






**相信大家最近都听过爬虫,那么爬虫究竟是什么东西呢?网络爬虫又称网络蜘蛛、网络机器人,它是一种按照一定的规则自动浏览、检索网页信息的程序或者脚本。网络爬虫能够自动请求网页,并将所需要的数据抓取下来。通过对抓取的数据进行处理,从而提取出有价值的信息;那么爬虫该怎么做呢?那么今天就给大家分享两种爬虫示例方式以及介绍。**
一、接口爬取
从事过互联网工作的朋友或是对互联网有过了解的朋友都知道,我们如今的所有app或者是web网页数据交互都是通过http协议的请求来进行的,而网页上的所有数据展示都是通过接口请求方式从后端获取,所以呢我们所需要的数据都在这些接口返回的数据当中,所以我们可以伪造这些http请求去获得自己想要的数据信息;伪造请求的方式呢又分为工具伪造以及脚本伪造,工具伪造就是那些能够发送http请求的工具、比如说postman、jmeter以及loadrunner等各种工具;但是工具爬取不是一个好方法,因为你获取到的信息非常杂,需要对数据进行清洗工作,那么工具就显得不那么灵活,有些数据不好清洗;另一种就是现在大家常用的方法:脚本伪造,也是今天给大家带来的分享方法。
脚本伪造就是通过代码的方式去发起请求,然后的到请求返回的响应数据后对这些数据进行清洗,得到所需数据后可以以文档的方式保存下来;而脚本的方式也非常多,比如说java、javascript、python等等。而我则推荐大家用python去进行脚本伪造;因为python这门语言非常简单而且很适合做数据清洗;支持强大的三方库可以使用,而且还拥有各种爬虫框架,比如说Scrapy、PySpider、Crawley、Beautiful Soup等等,有兴趣的朋友可以去了解一下
现在就给大家示例一下爬虫爬取的过程
一般写爬虫的时候都是要明确自己的目的,即自己想要爬取的东西是什么?目标网址是什么?最后得到的数据是什么样的?有了这三个目标那么我们就可以开始去制作爬虫;那么现在我想去爬取一些壁纸图片,然后下载到我的本地,那么下面我就开始教大家怎么去一步一步分析且编写脚本
1、进入目标网站,因为我们是要批量自动爬取,所以只要选择类型以后就自动开始下载图片到本地。所以第一步就是点击这个分类后爬取这个分类下所有图片

2、找到分类后我们需要去查看请求接口、怎么找呢?按下键盘上的F12按钮进入开发者模式;然后找到这个接口就是我们要找的分类下获取到的图片的内容数据,但是这个接口好像返回的不是我们熟悉的json数据,而是返回的一个html页面,内容刚好就在这个html页面里面,那么还是先把这个请求接口先伪造出来
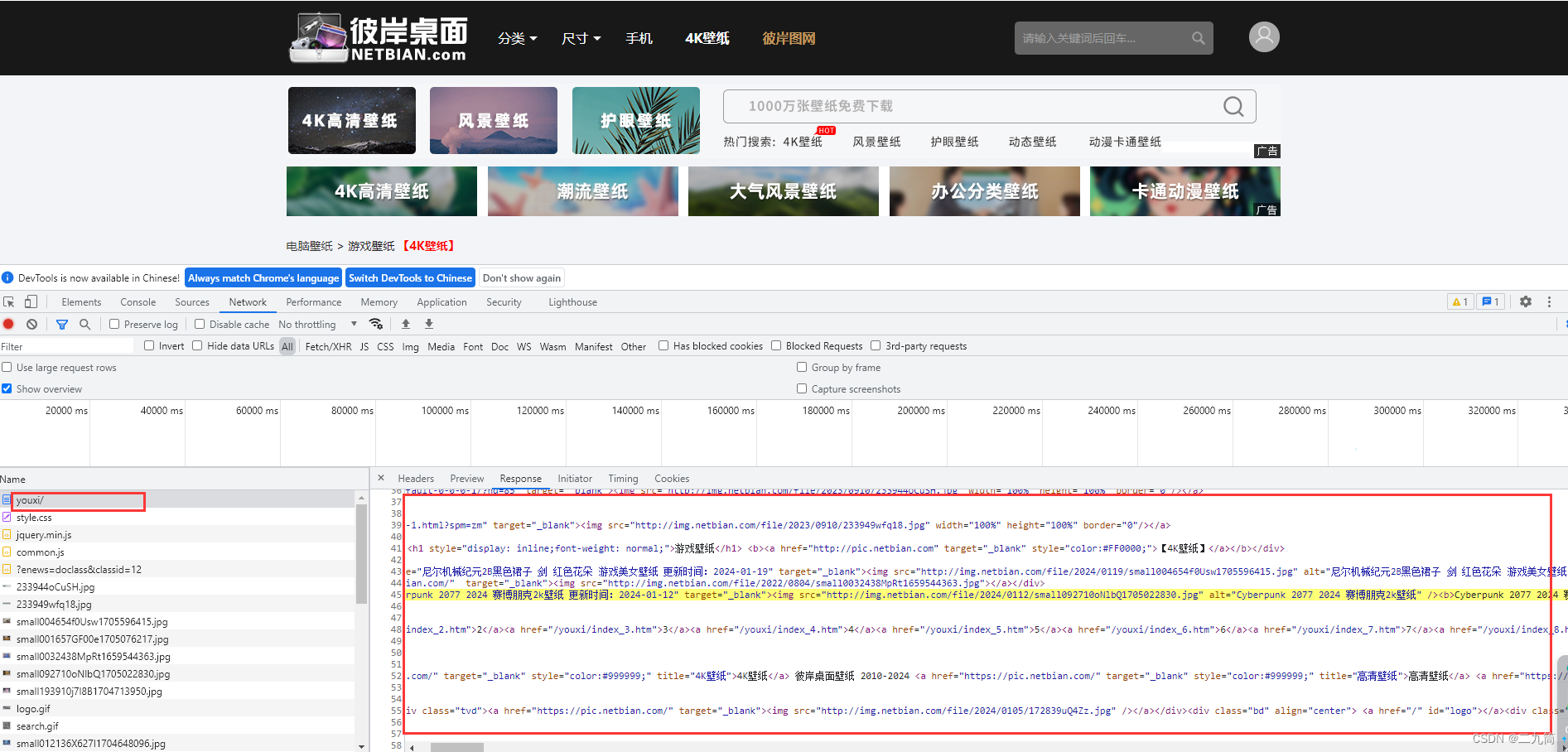
3、查看请求接口的内容,找到headers,这里面有我们需要的参数信息
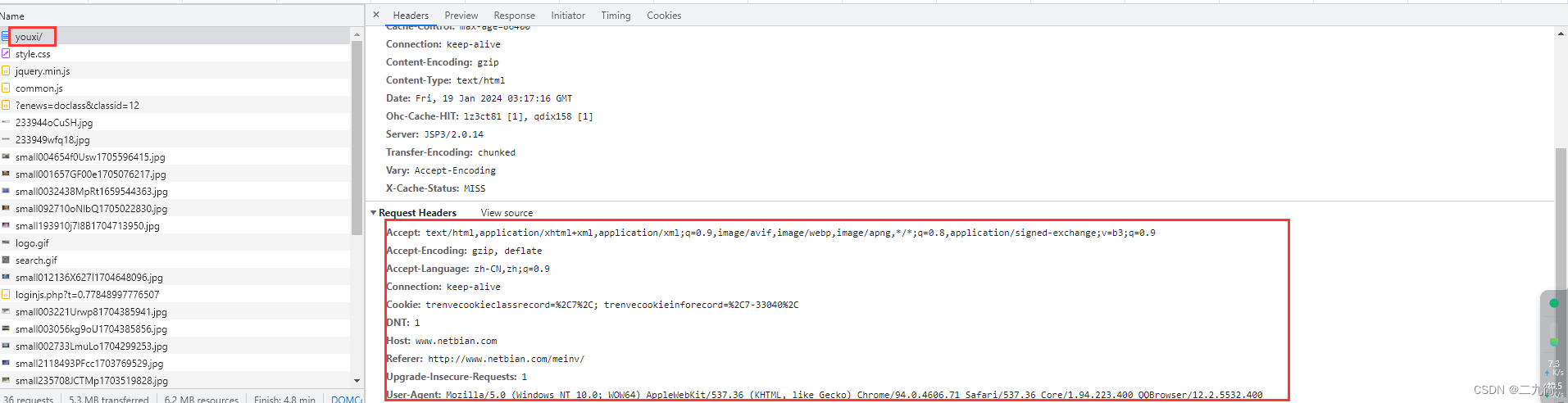
