







本文借鉴了数学建模清风老师的课件与思路,可以点击查看链接查看清风老师视频讲解:清风数学建模:https://www.bilibili.com/video/BV1DW411s7wi
目录
一、K最近邻(KNN)
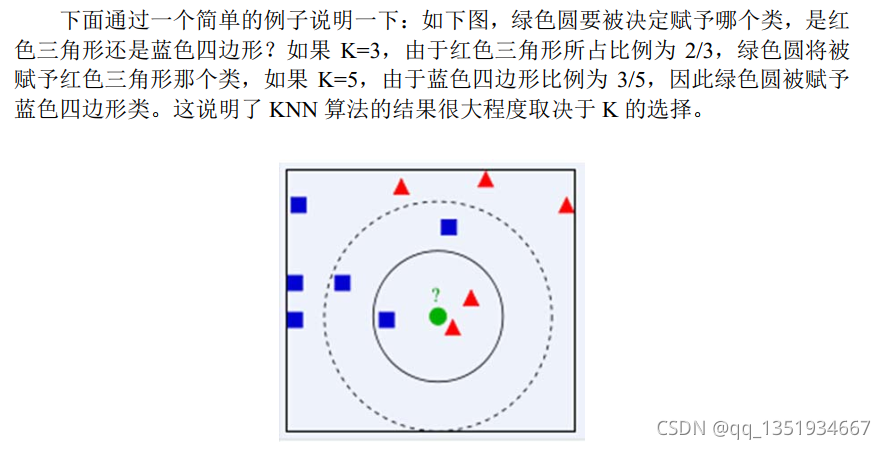
KNN算法的简单例子:
KNN算法用于分类的流程图:

二、决策树
决策树=决策+树 我们定义决策树最初的问题所在的结点叫根节点,得到结论的结点叫叶节点,根节点和叶节点之间的结点叫内部节点。
我们从树的根节点开始往下面进行决策,对决策的结果进行分类,不同的类别分别对应不同的内部节点,之后又从内部节点开始往下面进行决策,对决策的结果进行分类,直至到达了树的叶节点为止。
以下面这颗决策树为例,计划将动物根据这颗决策树来区分它们是哺乳类还是非哺乳类:

当我们发现了一种新的动物,我们就可以通过这颗决策树判断它是哺乳动物还是非哺乳动物。
决策树算法的核心解决问题:
①如何从数据表中找出最佳节点和最佳分枝?
②如何让决策树停止生长,防止过拟合?
三、支持向量机
四、集成学习
集成学习(ensemble learning)是时下非常流行的机器学习算法,它本身不是一个
单独的机器学习算法,而是通过在数据上构建多个模型,集成所有模型的建模结果。
根据个体学习器的生成方式,目前的集成学习方法大致可分为两大类:
(1) 个体学习器间存在强依赖关系、必须串行生成的序列化方法。这种方法我们称为提升法( Boosting),其代表模型有 Adboost(自适应提升算法)(MATLAB里自动选择该算法)、GBDT(梯度提升决策树)、 Xgboost(极端梯度提升算法)。
(2) 个体学习器间不存在强依赖关系、可同时生成的并行化方法。这种方法我们称为装袋法(Bagging), 另外, 大家经常听到的随机森林(Random Forest)(MATLAB里自动选择该算法)算法可以视为装袋法(Bagging) 的一种变形, 它们都是对决策树进行集成。
五、实时脚本的介绍
创建一个实时脚本后,运行程序后会直接在程序的下方得到结果。
在里面可直接添加文字,快捷键CTRL+E切换文本和代码。
若只想运行一部分代码,可快捷键CTRL+ALT+ENTER创建节,只运行该节的代码。
运行某一节代码快捷键CTRL+ENTER。
打开试图里的数据提示功能,光标落在变量那里,会显示该变量的值。
六、导入数据并生成脚本
首先将原始的数据集拆分成两个Excel文件(一个为已知y的,一个为未知y的),如下图(该数据中y为种类)。

将该数据导入进MATLAB中,如下图:

导入后记得将名字改一下,如下图(data1为该数据集的名字,下面的为指标的名字,若在这里改了指标名,后面导入的数据集也应更改):

选择生成脚本,生成脚本后,在之后直接运行该脚本即可导入数据。

注:要将MATLAB的路径变更为数据集所在的路径下,也可直接调用命令(路径为自己的数据集所在路径):
cd'E:\建模清风\机器学习进阶课程配套文件\机器学习进阶课程配套文件\1.鸢尾花数据集'生成后的脚本如下:
%% 导入电子表格中的数据
% 用于从以下电子表格导入数据的脚本:
%
% 工作簿: E:\建模清风\机器学习进阶课程配套文件\机器学习进阶课程配套文件\1.鸢尾花数据集\鸢尾花1.xlsx
% 工作表: Sheet1
%
% 由 MATLAB 于 2022-07-03 14:34:01 自动生成
%% 设置导入选项并导入数据
opts = spreadsheetImportOptions("NumVariables", 5);
% 指定工作表和范围
opts.Sheet = "Sheet1";
opts.DataRange = "A2:E145";
% 指定列名称和类型
opts.VariableNames = ["VarName1", "VarName2", "VarName3", "VarName4", "VarName5"];
opts.VariableTypes = ["double", "double", "double", "double", "categorical"];
% 指定变量属性
opts = setvaropts(opts, "VarName5", "EmptyFieldRule", "auto");
% 导入数据
data1 = readtable("E:\建模清风\机器学习进阶课程配套文件\机器学习进阶课程配套文件\1.鸢尾花数据集\鸢尾花1.xlsx", opts, "UseExcel", false);
%% 清除临时变量
clear opts七、导出模型并进行预测
导入完数据后,就可以使用分类学习器了,可以在上方的App中点击分类学习器,也可以使用下面的代码调用。
classificationLearner
% 调用回归学习器的命令是regressionLearner点击 在左上角的新建会话将data1(因为data1里面有y)导入进来。

