







定义
由点集和边集形成的一个东西..
比如 A ——————————B
| |
| |
| |
C——————————D
当然C和B也有可能有连接 A和D也有可能有连接
邻接表法
A:B(可以在括号里封装一个AB间的距离),C
B:C,D
C:A,D
D:B,C
矩阵法
A | B | C | D | |
A | 0 | AB距离 | 无穷(不存在) | |
B | 0 | |||
C | 0 | |||
D | 0 |
除了这两种,还有N多种....
所以表示和算法,要找到普适、常用、熟悉的。
就是用一招鲜,吃遍天
用自己的模板套所有东西
学会了给妈妈做蛋炒饭
就要学会 “ 为了建设美好中国,先给妈妈做一顿蛋炒饭”
图的表达
左神在课程里教的是点集和边集表达...
但是C语言实现麻烦的一批...
所以我就问chatgpt哪种方式最值得一学
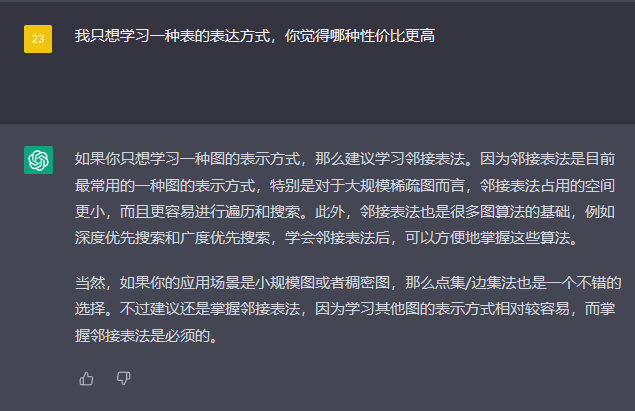
考研书上对邻接表法的定义是这样的:
对图G中的每个顶点Vi建立一个单链表,第i个单链表中的节点表示依附于顶点Vi的边,这个单链表就称为顶点Vi的边表(有向图叫出边表)。边表的头指针和顶点的数据信息采用顺序存储(称为顶点表),所以在邻接表中存在两种节点:顶点表节点和边表节点。
// 邻接表的节点
struct AdjListNode {
int dest; // 目标顶点
int weight; // 两点之间的权重
struct AdjListNode* next; // 指向下一个邻接节点的指针
};
// 邻接表的头结点
struct AdjList {
struct AdjListNode* head; // 邻接链表的头指针
};
// 图的结构体
struct Graph {
int V; // 顶点数/链表数
struct AdjList* array; // 邻接链表的数组
};按链表的知识来看。
AdjListNode就是节点, 其中包括的value有 dest(下一顶点的value)和weight(两点间的权重),而AdjListNode* next是指向下一节点的指针。
ArrayList是链表结构体,存储头节点,就能顺着找到整条列表。
Graph是图的结构体,其中包含两部分:V是顶点数量。array是存储链表的数组。
就是 类似于
struct AdjList* array = (struct AdjList*)malloc( V * sizeof(struct AdjList));
// V大小的动态数组, 存储 AdjList型的变量假设这样一个邻接表
0: 1->4
1: 0->2->3->4
2: 1->3
3: 1->2->4
4: 0->1->3
这里面的V就是5。因为存储了5个顶点,每个顶点延伸出一条链表.