4、编写请求信息,因为这个接口比较简单,没有实名参数传递,而且通过分析,这个接口分页方式是直接放在链接里面的

代码编写:
def getAllKindOfPiture(self):
kindUrl = "http://www.netbian.com/youxi/" #后面的youxi就是图片类型的拼音,要选择不同的种类,拼上各个种类拼音就行
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.223.400 QQBrowser/12.2.5532.400"
}
re = requests.get(url=kindUrl,headers=headers)
print(re.text)
5、当然前面只是获取到了数据,但是这个数据并不是外面想要的数据,外面要想下载图片,那就得找到这个图片的url才行,所以我们需要在这些内容中提取出url;所以我们要开始进行数据清洗;这个又很多中方法。包括正则提取;还有就是Beautiful Soup的方法可以快速提取想要的内容;这儿我就用正则提取的方法进行提取
def picturenum(self):
data=Downloadpucture.indexdata(self)
zz=r'href="/desk/.*?.htm"' #正则表达式
global URl
for i in data.split():
try:
ret=re.search(zz,i).group()[12:17]
URl = 'http://www.netbian.com/desk/%s-1920x1080.htm' % ret
Downloadpucture.download(self,PATH)
except:
pass
6. 通过数据清洗就可以得到我们想要的数据了,然后实现爬取功能;上面只是简介一下爬取过程;然后最终的代码如下
import requests,re,os
class Downloadpucture(object):
def __init__(self):
#请求头
self.headers={
'Accept': 'text / html, application / xhtml + xml, application /'
' xml;q = 0.9, image / webp, image / apng, * / *;q = 0.8',
'Accept - Encoding': 'gzip, deflate',
'Accept - Language': 'zh - CN, zh;q = 0.9',
'Cache - Control': 'max - age = 0',
'Host': 'www.netbian.com',
'Upgrade - Insecure - Requests': '1',
