







数据集描述melb_data.csv
这是Tony Pino创建的数据集的快照。
它是从Domain.com.au每周发布的公开结果中抓取出来的。他清理得很好,现在轮到你让数据分析变得神奇了。该数据集包括地址,房地产类型,郊区,销售方式,房间,价格,房地产经纪人,销售日期以及到CBD的距离
具体变量说明 房间数:房间数
价格:以美元计算的价格
方法:S -物业出售;SP -先前出售的物业;PI—传入的属性;PN -出售前未披露;SN -出售未披露;NB -无出价;VB
-供应商投标;W -在拍卖前撤回;SA -拍卖后出售;SS -拍卖后出售价格未披露。没有报价或最高出价。类型:卧房;房屋、小屋、别墅、半屋、露台;U -单元,双工;T—联排别墅;Dev site—开发站点;其他住宅。
卖方:房地产中介
日期:售出日期
距离:距离CBD
地区名称:总区(西、西北、北、东北等)
Propertycount:郊区中存在的属性数量。
卧室2:刮掉的卧室数量(来自不同的来源)
浴室:浴室的数量
汽车:停车位的数量
Landsize:土地面积
建筑面积:建筑面积
CouncilArea:该地区的管理委员会
数据解释
结果为原始数据集中的每列显示8个数字。第一个数字是count,显示有多少行具有非缺失值。
缺失值的产生有很多原因。例如,在调查一间卧室的房子时,不会收集第二间卧室的大小。我们将回到丢失数据的话题。
第二个值是均值,也就是平均值。在此之下,std是标准偏差,它衡量数值的数值分布。
要解释min、25%、50%、75%和max值,想象一下从最小值到最大值对每个列进行排序。第一个(最小的)值是最小值。如果你在列表中走四分之一的路,你会发现一个大于25%且小于75%的值。这就是25%的值(发音为“第25百分位”)。第50百分位和第75百分位的定义类似,max是最大的数字。
代码
import pandas as pd
#保存文件路径
melbourne_file_path = 'E:/pythonProject5/input/melb_data.csv'
#读取并保存数据
melbourne_data = pd.read_csv(melbourne_file_path)
#打印墨尔本数据汇总
melbourne_data.describe()
#打印列表的属性
melbourne_data.columns
#删除缺失值
melbourne_data = melbourne_data.dropna(axis=0)
#选择预测对象,这里选择房价
y = melbourne_data.Price
#构建一个只有几个特征的模型
#在括号内提供列名称列表来选择多个特性。该列表中的每个项都应该是字符串(带引号)
melbourne_features = ['Rooms','Bathroom','Landsize','Lattitude','Longtitude']
X = melbourne_data[melbourne_features]
#让我们快速回顾一下将用于使用describe方法和head方法预测房价的数据,该方法显示了最上面的几行。
X.describe()
X.head()
#决策树拟合示例
from sklearn.tree import DecisionTreeRegressor
#定义模型。为random_state添加一个数据保证运行结果相同
melbourne_model = DecisionTreeRegressor(random_state=1)
#拟合模型
melbourne_model.fit(X,y)
# print("Making predictions for the following 5 houses:")
# print(X.head())
# print("The predictions are")
# print(melbourne_model.predict(X.head()))
from sklearn.metrics import mean_absolute_error
predicted_home_price = melbourne_model.predict(X)
mean_absolute_error(y,predicted_home_price)
from sklearn.model_selection import train_test_split
#将数据分为训练和验证两部分,对于特征值和目标值,分割数据是基于一个随机数,random_state参数保证我们每次都得到相同的分割
train_X, val_X, train_y, val_y = train_test_split(X, y, random_state=0)
#定义模型
melbourne_model = DecisionTreeRegressor()
#拟合模型
melbourne_model.fit(train_X, train_y)
#根据验证数据获取价格
val_predicitions = melbourne_model.predict(val_X)
# print(mean_absolute_error(val_y, val_predicitions))
from sklearn.metrics import mean_absolute_error
from sklearn.tree import DecisionTreeRegressor
def get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y):
model = DecisionTreeRegressor(max_leaf_nodes=max_leaf_nodes,random_state=0)
model.fit(train_X, train_y)
preds_val = model.predict(val_X)
mae = mean_absolute_error(val_y, preds_val)
return(mae)
#用不同的max_leaf_nodes值比较MAE
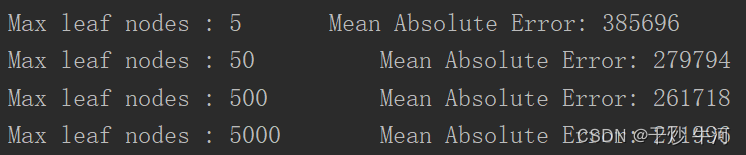
for max_leaf_nodes in [5,50,500,5000]:
my_mae = get_mae(max_leaf_nodes,train_X,val_X,train_y,val_y)
# print("Max leaf nodes : %d \t\t Mean Absolute Error: %d" %(max_leaf_nodes, my_mae))
'''随机森林'''
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error
forest_model = RandomForestRegressor(random_state=1)
forest_model.fit(train_X, train_y)
melb_preds = forest_model.predict(val_X)
print(mean_absolute_error(val_y,melb_preds))
预测结果
决策树
根据不同叶子数MAE不同
随机森林


















 1084
1084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