导入之后如下图:

可将所有模型都训练一遍,选择其中准确度最高的模型导出,本数据集里准确度最高为线性判别分析,如下图:

将该模型导出后,会在命令行显示如下:
变量已在基础工作区中创建。
从 分类学习器 导出了结构体 'trainedModel'。
要对新表 T 进行预测:
yfit = trainedModel.predictFcn(T)
有关详细信息,请参阅 How to predict using an exported model。此时直接运行下面代码,可得到data2的分类结果。
trainedModel.predictFcn(data2) 八、导出代码并进行预测
生成函数即生成代码。

生成代码后,操作以下三步:
①将代码的第一行注释
②在
inputTable = trainingData;的前面一行添加
trainingData = data1;③找到
trainedClassifier.predictFcn = @(x) discriminantPredictFcn(predictorExtractionFcn(x));
在代码最后另起一行,输入
trainedClassifier.predictFcn(data2)现在运行所有的代码即可得到预测结果。
九、决策树的预测和可视化
我们以决策树模型为例,对于决策树模型,我们可以使用下面的代码将它可视化(如果图上节点太多,图会非常丑,这时候就别放论文):
如果使用的导出模型:
figure(1)
view(trainedModel.ClassificationTree,'Mode','graph') % 根据你自己导出来的模型名称修改如果是生成函数,在代码最后加上下面这段代码:
figure(2)
view(trainedClassifier.ClassificationTree,'Mode','graph')可视化结果如下:

十、交叉验证的测试集和随机数种子
K 折交叉验证
图上的“平均”两个字大家可以不用管,容易给人产生误导。 我们进行交叉验证的目的是为了看我们的模型在测试集上的表现,即为了衡量模型的泛化能力。
在上面的 10 折交叉验证中,我们将这个模型训练了十次,每次的测试集都是新的,且每一个样本都会作为一次测试集,作为测试集时, MATLAB 会给我们返回它们的预测结果。
因此经过交叉验证后,我们就能得到每个样本的预测结果,又由于我们知道每个样本它们的真实的结果,因此我们可以将所有样本预测的结果和真实的结果汇总成一个完整的混淆矩阵,然后通过这个混淆矩阵来计算我们所需要衡量的指标,例如分类准确率、 f1 分数等。
随机数种子函数:rng(n) n为整数,将这个函数放在代码的最前面,运行得到的结果会固定住。因为交叉验证每次的训练集不一样,所以结果可能也会不一样,用随机数种子就可以固定住。
十一、多分类问题的F1分数计算原理
11.1 二分类问题的 F1 分数
首先要选好正类是哪一个。 在机器学习中,我们通常将更关注的事件定义为正类事件。然后计算下面这些指标:



11.2 多分类问题的 F1 分数
多分类的 F1 分数分为两种,一种叫做 micro F1 分数(micro[ˈmaɪkroʊ]表示微观的) ,另一种叫做 macro F1 分数(macro[ˈmækroʊ]表示宏观的)。
和二分类的 F1 分数不同, micro F1 分数和 macro F1 分数不需要指定正类是什么,因为它们计算的是一个综合的分数。(二分类别用这两个 F1 分数,没见过有人在二分类用过它们)
micro F1 分数: 每个类别分别作为正类时,都可以算出来一组 TP、 FP 和 FN 的值, 我们
把它们分别求和来计算所有样本的 TP、 FP 和 FN,然后再套用 F1 分数的公式。
macro F1 分数, 它有两种定义方法:
第一种: 先计算出每一类作为正类时的 F1 分数,然后对所有的 F1 分数求平均。(MATLAB和 Python 中用的都是这一种计算方法)
第二种: 先计算出每一类作为正类时的精确率 P 和召回率 R,然后分别计算 P 和 R 的平均值,再利用公式𝑭𝑭𝟏𝟏 = 𝟐𝟐 × 𝑻𝑻×𝑹𝑹𝑻𝑻+𝑹𝑹用该平均值计算 F1 分数。
(1) Macro-F1 Score 与Mincro-F1 Score(有例子)
(2) [评价指标系列 01] Micro-F1 和 Micro-F1(有公式, 它用的 macroF1 公式是第二种)
十二、MATLAB计算F1分数
使用场景: micro F1 分数在计算公式中考虑到了每个类别的数量,所以适用于数据分布不平衡(各个类别的数量差异较大) 的情况; macro F1 分数没有考虑到数据的数量,所以会平等的看待每一类。 因此, 如果你的数据分布不平衡,推荐使用 micro F1 分数;否则两个都可以汇报,这个并不绝对。另外,如果数据极度不平衡,例如某些类只有几个样本点,这时候两种方法都不好,你可以单独汇报你关心的正类的 F1 分数。
怎么看每一类的个数? MATLAB 的 tabulate 函数可以帮你,具体可以看视频演示。
目前, MATLAB 中没有直接计算 F1 分数的内置函数,这里我们可以使用别人写的代码。
参考格式如下:
Eugenio Bertolini (2021). Precision, Specificity, Sensitivity, Accuracy & F1-score
(https://www.mathworks.com/matlabcentral/fileexchange/86158-precision-specificitysensitivity-accuracy-f1-score), MATLAB Central File Exchange. Retrieved August 5, 2021.
注意, 原作者提交的这个代码中有一点问题,我给大家的 m 文件是正确的。
函数名: statsOfMeasure.m 使用前需要将这个函数放到 MATLAB 工作文件夹下
Excel里的例子代码如下:
zs = {'A','A','A','A','B','B','B','C','C'}; % 真实的结果
yc = {'A','A','B','C','B','B','C','B','C'}; % 预测的结果
ClassNames = {'A','B','C'}; % 样本有几类
C = confusionmat(zs,yc,'Order',ClassNames) % 先计算混淆矩阵(order后面指定类的顺序)
confusionchart(zs,yc) % 混淆矩阵的可视化 R2018b版本才被引入
stats = statsOfMeasure(C) % 调用我们下载的那个第三方的函数(函数要放到当前文件夹)返回结果:
C =
2 1 1
0 2 1
0 1 1
stats =
9×4 table
name classes macroAVG microAVG
________________ _____________________________ ________ ________"true_positive" 2 2 1 1.6667 1.6667
"false_positive" 0 2 2 1.3333 1.3333
"false_negative" 2 1 1 1.3333 1.3333
"true_negative" 5 4 5 4.6667 4.6667
"precision" 1 0.5 0.33333 0.61111 0.55556
"sensitivity" 0.5 0.66667 0.5 0.55556 0.55556
"specificity" 1 0.66667 0.71429 0.79365 0.77778
"accuracy" 0.55556 0.55556 0.55556 0.55556 0.55556
"F-measure" 0.66667 0.57143 0.4 0.54603 0.55556