'User - Agent': 'Mozilla / 5.0(WindowsNT10.0;WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / '
'70.0.3538.25Safari / 537.36Core / 1.70.3870.400QQBrowser / 10.8.4405.400'
}
#选择图片类型
def choosevarise(self):
list=["rili","dongman","fengjing","meinv","youxi","yingshi","dongtai","weimei","sheji","keai","qiche","huahui",
"dongwu","jieri","renwu","meishi","shuiguo","jianzhu","tiyu","junshi","feizhuliu","qita","wangzherongyao","huyan","lol"]
LIST=["0.日历","1.动漫","2.风景","3.美女","4.游戏","5.影视","6.动态","7.唯美","8.设计","9.可爱","10.汽车","11.花卉","12.动物",
"13.节日","14.人物","15.美食","16.水果","17.建筑","18.体育","19.军事","20.非主流","21.其他","22.王者荣耀","23.护眼","24.LOL"]
print(LIST[0:12])
print(LIST[13:25])
Downloadpucture.choosepath(self) #调用路径填写函数
Downloadpucture.choosenum(self) #调用图片类型选择函数
Downloadpucture.judge(self, number, LIST, list) #调用路径填写函数
#保存路径,主要对路径做一个判断,判断路径是否填写正确,如果该路径下存在文件夹则跳过,不存在则创建文件夹
def choosepath(self):
global PATH
while True: #对文件进行判定,文件夹后面是否带“/”,不带则主动添加“/”,因为这儿是为了下面图片下载函数能正确下载到填写的文件夹下
try:
try:
PATH=input("请输入保存路径,具体到某个文件夹:")
gz = r"/$"
rep = re.findall(gz, PATH)[0]
pass
if rep == "/":
pass
else:
pass
except:
PATH += "/"
folder=os.path.exists(PATH)
if not folder:
os.mkdir(PATH) #创建文件夹
break
else:
break
except:
print("路径错误,请仔细检查路径后重试!!")
