






PPChecker
总体流程
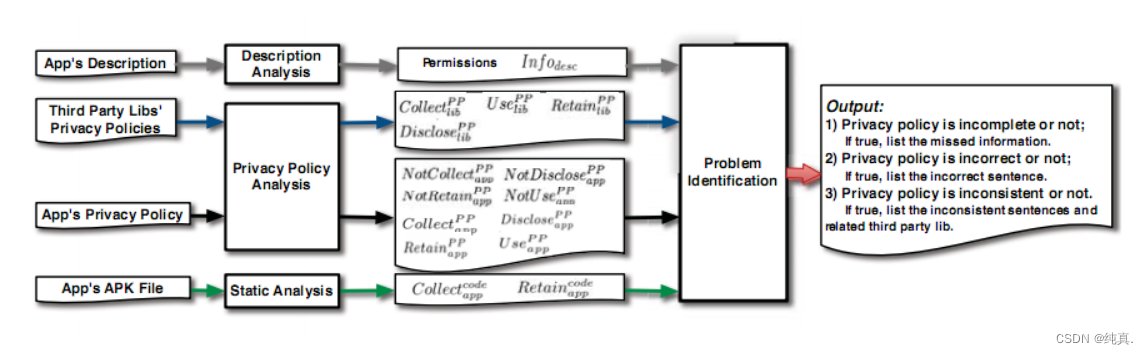
PPChecker接受app-s隐私策略、描述、apk文件和第三方libs-privacy策略。输出包括:1)隐私策略是否不完整。如果是,则列出遗漏的信息;2) 隐私策略是否正确。如果是,它列举了不正确的句子;3) 无论隐私策略是否不一致。如果是,它列出了不一致的句子和相关的第三方lib-s隐私政策。
关于输出的解释
(1) 隐私政策不完整。一份书面的隐私政策应涵盖应用程序的所有隐私相关行为。不完整的隐私政策可能会导致罚款。
(2) 隐私政策不正确。隐私政策应列出应用程序的真实行为。不正确的隐私政策声明,应用程序不会收集、使用、保留或披露个人信息,但应用程序会这样做。
(3) 隐私政策不一致。由于应用程序可能集成第三方库,因此其隐私政策应涵盖第三方的整体行为或指向其隐私政策。如果app-s隐私政策声明其不会访问个人信息,但其第三方libs-隐私政策提到他们会进行此类行为,我们将app-s隐私策略视为不一致的隐私政策。
具体模块
PPChecker由三个主要模块组成,包括:(1)隐私政策分析模块。它分析隐私政策,以确定要收集、使用、保留或披露的信息。(2) 静态分析模块。它检查应用程序的字节码,以决定应用程序是否会收集或保留私人信息。(3) 问题识别模块。它使用三种问题的模型来识别不完整的隐私策略。
隐私政策分析模块
主要动词、句子和资源
(1)收集动词。它们描述一方访问、收集或从另一方获取数据,如collect、gather等。让VPcollect表示此类动词。
(2)使用动词。它们描述了一方出于某种目的使用另一方的数据,例如使用(use)、处理(process)等。让VPuse表示这样的动词。
(3)保留动词。它们意味着一方将从另一方收集的数据保留特定时间段或特定位置,例如retain、store等。让VPretain表示这样的动词。
(4)披露动词。它们表示一方将收集的数据传输给另一方,如disclose、share等。让VPdisclose代表这些动词。
下面将根据上述的四种动词定义一些符号,分别是从app的隐私政策中提取的以及从第三方库的隐私政策中提取的。“”可以用上述定义的四种动词进行替换。

对于肯定句,通过分析句子,PPChecker识别出由各类主要动词所处理的隐私信息。而后引出几个新的符号定义,“”可由app或lib进行替代,表明是从app的隐私政策还是第三方库的隐私政策中提取得到的。

隐私政策可能使用否定句。例如,“我们不能收集”与“我们可以收集”的意思相反。同理可以给出几组新的符号定义。

隐私政策分析步骤
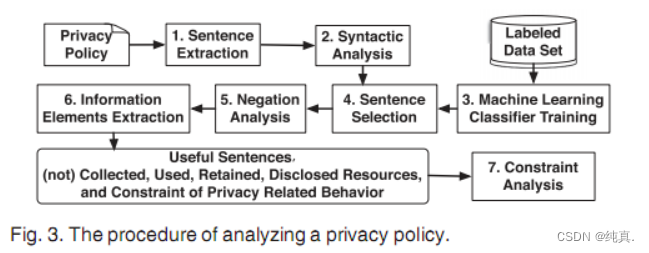
总体示意图
检查隐私策略的过程,其中包括以下六个步骤。
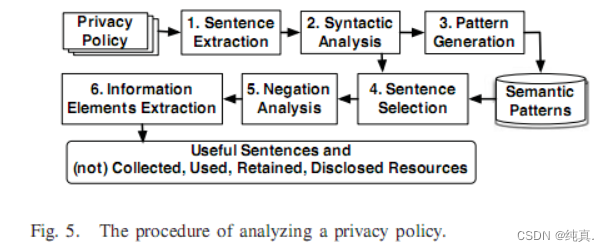
第一步:句子提取
PPChecker从隐私策略中提取内容,并将其拆分成句子。使用Beautiful Soup 以HTML格式从每个隐私策略中提取内容,并删除所有非ASCII符号和一些无意义的ASCII符号。(注意,这篇文章中只考虑了用英语编写的隐私政策,因此提取的内容仅包含英文字母和一些指定的标点符号。)