最左侧的name列从上到下分别是:
TP FP FN TN 查准率或精确率 查全率或召回率 特异性 分类准确率 F1分数。
最后两列分别是Macro F1和Micro F1,我们只用管它们最下面的那个元素,上面的元素可以忽略。
Macro F1 = 0.54603 ; Micro F1 = 0.55556
因为我们是三分类问题,所以classes下面有三列,分别表示当正类为ClassNames中的某个元素时(三列依次对应A B C),其对应的衡量指标。
下面以决策树分类鸢尾花为例计算F1分数:
trainingData = data1;
inputTable = trainingData;
predictorNames = {'VarName1', 'VarName2', 'VarName3', 'VarName4'};
predictors = inputTable(:, predictorNames);
response = inputTable.VarName5;
isCategoricalPredictor = [false, false, false, false];
% 训练分类器
% 以下代码指定所有分类器选项并训练分类器。
classificationTree = fitctree(...
predictors, ...
response, ...
'SplitCriterion', 'gdi', ...
'MaxNumSplits', 100, ...
'Surrogate', 'off', ...
'ClassNames', categorical({'变色鸢尾'; '山鸢尾'; '维吉尼亚鸢尾'}));
% 使用预测函数创建结果结构体
predictorExtractionFcn = @(t) t(:, predictorNames);
treePredictFcn = @(x) predict(classificationTree, x);
trainedClassifier.predictFcn = @(x) treePredictFcn(predictorExtractionFcn(x));
% 向结果结构体中添加字段
trainedClassifier.RequiredVariables = {'VarName1', 'VarName2', 'VarName3', 'VarName4'};
trainedClassifier.ClassificationTree = classificationTree;
trainedClassifier.About = '此结构体是从分类学习器 R2021a 导出的训练模型。';
trainedClassifier.HowToPredict = sprintf('要对新表 T 进行预测,请使用: \n yfit = c.predictFcn(T) \n将 ''c'' 替换为作为此结构体的变量的名称,例如 ''trainedModel''。\n \n表 T 必须包含由以下内容返回的变量: \n c.RequiredVariables \n变量格式(例如矩阵/向量、数据类型)必须与原始训练数据匹配。\n忽略其他变量。\n \n有关详细信息,请参阅 <a href="matlab:helpview(fullfile(docroot, ''stats'', ''stats.map''), ''appclassification_exportmodeltoworkspace'')">How to predict using an exported model</a>。');
% 提取预测变量和响应
% 以下代码将数据处理为合适的形状以训练模型。
%
inputTable = trainingData;
predictorNames = {'VarName1', 'VarName2', 'VarName3', 'VarName4'};
predictors = inputTable(:, predictorNames);
response = inputTable.VarName5;
isCategoricalPredictor = [false, false, false, false];
% 执行交叉验证
partitionedModel = crossval(trainedClassifier.ClassificationTree, 'KFold', 5);
% 计算验证预测
[validationPredictions, validationScores] = kfoldPredict(partitionedModel);
% 计算验证准确度
validationAccuracy = 1 - kfoldLoss(partitionedModel, 'LossFun', 'ClassifError');
%下面就是利用交叉验证预测的结果和真实的结果来计算F1分数
ClassNames = unique(response) % y中各类的名称
group = response; % y所在的那一列(真实的类别)
C = confusionmat(group,validationPredictions,'Order',ClassNames); % 先计算混淆矩阵
stats = statsOfMeasure(C) % 调用我们下载的那个第三方的函数
tabulate(response)
% 查看每一类的样本量%使用场景:micro F1分数在计算公式中考虑到了每个类别的数量,所以适用于数据分布不平衡(各个类别的数量差异较大)的情况;macro F1分数没有考虑到数据的数量,所以会平等的看待每一类。因此,如果你的数据分布不平衡,推荐使用micro F1分数;否则两个都可以汇报,这个并不绝对。另外,如果数据极度不平衡,例如某些类只有几个样本点,这时候两种方法都不好,你可以单独汇报你关心的正类的F1分数。
tabulate(response) % 查看每一类的样本量
%在我们这个题里面,样本分布均匀,micro F1和macro F1分数都可以用,你可以都汇报,也可以选择任意一个汇报。别求平均就行,没见人把它们求平均。
Macro_f1_score = stats.macroAVG(end) % macro:宏观
Micro_f1_score = stats.microAVG(end) % micro:微观
%如果你关心某一类的F1分数,可以使用下面的代码得到它对应的F1分数
ClassNames
kk = 1; % 指定正类,kk是正类在ClassNames中的位置
F1_score1 = stats.classes(end,kk) % 单独指定某个正类对应的F1分数
%注意:如果你自己的数据是二分类问题,也可以调用这个函数来计算F1分数。但是在二分类别用micro F1和macroF1分数,没见过有人在二分类用过它们)
十三、绘制ROC曲线并计算AUC
ROC 曲线: 根据一系列不同的分类阈值,以真正类率(True Postive Rate, TPR)为纵坐标,假正类率(False Positive Rate, FPR)为横坐标绘制的曲线。(原理有兴趣的同学可以在 b 站搜索相关的视频)
ROC 曲线的用法: 将不同的模型的 ROC 曲线绘制在同一张图内,最靠近左上角的那条曲线代表的模型的分类效果最好。