print("图片保存路径:%s" % PATH)
#判断输入的序号是否正确
def choosenum(self):
global number
while True:
try:
number = int(input("请输入要下载的类型图序号:"))
if isinstance(number,int):
if 0<=number<=24:
break
else:
print("请输入正确序号!!!")
else:
print("请输入正确序号!!!")
except:
print("请输入正确序号!!!")
#对页面URL进行处理,主要是爬取的页面URL不一致,进行判断,获取URL
def judge(self,number,LIST,list):
global Url
kd = list[number]
print("你已选择:%s" % LIST[number])
for i in range(1, Downloadpucture.picturepages(self, kd, number) + 1):
if 0 <= number < 22:
Url = "http://www.netbian.com/%s/index_%d.htm" % (kd, i)
if i == 1:
Url = "http://www.netbian.com/%s/" % kd
else:
pass
elif 22 <= number <= 24:
Url = "http://www.netbian.com/s/%s/index_%d.htm" % (kd, i)
if i == 1:
Url = "http://www.netbian.com/s/%s/" % kd
else:
pass
Downloadpucture.picturenum(self)
#获取图片;类型下所有图片的二级链接
def indexdata(self):
rep = requests.get(url=Url, headers=self.headers)
return rep.text
#正则提取出二级链接下响应页面的三级地址
def picturenum(self):
data=Downloadpucture.indexdata(self)
zz=r'href="/desk/.*?.htm"'
global URl
for i in data.split():
try:
ret=re.search(zz,i).group()[12:17]
URl = 'http://www.netbian.com/desk/%s-1920x1080.htm' % ret
Downloadpucture.download(self,PATH)
except:
pass
#获取图片所有页数,找到该图片类型下所有的页数
def picturepages(self, kd,number):
if 0<=number<22:
req = requests.get(url="http://www.netbian.com/%s/" % kd, headers=self.headers).text
gz = r'.htm">.*?</a><a href="/%s/index_2.htm'% kd
NUM=re.findall(gz,req)[0].split(">")[-2]
PAGE=re.match(r'\d{0,4}',NUM).group()
return int(PAGE)
else:
req = requests.get(url="http://www.netbian.com/s/%s/" % kd, headers=self.headers).text
gz = r'.htm">.*?</a><a href="/s/%s/index_2.htm'% kd
NUM=re.findall(gz,req)[0].split(">")[-2]
PAGE=re.match(r'\d{0,4}',NUM).group()
return int(PAGE)
# 获取图片正式地址
def htmldata(self,URl):
re = requests.get(url=URl, headers=self.headers)
return re.text
# 响应数据处理,获取图片相应的url
def picturelink(self):
data = Downloadpucture.htmldata(self, URl).split()
list = []
for i in data:
if i[0:4] == "src=":
if i[-4:-1] == "jpg":
url = i[5:-1]
list.append(url)
else:
pass
else:
pass
return list[1]
# 下载图片
def download(self,PATH):
D = requests.get(Downloadpucture.picturelink(self), stream=True)
path = PATH + Downloadpucture.picturelink(self)[-10:-4] + ".jpg"
with open(path, "wb") as f:
f.write(D.content)
print(Downloadpucture.picturelink(self)[-10:-4] + ".jpg" + "下载完成!")
