。
2.5 Operand操作数
class Operand
{
public:
void remove_consumer(const Operator* c);
Operator* producer;
std::vector<Operator*> consumers;
// 0=null 1=f32 2=f64 3=f16 4=i32 5=i64 6=i16 7=i8 8=u8 9=bool 10=cp64 11=cp128 12=cp32
int type;
std::vector<int> shape;
// keep std::string typed member the last for cross cxxabi compatibility
std::string name;
std::map<std::string, Parameter> params;
};
producer和customers, 分别表示生成该操作数的操作算子和使用该操作数的操作算子列表。注意,产生这个操作数的算子只能有一个,而使用这个操作数的算子可以有很多个。
2.6 Attribute与Parameter
在PNNX中,**权重数据结构(Attribute)和参数数据结构(Param)**定义如下,它们通常与一个运算符相关联,例如Linear算子的in_features属性和weight权重。
class Parameter
{
public:
Parameter()
: type(0)
{
}
static Parameter parse_from_string(const std::string& value);
// 0=null 1=b 2=i 3=f 4=s 5=ai 6=af 7=as 8=others
int type; // 用于表示 Parameter 对象的具体类型
// value
bool b;
int i;
float f;
std::vector<int> ai;
std::vector<float> af;
// keep std::string typed member the last for cross cxxabi compatibility
std::string s;
std::vector<std::string> as;
};
class Attribute
{
public:
Attribute()
: type(0)
{
}
Attribute(const std::initializer_list<int>& shape, const std::vector<float>& t);
// 0=null 1=f32 2=f64 3=f16 4=i32 5=i64 6=i16 7=i8 8=u8 9=bool
int type;
std::vector<int> shape;
std::vector<char> data;
};
以上来源于nccn中的pnnx的src。

-
Graph 类 : 是整个计算图的控制中心,它管理着
Operator和Operand,即图中的节点和边。Graph包含了一个ops向量,用来存储所有的Operator对象;还有一个operands向量,用来存储所有的Operand对象。 -
Operator 类 : 是计算图中的节点,代表着某种操作。每个
Operator都有一个inputs向量,用来存储指向输入Operand的指针;还有一个outputs向量,用来存储指向输出Operand的指针。Operator还包含type(表示操作的类型,例如卷积、ReLU等)、name(操作的名称)、params(参数)和attrs(属性)等字段。 -
Operand 类 : 是计算图中的边,表示模型中的操作数,代表着数据流动。它有一个
producer指针,指向生成该Operand的Operator,还有一个consumers向量,存储着所有使用该Operand的Operator。Operand还包含了type(数据类型)、shape(张量形状)、name(操作数名称)和params(参数)等字段。 -
Parmeter 类:表示操作符的
参数,这些参数通常是一些标量或向量类型的数据,用于配置操作符的行为。例如,一个卷积操作的核大小、步幅、填充方式等都可以作为Parameter。 -
Attribute 类 : 表示操作符的权重或常量数据,这些数据通常是在训练阶段确定的,并在推理阶段保持不变。例如,卷积层的权重、偏置项等都可以作为
Attribute。
小结:
Graph 组织和管理 Operator 和 Operand,形成完整的计算图。
Operator 通过 inputs 和 outputs 与 Operand 连接,形成数据流动的路径。
Operand 通过 producer 和 consumers 确定数据的流向,并与多个 Operator 关联。
Parameter 和 Attribute 在 PNNX 中分别用于处理操作符的配置参数(卷积核大小,步长等)和权重数据(卷积层权重,偏置)。
三、RuntimeGraph
3.1 RuntimeGraph整体介绍
下面对PNNX中的计算图进一步封装,实现RuntimeGraph,集成了 PNNX 的 Graph 以管理计算节点(RuntimeOperator)和数据流(Operand)。
/// 计算图结构,由多个计算节点和节点之间的数据流图组成
class RuntimeGraph {
public:
RuntimeGraph(std::string param_path, std::string bin_path);
// 计算图的初始化,会调用下面各初始化函数
bool Init();
private:
/**
* 初始化kuiper infer计算图节点中的输入操作数
* @param inputs pnnx中的输入操作数
* @param runtime_operator 计算图节点
*/
static void InitGraphOperatorsInput(
const std::vector<pnnx::Operand *> &inputs,
const std::shared_ptr<RuntimeOperator> &runtime_operator);
/**
* 初始化kuiper infer计算图节点中的输出操作数
* @param outputs pnnx中的输出操作数
* @param runtime_operator 计算图节点
*/
static void InitGraphOperatorsOutput(
const std::vector<pnnx::Operand *> &outputs,
const std::shared_ptr<RuntimeOperator> &runtime_operator);
/**
* 初始化kuiper infer计算图中的节点属性
* @param attrs pnnx中的节点属性
* @param runtime_operator 计算图节点
*/
static void
InitGraphAttrs(const std::map<std::string, pnnx::Attribute> &attrs,
const std::shared_ptr<RuntimeOperator> &runtime_operator);
/**
* 初始化kuiper infer计算图中的节点参数
* @param params pnnx中的参数属性
* @param runtime_operator 计算图节点
*/
static void
InitGraphParams(const std::map<std::string, pnnx::Parameter> ¶ms,
const std::shared_ptr<RuntimeOperator> &runtime_operator);
public:
private:
std::string input_name_; /// 计算图输入节点的名称
std::string output_name_; /// 计算图输出节点的名称
std::string param_path_; /// 计算图的结构文件
std::string bin_path_; /// 计算图的权重文件
std::vector<std::shared_ptr<RuntimeOperator>> operators_;
std::map<std::string, std::shared_ptr<RuntimeOperator>> operators_maps_;
std::unique_ptr<pnnx::Graph> graph_; /// pnnx的graph
};
RuntimeGraph 使用了 PNNX 的 Graph 作为其内部数据结构,存储了计算图的节点和边。在 RuntimeGraph 中,graph_ 是一个指向 PNNX Graph 的独占指针 (std::unique_ptr<pnnx::Graph>),用于表示整个计算图。
RuntimeGraph 将 PNNX 的 Operator 和 Operand 结构映射到自定义的 RuntimeOperator 和 RuntimeOperand,并在初始化Init()函数中设置它们之间的输入输出关系。这些映射操作由以下函数完成:
InitGraphOperatorsInput:初始化计算图节点中的输入操作数。InitGraphOperatorsOutput:初始化计算图节点中的输出操作数。InitGraphAttrs:初始化计算图节点中的属性。InitGraphParams:初始化计算图节点中的参数
这些函数用于初始化和管理推理节点(RuntimeOperator)的输入、输出、属性和参数,并且这些函数基于 PNNX Graph 中的数据进行操作。
PNNX的Graph和RuntimeGraph 联系:PNNX 的 Graph 主要用于表示和处理模型的计算图结构,提供了模型的结构化表示。RuntimeGraph 则专注于推理阶段,使用 PNNX Graph 提供的数据来初始化并管理推理过程中的计算节点和数据流。通过这种方式,RuntimeGraph 能够灵活地管理推理过程中的操作节点和数据流,同时充分利用 PNNX 提供的模型表示和处理能力。
在RuntimeGraph中,RuntimeOperator、RuntimeOperand、RuntimeParameter以及RuntimeAttribute的UML结构图如下:

RuntimeOperator 表示计算图中的一个操作节点,每个节点对应着一个特定的计算任务,例如卷积、激活等操作。RuntimeOperand 表示计算节点的输入或输出的数据。它可以视为计算图中节点之间连接的边,传递数据。
RuntimeOperator 与 RuntimeOperand 的关系:
-
输入输出关系:每个
RuntimeOperator通过input_operands接收一个或多个RuntimeOperand作为输入,通过output_operands产生一个或多个RuntimeOperand作为输出。这些操作数代表了节点之间传递的数据流。 -
数据流与计算流的联动:
RuntimeOperand是RuntimeOperator的输入和输出数据。操作数的数据流(RuntimeOperand)决定了计算流(RuntimeOperator)的执行顺序和依赖关系。 -
计算图的构建: 在
RuntimeGraph中,这些RuntimeOperator通过RuntimeOperand连接起来,形成一个有向无环图(DAG),用于描述整个模型的计算流程。
总之,RuntimeOperand 是 RuntimeOperator 的输入和输出,而多个 RuntimeOperator 通过 RuntimeOperand 连接,形成完整的计算图结构。
3.2 RuntimeOperator
RuntimeOperator是KuiperInfer计算图中的核心数据结构,是对PNNX::Operator的再次封装,在runtime_op文件中,它有如下的定义:
/// 计算图中的计算节点
struct RuntimeOperator {
virtual ~RuntimeOperator();
bool has_forward = false;
std::string name; /// 计算节点的名称
std::string type; /// 计算节点的类型
std::shared_ptr<Layer> layer; /// 节点对应的计算Layer
std::vector<std::string> output_names; /// 节点的输出节点名称
std::shared_ptr<RuntimeOperand> output_operands; /// 节点的输出操作数
std::map<std::string, std::shared_ptr<RuntimeOperand>> input_operands; /// 节点的输入操作数
std::vector<std::shared_ptr<RuntimeOperand>> input_operands_seq; /// 节点的输入操作数,顺序排列
std::map<std::string, std::shared_ptr<RuntimeOperator>> output_operators; /// 输出节点的名字和节点对应
std::map<std::string, RuntimeParameter*> params; /// 算子的参数信息
std::map<std::string, std::shared_ptr<RuntimeAttribute>> attribute; /// 算子的属性信息,内含权重信息
};
以上这段代码定义了一个名为RuntimeOperator的结构体。结构体包含以下成员变量:
-
name: 运算符节点的名称,可以用来区分一个唯一节点,例如Conv_1,Conv_2等; -
type: 运算符节点的类型,例如Convolution,Relu等类型; -
layer: 负责完成具体计算的组件,例如在Convolution Operator中,layer对输入进行卷积计算,即计算其相应的卷积值; -
input_operands和output_operands分别表示该运算符的输入和输出操作数。如果一个运算符(
RuntimeOperator)的输入大小为(4, 3, 224, 224),那么在input_operands变量中,datas数组的长度为 4,数组中每个元素的张量大小为(3, 224, 224); -
params是运算符(RuntimeOperator)的参数信息,包括卷积层的卷积核大小、步长等信息; -
attribute是运算符(RuntimeOperator)的权重、偏移量信息,例如Matmul层或Convolution层需要的权重数据; -
其他变量的含义可参考注释。
在这个过程中,需要先从 PNNX::Operator 中提取数据信息(包括 Operand 和 Operator 结构),并依次填入到 KuiperInfer 对应的数据结构中。相应的代码如下所示,由于篇幅原因,在课件中省略了一部分内容,完整的代码可以在runtime_ir.cpp 文件夹中查看。
bool RuntimeGraph::Init() {
if (this->bin_path_.empty() || this->param_path_.empty()) {
LOG(ERROR) << "The bin path or param path is empty";
return false;
}
this->graph_ = std::make_unique<pnnx::Graph>();
int load_result = this->graph_->load(param_path_, bin_path_);
if (load_result != 0) {
LOG(ERROR) << "Can not find the param path or bin path: " << param_path_
<< " " << bin_path_;
return false;
}
std::vector<pnnx::Operator *> operators = this->graph_->ops;
// 在for循环中依次对每个运算符进行处理
for (const pnnx::Operator *op : operators) {
std::shared_ptr<RuntimeOperator> runtime_operator = std::make_shared<RuntimeOperator>();
// 初始化算子的名称,提取PNNX运算符中的名字(name)和类型(type).
