







导语
- 会议:ICML 2021
- 链接:https://proceedings.mlr.press/v139/radford21a/radford21a.pdf
当前的计算机视觉系统通常只能识别预先设定的对象类别,这限制了它们的广泛应用。为了突破这一局限,本文探索了一种新的学习方法,即直接从图像相关的原始文本中学习。本文开发了一种简单的预训练任务,通过预测图片与其对应标题的匹配关系,从而有效地从一个包含4亿图像-文本对的大数据集中学习图像表征。该方法能够在没有额外特定数据训练的情况下,让模型在多达30种不同的计算机视觉任务上达到与传统方法相媲美的性能。例如,在不使用任何训练数据的情况下,CLIP模型在ImageNet上实现了与原始ResNet-50相同的准确率。
1 引言与动机
直接从原始文本中学习的预训练方法在过去几年里已经彻底改变了自然语言处理领域。通过将“文本到文本”作为标准化的输入输出接口,如GPT-3等,这些架构能够在无需针对具体任务设计专门的输出头的情况下,直接转移到下游数据集。尽管在计算机视觉领域,使用众包数据集如ImageNet进行模型预训练仍是常规做法,但有研究显示,从网络文本直接学习的预训练方法在计算机视觉中同样具有突破性潜力。历史上,已有多个工作展示通过训练模型预测与图像相关的文字,可以有效地提升图像的表示学习。
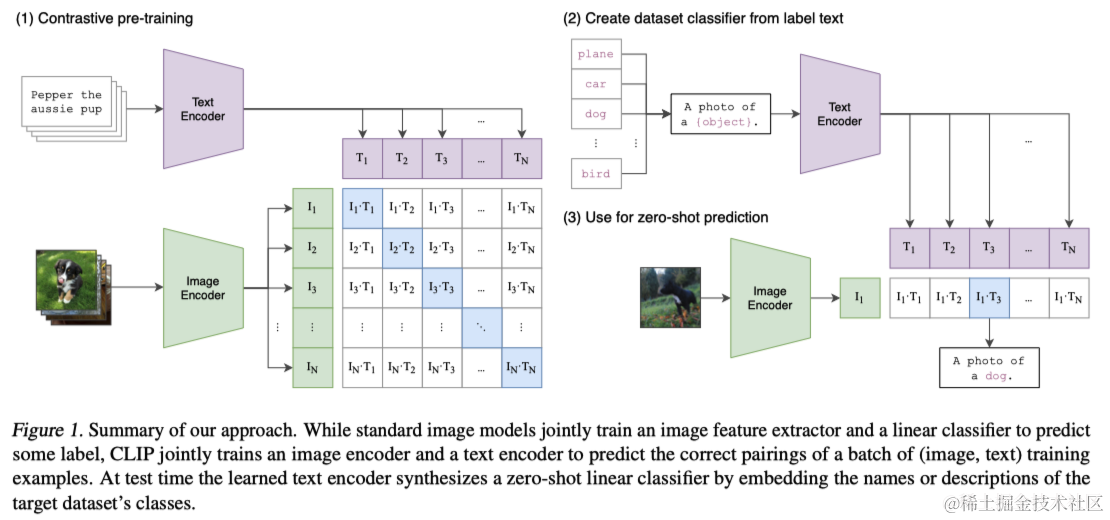
在此基础上,本文提出了一个新的模型CLIP(Contrastive Language-Image Pre-training),这是一个简化版的ConVIRT,旨在通过大规模的自然语言监督学习图像表示。本文首先创建了一个包含4亿图像-文本对的新数据集,并发现CLIP在从自然语言监督中学习方面极为有效。通过对比训练多个模型,观察到转移性能与计算投入成平滑可预测的关系。
CLIP在预训练期间学会执行包括OCR、地理定位和动作识别在内的多种任务,并且在30多个现有数据集上的零样本转移性能可以与先前的任务特定监督模型相媲美。此外,CLIP的线性探针(Linear Probing,即固定模型参数,仅微调分类头)表示学习分析显示其性能优于最佳公开可用的ImageNet模型,并具有更高的计算效率。这些发现突显了利用自然语言进行图像表示学习的巨大潜力,同时也提示了这种方法在未来的政策和伦理方面可能带来的重要影响。
2 方法
2.1 自然语言监督
尽管利用自然语言作为训练信号的思想并不新颖,但相关工作中使用的术语多样且似乎相互矛盾。不同的研究,虽然都采用了从文本学习视觉表征的方法,但被分别标记为无监督、自监督、弱监督和监督学习。本文强调,这些研究的共同点在于对自然语言作为训练信号的重视,而不是具体方法的细节。