(比较多个模型时,训练集和测试集的划分要一致,可以用 rng 函数固定随机数种子)
缺点: 实际任务中,情况很复杂,如果两条 ROC 曲线发生了交叉,则很难一般性地断言
谁优谁劣。
AUC: AUC 被定义为 ROC 曲线与下方的坐标轴围成的面积, AUC 的范围位于[0,1]之间,AUC 越大则模型的分类效果越好,如果 AUC 小于等于 0.5,则该模型是不能用的。通常AUC 大于 0.85 的模型就表现可以了。(当然这种标准不绝对,具体问题具体分析)
注意, ROC 曲线和 AUC 不区分二分类和多分类问题, 但我们需要选好正类是哪一个, 不同的正类对应的 ROC 曲线和 AUC 不同。
绘制单独一个模型的ROC曲线代码如下,以决策树为例:
% 刚开始就导出函数,然后令trainingData = data1;
trainingData = data1;
inputTable = trainingData;
predictorNames = {'VarName1', 'VarName2', 'VarName3', 'VarName4'};
predictors = inputTable(:, predictorNames);
response = inputTable.VarName5;
isCategoricalPredictor = [false, false, false, false];
% 训练分类器
% 以下代码指定所有分类器选项并训练分类器。
classificationTree = fitctree(...
predictors, ...
response, ...
'SplitCriterion', 'gdi', ...
'MaxNumSplits', 100, ...
'Surrogate', 'off', ...
'ClassNames', categorical({'变色鸢尾'; '山鸢尾'; '维吉尼亚鸢尾'}));
% 使用预测函数创建结果结构体
predictorExtractionFcn = @(t) t(:, predictorNames);
treePredictFcn = @(x) predict(classificationTree, x);
trainedClassifier.predictFcn = @(x) treePredictFcn(predictorExtractionFcn(x));
% 向结果结构体中添加字段
trainedClassifier.RequiredVariables = {'VarName1', 'VarName2', 'VarName3', 'VarName4'};
trainedClassifier.ClassificationTree = classificationTree;
trainedClassifier.About = '此结构体是从分类学习器 R2021a 导出的训练模型。';
trainedClassifier.HowToPredict = sprintf('要对新表 T 进行预测,请使用: \n yfit = c.predictFcn(T) \n将 ''c'' 替换为作为此结构体的变量的名称,例如 ''trainedModel''。\n \n表 T 必须包含由以下内容返回的变量: \n c.RequiredVariables \n变量格式(例如矩阵/向量、数据类型)必须与原始训练数据匹配。\n忽略其他变量。\n \n有关详细信息,请参阅 <a href="matlab:helpview(fullfile(docroot, ''stats'', ''stats.map''), ''appclassification_exportmodeltoworkspace'')">How to predict using an exported model</a>。');
% 提取预测变量和响应
% 以下代码将数据处理为合适的形状以训练模型。
%
inputTable = trainingData;
predictorNames = {'VarName1', 'VarName2', 'VarName3', 'VarName4'};
predictors = inputTable(:, predictorNames);
response = inputTable.VarName5;
isCategoricalPredictor = [false, false, false, false];
% 执行交叉验证
partitionedModel = crossval(trainedClassifier.ClassificationTree, 'KFold', 5);
% 计算验证预测
[validationPredictions, validationScores] = kfoldPredict(partitionedModel);
% 计算验证准确度
validationAccuracy = 1 - kfoldLoss(partitionedModel, 'LossFun', 'ClassifError');
%接下来加上下面这些代码
ClassNames = unique(response) % y中各类的名称
kk = 1; % 指定正类,kk是正类在ClassNames中的位置
posclass = ClassNames(kk); % 正类的名称
group = response; % y所在的那一列(真实的类别)
% validationScores是我们运行上面导出的代码得到的预测的分数(这个分数在不同的模型中代表的含义不同)
[x_roc,y_roc,~,auc] = perfcurve(group,validationScores(:,kk),posclass); % 第三个输出参数我们不需要,所以这里写成~
figure(3)
plot(x_roc,y_roc)
xlabel('假正类率FPR'); ylabel('真正类率TPR');返回AUC曲线:

当要比较多个
当要比较不同的模型,将ROC曲线绘制到同一个图上时,代码如下(这里以决策树和SVM为例,三个以上模型比较可类推):
%% 决策树
% 刚开始就导出函数,然后令trainingData = data1;
trainingData = data1;
inputTable = trainingData;
predictorNames = {'VarName1', 'VarName2', 'VarName3', 'VarName4'};
predictors = inputTable(:, predictorNames);
response = inputTable.VarName5;
isCategoricalPredictor = [false, false, false, false];
% 训练分类器
% 以下代码指定所有分类器选项并训练分类器。
classificationTree = fitctree(...
predictors, ...
response, ...
'SplitCriterion', 'gdi', ...
'MaxNumSplits', 100, ...
'Surrogate', 'off', ...
'ClassNames', categorical({'变色鸢尾'; '山鸢尾'; '维吉尼亚鸢尾'}));
% 使用预测函数创建结果结构体
predictorExtractionFcn = @(t) t(:, predictorNames);
treePredictFcn = @(x) predict(classificationTree, x);
trainedClassifier.predictFcn = @(x) treePredictFcn(predictorExtractionFcn(x));
% 向结果结构体中添加字段
trainedClassifier.RequiredVariables = {'VarName1', 'VarName2', 'VarName3', 'VarName4'};
trainedClassifier.ClassificationTree = classificationTree;
trainedClassifier.About = '此结构体是从分类学习器 R2021a 导出的训练模型。';
trainedClassifier.HowToPredict = sprintf('要对新表 T 进行预测,请使用: \n yfit = c.predictFcn(T) \n将 ''c'' 替换为作为此结构体的变量的名称,例如 ''trainedModel''。\n \n表 T 必须包含由以下内容返回的变量: \n c.RequiredVariables \n变量格式(例如矩阵/向量、数据类型)必须与原始训练数据匹配。\n忽略其他变量。\n \n有关详细信息,请参阅 <a href="matlab:helpview(fullfile(docroot, ''stats'', ''stats.map''), ''appclassification_exportmodeltoworkspace'')">How to predict using an exported model</a>。');
% 提取预测变量和响应
% 以下代码将数据处理为合适的形状以训练模型。
%
inputTable = trainingData;
predictorNames = {'VarName1', 'VarName2', 'VarName3', 'VarName4'};
predictors = inputTable(:, predictorNames);
response = inputTable.VarName5;
isCategoricalPredictor = [false, false, false, false];
% 执行交叉验证
partitionedModel = crossval(trainedClassifier.ClassificationTree, 'KFold', 5);
% 计算验证预测
[validationPredictions, validationScores] = kfoldPredict(partitionedModel);
% 计算验证准确度
validationAccuracy = 1 - kfoldLoss(partitionedModel, 'LossFun', 'ClassifError');
%接下来加上下面这些代码
ClassNames = unique(response) % y中各类的名称
kk = 1; % 指定正类,kk是正类在ClassNames中的位置
posclass = ClassNames(kk); % 正类的名称
group = response; % y所在的那一列(真实的类别)
% validationScores是我们运行上面导出的代码得到的预测的分数(这个分数在不同的模型中代表的含义不同)
[x1,y1,~,auc1] = perfcurve(group,validationScores(:,kk),posclass); % 第三个输出参数我们不需要,所以这里写成~
%这里因为有多个模型,所以是x1,y1,auc1,下面的x2,y2,auc2同理。
%% SVM
inputTable = trainingData;
predictorNames = {'VarName1', 'VarName2', 'VarName3', 'VarName4'};
predictors = inputTable(:, predictorNames);
response = inputTable.VarName5;
isCategoricalPredictor = [false, false, false, false];
% 训练分类器
% 以下代码指定所有分类器选项并训练分类器。
template = templateSVM(...
'KernelFunction', 'linear', ...
'PolynomialOrder', [], ...
'KernelScale', 'auto', ...
'BoxConstraint', 1, ...
'Standardize', true);
classificationSVM = fitcecoc(...
predictors, ...
response, ...
'Learners', template, ...
'Coding', 'onevsone', ...
'ClassNames', categorical({'变色鸢尾'; '山鸢尾'; '维吉尼亚鸢尾'}));
% 使用预测函数创建结果结构体
predictorExtractionFcn = @(t) t(:, predictorNames);
svmPredictFcn = @(x) predict(classificationSVM, x);
trainedClassifier.predictFcn = @(x) svmPredictFcn(predictorExtractionFcn(x));
% 向结果结构体中添加字段
trainedClassifier.RequiredVariables = {'VarName1', 'VarName2', 'VarName3', 'VarName4'};
trainedClassifier.ClassificationSVM = classificationSVM;
trainedClassifier.About = '此结构体是从分类学习器 R2021a 导出的训练模型。';
trainedClassifier.HowToPredict = sprintf('要对新表 T 进行预测,请使用: \n yfit = c.predictFcn(T) \n将 ''c'' 替换为作为此结构体的变量的名称,例如 ''trainedModel''。\n \n表 T 必须包含由以下内容返回的变量: \n c.RequiredVariables \n变量格式(例如矩阵/向量、数据类型)必须与原始训练数据匹配。\n忽略其他变量。\n \n有关详细信息,请参阅 <a href="matlab:helpview(fullfile(docroot, ''stats'', ''stats.map''), ''appclassification_exportmodeltoworkspace'')">How to predict using an exported model</a>。');
% 提取预测变量和响应
% 以下代码将数据处理为合适的形状以训练模型。
%
inputTable = trainingData;
predictorNames = {'VarName1', 'VarName2', 'VarName3', 'VarName4'};
predictors = inputTable(:, predictorNames);
response = inputTable.VarName5;
isCategoricalPredictor = [false, false, false, false];
% 执行交叉验证
partitionedModel = crossval(trainedClassifier.ClassificationSVM, 'KFold', 5);
% 计算验证预测
[validationPredictions, validationScores] = kfoldPredict(partitionedModel);
% 计算验证准确度
validationAccuracy = 1 - kfoldLoss(partitionedModel, 'LossFun', 'ClassifError');
%接下来加上下面这些代码
ClassNames = unique(response) % y中各类的名称
kk = 1; % 指定正类,kk是正类在ClassNames中的位置
posclass = ClassNames(kk); % 正类的名称
group = response; % y所在的那一列(真实的类别)
% validationScores是我们运行上面导出的代码得到的预测的分数(这个分数在不同的模型中代表的含义不同)
[x2,y2,~,auc2] = perfcurve(group,validationScores(:,kk),posclass); % 第三个输出参数我们不需要,所以这里写成~
%最后的画图
figure(4)
plot(x1,y1,'r','linewidth',2) % 红色、线宽为2
hold on % 继续在当前图上绘图
plot(x2,y2,'b','linewidth',2) % 蓝色、线宽为2
xlabel('假正类率FPR');
ylabel('真正类率TPR');
text1 = ['决策树, AUC = ', num2str(round(auc1,4))];
text2 = ['SVM, AUC = ', num2str(round(auc2,4))];
% strcat('决策树, AUC = ', num2str(round(auc1,4))) % 老版本请用这种方法拼接字符
% "决策树, AUC = " + round(auc1,4); % MATLAB2017a版本才支持双引号的字符串
legend(text1,text2) % 加上图例注:这里因为有多个模型,所以 x_roc,y_roc,auc 是x1,y1,auc1,下面的x2,y2,auc2同理。
返回的AUC曲线为:

多分类问题可只使用F1分数,因为F1分数不用指定正类,而ROC曲线需要指定正类,指定不同的正类时,AUC可能也会发生变化。
十四、调参的介绍和常见的超参数含义
14.1 调参的定义
调参即对模型的参数进行相应的调整,以期获得更好的预测效果!
其中参数又分为:模型参数和模型超参数。
模型参数: 模型内部的配置变量,可以用数据估计模型参数的值。比如线性回归或逻辑回归中的系数。它们会在模型训练过程中自动被计算出来,因此我们不需要管。
模型超参数:模型外部的配置,必须手动设置参数的值,其值不能从数据估计得到, 比如K 近邻分析的 K, 随机森林中决策树的个数。
总结: 模型参数是在训练过程中从数据中自动估计的,而模型超参数是需要手动设置的。
因此, 调参调整的是模型中的超参数。
14.2 调参的目的
调参调参,无非就是将模型的超参数调整到最佳的那个值,使得模型预测的效果最好。怎么去衡量预测效果的好坏呢?我们可以指定一些可用来衡量模型的泛化能力的指标。 例如,在分类问题中,我们可以使用 F1 分数或者 AUC 指标, 我们要找到一组超参数使模型的在测试集上的 F1 分数或者 AUC 指标最高。
14.3 MATLAB机器学习中可以调的参数
选择一个模型(例如选择 simple tree、粗略树)后,可以点击 Advanced(高级)选项查看:
2021a 版本

MATLAB 工具箱上面显示的参数都是一些比较重要的可以调节的超参数,如果你英文水平不好的话可以下载一个高版本的 MATLAB。
关于这些超参数的解释,大家可以在官网找到对应的文档:
Choose Classifier Options(要想弄懂参数的意义,必须要学习这些模型的理论推导)

十五、调参的三种方法
总的来说, 常见的调参方法有下面三种:
网格搜索: 在指定的参数范围内, 遍历每一种可能的情况,看哪组参数能使得模型的
效果最好。(类似于枚举法)
(1) 有些参数只存在少数几种可能, 例如下面决策树中的分裂准则中有三个选项可
以选择。
( 2)有些参数存在的可能性非常多, 甚至有无数种可能。例如最大分裂数,我们可
以取任意一个正整数。

这种情况下我们可以根据经验给定一个指定的搜索范围,并指定一个搜索的步长。
如果你学过决策树的理论,你就会知道决策树的最大分裂数不会超过样本个数。
假设现在样本个数为 500 的话,我们可以让最大分裂数从 1 开始取,每次增加 1(步长为 1) ,一直到 500 为止,这样会有 500 种不同的情况。
大家可以想一下, 如果每次训练平均需要 1 分钟, 那么调整这个参数需要训练 500 次,要等几个小时。。。如果你还需要同时考虑三种不同的分裂准则,那么需要训练3*500=1500 次。。。
这种情况下我们可以减少要搜索的范围,例如给定一个较大的步长,将最大分裂数分别设置为[10 20 30 … 490 500]进行搜索。这样得到的模型可能会比上面差一点,但是时间却缩短到原来的 1/10.
思考:怎么编程实现网格搜索?(用循环,有几个参数要搜索就是几层循环)
网格搜索的优点: 只要搜索的足够多,每种情况都尽量考虑到的话, 我们有很大的可能性能找到最好的模型。
网格搜索的缺点: 当要搜索的超参数比较多的时候, 十分消耗计算资源和时间。
随机搜索: 随机的在参数空间中进行采样(类似于蒙特卡罗模拟的思想)
Bergstra 和 Bengio 两位学者在他们 2012 年发表的文章中,表明随机搜索比网格搜索更高效。 在牺牲一些预测的准确性后, 可以大大缩短搜索的时间。
参考论文: Bergstra J, Bengio Y. Random search for hyper-parameter optimization[M].
JMLR.org, 2012.
贝叶斯调参:一种启发式的调参策略(调参过程中用到了历史信息)
原理可以参考:
强大而精致的机器学习调参方法:贝叶斯优化
或者
拟合目标函数后验分布的调参利器:贝叶斯优化
MATLAB 高版本的工具箱中内置了贝叶斯调参(以分类学习器为例,带有可优化开头的就是),我的 2021a 版本有, 2017a 版本没有,大家可以自己看下自己的版本有没有。