runtime_operator->name = op->name;
runtime_operator->type = op->type;
// 初始化算子中的input
const std::vector<pnnx::Operand *> &inputs = op->inputs;
InitGraphOperatorsInput(inputs, runtime_operator);
// 记录输出operand中的名称
const std::vector<pnnx::Operand *> &outputs = op->outputs;
InitGraphOperatorsOutput(outputs, runtime_operator);
// 初始化算子中的attribute(权重)
const std::map<std::string, pnnx::Attribute> &attrs = op->attrs;
InitGraphAttrs(attrs, runtime_operator);
// 初始化算子中的parameter
const std::map<std::string, pnnx::Parameter> ¶ms = op->params;
InitGraphParams(params, runtime_operator);
this->operators_.push_back(runtime_operator);
this->operators_maps_.insert({runtime_operator->name, runtime_operator});
}
return true;
}
RuntimeGraph::Init() 函数**负责从 PNNX 格式的计算图文件中读取图结构,并将其转换为适用于 RuntimeGraph 的 RuntimeOperator 格式。**这些操作包括加载图文件、解析操作符的输入输出、初始化属性和参数等。这个函数的顺利执行是后续图推理或训练的基础。
3.3 RuntimeOperand
/// 计算节点输入输出的操作数
struct RuntimeOperand {
std::string name; /// 操作数的名称
std::vector<int32_t> shapes; /// 操作数的形状
std::vector<std::shared_ptr<Tensor<float>>> datas; /// 存储操作数
RuntimeDataType type = RuntimeDataType::kTypeUnknown; /// 操作数的类型,一般是float
};
RuntimeOperand 是在计算图中表示操作数的数据结构,用于存储每个计算节点的输入和输出。RuntimeGraph::InitGraphOperatorsInput 和 RuntimeGraph::InitGraphOperatorsOutput 两个函数负责初始化 RuntimeOperator 中的输入和输出操作数。这两个函数在上面RuntimeGraph::Init() 中调用的,它们对 RuntimeOperand 的初始化如下:
void RuntimeGraph::InitGraphOperatorsInput(
const std::vector<pnnx::Operand *> &inputs,
const std::shared_ptr<RuntimeOperator> &runtime_operator) {
// 遍历所有的输入张量
for (const pnnx::Operand *input : inputs) {
if (!input) {
continue;
}
const pnnx::Operator *producer = input->producer;
std::shared_ptr<RuntimeOperand> runtime_operand = std::make_shared<RuntimeOperand>();
// 设置操作数的名称
runtime_operand->name = producer->name;
// 设置操作数的形状
runtime_operand->shapes = input->shape;
// 设置操作数的数据类型
switch (input->type) {
case 1:
runtime_operand->type = RuntimeDataType::kTypeFloat32;
break;
case 0:
runtime_operand->type = RuntimeDataType::kTypeUnknown;
break;
default:
LOG(FATAL) << "Unknown input operand type: " << input->type;
}
// 将初始化的操作数添加到 RuntimeOperator 的输入操作数映射和顺序列表中
runtime_operator->input_operands.insert({producer->name, runtime_operand});
runtime_operator->input_operands_seq.push_back(runtime_operand);
}
}
**这段代码的两个参数分别是来自 PNNX 中的一个运算符的所有输入操作数(Operand)和待初始化的 RuntimeOperator。**在以下的循环中:
for (const pnnx::Operand *input : inputs)
需要依次将每个 Operand 中的数据信息填充到新初始化的 RuntimeOperand 中,包括 type, name, shapes 等信息,并记录输出这个操作数(Operand)的运算符(producer)。然后,再将数据完备的 RuntimeOperand 插入到待初始化的 RuntimeOperator 中。
然后InitGraphOperatorsOutput初始化计算节点(RuntimeOperator)的输出操作数。在这个函数中,虽然没有直接初始化 RuntimeOperand,但它处理了输出操作数的关联信息:
void RuntimeGraph::InitGraphOperatorsOutput(
const std::vector<pnnx::Operand *> &outputs,
const std::shared_ptr<RuntimeOperator> &runtime_operator) {
for (const pnnx::Operand *output : outputs) {
if (!output) {
continue;
}
const auto &consumers = output->consumers;
for (const auto &c : consumers) {
runtime_operator->output_names.push_back(c->name);
}
}
}
这段代码的两个参数分别是来自 PNNX 中的一个运算符的所有输出操作数(Operand)和待初始化的 RuntimeOperator。在这里,只需要记录操作数的消费者的名字(customer.name)即可。后面,我们才会对 RuntimeOperator 中的输出操作数(RuntimeOperand)进行构建。
RuntimeGraph::InitGraphOperatorsInput 主要负责初始化 RuntimeOperand,包括其名称、形状和数据类型,并将其添加到对应 RuntimeOperator 的输入操作数中。
RuntimeGraph::InitGraphOperatorsOutput 主要负责记录输出操作数的消费者信息,并将消费者的名称存储在 RuntimeOperator 的 output_names 中,但不直接初始化 RuntimeOperand。
3.4 RuntimeAttribute
RuntimeAttribute 是用来存储计算图节点(RuntimeOperator)的属性信息的结构体,通常包含权重参数、形状信息和数据类型。
/// 计算图节点的属性信息
struct RuntimeAttribute {
std::vector<char> weight_data; /// 节点中的权重参数
std::vector<int> shape; /// 节点中的形状信息
RuntimeDataType type = RuntimeDataType::kTypeUnknown; /// 节点中的数据类型
// 从节点中加载权重参数
template <class T> //
std::vector<T> get(bool need_clear_weight = true);
// 清除权重
void ClearWeight();
};
RuntimeGraph::InitGraphAttrs 函数则负责从 pnnx 的节点属性(pnnx::Attribute)中初始化并填充 RuntimeAttribute,并将这些属性关联到对应的 RuntimeOperator 中。
void RuntimeGraph::InitGraphAttrs(
const std::map<std::string, pnnx::Attribute> &attrs,
const std::shared_ptr<RuntimeOperator> &runtime_operator) {
for (const auto &[name, attr] : attrs) {
switch (attr.type) {
case 1: {
std::shared_ptr<RuntimeAttribute> runtime_attribute = std::make_shared<RuntimeAttribute>();
// 设置属性的数据类型
runtime_attribute->type = RuntimeDataType::kTypeFloat32;
// 将 pnnx::Attribute 中的权重数据拷贝到 RuntimeAttribute 的 weight_data 中
runtime_attribute->weight_data = attr.data;
// 将 pnnx::Attribute 中的形状信息拷贝到 RuntimeAttribute 的 shape 中
runtime_attribute->shape = attr.shape;
// 将已初始化的 RuntimeAttribute 添加到 RuntimeOperator 的 attribute 映射中
runtime_operator->attribute.insert({name, runtime_attribute});
break;
}
default: {
LOG(FATAL) << "Unknown attribute type: " << attr.type;
}
}
}
}
这段代码的两个参数分别是来自 PNNX 中的一个运算符的所有权重数据结构(Attribute)和待初始化的RuntimeOperator。在以下的循环中,
for (const auto& [name, attr] : attrs)
需要依次将 Attribute 中的数据信息填充到新初始化的 RuntimeAttribute 中,包括 type, weight_data, shapes 等信息。然后,将数据完备的 RuntimeAttribute 插入到待初始化的 RuntimeOperator 中,同时记录该权重的名字。
在Linear层中这里的name就是weight或bias, 对于前文测试模型中的Linear层,它的weight shape是(32, 128),weight_data就是32 x 128个float数据。
3.5 RuntimeParam
/// 计算节点中的参数信息
struct RuntimeParameter {
virtual ~RuntimeParameter() = default;