if __name__=="__main__":
a=Downloadpucture()
a.choosevarise()
总结:其实接口爬取只要分析到位,很快就能写出脚本;但是恰巧难的就是分析过程,上述的爬取只是最贱单的方式,这里面不涉及到鉴权验签以及参数的传递;如果涉及到验签还得去js逆向,有兴趣的可以去了解一下js逆向爬虫
二、页面爬取
页面爬取就是针对接口爬取行不通或者是接口爬取太难(鉴权这类)时使用的;主要就是通过代码去控制游览器操作页面,从而进入某个页面;获取到页面信息;当然这个就只能针对web网页了,像什么app之类的肯定不行;所以接下来就介绍一下页面爬取的方法
做过测试的人都知道页面自动化吧,那就是selenium这个东西;这个东西怎么说呢,会用的人可以拿来做很多事情,比如说抢票、购物秒杀、以及即将介绍的爬虫,不会的人呢对这个东西还是有一定的难度;因为这个东西对前端知识要有一定的认知;当然现在也有相关的工具可以进行脚本录制,但是工具这个东西说实话还是不怎么灵活,即使录制出来也要自己去优化脚本;所以感兴趣的可以去学习一下selenium这个东西;废话不多说,开始介绍。。。
1、照样继续我们的三问原则;我们需要爬取什么?目标网址在哪里?得到的数据是什么样的?我们现在需要爬取招聘信息,然后需要得到相关岗位都有哪些公司在招聘
2、首先我们得进入这个网站查看信息,进入页面后进行职位搜索,就可以找到该职位下各个招聘信息;这个步骤完全可以用selenium完成;注意使用selenium需要下载对应游览器的driver;现在我使用的是chrome游览器,那么就需要下载对应chrome游览器版本的驱动driver;两者版本必须保持一致,不然启动游览器会报错的
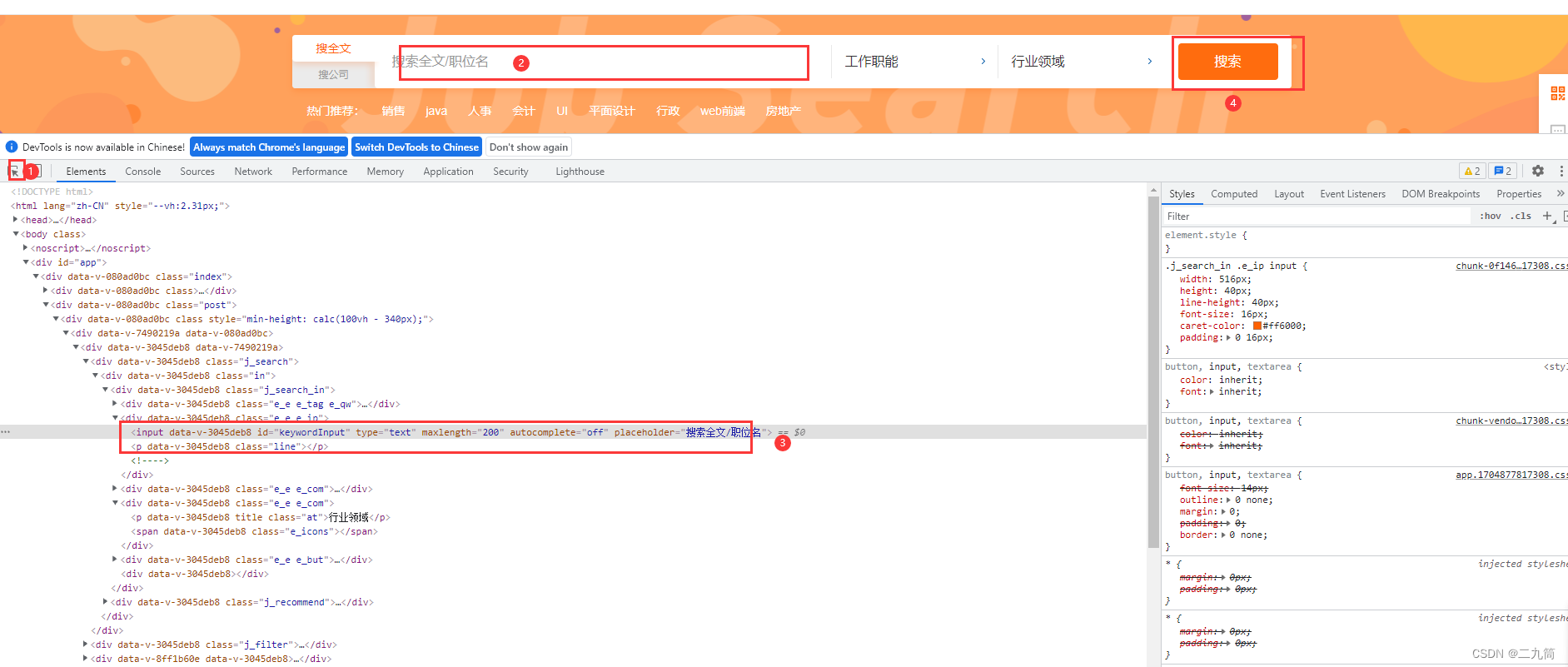
3、编写脚本代码。这里同样需要进入页面;打开F12,查看页面元素信息,因为selenium就是靠页面元素进行定位然后操作的;定位方式有八种;操作包括点击、输入、选择等等;有兴趣的去了解就行
class GetData():
#初始化函数,主要做爬取前的准备工作
def __init__(self):
self.chome_options = webdriver.ChromeOptions()
self.chome_options.add_argument('--headless') #无页面爬取,不会打开游览器窗口
self.driver = uc.Chrome(options=self.chome_options)
self.filePath='C:/Users/suoer/Desktop/2.csv'
self.file = open(self.filePath, 'a+',newline='', encoding='gbk')
self.write = csv.writer(self.file)
#先一步写入文件title,后面循环就不加title了
self.write.writerow(
['公司', '岗位', '薪资', '福利', '工作经验', '学历', '城市', '招聘人数', '公司规模', '公司方向'])
#页面爬取数据函数
def inIndex(self):
driver = self.driver
driver.get('https://search.51job.com/')
sleep(1)
self.sliderCheck()
sleep(1)
driver.find_element(By.XPATH, '//*[@id="keywordInput"]').send_keys("会计") #搜索的职位
sleep(1)
driver.find_element(By.XPATH, '//*[@id="search_btn"]').click()
sleep(1)
driver.find_element(By.XPATH, '//*[@id="keywordInput"]').send_keys("-")
sleep(1)
driver.find_element(By.XPATH, '//*[@id="search_btn"]').click()
