






首先上代码(头文件是我把所有C头文件整合到一个文件,拷贝到/usr/include/里面了)
#include <myhead.h>
void print(int x)
{
printf("%d\n", x);
}
int main()
{
pid_t pid1, pid2;
#ifdef a
print(1); // 只有一条进程
pid1 = fork();
print(2); // 有两条进程
pid2 = fork();
print(3); // 有四条进程
wait(NULL);
wait(NULL);
wait(NULL);
#else
print(1);
pid1 = fork();
print(2);
if (pid1 == 0)
{
pid2 = fork();
print(3);
}
print(4);
wait(NULL);
wait(NULL);
#endif
printf("进程:%d结束。\n",getpid());
return 0;
}关于进程的创建,我的理解为:创建的新子进程,会复制所有代码,但调用fork()函数之前的代码就不会运行了
#ifdef a
print(1); // 只有一条进程
pid1 = fork();
print(2); // 有两条进程
pid2 = fork();
print(3); // 有四条进程
wait(NULL);
wait(NULL);
wait(NULL);
wait(NULL);
#else这里用了一个条件编译,我们先运行第一段代码,需要加上 -D和自己代码中的字符,我用的是a,下面的命令行'a'是我自己取的别名,也就是"./a.out"

我们可以看到,第一次调用fork前,我们打印了一个print(1),最终数字1只打印了一次,也就是主进程打印的。然后此时一共有两条进程,print(2)就打印了两个2,也就是主进程和他的子进程打印的。之后我们再调用一次fork()函数,根据上面的理论,主进程和它的子进程都会调用一次,各创建一条属于自己的子进程(有点类似细胞分裂),此时就有了四条进程,然后print(3)就会被四个进程各执行一次,数字3也就打印了4次当然,最后那条printf("进程结束")也一样打印了四次。还有一点,这个打印顺序似乎有点乱,这是因为进程创建需要时间,创建新进程时,父进程不会等待子进程创建完,而是继续执行自己下面的代码。当3打印出来时,就意味着有进程运行完了,但是上面打印了两个3时,却只打印了一行进程结束,这是因为有一个3是主进程打印的,主进程需要等待所有子进程结束。
在上面的代码中,主进程调用了两次 fork() 函数,创建了三个子进程。然后,主进程调用了三次 wait() 函数,分别等待三个子进程结束。而子进程中的 wait() 函数调用不会产生任何效果。当所有子进程都结束后,主进程才会结束。
补充:wait() 函数只能用于等待当前进程的子进程。如果当前进程没有子进程,或者所有子进程都已经结束,那么 wait() 函数会立即返回。因此,在子进程中调用 wait() 函数不会产生任何效果。
再来看第二段代码
#else
print(1);
pid1 = fork();
print(2);
if (pid1 == 0)
{
pid2 = fork();
print(3);
}
print(4);
wait(NULL);
wait(NULL);
#endif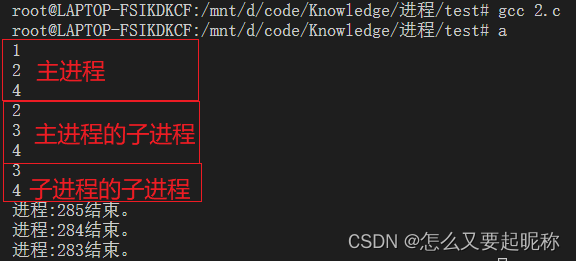
第二段与第一段的不同之处在于,第二次调用fork()函数通过if(pid1==0){}放在子进程中。也就是说,主进程只创建一次进程,而子进程会创建第二次进程,所以一共有3条进程。这次打印明显没有第一次那么乱了,因为主进程创建的子进程同时,自己的任务就结束了,直接打印了4出来,而子进程可能才创建出来。当然,这个子进程的创建还和cpu算力有关系,cpu越强,进程创建的时间就越短,也就会遇到各种不同的打印顺序,如果你快速运行多次可执行文件,你会发现打印顺序也不一样,应该是cpu忙不过来了。
如果上述有不对的地方,欢迎大家指正。因一边写博客一边改代码,所以代码块可能有不一样的,以第一段完整代码为主。
















 1990
1990











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