explicit RuntimeParameter(RuntimeParameterType type = RuntimeParameterType::kParameterUnknown) : type(type) {
}
RuntimeParameterType type = RuntimeParameterType::kParameterUnknown;
};
struct RuntimeParameterInt : public RuntimeParameter {
RuntimeParameterInt() : RuntimeParameter(RuntimeParameterType::kParameterInt) {
}
int value = 0;
};
RuntimeParameter 是一个抽象类或接口,用于表示运行时参数。在推理系统中,运行时参数通常用于表示模型中节点的配置或权重等数据。它有多个子类,分别对应不同的数据类型,如 int、float、string、bool 以及它们的数组类型。
RuntimeGraph::InitGraphParams 函数的作用是从 pnnx::Parameter 中读取节点参数数据,并将其转换为 RuntimeParameter 的具体子类对象,然后将这些参数与对应的 RuntimeOperator 关联。
void RuntimeGraph::InitGraphParams(
const std::map<std::string, pnnx::Parameter> ¶ms,
const std::shared_ptr<RuntimeOperator> &runtime_operator) {
for (const auto &[name, parameter] : params) {
const int type = parameter.type;
switch (type) {
// 对应不同的参数类型,根据类型创建对应的 RuntimeParameter 子类对象
case int(RuntimeParameterType::kParameterUnknown): {
RuntimeParameter *runtime_parameter = new RuntimeParameter;
runtime_operator->params.insert({name, runtime_parameter});
break;
}
case int(RuntimeParameterType::kParameterBool): {
RuntimeParameterBool *runtime_parameter = new RuntimeParameterBool;
runtime_parameter->value = parameter.b;
runtime_operator->params.insert({name, runtime_parameter});
break;
}
......
case int(RuntimeParameterType::kParameterStringArray): {
RuntimeParameterStringArray *runtime_parameter = new RuntimeParameterStringArray;
runtime_parameter->value = parameter.as;
runtime_operator->params.insert({name, runtime_parameter});
break;
}
default: {
LOG(FATAL) << "Unknown parameter type: " << type;
}
}
}
}
通过这种方式,每个 RuntimeOperator 节点都能够访问和使用其参数信息,从而在计算过程中可以依据这些参数进行操作。
四、计算图的build
在上面完成RuntimeGraph相关的初始化,在**Init 函数** 中,完成 RuntimeGraph 的基础准备阶段,侧重于从文件中加载图结构,并初始化节点的基本属性和连接关系,主要包括了构建计算图中每个**计算节点(RuntimeOperator)**的权重信息(RuntimeAttribute)、参数信息(RuntimeParameter)以及输入输出张量(input tensor, output tensor)等信息。
下面将在Build函数完成完整计算图的构建和执行准备, Build 函数 是在 Init 的基础上,进一步完成图的完整构建,进一步完成图的连接、输入输出初始化、拓扑排序等关键步骤,使得图可以正确执行。它确保所有节点按依赖关系正确排序,并为执行过程分配所需的资源。
void RuntimeGraph::Build(const std::string &input_name,
const std::string &output_name) {
// 如果图的状态已经是Complete,表示图已经构建完成,直接返回
if (graph_state_ == GraphState::Complete) {LOG(INFO) << "Model has been built already!";return;}
// 如果图的状态是NeedInit,表示图需要初始化,调用Init()函数进行初始化
if (graph_state_ == GraphState::NeedInit) {bool init_graph = Init();
LOG_IF(FATAL, !init_graph) << "Init graph failed!";
}
// 检查当前图的状态是否至少是NeedBuild,如果不是则报告错误
CHECK(graph_state_ >= GraphState::NeedBuild)
<< "Graph status error, current state is " << int(graph_state_);
// 确保operators_列表不为空,如果为空则表示初始化失败,报告错误
LOG_IF(FATAL, this->operators_.empty())<< "Graph operators is empty, may be no init";
// 构建图节点之间的连接关系
for (const auto ¤t_op : this->operators_) {
// 获取当前节点的所有输出节点的名称
const std::vector<std::string> &output_names = current_op->output_names;
for (const auto &kOutputName : output_names) {
// 在operators_maps_中查找对应的输出节点并插入到当前节点的output_operators中
if (const auto &output_op = this->operators_maps_.find(kOutputName);
output_op != this->operators_maps_.end()) {
current_op->output_operators.insert({kOutputName, output_op->second});
}
}
}
// 初始化每个节点的输入和输出空间
RuntimeOperatorUtils::InitOperatorInput(operators_);
RuntimeOperatorUtils::InitOperatorOutput(graph_->ops, operators_);
// 构建拓扑排序
topo_operators_.clear();
for (const auto &[_, op] : operators_maps_) {
// 从输入节点开始,进行反向拓扑排序
if (op->type == "pnnx.Input" && !op->has_forward) {
this->ReverseTopo(op);
}
}
// 确保拓扑排序的节点数和图中的操作符数量一致,如果不一致,报告错误
CHECK(topo_operators_.size() == operators_.size())<< "Build wrong topo queue";
// 将拓扑排序的结果反转,得到最终的执行顺序
std::reverse(topo_operators_.begin(), topo_operators_.end());
// 设置图的状态为Complete,表示图的构建已经完成
graph_state_ = GraphState::Complete;
input_name_ = input_name;
output_name_ = output_name;
// 如果临时的图结构不为空,释放它以节省资源
if (graph_ != nullptr) {
graph_.reset();
graph_ = nullptr;
}
}
以上函数主要完成以下内容:
-
状态检查与初始化:
Build函数首先检查图的当前状态。如果图已经构建完成或尚未初始化,它会根据需要执行相应的操作。 -
构建节点之间的连接关系:根据节点的输出名称,建立节点之间的连接关系。
-
初始化输入输出空间:为每个节点分配输入和输出的空间,确保数据在计算过程中能够正确传递。
-
拓扑排序:根据节点之间的依赖关系,生成
图的拓扑排序,确保节点按照正确的顺序执行。 -
完成构建:设置图的状态为
Complete,表示图的构建已经完成,并释放临时的图结构以节省资源。
4.1 计算图状态
GraphState 枚举类定义了 RuntimeGraph 在其生命周期中的不同状态。RuntimeGraph共有三个状态,表示不同状态下的同一个模型(待初始化、待构建和构建完成),
enum class GraphState {
NeedInit = -2, // 待初始化
NeedBuild = -1, // 待构建
Complete = 0, // 构建完成
};
在RuntimeGraph类中有一个变量会记录此刻模型的状态:
GraphState graph_state_ = GraphState::NeedInit;
三者的状态变换如下,依次表示待初始化,待构建和模型构建完成。

在初始情况下模型的状态graph_state_为NeedInit,表示模型目前待初始化。因此不能在此刻直接调用Build函数中的功能,而是需要在此之前先调用模型的Init函数,在初始化函数(Init)调用成功后会将模型的状态调整为NeedBuild.
// 如果图的状态已经是Complete,表示图已经构建完成,直接返回
if (graph_state_ == GraphState::Complete) {LOG(INFO) << "Model has been built already!";return;}
// 如果图的状态是NeedInit,表示图需要初始化,调用Init()函数进行初始化
if (graph_state_ == GraphState::NeedInit) {bool init_graph = Init();
LOG_IF(FATAL, !init_graph) << "Init graph failed!";
}
// 检查当前图的状态是否至少是NeedBuild,如果不是则报告错误
CHECK(graph_state_ >= GraphState::NeedBuild)
<< "Graph status error, current state is " << int(graph_state_);
以上构建(Build)函数中代码的目的是为了检查模型是否已经构建完成,即检查graph_state_ == GraphState::Complete。如果是表示模型已经构建完成,Build函数直接返回。如果模型此刻的状态是NeedInit, 首先需要先对这个模型进行初始化(先调用Init函数),再进行构建(Build函数)。
在Init函数中,当模型初始化后,要将模型的状态从NeedInit调整到NeedBuild(需要被构建),所以从Init函数返回后,Build函数便可以继续执行其中的代码。
bool RuntimeGraph::Init() {
...
