







CLIP 论文整体架构
该论文总共有 48 页,除去最后的补充材料十页去掉,正文也还有三十多页,其中大部分篇幅都留给了实验和响应的一些分析。
从头开始的话,第一页就是摘要,接下来一页多是引言,接下来的两页就是讲了一下方法,主要说的是怎么做预训练,然后从第六页一直到第十八页全都是说的实验,当然这里面也包括了怎么去做 zeor-shot 的推理,还有包括这种 prompt engineering 、prompt ensemble 等等,算是方法和实验的合体。
讲完了实验作者大概花了一页篇幅去讨论了一下 CLIP 工作的局限性,然后接下来的五页作者主要就是讨论了一下CLIP这篇工作有可能能带来的巨大的影响力,在这个部分首先讨论的是 bias ,即模型的偏见,然后讨论了 CLIP 有可能在监控视频里的一些应用,最后作者展望了一下 CLIP 还有哪些可以做的这个未来工作,然后在讲完了所有的这些方法、实验和分析之后作者用了一页的篇幅就大概说了一下相关工作,最后给出了一个简短的小结论。
CLIP 到底是什么
CLIP 的迁移学习能力非常强,其预训练好的模型能够在任意一个视觉分类的数据集上取得不错的效果。
最重要的是,其是 zero-shot 的:

预训练的含义:

作者在这篇文章中做了超级多的实验,在超过三十个数据集上做了测试:

CLIP 到底是什么?到底是怎么去做到 zero-shot 推理的?
看文章中的图一:
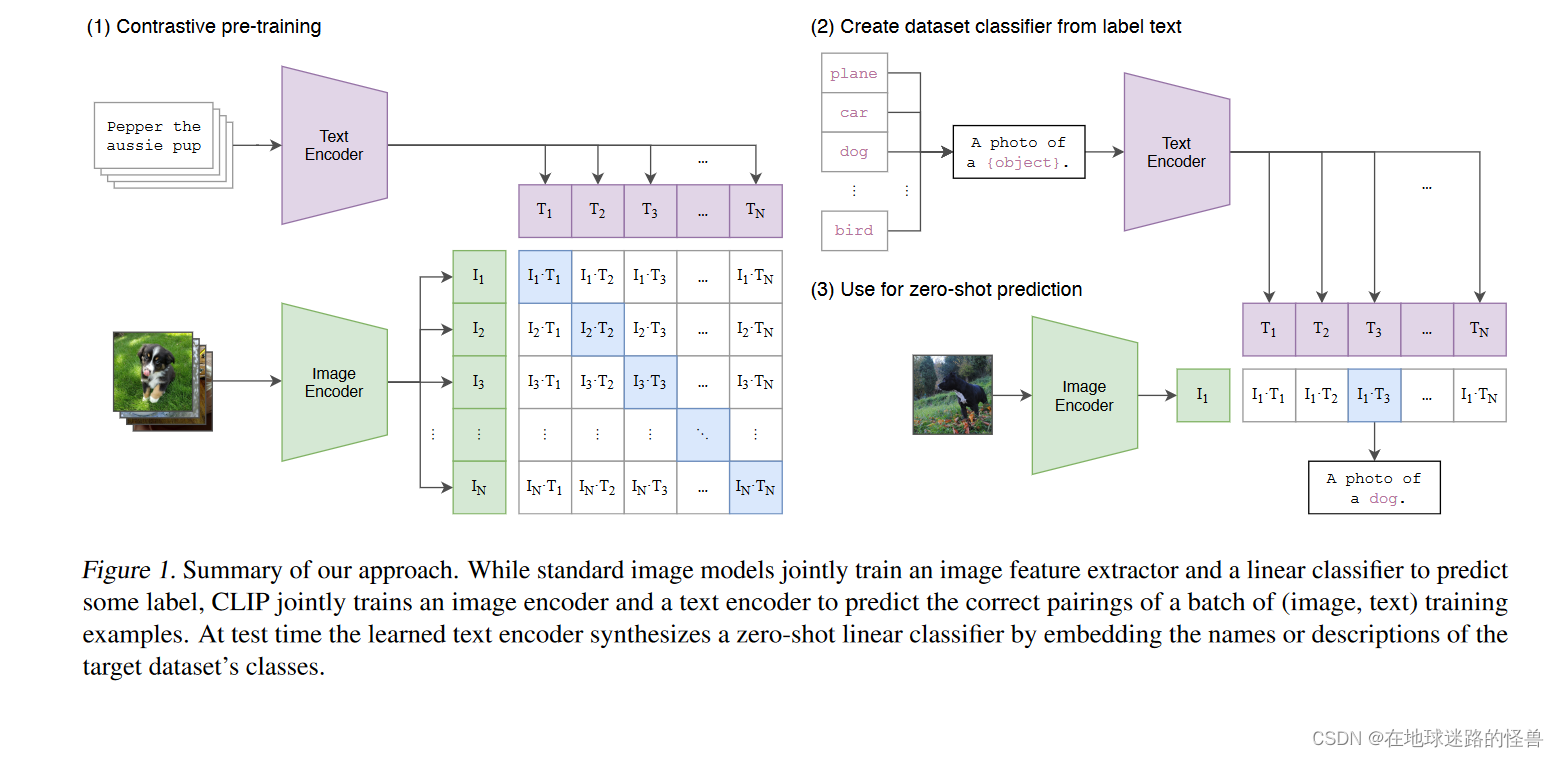
上图是模型总览图,这是 CLIP 工作的一个大概流程。
CLIP 是如何进行预训练的?从题目中可以窥见一二,通过自然语言处理那边来的一些监督信号,我们可以训练一个迁移效果很好的视觉模型。因此明显这是一个牵扯到文字、图片的一个多模态的工作。
那么是如何利用来自自然语言处理那边的信号的呢?在训练过程中,模型的输入是一个图片和文字的配对。以上图为例,图片是一只狗,配对的文字也是 pepper 是一只小狗。
然后图片会通过一个 Image Encoder 图片编码器,从而得到一些特征(这里的编码器可以是一个 ResNet 也可以是一个Vision Transformer)。对于文本句子来说其也会通过一个文本编码器,从而得到一些文本的特征。
假设现在每个Training Batch(训练批次)里都有 n 个这样的图片文本对,也就是说有 n 个句子,n 张图片,对应的会得到 n 个文本特征以及 n 个图片特征,而 CLIP 就是在这些特征上去做对比学习。
对比学习非常的灵活,只需要一个正样本和一个负样本的定义即可,其他的都是正常套路。
正样本是啥?其实很简单,上面图中的一个配对的 图片-文本对 就是一个正样本。因为其描述的是一个东西。
所以说在上图中的特征矩阵里,沿着对角线方向上的内容都是正样本:
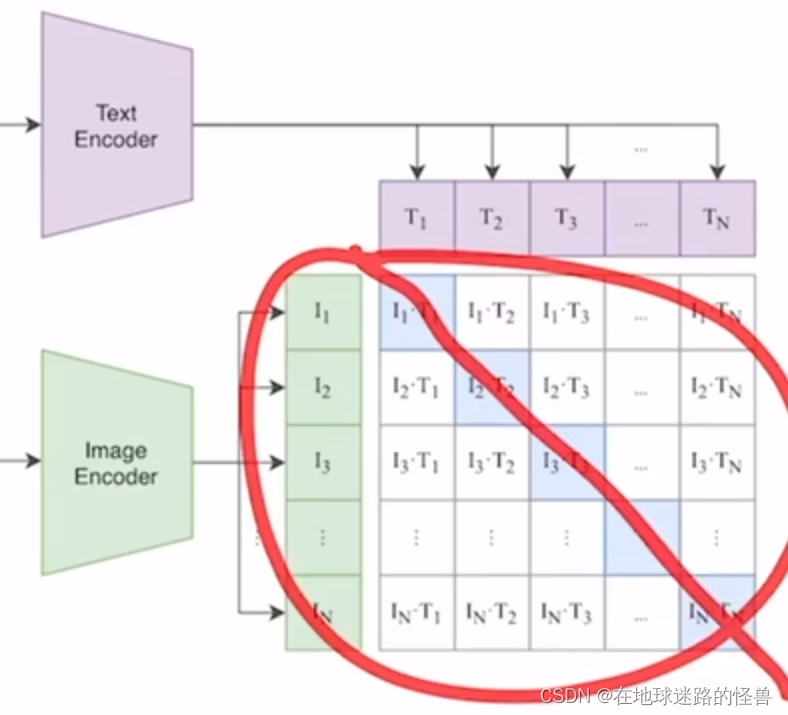
因为 I1T1 、I2T2 这些本身就都是配对的。
那么剩下矩阵中的不是对角线上的其他元素就都是负样本了。也就是说我们有 n 个正样本,然后又 n 平方减去 n 个负样本。
一旦有了正负样本,模型就可以通过对比学习的方式去训练起来了,完全不需要任何手工的标注。
但是对于这种无监督的预训练方式,也就是对比学习,其是需要大量的数据的,因此 OpenAI 还专门去收集了这么一个数据集。该数据集中有 4 亿个 图片-文本对,数据质量很高,这也是为什么 CLIP 这个预训练模型为什么能这么强大的主要原因之一。
CLIP 如何做推理的
CLIP 如何去做 zeor-shot 的推理的呢?
从上面可以知道,CLIP 这个模型经过预训练之后其实只能得到一些视觉上和文本上的特征,他并没有在任何分类的任务上去做继续的这种训练或者微调,因此他是没有分类头的,没有分类头怎么做推理呢?
分类头:

本文提出了一个非常巧妙的利用自然语言的一种办法,叫 prompt template。
这里使用 Image Net 数据集做一个例子。
CLIP 就是先将 Image Net 里这 1000 个类,比如飞机啊、汽车啊、狗啊变成一个句子:
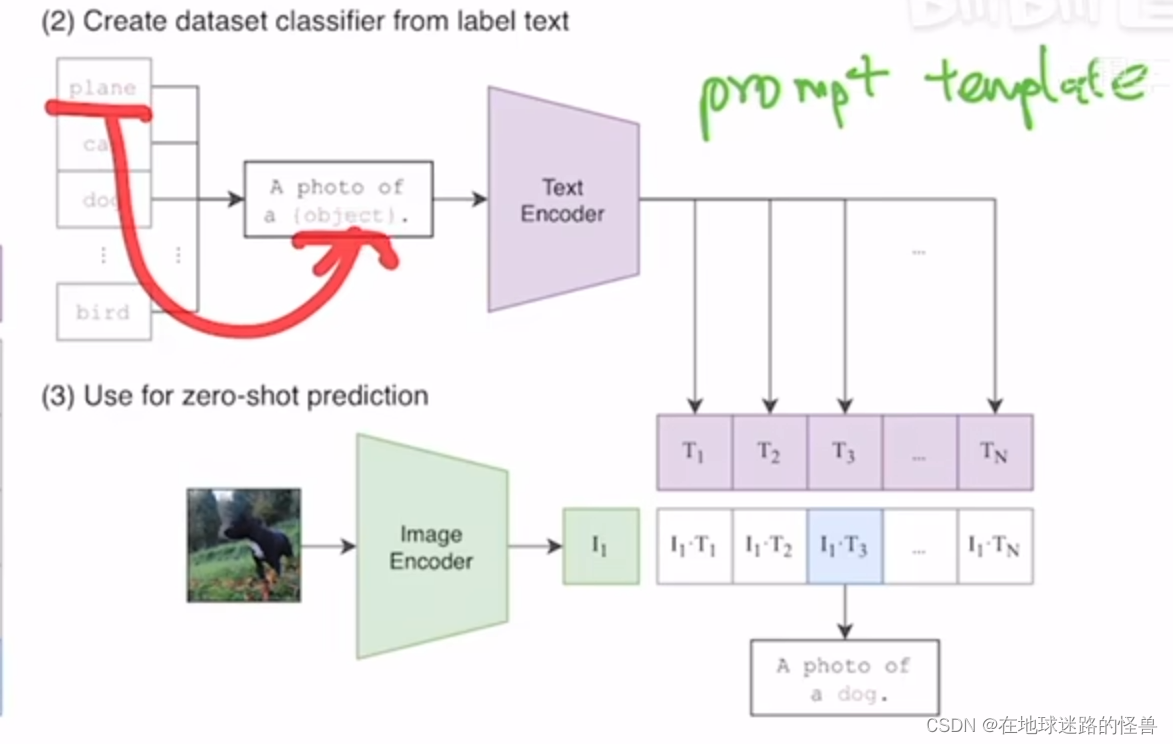
从上图可以看到,也就是用 plane、cat、dog 等去替代花括号包起来的 object 的这个内容,就相当于一个模板(在很多 it 技术领域都有类似概念的存在)。
有 1000 个类,那么就生成了这样的 1000 个句子。然后这 1000 个句子通过我们之前预训练好的这个文本编码器 Text Encoder 就会得到一千个这个文本的特征。
但其实直接使用原生的那些单词去做文本特征的提取也是可以的,但是因为在模型预训练的时候我们的图片每次看到的基本都是一个句子,如果在推理的时候突然把所有的这个文本都变成了一个单词,那这样就跟在训练的时候看到的这个文本就不太一样了,效果就会稍有下降。
另外一个单词如何变成一个句子也是很有讲究的。因此 CLIP 这篇论文在后面还提出了 prompt engineering 和 prompt ensemble 这两种方式去进一步的提高这个模型的准确率。而不需要重新训练这个模型。
然后在推理的时候,不论此时来到的什么图片,我们只要将这个图片扔给这个图片的编码器,得到了这个图片特征之后就让这个图片特征去跟所有的这些文本特征去做这个 cosine similarity(余弦相似度):