比如0节点,其延伸出的链表就是
0->1->4 其中0作为头指针
遍历姿势
图的宽度优先遍历(BFS)
比如 A ——————————B
| |
| |
| |
C——————————D
回到小红图
宽度优先遍历类似于二叉树按层遍历
就是说 谁离得近 我先遍历谁
这里面的顺序就应该是 A B C D
当然因为不知道B和C和A之间边的权重 所以也可能是 A C B D
看起来是先进先出的结构
那就用队列来实现
A进队 判断他的下一节点 B、C
B、C进队,但是在无向图里, A也是B、C的下一节点,还能让A再进队吗?显然不能。
于是创建一个存储机制让他记住 A已经输出完了
coding~
还是 先写这个队列所需的一些基本操作
struct QueueNode{
struct AdjListNode* node;
struct QueueNode* next;
};
struct Queue{
struct QueueNode* front;
struct QueueNode* rear;
};
// 新建队列节点
struct Queue* newQueueNode(struct AdjListNode* node) {
struct Queue* newNode = (struct Queue*)malloc(sizeof(struct Queue));
newNode->data = node;
newNode->next = NULL;
return newNode;
}
//入队
void enqueue(struct Queue* queue, struct AdjListNode* node){
// 定义一个队列节点类型的newnode
struct QueueNode* newnode = (struct QueueNode*)malloc(sizeof(struct QueueNode));
newnode->node = node;
newnode->next = NULL; //初始化
if(queue->rear ==NULL){
queue->front = queue->rear = newnode;
}
else{
newnode->next = queue->rear;
queue->rear = newnode;
}
//出队,返回AdjListNode*变量
struct AdjListNode* dequeue(struct Queue* queue){
if(queue->front ==NULL){
return NULL;
}
AdjListNode* node = queue->front->node; //把队头的值取出来
struct QueueNode* temp = queue->front;
queue->front = queue->front->next;
if(queue->front ==NULL){
queue->rear =NULL;
}
free(temp);
return node; //返回头节点
}
//判断是否为空
bool is_empty(struct Queue* queue){
return queue->front ==NULL;
}
再写一些图的基础操作
//先实现图的结构
struct AdjListNode{
int dest;
int weight;
struct AdjListNode* next;
};
struct AdjList{
struct AdjListNode* head;
};
struct Graph{
int V;
struct AdjList* array;
};
// 创建链表节点
struct AdjListNode* CreateAdjListNode(int dest){
struct AdjListNode* newnode = (struct AdjListNode*)malloc(sizeof(struct AdjListNode));
newNode->dest = dest;
newNode->next = NULL;
return newNode;
}
//创建图
struct Graph* CreateGraph(int V){
struct Graph* graph = (struct Graph*)malloc(sizeof(struct Graph));
graph->V = V;
graph->array = (struct AdjList*)malloc(V * sizeof(struct AdjList));
for(int i=0; i<V; i++){
graph->array[i]->head = NULL;
}
return graph;
}
//添加边
void addEdge(struct Graph* graph, int src, int dest){
struct AdjListNode* newNode = CreateAdjListNode(dest); //建一个新节点
newNode->next = graph->array[src]->head; //让原来图的顶点 指向新节点的next
graph->array[src]->head = newNode; //让新节点变成新顶点
//newNode = newAdjListNode(src); //双向图需要处理
//newNode->next = graph->array[dest]->head;
//graph->array[dest]->head = newNode;
}
最后是实现宽度优先遍历函数
void BFS(struct Graph* graph, int start){
//创建一个队列
struct Queue* queue = (struct Queue*)malloc(sizeof(struct Queue));
queue->front = queue->rear =NULL;
//创建一个大小为V, bool类型的动态数组 来记录某个点是否已经存在了
bool* visited = (bool*)malloc(graph->V * sizeof(bool));
for(int i=0; i<graph->v; i++){
visited[i] = false;
}
//
visited[start] = true;
enqueue(queue, start);
while(!is_empty(queue)){
//出队
int current = dequeue(queue);
printf("%d ", current);
//遍历与当前节点相邻的节点
struct AdjListNode* temp = graph->array[current]->head;
while(temp!=NULL){
int adj_node = temp->dest;
if(!visited[adj_node]){
visited[adj_node] = true;
enqueue(queue, adj_node);
}
temp= temp->next;
}
}
}深度优先遍历
搞个新的图
A -- B -- C
| | |
| | |
D -- E -- F我问了chatgpt很多很多次,每次深度优先遍历的结果都不同
深度优先遍历类似于二叉树的中序遍历,一条路走到黑再返回
比如A->B->C->F->E->D
void DFS(struct Graph* graph, int v){
//还是建一个动态的bool数组
bool* visited = (bool*)malloc(graph->V * sizeof(bool));
for(int i=0; i<graph->v; i++){
visited[i] = false;
}
visited[v] = true; // 标记当前节点已访问
printf("%d ", v); // 输出访问的节点
struct AdjListNode* current = graph->array[v]->head;
while(current != NULL){
if(!visited[current->dest]){ // 如果当前节点的邻居节点没有访问过,则递归访问它
DFS(graph, current->dest, visited);
}
current = current->next; // 处理下一个邻居节点
}
}
这里的操作真的很像二叉树那块
只要当前节点的邻居节点没有被访问过,就往下继续访问
总结
看到最后一个题的递归的时候还是做的不太好...
这么点内容写了大半天,太久不学习真的脑子生锈- -
先写熟这一套图的表达吧。视频里的建议是,熟到无论怎么变型都能定制出来要求。~















 336
336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