...
graph_state_ = GraphState::NeedBuild;
return true;
}
4.2 构建计算图图关系
在检查完图的状态以确定是否需要初始化或构建,如果图处于 NeedBuild 状态(或刚刚完成初始化),则会继续执行构建过程,构建图中算子之间(前驱节点、后继节点)的关系后。代码如下在Build函数中实现。
// 构建图节点之间的连接关系
for (const auto ¤t_op : this->operators_) {
// 获取当前节点的所有输出节点的名称
const std::vector<std::string> &output_names = current_op->output_names;
for (const auto &kOutputName : output_names) {
// 在operators_maps_中查找对应的输出节点并插入到当前节点的output_operators中
// if 语句中的初始化器特性
if (const auto &output_op = this->operators_maps_.find(kOutputName);
output_op != this->operators_maps_.end()) {
current_op->output_operators.insert({kOutputName, output_op->second});
}
}
}
这段代码的作用是通过遍历计算图中的操作节点,构建每个节点之间的连接关系,进而形成完整的计算图。具体步骤如下:
-
遍历所有操作节点 (
this->operators_)this->operators_是一个包含所有计算节点的向量。代码遍历其中的每个节点 (current_op)。 -
获取当前节点的所有后继节点名称 (
output_names)每个节点可能会有多个后继节点,这些后继节点是由当前节点的输出操作数连接到其他节点的输入操作数来表示的。通过
current_op->output_names可以获得这些后继节点的名称列表。 -
查找并插入后继节点
- 对于每一个后继节点名称 (
kOutputName),代码会在operators_maps_中查找是否存在相应的节点。 - 如果找到了对应的后继节点 (
output_op),则将该节点插入到当前节点 (current_op) 的output_operators映射中。
- 对于每一个后继节点名称 (
通过这个过程,每个节点会知道它的后继节点是谁,从而构建了节点间的依赖关系,最终形成一个有向图。这些关系对于后续的计算流程至关重要,因为它们决定了计算节点的执行顺序。
补充:这里 if 语句的写法利用了 C++17 引入的if 语句中的初始化器特性。它允许在 if 语句的条件部分之前进行变量初始化。这使得代码更加紧凑,并且减少了变量的作用域,防止变量泄漏到 if 语句块之外。语法如下:
if (type var = initializer; condition) {
// 如果 condition 为真,则执行此处代码
} else {
// 如果 condition 为假,则执行此处代码
}
在这个语法中,type var = initializer; 是变量的初始化,condition 是基于这个变量的条件判断。
假设有以下的 operators_ 向量和 operators_maps_ 映射表:
std::vector<std::shared_ptr<RuntimeOperator>> operators_ = {INPUT, OP1, OP2, OP3, ADD, OUTPUT};
std::unordered_map<std::string, std::shared_ptr<RuntimeOperator>> operators_maps_ = {
{"INPUT", INPUT},
{"OP1", OP1},
{"OP2", OP2},
{"OP3", OP3},
{"ADD", ADD},
{"OUTPUT", OUTPUT}
};
INPUT->output_names 包含 {"OP1"}
OP1->output_names 包含 {"OP2", "OP3"}
OP2->output_names 包含 {"ADD"}
OP3->output_names 包含 {"ADD"}
ADD->output_names 包含 {"OUTPUT"}
OUTPUT->output_names 是空的
计算图如下:

for 循环会遍历 operators_ 中的每一个节点,并通过 if 语句中的初始化器特性为每个节点构建它们之间的连接关系。以input节点为例,current_op 指向 INPUT节点,然后input的output_names 包含 {"OP1"}。内层 for 循环遍历 output_names,使用 if 语句查找 "OP1" 对应的节点,如果operators_maps_ 中存在 "OP1",将 OP1 插入到 INPUT->output_operators 中。
通过上述操作,构建了以下的节点连接关系:
INPUT->output_operators 包含 {"OP1": OP1}
OP1->output_operators 包含 {"OP2": OP2, "OP3": OP3}
OP2->output_operators 包含 {"ADD": ADD}
OP3->output_operators 包含 {"ADD": ADD}
ADD->output_operators 包含 {"OUTPUT": OUTPUT}
OUTPUT->output_operators 为空
这使得 INPUT 的输出连接到 OP1,OP1 的输出连接到 OP2 和 OP3,OP2 和 OP3 的输出都连接到 ADD,最后 ADD 的输出连接到 OUTPUT,从而正确构建了计算图的关系。
4.3 初始化节点的输入和输出空间
在 Build 函数中初始化计算节点的输出张量空间是一个关键步骤,它确保了每个计算节点在图构建时就有足够的内存来存放计算结果。
为什么在Build阶段初始化输出张量空间,而不是在算子计算的时候再对输出空间初始化呢?在构建阶段提前申请输出张量的内存空间可以大大减少运行时的内存分配延迟。因为输出张量的大小通常是由图中的每个节点的计算结果决定的,提前分配可以减少在实际计算时的开销。
在构建计算图时,通常只需要初始化输出空间,因为输入空间的张量在图中是由前一个节点提供的,可以直接复用,从而避免重复分配和初始化内存。
void RuntimeOperatorUtils::InitOperatorInput(
const std::vector<std::shared_ptr<RuntimeOperator>> &operators) {
// 如果操作符列表为空,记录错误日志并返回
if (operators.empty()) {
LOG(ERROR) << "Operators for init input shapes is empty!";
return;
}
// 遍历每一个操作符
for (const auto &op : operators) {
// 如果当前操作符没有输入操作数,跳过这个操作符
if (op->input_operands.empty()) {
continue;
} else {
// 获取当前操作符的输入操作数映射表
const std::map<std::string, std::shared_ptr<RuntimeOperand>> &
input_operands_map = op->input_operands;
// 遍历每一个输入操作数并初始化相应的输入空间
for (const auto &[_, input_operand] : input_operands_map) {
// 检查输入操作数的数据类型,当前仅支持float32类型
const auto &type = input_operand->type;
CHECK(type == RuntimeDataType::kTypeFloat32)
<< "The graph only support float32 yet!";
// 获取输入操作数的形状
const auto &input_operand_shape = input_operand->shapes;
// 获取输入操作数对应的数据存储空间
auto &input_datas = input_operand->datas;
// 检查输入操作数的形状不为空
CHECK(!input_operand_shape.empty());
// 获取batch大小,即形状的第一个维度的大小
const int32_t batch = input_operand_shape.at(0);
CHECK(batch >= 0) << "Dynamic batch size is not supported!";
// 检查输入操作数的形状是否为支持的形状
CHECK(input_operand_shape.size() == 2 ||
input_operand_shape.size() == 4 ||
input_operand_shape.size() == 3)
<< "Unsupported tensor shape sizes: " << input_operand_shape.size();
// 如果数据空间已经初始化过,则检查其大小是否与batch大小一致
if (!input_datas.empty()) {
CHECK_EQ(input_datas.size(), batch);
} else {
// 否则,根据batch大小初始化数据存储空间
input_datas.resize(batch);
}
}
}
}
}
该函数主要负责为每个节点初始化输入张量的空间。如果某个节点的输入张量之前已经被分配了适当的内存(即来自前一个节点的输出),则不会重新分配内存,而是复用已存在的张量。函数会检查每个输入操作数的形状和数据是否符合预期,如果符合则直接使用。如果输入操作数的空间未初始化,则根据其形状和 batch 大小进行初始化。
void RuntimeOperatorUtils::InitOperatorOutput(
const std::vector<pnnx::Operator *> &pnnx_operators,
const std::vector<std::shared_ptr<RuntimeOperator>> &operators) {
// 检查输入的 pnnx 操作符和计算图中的操作符是否为空
CHECK(!pnnx_operators.empty() && !operators.empty());
// 确保 pnnx 操作符的数量与计算图中的操作符数量一致
CHECK(pnnx_operators.size() == operators.size());
// 遍历每个 pnnx 操作符
for (uint32_t i = 0; i < pnnx_operators.size(); ++i) {
// 获取当前 pnnx 操作符的输出操作数
const std::vector<pnnx::Operand *> operands = pnnx_operators.at(i)->outputs;
// 确保每个节点只有一个输出(暂时不支持多个输出)
CHECK(operands.size() <= 1) << "Only support one node one output yet!";
if (operands.empty()) {
continue; // 如果没有输出,跳过这个操作符
}
CHECK(operands.size() == 1) << "Only support one output in the KuiperInfer";
// 获取当前节点对应的 pnnx 操作数
pnnx::Operand *operand = operands.front();
const auto &runtime_op = operators.at(i);
CHECK(operand != nullptr) << "Operand output is null";
// 获取输出操作数的形状
const std::vector<int32_t> &operand_shapes = operand->shape;
// 获取当前操作符的输出张量空间
const auto &output_tensors = runtime_op->output_operands;
// 获取输出张量的 batch 大小
const int32_t batch = operand_shapes.at(0);
CHECK(batch >= 0) << "Dynamic batch size is not supported!";
// 确保输出张量的形状为支持的形状(2维、3维或4维)
CHECK(operand_shapes.size() == 2 || operand_shapes.size() == 4 ||
operand_shapes.size() == 3)
<< "Unsupported shape sizes: " << operand_shapes.size();
// 如果输出张量空间还未初始化
if (!output_tensors) {
// 创建并初始化输出操作数的空间
std::shared_ptr<RuntimeOperand> output_operand =
std::make_shared<RuntimeOperand>();
// 设置输出操作数的形状、数据类型和名称
output_operand->shapes = operand_shapes;
output_operand->type = RuntimeDataType::kTypeFloat32;
output_operand->name = operand->name + "_output";
// 根据输出张量的形状和 batch 大小初始化输出张量
for (int j = 0; j < batch; ++j) {
if (operand_shapes.size() == 4) {
// 4维张量
sftensor output_tensor = TensorCreate(
operand_shapes.at(1), operand_shapes.at(2), operand_shapes.at(3));
output_operand->datas.push_back(output_tensor);
} else if (operand_shapes.size() == 2) {
// 2维张量
sftensor output_tensor = TensorCreate((uint32_t) operand_shapes.at(1));
output_operand->datas.push_back(output_tensor);
} else {
// 3维张量
sftensor output_tensor = TensorCreate(
(uint32_t) operand_shapes.at(1), (uint32_t) operand_shapes.at(2));
output_operand->datas.push_back(output_tensor);
}
}
// 将初始化好的输出操作数赋值给当前操作符
runtime_op->output_operands = std::move(output_operand);
} else {
// output_tensors已经被初始化的情况,检查输出张量的形状和 pnnx::Operand 中定义的形状一致。
// 如果形状不匹配,则进行调整(即 reshape)以确保计算的正确性
......