然后,我们使用自然语言工具包(NLTK)将文本分成句子。由于NLTK将枚举列表划分为单个句子,因此可能会导致错误。例如,将“we will collect the following information: your name; your IP address; your device ID.” 划分为四部分,“:”之后的三个资源被视为三个句子。为了解决这个问题,PPChecker逐一检查NLTK中的句子序列。如果前一句以符号“:”或“;”结尾,PPChecker将当前句子附加到前一个句子。最后,PPChecker将所有字母转换为小写。
第二步:句法分析
它解析句子并获得句法信息。对于每个句子,我们使用Stanford Parser来获得其句法树和依赖关系。例如,下图显示了句子的句法信息:“we will provide your information to third party companies to improve service”. 左侧部分是解析树结构,右侧部分是类型化依赖关系。
 解析树将句子分成短语,并在层次结构中显示它们,每个短语占据一行。解析树还包含单词和短语的词性(POS)标记,这些标记是基于单词的或短语的语法行为分配的。常见的POS标签包括名词(NN)、动词(VB)、形容词(ADJ)、副词(ADV)、代词(PRP)等。在上图中,provide是一个动词,我们可以在它的子树中找到它的宾语-名词短语“your information”。auxpass的意思是被动辅助
解析树将句子分成短语,并在层次结构中显示它们,每个短语占据一行。解析树还包含单词和短语的词性(POS)标记,这些标记是基于单词的或短语的语法行为分配的。常见的POS标签包括名词(NN)、动词(VB)、形容词(ADJ)、副词(ADV)、代词(PRP)等。在上图中,provide是一个动词,我们可以在它的子树中找到它的宾语-名词短语“your information”。auxpass的意思是被动辅助
键入的依赖关系描述单词之间的关系。常见的关系包括:sbj表示主语,dobj表示直接宾语,root表示与句子词根的关系点,nsubjpass表示名词短语是被动动词的句法主语。prep to是指由以to开头的介词修饰的动词、形容词或名词(例如,go to store)。在上图中,provide是这句话的词根。这句话的主语是we,宾语是your information。
句法信息用于下面的模式生成步骤和句子选择步骤。
第三步:模式生成
现有的隐私策略分析系统使用预定义的模式来查找与信息收集相关的句子。我们增强了自举机制,以根据简单的种子模式从隐私策略中自动找到模式。我们将使用下图中的示例来解释自举机制,然后描述增强。
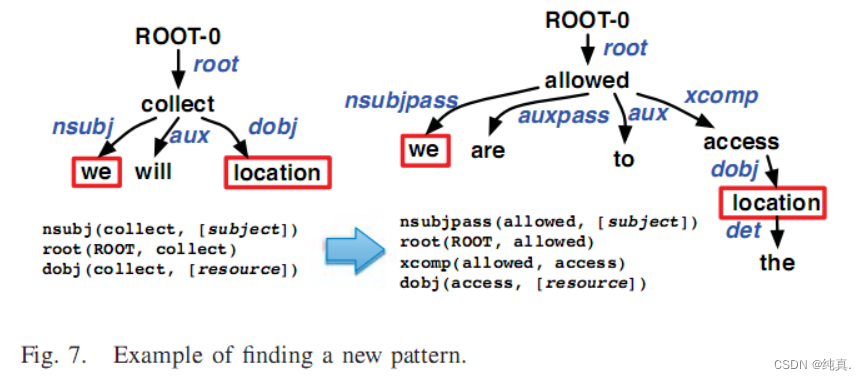 我们首先准备一个语料库,其中包含与信息收集、利用、保留和披露相关的句子。种子模式是主语-动词-宾语,初始动词包括收集、使用、保留和披露。显然,种子模式与我们将在图7中收集位置的左侧句子相匹配。我们收集所有匹配句子的主语和宾语(例如,左侧句子中的We和location),并将频率高于中值的主语和主语分别插入主语列表和宾语列表。
我们首先准备一个语料库,其中包含与信息收集、利用、保留和披露相关的句子。种子模式是主语-动词-宾语,初始动词包括收集、使用、保留和披露。显然,种子模式与我们将在图7中收集位置的左侧句子相匹配。我们收集所有匹配句子的主语和宾语(例如,左侧句子中的We和location),并将频率高于中值的主语和主语分别插入主语列表和宾语列表。
然后,我们通过将每个类型依赖树中的主语和宾语与主语列表和宾语列表中的元素进行匹配来寻找新模式。对于Fig 7中的正确句子,由于其类型依赖树包含主语we和宾语location,因此我们提取它们之间的最短路径作为新模式。因此,提取了新的模式主语-“allowed”-宾语,所有新的模式都被插入到模式列表中,以便下次迭代,当没有找到新的模式时,算法停止。