4、同样进入页面后获取的就是页面信息;所有岗位信息都在页面上,恰好selenium可以吧这个页面全部信息打印出来,然后同样的需要提取相关数据,这里还是用的正则方式去提取(我认为正则提取最简单,哈哈)
#处理当前页面数据,最终返回一个数组
def pageData(self)->list:
list = []
#下面两个正则是为了提取页面的数据
data = re.findall('<div class="j_joblist">.*?<div class="j_page">', self.driver.page_source)
data1 = re.findall('<p class="t">.*?<button track-type', data[0])
#下面这个循环是取出上面正则提取出来的数据,上面正则提取的是一个数组
for i in data1:
data2 = re.findall('>.*?<', i) #根据上面正则提取出的页面数据,进一步得到最终所需要的信息
data3 = [a[1:-1] for a in data2 if a != '><' and a != '> <'] #去掉提取出来所有信息两边的残留
data4 = '' #因为页面爬取的待遇所有都是合在一起的,所以单独处理这条数据,这儿先定义它
for d in data3[4:-4]: #这个循环就是为了吧合在一起的待遇这条数据用空格分割开
data4 += str(d + ' ')
#这儿就是从页面上一条招聘信息提取出来的所有信息,然后把整个页面上的通过循环存进数组中
list.append([data3[-3],data3[0],data3[2],data4,data3[3].split('|')[1],
data3[3].split('|')[2],data3[3].split('|')[0],"",data3[-2],data3[-1]])
return list
5、提取出来后我们就可以存为文档了
def writeCsv(self,list):
self.write.writerow(list)
6、以上就是页面爬取的简单介绍以及示例;下面是整个爬取代码
import re,csv
from selenium import webdriver
from time import sleep
import undetected_chromedriver as uc
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
class GetData():
#初始化函数,主要做爬取前的准备工作
def __init__(self):
self.chome_options = webdriver.ChromeOptions()
self.chome_options.add_argument('--headless') #无页面爬取,不会打开游览器窗口
self.driver = uc.Chrome(options=self.chome_options)
self.filePath='C:/Users/suoer/Desktop/2.csv'
self.file = open(self.filePath, 'a+',newline='', encoding='gbk')
self.write = csv.writer(self.file)
#先一步写入文件title,后面循环就不加title了
self.write.writerow(
['公司', '岗位', '薪资', '福利', '工作经验', '学历', '城市', '招聘人数', '公司规模', '公司方向'])
#页面爬取数据函数
def inIndex(self):
driver = self.driver
driver.get('https://search.51job.com/')
sleep(1)
self.sliderCheck()
sleep(1)
driver.find_element(By.XPATH, '//*[@id="keywordInput"]').send_keys("会计") #搜索的职位
sleep(1)
driver.find_element(By.XPATH, '//*[@id="search_btn"]').click()
sleep(1)