}
}
}
这个函数的核心工作是根据 pnnx::Operand 的形状信息来初始化 RuntimeOperator 的输出张量空间。
在上面代码中,首先通过 pnnx_operators.at(i)->outputs 获取当前 pnnx::Operator 的输出操作数 operand, 根据这个pnnx计算数Operand中记录的Shape和Type信息来初始化初始化 RuntimeOperand。
如果 RuntimeOperator 中的输出张量空间 output_tensors尚未初始化,创建一个新的 RuntimeOperand对象。在 RuntimeOperand中,初始化形状、类型和名称等信息。
struct RuntimeOperand {
std::string name; /// 操作数的名称
std::vector<int32_t> shapes; /// 操作数的形状
std::vector<std::shared_ptr<Tensor<float>>> datas; /// 存储操作数
RuntimeDataType type = RuntimeDataType::kTypeUnknown; /// 操作数的类型
};
然后根据输出张量的形状operand_shapes和 batch 大小初始化输出张量,为每个批次创建一个输出张量,并将这些张量存储到 output_operand->datas 中。创建的张量数量等于 batch_size,每个张量的维度依据 operand_shapes来确定。对于一个计算算子runtime_op来说,它的输出张量数组的长度等于batch_size个,所以在循环中需要对batch_size个输出张量进行创建(创建的时候需要依据operand_shapes, 从pnnx::operand中得到的维度)。
最后将初始化好的 RuntimeOperand绑定到 RuntimeOperator 的 output_operands 中,确保计算节点可以正确存储和访问输出数据。通过这些步骤,InitOperatorOutput 函数确保了每个计算节点的输出张量空间按照 pnnx 模型中定义的形状和类型进行正确初始化,以便在后续的推理过程中使用。
4.4 计算图执行顺序
深度学习模型是一个有向无环图。对于有向图结构中的节点,可以认为是深度学习模型中的计算节点(算子),而有向图结构中的边可以认为是算子之间连接和前后依赖关系。计算图的执行顺序由节点之间的依赖关系决定,通过拓扑排序确保每个节点在依赖节点执行完毕后再执行。

上图计算图中,一共有三个计算节点conv1, conv2和conv3以及两条边。这些连接的边指定了节点执行的先后顺序,必须先执行conv1,再执行conv2或conv3。**在 DAG 中,节点的执行顺序可以通过拓扑排序确定。拓扑排序会确保每个节点在其所有依赖的输入节点都已经执行完毕后才开始执行。**也就是说,如果节点conv2依赖于节点conv1的输出,那么conv1必须先于conv2执行。因此执行节点顺序有以下两种:
- conv1->conv2->conv3
- conv1->conv3->conv2
4.4.1 基于深度优先的拓扑排序
RuntimeGraph::ReverseTopo函数实现了对计算图进行逆向拓扑排序的功能。这种排序方式从计算图的末端节点开始,逐步反向遍历并将节点按拓扑顺序存储在 topo_operators_ 容器中。最后还需要reverse。
void RuntimeGraph::ReverseTopo(const std::shared_ptr<RuntimeOperator> &root_op) {
CHECK(root_op != nullptr) << "current operator is nullptr";
// 标记当前节点已被访问过,避免重复遍历。
root_op->has_forward = true;
// 获取当前节点的所有输出节点,这些节点是当前节点的下游节点。
const auto &next_ops = root_op->output_operators;
// 遍历所有输出节点(即当前节点的下游节点)
for (const auto &[_, op] : next_ops) {
if (op != nullptr) { // 确保下游节点不为空
if (!op->has_forward) { // 如果下游节点还未被访问过
this->ReverseTopo(op); // 递归调用 ReverseTopo,继续对下游节点进行拓扑排序
}
}
}
// 再次遍历所有输出节点,确保所有下游节点都已被访问。
for (const auto &[_, op] : next_ops) {
// 确保每个下游节点的 has_forward 都被设置为 true,验证排序的正确性。
CHECK_EQ(op->has_forward, true);
}
// 将当前节点加入到拓扑排序列表 topo_operators_`中。
// 由于是递归调用的最后一步,因此当前节点会在其所有下游节点之后被添加。
this->topo_operators_.push_back(root_op);
}
- 选定一个入度为零的节点(
current_op),入度为零指的是该节点没有前驱节点或所有前驱节点已经都被执行过,在选定的同时将该节点的已执行标记置为True,并将该节点传入到ReverseTopo函数中; - 遍历1步骤中节点的后继节点(
current_op->output_operators); - 如果1的某个后继节点没有被执行过(已执行标记为
False),则递归将该后继节点传入到ReverseTopo函数中; - 第2步中的遍历结束后,将当前节点放入到执行队列(
topo_operators_)中。
当该函数结束后,对执行队列中的排序结果做逆序就得到最终的拓扑排序的结果,如下所示,在Build函数中,当计算图构建完成后进行拓扑排序。
// 构建拓扑顺序
topo_operators_.clear();
for (const auto &[_, op] : operators_maps_) {
// 根据输入节点构建拓扑排序
if (op->type == "pnnx.Input" && !op->has_forward) {
this->ReverseTopo(op);
}
}
CHECK(topo_operators_.size() == operators_.size())
<< "Build wrong topo queue";
std::reverse(topo_operators_.begin(), topo_operators_.end());
4.4 2 基于广度优先的拓扑排序
void RuntimeGraph::BFSTopoSort() {
// 创建一个哈希表,用于存储每个节点的入度(即有多少个边指向该节点)
std::unordered_map<std::shared_ptr<RuntimeOperator>, int> in_degree;
// 创建一个队列,用于广度优先搜索(BFS)
std::queue<std::shared_ptr<RuntimeOperator>> q;
// 初始化所有节点的入度为0
for (const auto &[_, op] : operators_maps_) {
in_degree[op] = 0; // 所有节点初始入度为0
}
// 计算每个节点的实际入度
for (const auto &[_, op] : operators_maps_) {
for (const auto &[_, next_op] : op->output_operators) {
in_degree[next_op]++; // 对每个指向的节点的入度加1
}
}
// 将所有入度为0的节点加入队列
for (const auto &[op, degree] : in_degree) {
if (degree == 0) {
q.push(op); // 入度为0的节点可以作为排序的起点
}
}
// 清空原有的拓扑顺序
this->topo_operators_.clear();
// 广度优先搜索
while (!q.empty()) {
// 取出队列中的节点
auto current_op = q.front();
q.pop();
// 将当前节点添加到拓扑顺序中
this->topo_operators_.push_back(current_op);
// 遍历当前节点的所有输出节点
for (const auto &[_, next_op] : current_op->output_operators) {
in_degree[next_op]--; // 对每个输出节点的入度减1
if (in_degree[next_op] == 0) {
q.push(next_op); // 如果入度变为0,将该节点加入队列
}
}
}
// 检查是否存在环
if (topo_operators_.size() != operators_maps_.size()) {
LOG(FATAL) << "The graph has a cycle!"; // 日志记录错误
throw std::runtime_error("The graph has a cycle!"); // 抛出异常
}
}
在计算图中,广度优先搜索(BFS)和深度优先搜索(DFS)可以用来实现不同的图操作,尤其是在拓扑排序和图遍历方面。使用 BFS(Kahn’s Algorithm)通常更直观,因为它直接处理入度为零的节点。使用 DFS 拓扑排序时,通常会在回溯时收集节点,从而构建排序。
五、计算图的计算
5.1 Layer类(算子的计算)
经过上面的Init和Build已经构建了一个完整的计算图,包括了输入、输出节点以及计算节点等。计算节点是RuntimeOperator, 具体的结构定义如下的代码所示:
/// 计算图中的计算节点
struct RuntimeOperator {
virtual ~RuntimeOperator();
bool has_forward = false;
std::string name; /// 计算节点的名称
std::string type; /// 计算节点的类型
std::shared_ptr<Layer> layer; /// 节点对应的计算Layer