我们从两个方面对算法进行了改进。
一个是如何处理语义差异,这是指新术语的含义与种子模式的含义的偏差。我们使用三个黑名单来解决这个问题。首先,由于我们只关注app的行为,PPChecker维护了一个主语黑名单,其中包含诸如you、user、visitor等单词,以删除描述app用户的句子。其次,由于我们只关心应用程序的四种行为,PPChecker删除了与这些行为无关的动词(例如have、make等)。第三,PPChecker通过对宾语(例如,服务等)使用黑名单来丢弃与隐私信息无关的句子。
另一个是如何排序和获取新模式。从语料库中找到新模式后,我们对它们进行排序,以选择重要模式。给定模式p,如果它能匹配更多关于信息收集、使用、保留或披露的句子,这一点很重要。然而,如果p-s可以匹配许多不相关的句子,那么p-s的重要性就会降低。为了给每个模式打分,我们从实际的政策政策中构建了两个句子集。一个被称为肯定句集,包含有关信息收集、使用、保留或披露的句子,而另一个被命名为否定句集,包括不相关的句子。对于模式p,我们使用pos(p)来表示p可以匹配的肯定句的数量,并使用neg(p)表示p能够匹配的否定句的数量。设unk(p)表示任何模式都无法匹配的句子数。然后,模式p的准确性和置信度定义为:
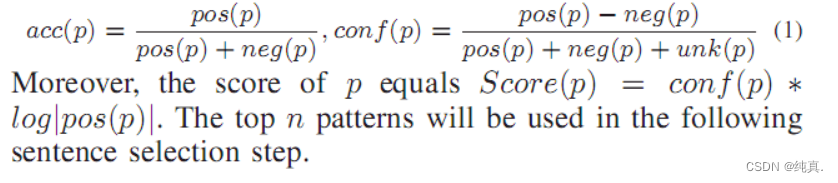
第四步:句子选择
PPChecker使用生成的模式来识别隐私策略中的句子。匹配的句子被视为有用的句子,其他句子将被丢弃。我们使用Table II中列出的五种模式作为示例来说明这个过程。P1是种子方案。P2是P1的被动语态版本。从语料库中自动提取其他三个模式(即P3、P4和P5)。
为了找到与模式P1和P2匹配的句子,我们解析每个句子的类型依赖以提取其词根,然后检查其词根是否属于四个主要动词类别。如果是这样的话,我们就把这个句子当作一个有用的句子。此外,如果有用句子的词根动词与其他单词有扩展关系,则该句子具有被动语态(即P2)。否则,它具有主动语态(即P1)。
P3模式描述了允许主语做某事。为了匹配它,一个句子的词根应该是“allowed”。此外,它的“allowed”应该与另一个单词有auxpass关系,与动词有xcomp关系。动词不定式短语中的动词应该属于动词的主要类别。模式P4表示主语能够做某事。为了匹配它,一个句子的词根应该是“able”。此外,“able”可以用开放小句补语修饰,并且应该与另一个属于主动词范畴的动词有xcomp关系。P5模式是状语从句。为了与之匹配,句子的词根应该属于主要动词的类别,并与另一个动词有副词关系。

第五步:否定分析
PPChecker通过检查两个地方是否存在否定词来确定一个句子是否为否定。一个是识别像“nothing will be collected”这样的句子的主语。另一种是指用来修饰词根的词语,如“我们不会收集信息”。我们采用否定词列表,因为它包括否定动词(例如,“防止”)、否定副词(例如,“几乎”)、否定形容词(例如,“不能”)和否定限定词(例如,“不”)。
第六步:信息元素提取
从每个有用的句子中,我们寻找四个元素,包括主要动词、动作执行者、资源和约束。例如,Fig8显示了句子中的信息元素:“we will provide your information to third party companies to improve service if you …”, 其中主要动词是provide,主语是we,宾语是your information,约束条件是if you