driver.find_element(By.XPATH, '//*[@id="keywordInput"]').send_keys("-")
sleep(1)
driver.find_element(By.XPATH, '//*[@id="search_btn"]').click()
#处理当前页面数据,最终返回一个数组
def pageData(self)->list:
list = []
#下面两个正则是为了提取页面的数据
data = re.findall('<div class="j_joblist">.*?<div class="j_page">', self.driver.page_source)
data1 = re.findall('<p class="t">.*?<button track-type', data[0])
#下面这个循环是取出上面正则提取出来的数据,上面正则提取的是一个数组
for i in data1:
data2 = re.findall('>.*?<', i) #根据上面正则提取出的页面数据,进一步得到最终所需要的信息
data3 = [a[1:-1] for a in data2 if a != '><' and a != '> <'] #去掉提取出来所有信息两边的残留
data4 = '' #因为页面爬取的待遇所有都是合在一起的,所以单独处理这条数据,这儿先定义它
for d in data3[4:-4]: #这个循环就是为了吧合在一起的待遇这条数据用空格分割开
data4 += str(d + ' ')
#这儿就是从页面上一条招聘信息提取出来的所有信息,然后把整个页面上的通过循环存进数组中
list.append([data3[-3],data3[0],data3[2],data4,data3[3].split('|')[1],
data3[3].split('|')[2],data3[3].split('|')[0],"",data3[-2],data3[-1]])
return list
#因为这个网站做了反爬处理,所以要滑动验证才行,这儿做的是一个滑动验证
def sliderCheck(self):
try: # 有时候又不需要验证,导致找不到页面元素可能报错,所以加了一个try
action = ActionChains(self.driver)
source = self.driver.find_element(By.XPATH, '//*[@id="nc_1_n1z"]')
action.click_and_hold(source).perform()
action.move_by_offset(400, 0)
action.release().perform()
except:
pass
#把数据写入文件,传入的是一个list
def writeCsv(self,list):
self.write.writerow(list)
#主程序-运行程序
def main(self):
self.inIndex() #进入网站页面
sleep(1)
for i in range(1): #循环-设置爬取多少页
for i in self.pageData(): #循环一个页面上爬取出来的二维数组,把该数组里面的数组传入写入文件函数
self.writeCsv(i)
self.driver.find_element(By.CLASS_NAME, 'next').click() #点击事件-分页
sleep(2)
self.driver.close()
self.file.close()
#入口函数
if __name__ == '__main__':
GetData().main()
总结:页面爬取其实相对于接口爬取来说更简单更容易;唯一的缺点就是 爬取速度慢,容易出错、还容易被检测到;所以在页面爬取我们需要去处理各个定位元素操作流程中的休眠时间以及异常处理;事件太快了页面元素还没加载完成,所以会导致定位不到元素从而报错,流程就会中断;相比于接口爬取来说很不友好;唯一的好处就是简单快捷















 6685
6685











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