std::vector<std::string> output_names; /// 节点的输出节点名称
std::shared_ptr<RuntimeOperand> output_operands; /// 节点的输出操作数
std::map<std::string, std::shared_ptr<RuntimeOperand>> input_operands; /// 节点的输入操作数
std::vector<std::shared_ptr<RuntimeOperand>> input_operands_seq; /// 节点的输入操作数,顺序排列
std::map<std::string, std::shared_ptr<RuntimeOperator>> output_operators; /// 输出节点的名字和节点对应
std::map<std::string, RuntimeParameter*> params; /// 算子的参数信息
std::map<std::string, std::shared_ptr<RuntimeAttribute>> attribute; /// 算子的属性信息,内含权重信息
};
RuntimeOperator记录了与该节点相关的类型、名称,以及输入输出数等信息。其中layer变量,它表示与计算节点关联的算子,也就是进行具体计算的实施者。
通过访问RuntimeOperator的输入数(input_operand),layer可以获取计算所需的输入张量数据,并根据layer各派生类别中定义的计算函数(forward)对输入张量数据进行计算。计算完成后,计算结果将存储在该节点的输出数(output_operand)中。
Layer类,它是所有算子的父类,模型中的算子都需要继承于该类作为派生类并重写其中的计算函数(forward),定义如下:
class Layer {
public:
explicit Layer(std::string layer_name) : layer_name_(std::move(layer_name)) {}
virtual ~Layer() = default;
/**
* Layer的执行函数
* @param inputs 层的输入
* @param outputs 层的输出
* @return 执行的状态
*/
virtual InferStatus Forward(
const std::vector<std::shared_ptr<Tensor<float>>>& inputs,
std::vector<std::shared_ptr<Tensor<float>>>& outputs);
/**
* Layer的执行函数
* @param current_operator 当前的operator
* @return 执行的状态
*/
virtual InferStatus Forward();
protected:
std::weak_ptr<RuntimeOperator> runtime_operator_; //弱指针,指向当前层所使用的运行时算子,用于管理层的执行
std::string layer_name_; /// Layer的名称
};
以上的代码定义了Layer类的构造函数,它只需要一个layer_name变量来指定该算子的名称。带有参数的Forward方法,它是算子中定义的计算函数。这个函数有两个参数,分别是inputs和outputs。它们是在计算过程中所需的输入和输出张量数组。每个算子的派生类都需要重写这个带参数的Forward方法,并在其中定义计算的具体逻辑。
在Layer类中有两个成员变量,一个是在构造函数中指定的算子名称 layer_name,另一个是与该算子关联的计算节点变量 RuntimeOperator。在 RuntimeOperator中也的定义了layer(std::shared_ptr layer;)。RuntimeOperator与该节点对应的 Layer相关联,而 Layer也关联了它所属的 RuntimeOperator,因此它们之间是双向关联的关系。
对于 Layer类中不带参数的 Forward方法。这个方法是所有算子的父类方法,它的作用是准备输入和输出数据,并使用这些数据调用每个派生类算子中各自实现的计算过程的函数,即带参数的 Forward 函数。
InferStatus Layer::Forward() {
LOG_IF(FATAL, this->runtime_operator_.expired()) << "Runtime operator is expired or nullptr";
// 获取相关的计算节点
const auto& runtime_operator = this->runtime_operator_.lock();
// 获取当前运行时算子所需的输入操作数
const std::vector<std::shared_ptr<RuntimeOperand>>& input_operand_datas =
runtime_operator->input_operands_seq;
// 准备节点layer计算所需要的输入
std::vector<std::shared_ptr<Tensor<float>>> layer_input_datas;
// 遍历所有输入操作数,并将其中的每个数据张量添加到 layer_input_datas 中
for (const auto& input_operand_data : input_operand_datas) {
for (const auto& input_data : input_operand_data->datas) {
layer_input_datas.push_back(input_data);
}
}
// 获取当前运行时算子的输出操作数
const std::shared_ptr<RuntimeOperand>& output_operand_datas =
runtime_operator->output_operands;
CHECK(!layer_input_datas.empty())
<< runtime_operator->name << " Layer input data is empty";
CHECK(output_operand_datas != nullptr && !output_operand_datas->datas.empty())
<< "Layer output data is empty";
// 调用当前层的 Forward 函数,执行计算过程
// 计算结果将存储在 current_op->output_operands->datas 中
InferStatus status = runtime_operator->layer->Forward(
layer_input_datas, output_operand_datas->datas);
return status; // 返回执行状态
}
在Layer类的不带参数的Forward方法中,首先获取与该Layer相对应的计算节点RuntimeOperator。它们之间是双向关联的关系,一个算子对应一个计算节点(RuntimeOperator),一个计算节点对应一个算子(Layer)。
从计算节点中得到该节点对应的输入数input_operand_datas以及该输入数存储的张量数据layer_input_datas。然后从计算节点中取出对应的输出数output_operand_datas.在以上的步骤中,从计算节点RuntimeOperator中获取了相关的输入数和输出数,然后使用对应的输入和输出张量去调用子类算子各自实现的,带参数的Forward函数,执行前向传播计算。计算结果将存储在 output_operand_datas->datas 中。
Foward函数中实现了在神经网络中执行层的前向传播操作,通过提取输入数据、执行计算,并将结果存储在指定的输出空间中。
5.2 算子注册机制
算子注册表是一个用于管理算子类型和相关创建函数的数据结构。它使得系统能够在运行时动态地创建和管理算子实例,而不需要在编译时硬编码所有的算子类型。通过算子注册表,计算图能够动态地创建、管理和使用不同类型的算子,使得计算图的构建和执行更加灵活和可扩展。算子注册表的机制使得系统可以轻松地添加新类型的算子,而不需要修改计算图的核心实现。
通过将算子类型和创建函数的映射保存在注册表中,可以在运行时根据需求创建不同类型的算子,而不需要在编译时确定所有类型。这种设计模式使得系统的扩展变得更加容易,并支持将新的算子类型无缝地集成到现有的计算框架中。
在KuiperInfer中算子注册机制使用单例模式和工厂模式。首先,在全局范围内创建一个唯一的注册表registry,它是一个map类型的对象。**这个注册表的键是算子的类型,而值是算子的初始化过程。**开发者完成一个算子的设计后,需要通过特定的注册机制将算子写入全局注册表中。这可以通过在注册表中添加键值对来实现。算子的类型作为键,算子的初始化过程作为值。这样,当需要使用某个算子时,可以根据算子的类型从全局注册表中方便地获取对应的算子。
在实现上单例模式确保了只有一个全局注册表实例,并且可以在代码的任何地方访问该注册表。工厂模式则负责根据算子的类型返回相应的算子实例。这种注册机制的设计使得推理框架能够感知到开发者已经实现的算子,并且能够方便地调用和使用这些算子。
class LayerRegisterer {
public:
// Creator是一个函数指针类型,定义了用于创建Layer的函数签名
// 等价于using Creator = ParseParameterAttrStatus (*)(const std::shared_ptr<RuntimeOperator> &op, std::shared_ptr<Layer> &layer);
typedef ParseParameterAttrStatus (*Creator)
(const std::shared_ptr<RuntimeOperator> &op,
std::shared_ptr<Layer> &layer);
// CreateRegistry是一个映射,存储算子类型到其创建函数的映射
typedef std::map<std::string, Creator> CreateRegistry;
public:
/**
* 向注册表注册算子类型及其创建函数