问题识别模块使用主语、主要动词和资源。该约束用于识别和删除某些特定语句,包括
(1)当用户通过网站注册帐户时,尽管网站可能会收集私人信息,但PPChecker不考虑;
(2) 当用户访问将记录IP地址和其他信息的网站时,由于该行为不是由应用程序执行的,PPChecker会忽略它。
资源是动作执行器使用的数据,比如location、your information等。
提取了两种约束:前条件和后条件。前置条件以if、on、un-less开头,后置条件以when、before开头。我们通过从句法树中提取以这些单词开头的子树来收集约束。
隐私政策分析模块2.0
修改后的总体示意图
第一步:句子提取
PPChecker从隐私策略中提取内容,并将其拆分成句子。使用Beautiful Soup 以HTML格式从每个隐私策略中提取内容,并删除所有非ASCII符号和一些无意义的ASCII符号。(注意,这篇文章中只考虑了用英语编写的隐私政策,因此提取的内容仅包含英文字母和一些指定的标点符号。)
然后,我们使用自然语言工具包(NLTK)将文本分成句子。由于NLTK将枚举列表划分为单个句子,因此可能会导致错误。例如,将“we will collect the following information: your name; your IP address; your device ID.” 划分为四部分,“:”之后的三个资源被视为三个句子。为了解决这个问题,PPChecker逐一检查NLTK中的句子序列。如果前一句以符号“:”或“;”结尾,PPChecker将当前句子附加到前一个句子。最后,PPChecker将所有字母转换为小写。
第二步:句法分析
它解析句子并获得句法信息。对于每个句子,我们使用Stanford Parser来获得其句法树和依赖关系。例如,下图显示了句子的句法信息:“we will provide your information to third party companies to improve service”. 左侧部分是解析树结构,右侧部分是类型化依赖关系。
解析树将句子分成短语,并在层次结构中显示它们,每个短语占据一行。解析树还包含单词和短语的词性(POS)标记,这些标记是基于单词的或短语的语法行为分配的。常见的POS标签包括名词(NN)、动词(VB)、形容词(ADJ)、副词(ADV)、代词(PRP)等。在上图中,provide是一个动词,我们可以在它的子树中找到它的宾语-名词短语“your information”。auxpass的意思是被动辅助
键入的依赖关系描述单词之间的关系。常见的关系包括:sbj表示主语,dobj表示直接宾语,root表示与句子词根的关系点,nsubjpass表示名词短语是被动动词的句法主语。prep to是指由以to开头的介词修饰的动词、形容词或名词(例如,go to store)。在上图中,provide是这句话的词根。这句话的主语是we,宾语是your information。
第三步:分类器训练(相较于1.0有变动)
在会议版本v1.0中,我们使用一系列种子模式从隐私策略语料库中找到语义模式。这些模式用于识别与信息收集、使用、保留和披露相关的句子。然而,如果预定义的种子模式不完整或不正确,则发现的模式不能以高召回率和高精度识别与信息收集、使用、保留和披露相关的句子。为了克服这一限制,本文提出使用机器学习分类器来自动识别这些句子。