随着深度上下文表示学习的进步,我们现在具备了有效利用这一丰富监督源的工具。与传统的众包图像分类标注相比,自然语言监督的扩展性更强,它允许从互联网上的大量文本中被动学习,而不需要符合典型的机器学习格式。此外,与大多数无监督或自监督学习方法相比,从自然语言学习不仅仅是学习一种表征,而且还能将该表征与语言连接起来,从而实现灵活的零样本转移。接下来的部分将详细介绍本研究确定的具体方法。
2.2 创建足够大的数据集
虽然已有数据集如MS-COCO、Visual Genome和YFCC100M提供了一定的图像-文本对,但它们的规模相对较小或元数据质量参差不齐。例如,YFCC100M数据集虽然拥有1亿张照片,但其元数据的实用性有限,过滤后只剩1500万张照片,与ImageNet的规模相当。
为充分发挥自然语言监督的潜力,本文构建了一个新的、包含4亿对(图像,文本)的数据集,称为WIT(WebImageText)。该数据集从互联网上公开可用的资源中收集而来,旨在涵盖尽可能广泛的视觉概念。在数据集构建过程中,作者使用了500,000个搜索查询,并通过每个查询最多包含20,000对(图像,文本)来实现类别的近似平衡。这样的方法不仅提供了与GPT-2训练用的WebText数据集相似的词汇量,还为自然语言视觉监督提供了一个前所未有的规模。
2.3 选择高效的预训练方法
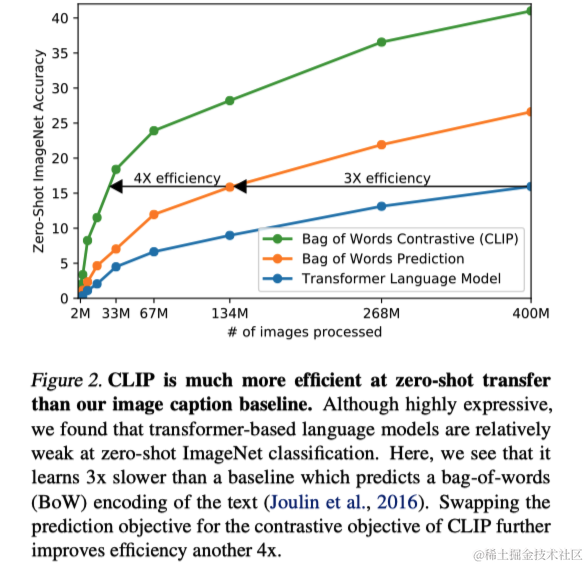
鉴于先前系统例如ResNeXt101-32x48d和Noisy Student EfficientNet-L2的高计算需求,从自然语言中学习视觉概念是一项艰巨的任务。因此,训练效率成为了成功扩展自然语言监督的关键。作者最初尝试了类似于VirTex的方法,即从零开始共同训练图像CNN和文本Transformer来预测图像的标题。但是,这种方法在效率上的扩展遇到了困难。作者随后探索了一种可能更简单的代理任务,即预测哪些文本与哪些图像配对,而非预测文本的确切单词。这一转变到使用对比目标后,观察到零样本转移到ImageNet的效率提高了四倍。
为此,作者开发了CLIP模型,它通过预测批次中实际发生的图像和文本配对来训练。CLIP通过联合训练图像编码器和文本编码器来学习一个多模态嵌入空间,最大化真实配对的图像和文本嵌入的余弦相似度,同时最小化错误配对的相似度。此外,CLIP模型的训练相对简化,不依赖于预训练权重或复杂的投影技术,仅使用线性投影,并直接在训练中优化温度参数,避免了作为超参数的调整。
CLIP的简单伪代码实现如下:
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 480
480

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