* @param layer_type 算子的类型,用于标识不同的算子
* @param creator 处理该类型算子的创建函数
*/
static void RegisterCreator(const std::string &layer_type, const Creator &creator);
/**
* 根据给定的RuntimeOperator创建对应的Layer对象
* @param op 包含了初始化Layer所需信息的RuntimeOperator对象
* @return 初始化后的Layer对象
*/
static std::shared_ptr<Layer> CreateLayer(const std::shared_ptr<RuntimeOperator> &op);
/**
* 返回算子的注册表
* @return 包含所有已注册算子类型及其创建函数的映射
*/
static CreateRegistry &Registry();
/**
* 返回所有已被注册的算子类型
* @return 包含所有已注册算子类型的字符串列表
*/
static std::vector<std::string> layer_types();
};
5.2.1 全局算子注册表
以上代码中的Creator是一个函数指针,它指向一个函数,该函数接受两个参数:RuntimeOperator的共享指针和Layer的共享指针,并返回一个ParseParameterAttrStatus类型的状态码。用于某一类算子的初始化过程,不同的算子具有不同的实例化函数,但是都需要符合要求:
typedef ParseParameterAttrStatus (*Creator)
(const std::shared_ptr<RuntimeOperator> &op,std::shared_ptr<Layer> &layer);
typedef可以使用using替换:
using Creator = ParseParameterAttrStatus (*)(const std::shared_ptr<RuntimeOperator> &op, std::shared_ptr<Layer> &layer);
这里的Creator是一个函数指针类型,用于定义某个类型算子的创建过程。当需要使用某个类型的算子时,可以从CreateRegistry类型的注册表中获取该算子的创建过程。
typedef std::map<std::string, Creator> CreateRegistry;
// 键:"ReLU",值:ReLUInstance
CreateRegistry它是一个std::map,将字符串(算子类型)映射到对应的Creator函数指针。这种映射允许根据算子类型查找对应的创建函数。在Registry()函数中实现全局注册表,其代码如下:
// 得到全局注册算子表 单例模式的懒汉模式
LayerRegisterer::CreateRegistry& LayerRegisterer::Registry() {
static CreateRegistry* kRegistry = new CreateRegistry(); // 算子注册表
CHECK(kRegistry != nullptr) << "Global layer register init failed!";
return *kRegistry;
}
这里使用了线程安全的懒汉式单例模式实现,并且利用了C++11标准中的Magic Static(局部静态变量)特性。这个两个保证了全局注册表registry变量是一个唯一的实例kRegistry,无论该函数被调用多少次,都会返回同一个对象。
5.2.2 RegisterCreator()算子注册
// 注册算子函数
void LayerRegisterer::RegisterCreator(const std::string &layer_type,
const Creator &creator) {
CHECK(creator != nullptr);
CreateRegistry ®istry = Registry(); // 获取全局的算子注册表
CHECK_EQ(registry.count(layer_type), 0)
<< "Layer type: " << layer_type << " has already registered!";
registry.insert({layer_type, creator}); // 将新的算子及其对应的创建函数指针插入到注册表中
}
算子注册函数RegisterCreator,这个函数接受两个参数:算子的类型layer_type和Creator(函数指针, 算子的创建过程)类型。
这个函数的作用是将算子和对应的创建函数注册到全局注册表中。它首先检查创建函数是否有效,并确保该算子尚未被注册,然后将算子类型和创建函数添加到全局注册表中。这样可以动态地创建不同的算子,而不需要在代码中显式地实例化每个算子。
5.2.3 LayerRegisterer::CreateLayer()实例化Layer
Layer类用于表示计算图中的一个计算层(算子的计算逻辑)。它封装了层的基本属性(如名称、权重、偏置)、执行计算的逻辑以及与之关联的执行算子。通过 Forward 方法,具体的计算逻辑可以在派生类中实现,从而支持不同类型的算子。
CreateLayer 方法根据给定的 RuntimeOperator 对象的类型,从全局注册表中获取对应的 Creator 函数,并使用该函数创建一个 Layer 实例,代码如下所示:
std::shared_ptr<Layer> LayerRegisterer::CreateLayer( // 通过算子参数op来初始化Layer
const std::shared_ptr<RuntimeOperator> &op) {
CreateRegistry ®istry = Registry();
const std::string &layer_type = op->type;
LOG_IF(FATAL, registry.count(layer_type) <= 0) << "Can not find the layer type: " << layer_type;
const auto &creator = registry.find(layer_type)->second;
LOG_IF(FATAL, !creator) << "Layer creator is empty!";
std::shared_ptr<Layer> layer;
// creator是一个函数指针,指向某一类算子的初始化过程,不同的算子具有不同的实例化函数
const auto &status = creator(op, layer);
LOG_IF(FATAL, status != ParseParameterAttrStatus::kParameterAttrParseSuccess)
<< "Create the layer: " << layer_type
<< " failed, error code: " << int(status);
return layer;
}
CreateLayer用于实例化Layer,它接受一个名为RuntimeOperator的参数作为输入,该参数包含了算子的所有权重和参数信息。先获得全局注册表registry,检查该算子类型layer_type是否已经被注册到全局注册表中,如果已经被注册过,则获取到该算子类型对应的创建过程creator。 creator是一个算子的创建过程函数,它的传入参数为包含所有参数和权重等信息的RuntimeOperator以及一个待初始化的算子layer。
5.2.4 RuntimeGraph::CreateLayer(Build中调用)
在 RuntimeGraph 中:遍历所有的 RuntimeOperator 对象,并为每个算子(除输入和输出节点外)使用 CreateLayer 函数创建和初始化 Layer 对象。将创建的 Layer 对象与对应的 RuntimeOperator 关联起来。这里使用的是RuntimeGraph::CreateLayer函数,其内部是调用的LayerRegisterer::CreateLayer()函数:
std::shared_ptr<Layer> RuntimeGraph::CreateLayer(
const std::shared_ptr<RuntimeOperator>& op) {
LOG_IF(FATAL, !op) << "Operator is empty!";
// 使用 LayerRegisterer 的 CreateLayer 方法来创建一个 Layer 实例。
// 这会根据 RuntimeOperator 提供的算子类型从注册表中找到合适的创建函数 (Creator)。
// 并用它来实例化 Layer。
auto layer = LayerRegisterer::CreateLayer(op);
// 检查创建的 Layer 对象是否为空。如果为空,记录错误并终止程序。
LOG_IF(FATAL, !layer) << "Layer init failed " << op->type;
// 返回创建好的 Layer 对象。
return layer;
}
在计算图的构建过程中(Build()函数),为每个算子(除了输入和输出节点)创建并初始化 Layer 对象,并设置其运行时算子,与 RuntimeOperator 关联,完成初始化。
for (const auto &kOperator : this->operators_) {
// 除了输入和输出节点,都创建layer
if (kOperator->type != "pnnx.Input" && kOperator->type != "pnnx.Output") {
std::shared_ptr<Layer> layer = RuntimeGraph::CreateLayer(kOperator);
CHECK(layer != nullptr)
<< "Layer " << kOperator->name << " create failed!";
if (layer) {
kOperator->layer = layer;
layer->set_runtime_operator(kOperator);
}
}
}
到这里Build()函数的功能才全部实现完成!