更准确地说,我们让特征集包括unigram、bigrams、trigrams和单词之间的类型依赖关系。计算TF-IDF(术语频率反向文档频率)35值以测量每个单词的权重。这种值通常用于信息检索中,以衡量一个词的重要性。TF(即术语频率)是指一个词在文档中出现的频率。IDF(即,反向文档频率)意味着多次出现的术语不重要(例如,an、of)。我们选择了四个分类器,包括最大熵、SVM 、朴素贝叶斯和随机森林,并根据数据集的10倍交叉验证结果选择最佳分类器。对于分类器识别的句子,我们只保留包含收集、使用、保留和披露动词的句子(第3.2.1节)。
第四步:句子选择
PPChecker使用经过训练的分类器从隐私策略中识别句子。匹配的句子被视为有用的句子,其他句子将被丢弃。
第五步:否定分析
PPChecker通过检查两个位置20中否定词的存在来确定句子是否是否定的。一个是识别句子的主语,就像什么都不会收集一样。另一种是指用于修改词根的单词,例如我们不会收集信息。我们采用了40个否定词列表,因为它包括否定动词(例如,阻止)、否定副词(例如,几乎不·)、否定形容词(例如,无法)和否定限定词(例如:否)。
第六步:信息元素提取
从每个有用的句子中,我们寻找四个元素,包括主要动词、动作执行者、资源和约束。例如,Fig8显示了句子中的信息元素:“we will provide your information to third party companies to improve service if you …”, 其中主要动词是provide,主语是we,宾语是your information,约束条件是if you
问题识别模块使用主语、主要动词和资源。该约束用于识别和删除某些特定语句,包括
(1)当用户通过网站注册帐户时,尽管网站可能会收集私人信息,但PPChecker不考虑;
(2) 当用户访问将记录IP地址和其他信息的网站时,由于该行为不是由应用程序执行的,PPChecker会忽略它。
资源是动作执行器使用的数据,比如location、your information等。
当识别隐私政策中提到的个人信息时,我们发现一些句子包含细化短语(比如include)。细化短语用更具体的概念来细化一个一般概念。特定概念是指由应用程序访问的特定类型的信息(例如,设备ID),而一般概念是特定概念(例如设备信息)的抽象。例如,句子“个人信息”可能包括您的姓名、用户识别号或电子邮件地址。使用几个特定的概念细化个人信息:姓名、用户识别号、电子邮件地址。我们提出以下方法来处理它们。
(1)我们使用Girju等人提出的句法模式(Table 2)来识别细化短语描述的部分-整体关系。例如,“Personal information may include your name, user identification number, or email address” ,与Table 2的第一个模式相匹配。然后,我们可以发现动词include的主语和宾语之间存在部分-整体关系。因此,一般概念是个人信息(Personal information),具体概念包括姓名、用户识别号和电子邮件地址。

(2)我们从隐私政策中提取所有句子,并将它们存储在一个列表中,然后将所有包含精炼短语(比如include)的句子存储在一个列表中。如果句子列表中的i句包含细化短语,我们从隐私政策的句子列表中提取(i - 1)和(i+1)句。我们使用训练过的分类器(Section 3.2 Step 3)来确定这两个句子是否与信息收集、使用、保留或披露有关。如果将(i - 1)或(i + 1)句视为信息收集、使用、保留或披露,并且其中还提到了细化短语的一般概念,则我们认为相应的具体概念将被收集、使用、保留或披露。