计算相似性,最后这个图像特征和这里的哪个文本特征最相似,那么就把这个文本特征和所对应的那个句子挑出来,从而完成了分类这个任务:
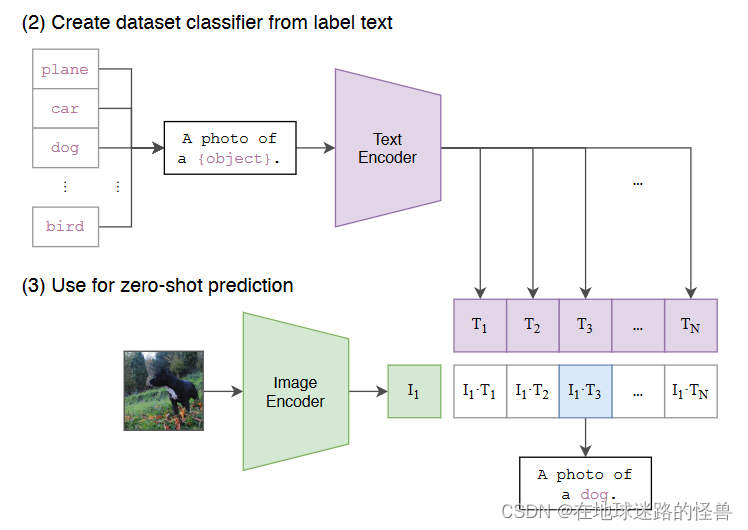
也就是这张图片里有狗这个物体。
并且在 CLIP 真正使用的时候,这里的标签还是可以改的(比如不是飞机,而是坦克),不光是 Image Net 这 1000 个类,可以换成任意的单词,同样图片也可以是任何的图片,然后依旧可以使用这种通过算余弦相似度的方式去判断这张图片里到底还有哪些物体。
这个性质就是CLIP的强大之处,因为它彻底摆脱了 categorical label 的这个限制,也就是说不论是在训练的时候还是在推理的时候,其都不需要有一个这么提前定好的这么一个标签列表了。任意给我一张照片,我都可以通过给模型去喂这种不同的文本句子从而知道这张图片里到底有没有我所感兴趣的物体。
而且 CLIP 不光是能识别新的物体,由于它真的把这个视觉的语义和文字的语义联系到了一起,所以它学到的这个特征的语义性非常强,迁移效果也非常的好。
基于CLIP的应用
基于CLIP 的图像生成,用文本去指导图像的生成。
基于CLIP 的物体检测和分割。
基于CLIP 的用来做视频检索的,意思是给定一段视频,然后想去搜索这个视频里到底有没有出现过某个物体或者是场景,那么就可以通过直接输入文本的这种形式去做检索。


















 1561
1561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