算子注册、创建和使用整体流程:
1.注册阶段:
- 定义并实现不同类型算子的创建函数 (
Creator)和全局算子注册表std::map<std::string, Creator> CreateRegistry。 - 使用
LayerRegisterer::RegisterCreator将算子类型和创建函数注册到全局注册表中。
2.创建阶段:
- 使用
RuntimeGraph::CreateLayer方法,通过RuntimeOperator获取相应的Layer创建函数并实例化Layer对象。
3.使用阶段:
- 在计算图中,Build()中将每个操作符的
Layer进行实例化,并将Layer与RuntimeOperator进行关联,以便进行后续的计算操作。
5.2.5 LayerRegistererWrapper算子注册
为了简化算子类型的注册过程,使其更具自动化,定义了LayerRegistererWrapper包装器类。
class LayerRegistererWrapper {
public:
/**
* @brief 构造函数,用于在构造时自动将算子类型及其创建函数注册到全局注册表中。
*
* @param layer_type 要注册的算子类型的名称。
* @param creator 对应算子类型的创建函数指针(Creator),用于创建该类型的 Layer 实例。
*/
LayerRegistererWrapper(const std::string &layer_type,
const LayerRegisterer::Creator &creator) {
// 调用 LayerRegisterer 的静态方法 RegisterCreator,将算子类型及其创建函数注册到全局注册表中。
LayerRegisterer::RegisterCreator(layer_type, creator);
}
};
这个工具类只有一个构造函数,该构造函数接受算子的类型和该算子对应的创建过程作为参数。当创建 LayerRegistererWrapper 类的实例时,会调用 LayerRegisterer::RegisterCreator 方法,将指定的算子类型和对应的创建函数注册到全局注册表中。
开发者只需在创建实例时传入算子类型和对应的创建函数,即可自动完成注册,无需手动调用注册函数。这减少了重复代码和手动注册的复杂性。这个机制常用于插件式架构或者需要动态加载组件的系统中,使得系统具有良好的扩展性和灵活性。
六、ReLU算子注册
ReLU,全称为 Rectified Linear Unit,是一种广泛应用于神经网络中的激活函数。ReLU 的主要特点是简单、高效,并且在实践中通常表现出优越的性能,ReLU 的数学表达式非常简单:
R
e
L
U
(
x
)
=
m
a
x
(
x
,
0
)
ReLU(x)=max(x,0)
ReLU(x)=max(x,0)
ReLU 函数会将所有小于 0 的输入直接变为 0,而将大于 0 的输入保留为原值。
要注册一个 ReLU 算子,首先需要实现 ReLU 的创建函数,然后通过 LayerRegistererWrapper 将其注册到算子注册表中。
using NonParamLayer = Layer; // 别名
class ReluLayer : public NonParamLayer {
public:
// 构造函数,调用基类 NonParamLayer 的构造函数,并传递激活函数名称 "Relu"
ReluLayer() : NonParamLayer("Relu") {}
// 覆盖基类的 Forward 函数,用于执行 ReLU 层的前向计算
InferStatus Forward(
const std::vector<std::shared_ptr<Tensor<float>>>& inputs,
std::vector<std::shared_ptr<Tensor<float>>>& outputs) override;
// 静态函数,用于实例化 ReLU 层,并将其与 RuntimeOperator 关联
static ParseParameterAttrStatus GetInstance(
const std::shared_ptr<RuntimeOperator>& op,
std::shared_ptr<Layer>& relu_layer);
};
ReluLayer继承自 NonParamLayer,表示是一个没有可学习参数的算子(不像卷积层那样需要卷积核),用于实现 ReLU 激活函数。Forward主要负责前向计算,并且通过静态函数 GetInstance 来实现与运行时算子(RuntimeOperator)的关联,以便在计算图中创建和使用 ReLU 算子。
6.1 构造函数 ReluLayer()
调用 NonParamLayer(Layer)的构造函数,并传递字符串 "Relu",用于指定该层的类型名称。这个名称通常用于调试、日志记录或层的注册机制中。
6.2 Forward()计算函数
Forward 函数是 ReluLayer的主要计算函数,用于执行 ReLU 的前向传播。它覆盖了基类的 Forward 函数,接受输入张量 inputs并输出结果张量 outputs。ReLU 的计算过程将在此函数中实现:对每个输入张量元素执行 max(0, x) 操作。
InferStatus ReluLayer::Forward(
const std::vector<std::shared_ptr<Tensor<float>>> &inputs, // 输入的张量列表
std::vector<std::shared_ptr<Tensor<float>>> &outputs) { // 输出的张量列表
// 检查输入张量数组是否为空
if (inputs.empty()) { LOG(ERROR) << "The input tensor array in the relu layer is empty";
return InferStatus::kInferFailedInputEmpty;
}
// 检查输入和输出的张量数组大小是否匹配
if (inputs.size() != outputs.size()) {
LOG(ERROR) << "The input and output tensor array size of the relu layer do "
"not match";
return InferStatus::kInferFailedInputOutSizeMatchError;
}
const uint32_t batch_size = inputs.size(); // 获取批处理大小
for (uint32_t i = 0; i < batch_size; ++i) { // 遍历每个输入和输出张量对,进行检查
const sftensor &input_data = inputs.at(i); // 获取当前输入张量
const sftensor &output_data = outputs.at(i); // 获取当前输出张量
// 检查当前输入张量是否为空或未初始化
if (input_data == nullptr || input_data->empty()) {
LOG(ERROR)<< "The input tensor array in the relu layer has an empty tensor "
<< i << " th";
return InferStatus::kInferFailedInputEmpty;
}
// 如果输出张量已初始化且非空,检查输入和输出的形状是否匹配
if (output_data != nullptr && !output_data->empty()) {
if (input_data->shapes() != output_data->shapes()) {
LOG(ERROR) << "The input and output tensor shapes of the relu " "layer do not match "
<< i << " th";
return InferStatus::kInferFailedInputOutSizeMatchError;
}
}
}
// 遍历每个输入和输出张量对,执行ReLU操作
for (uint32_t i = 0; i < batch_size; ++i) {
const std::shared_ptr<Tensor<float>> &input = inputs.at(i); // 获取当前输入张量
CHECK(input == nullptr || !input->empty())
<< "The input tensor array in the relu layer has an empty tensor " << i<< " th";
std::shared_ptr<Tensor<float>> output = outputs.at(i); // 获取当前输出张量
// 如果输出张量为空或未初始化,分配一个与输入张量形状相同的新张量
if (output == nullptr || output->empty()) {
DLOG(ERROR) << "The output tensor array in the relu layer has an empty tensor "
<< i << " th";
output = std::make_shared<Tensor<float>>(input->shapes()); // 分配新张量
outputs.at(i) = output; // 将新张量存入输出列表中
}
// 断言输入和输出的形状匹配
CHECK(output->shapes() == input->shapes())
<< "The input and output tensor shapes of the relu layer do not match "<< i << " th";
// 遍历输入张量中的每个元素,执行ReLU操作并存储到输出张量中
for (uint32_t j = 0; j < input->size(); ++j) {
float value = input->index(j); // 获取当前输入元素的值
output->index(j) = value > 0.f ? value : 0.f; // 计算ReLU输出
}
}
return InferStatus::kInferSuccess; // 返回成功状态
}
该函数首先输入张量列表 inputs是否为空,并判断输入张量和输出张量的数量是否一致,如果不一致则返回失败状态 。
ReLU算子不会改变输入张量的大小,也就是说输入和输出张量的维度应该是相同的。对于每个输入输出张量对,函数检查输入张量是否为空或未初始化,并确保如果输出张量已经初始化,**则它的形状必须与输入张量匹配。**若不满足这些条件,则相应地返回失败状态。
使用一个for循环逐个处理一个大小为batch_size的输入张量数组
// 遍历输入张量中的每个元素,执行ReLU操作并存储到输出张量中
for (uint32_t j = 0; j < input->size(); ++j) {
float value = input->index(j); // 获取当前输入元素的值
output->index(j) = value > 0.f ? value : 0.f; // 计算ReLU输出
}
在确保输入输出张量有效后,使用一个for循环逐个处理一个大小为batch_size的输入张量数组,在内存for循环中函数逐个处理输入张量的每个元素,计算 ReLU激活函数的结果并存储到对应的输出张量中。ReLU函数的核心计算为 output = max(0, input),即当输入值小于等于 0 时,输出为 0,否则输出为输入值本身。
6.3 GetInstance()实例化ReluLayer
GetInstance 是一个静态成员函数,用于创建和初始化一个 ReluLayer实例。它接收一个 RuntimeOperator(包含算子的信息)和一个 Layer的智能指针 relu_layer。此函数的目的是将传入的 RuntimeOperator转化为对应的 ReluLayer实例,并将其与算子关联。
ParseParameterAttrStatus ReluLayer::GetInstance(
const std::shared_ptr<RuntimeOperator> &op, // 输入的RuntimeOperator对象
std::shared_ptr<Layer> &relu_layer) { // 输出的ReluLayer对象
CHECK(op != nullptr) << "Relu operator is nullptr";
// 创建一个新的ReluLayer实例,并将其赋值给输出参数relu_layer
relu_layer = std::make_shared<ReluLayer>();
return ParseParameterAttrStatus::kParameterAttrParseSuccess;
}
ReluLayer::GetInstance是ReLU算子的初始化过程,该初始化函数符合之前Creator函数指针的参数类型、参数个数和返回值要求。该初始化函数对传入的layer进行初始化,并返回表示成功的状态码。
Creator函数指针定义如下:
typedef ParseParameterAttrStatus (*Creator)
(const std::shared_ptr<RuntimeOperator> &op, std::shared_ptr<Layer> &layer);
6.4 LayerRegistererWrapper注册ReLU算子
// 使用 LayerRegistererWrapper 工具类将 ReLU 算子注册到全局注册表中
// 第一个参数 "nn.ReLU" 是算子的类型名,用于标识 ReLU 算子
// 第二个参数 ReluLayer::GetInstance 是注册的创建函数,用于实例化 ReluLayer
LayerRegistererWrapper kReluGetInstance("nn.ReLU", ReluLayer::GetInstance);
使用LayerRegistererWrapper工具类将特定的算子(如 ReLU)注册到全局注册表中,简化了注册的过程。
参数介绍:
-
nn.ReLU:这是注册时使用的算子类型的名称字符串。在以后需要创建 ReLU 层时,系统会通过这个类型名找到对应的创建函数
-
ReluLayer::GetInstance:这是一个静态方法指针,指向用于创建 ReluLayer 实例的函数。在算子创建时,这个方法会被调用,实例化
ReluLayer。
ReLU注册机制:
- 注册阶段:当 LayerRegistererWrapper kReluGetInstance(“nn.ReLU”, ReluLayer::GetInstance);被执行时,
"nn.ReLU"和ReluLayer::GetInstance这一对键值被添加到全局注册表中。 - 创建阶段:在
build函数执行时,如果 kOperator->type是 “nn.ReLU”,那么 RuntimeGraph::CreateLayer(kOperator)会根据"nn.ReLU"从注册表中查找对应的创建函数(即 ReluLayer::GetInstance),并调用它来创建一个 ReluLayer对象。 - 最终结果:创建的 ReluLayer 对象被存储在 kOperator->layer中,并与当前的 RuntimeOperator 关联起来。通过这种注册和动态创建机制,计算图中的每个算子都能正确地被映射到具体的 Layer对象,将 Layer与算子关联,并设置算子的 runtime_operator,形成完整的计算流程。


















 670
670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