我们用下面两个句子作为例子来说明这个过程:“We collect your personal information. The personal information includes your name, your address, and device information”.在找到包含细化短语(include)的第二句话后,我们将训练好的分类器应用于第一句,发现它与信息披露有关。由于第一句声明了一般概念(即“个人信息”)将被收集,我们推断具体概念(即“姓名”、“地址”、“设备信息”)也将被收集。
第七步:约束条件分析
在通过提取有用句子中的条件副词从句来识别约束之后,我们首先过滤掉与app行为无关的约束。更准确地说,我们忽略了应用程序无法实现的限制,包括联系开发者、询问开发者问题、使用/取消服务、访问网站、法律要求、确定用户是否为儿童。为了消除这些限制,我们在阅读了300个随机选择的条件副词子句后,建立了一个黑名单,其中包含一系列(动词、名词)对(例如,(contact,us)(change,policy))。然后,对于每个有用的句子(在步骤4:句子选择中识别),如果它包含约束,我们根据类型依赖关系提取所有(动词、名词)对。例如,对于约束““if you enable location service”,将提取两个(动词、名词)对(即,(enable,you)和(enable、location service)),因为单词之间存在nsbj和dobj依赖关系。之后,我们使用ESA 44计算从约束中提取的每个(动词、名词)对与黑名单中的每个(名词、动词)对之间的语义相似度。如果相似度高于阈值(默认情况下,45中使用的是0.67),则忽略该约束。否则,我们分析其内容。为了获得两个文本的语义相似度,ESA使用知识库将每个文本映射到一个向量表示,然后计算两个向量的相似度。
Table3确定了可以在代码中检查的两种类型的约束。

第一类约束与启用服务相关,并具有模板“If users enable feature/function/ service, the app will access the information”。在应用程序中,开发者将在访问敏感信息之前检查相应的特性/功能/服务是否已启用。这些特性/功能/服务可分为两类。一类包括Android系统提供的服务(例如,位置、蓝牙)。另一类包括开发人员实现的特性/功能。例如,该应用程序的隐私政策包含以下语句“If you do enable the local weather feature, your approximate location is collected on a periodic basis”。“the local weather feature”由开发人员实现。
第二种类型的约束与UI回调相关,并具有类似“If users click/press UI element, the app will access the information”的模板。UI元素指的是布局中包括的视图类(例如,Button、TextView)48。在用户按下UI元素之后,这样的应用可以直接访问UI元素的回调中的敏感信息,或者启动其他活动来访问敏感信息。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