选择了可优化模型后, MATLAB 会自动调用贝叶斯调参过程,为我们选择效果最好的参数。
关于调参可供大家参考的链接:
https://blog.csdn.net/qq_27782503/article/details/90449858
https://www.jianshu.com/p/5378ef009cae
https://www.bilibili.com/video/BV1pX4y1F7LM
https://ww2.mathworks.cn/help/stats/bayesopt.html
若使用贝叶斯调参可引用论文《NCA降维和贝叶斯优化调参对分类模型的改进_李斌》
事实上, 如果要调的参数不多的话,网格搜索仍然是用的最普遍的调参方法。
在视频中,粗略介绍了一下各个模型的超参数,如果要调参的话,可以回顾一下该节视频。
十六、网格搜索对决策树调参
因为对鸢尾花进行分类是一个多分类问题,且不存在样本不平衡问题,因此我们可以考虑使用micro F1分数和macro F1分数。我这里就以micro F1分数为标准。
不同的模型设置的参数不一样,到时候需要自己改一下参数。(代码回忆不起来就看视频)
trainingData = data1;
inputTable = trainingData;
predictorNames = {'VarName1', 'VarName2', 'VarName3', 'VarName4'};
predictors = inputTable(:, predictorNames);
response = inputTable.VarName5;
isCategoricalPredictor = [false, false, false, false];
% 下面这两个变量在计算F1分数时会用到
ClassNames = unique(response); % y中各类的名称
group = response; % y所在的那一列(真实的类别)
% Train a classifier
% This code specifies all the classifier options and trains the classifier.
SplitCriterion = {'gdi','twoing','deviance'}; %分裂准则有三个可以选的,这里用元胞数组保存
MaxNumSplits = 1:30; % 最大分裂数(因为这个问题比较简单,我这里搜索设置的最大分裂数的上界是30)
num_i = length(SplitCriterion); % 第一个超参数SplitCriterion的可能性有3种
num_j = length(MaxNumSplits); % 第二个超参数MaxNumSplits的可能性有30种
MICRO_F1_SCORE = zeros(num_i,num_j); % 初始化最后得到的结果(初始化是为了加快代码运行速度)
mywaitbar = waitbar(0); % 设置一个进度条
TOTAL_NUM = num_i*num_j; % 总共要计算多少次
now_num = 0; % 已经计算了多少次
for i = 1:num_i
for j = 1:num_j
rng(520) % 设定随机数种子,保证结果的可重复性(这里的520也可以换成其他的数字)
% 注意,如果超参数是字符类型的话,它是被保存在元胞数组中的,取出时需要使用大括号才能得到字符型
classificationTree = fitctree(...
predictors, ...
response, ...
'SplitCriterion', SplitCriterion{i}, ...
'MaxNumSplits', MaxNumSplits(j), ...
'Surrogate', 'off', ...
'ClassNames', categorical({'变色鸢尾'; '山鸢尾'; '维吉尼亚鸢尾'}));
% 'SplitCriterion' - Criterion for choosing a split. One of 'gdi'
% (Gini's diversity index), 'twoing' for the twoing
% rule, or 'deviance' for maximum deviance reduction
% (also known as cross-entropy). Default: 'gdi'
% 'MaxNumSplits' - Maximal number of decision splits (or branch
% nodes) per tree. Default: size(X,1)-1
% Create the result struct with predict function
predictorExtractionFcn = @(t) t(:, predictorNames);
treePredictFcn = @(x) predict(classificationTree, x);
trainedClassifier.predictFcn = @(x) treePredictFcn(predictorExtractionFcn(x));
% Add additional fields to the result struct
trainedClassifier.RequiredVariables = {'VarName1', 'VarName2', 'VarName3', 'VarName4'};
trainedClassifier.ClassificationTree = classificationTree;
trainedClassifier.About = 'This struct is a trained model exported from Classification Learner R2017a.';
trainedClassifier.HowToPredict = sprintf('To make predictions on a new table, T, use: \n yfit = c.predictFcn(T) \nreplacing ''c'' with the name of the variable that is this struct, e.g. ''trainedModel''. \n \nThe table, T, must contain the variables returned by: \n c.RequiredVariables \nVariable formats (e.g. matrix/vector, datatype) must match the original training data. \nAdditional variables are ignored. \n \nFor more information, see <a href="matlab:helpview(fullfile(docroot, ''stats'', ''stats.map''), ''appclassification_exportmodeltoworkspace'')">How to predict using an exported model</a>.');
% Extract predictors and response
% This code processes the data into the right shape for training the
% model.
inputTable = trainingData;
predictorNames = {'VarName1', 'VarName2', 'VarName3', 'VarName4'};
predictors = inputTable(:, predictorNames);
response = inputTable.VarName5;
isCategoricalPredictor = [false, false, false, false];
% Perform cross-validation
partitionedModel = crossval(trainedClassifier.ClassificationTree, 'KFold', 5);
% Compute validation predictions
[validationPredictions, validationScores] = kfoldPredict(partitionedModel);
% Compute validation accuracy
validationAccuracy = 1 - kfoldLoss(partitionedModel, 'LossFun', 'ClassifError');
% 下面就是计算每一次循环得到的micro F1分数
C = confusionmat(group,validationPredictions,'Order',ClassNames);
stats = statsOfMeasure(C);
MICRO_F1_SCORE(i,j) = stats.microAVG(end); %下面单独显示了微观F1分数,并对其可视化
% 更新进度条
now_num = now_num+1;
mystr=['计算中...',num2str(100*now_num/TOTAL_NUM),'%'];
waitbar(now_num/TOTAL_NUM,mywaitbar,mystr);
end
end
进度条返回样例:

MICRO_F1_SCORE
微观F1分数返回结果:

对微观F1分数可视化结果如下:
figure(5) % 画一个热力图
heatmap(MaxNumSplits,SplitCriterion,MICRO_F1_SCORE)返回结果:

此处这个热力图太难看了,故去掉第一列重画:
figure(6) % 第一列和其他相比太小了 去掉第一列重画
h_graph = heatmap(MaxNumSplits(2:end),SplitCriterion,MICRO_F1_SCORE(:,2:end));
h_graph.XLabel = '最大分裂数';
h_graph.YLabel = '分裂准则';返回结果:

best_micro_f1_score = max(MICRO_F1_SCORE(:))
%找到MICRO_F1_SCORE第一次出现最大值的位置,因为可能会出现多个最大值
[r,c] = find(MICRO_F1_SCORE == best_micro_f1_score,1);
best_SplitCriterion = SplitCriterion{r} % 分裂准则,元胞数组用大括号取出元素,返回最优的分裂准则
best_MaxNumSplits = MaxNumSplits(c) % 决策树的最大分裂数,返回最优的最大分裂数在找到最优的参数后,即可用这些参数重新训练模型:
trainingData = data1;
inputTable = trainingData;
predictorNames = {'VarName1', 'VarName2', 'VarName3', 'VarName4'};
predictors = inputTable(:, predictorNames);
response = inputTable.VarName5;
isCategoricalPredictor = [false, false, false, false];
% Train a classifier
% This code specifies all the classifier options and trains the classifier.
classificationTree = fitctree(...
predictors, ...
response, ...
'SplitCriterion', best_SplitCriterion, ...%这里将最优的两个参数替换了
'MaxNumSplits', best_MaxNumSplits, ...
'Surrogate', 'off', ...
'ClassNames', categorical({'变色鸢尾'; '山鸢尾'; '维吉尼亚鸢尾'}));
% Create the result struct with predict function
predictorExtractionFcn = @(t) t(:, predictorNames);
treePredictFcn = @(x) predict(classificationTree, x);
trainedClassifier.predictFcn = @(x) treePredictFcn(predictorExtractionFcn(x));
% Add additional fields to the result struct
% trainedClassifier.RequiredVariables = {'VarName1', 'VarName2', 'VarName3', 'VarName4'};
% trainedClassifier.ClassificationTree = classificationTree;
% trainedClassifier.About = 'This struct is a trained model exported from Classification Learner R2017a.';
% trainedClassifier.HowToPredict = sprintf('To make predictions on a new table, T, use: \n yfit = c.predictFcn(T) \nreplacing ''c'' with the name of the variable that is this struct, e.g. ''trainedModel''. \n \nThe table, T, must contain the variables returned by: \n c.RequiredVariables \nVariable formats (e.g. matrix/vector, datatype) must match the original training data. \nAdditional variables are ignored. \n \nFor more information, see <a href="matlab:helpview(fullfile(docroot, ''stats'', ''stats.map''), ''appclassification_exportmodeltoworkspace'')">How to predict using an exported model</a>.');
%
% % Extract predictors and response
% % This code processes the data into the right shape for training the
% % model.
% inputTable = trainingData;
% predictorNames = {'VarName1', 'VarName2', 'VarName3', 'VarName4'};
% predictors = inputTable(:, predictorNames);
% response = inputTable.VarName5;
% isCategoricalPredictor = [false, false, false, false];
%
% % Perform cross-validation
% partitionedModel = crossval(trainedClassifier.ClassificationTree, 'KFold', 5);
%
% % Compute validation predictions
% [validationPredictions, validationScores] = kfoldPredict(partitionedModel);
%
% % Compute validation accuracy
% validationAccuracy = 1 - kfoldLoss(partitionedModel, 'LossFun', 'ClassifError');
trainedClassifier.predictFcn(data2)十七、拓展:三个超参数的网格搜索
trainingData = data1;
inputTable = trainingData;
predictorNames = {'VarName1', 'VarName2', 'VarName3', 'VarName4'};
predictors = inputTable(:, predictorNames);
response = inputTable.VarName5;
isCategoricalPredictor = [false, false, false, false];
% 下面这两个变量在计算F1分数时会用到
ClassNames = unique(response); % y中各类的名称
group = response; % y所在的那一列(真实的类别)
% Train a classifier
% This code specifies all the classifier options and trains the classifier.
SplitCriterion = {'gdi','twoing','deviance'}; %分裂准则有三个可以选的,这里用元胞数组保存
MaxNumSplits = 1:30; % 最大分裂数(因为这个问题比较简单,我这里搜索设置的最大分裂数的上界是30)
MinLeafSize = 1:5; % 最小叶大小, 一个叶节点要存在所需要的最小样本量
num_i = length(SplitCriterion); % 第一个超参数SplitCriterion的可能性有3种
num_j = length(MaxNumSplits); % 第二个超参数MaxNumSplits的可能性有30种
num_q = length(MinLeafSize); % 第三个超参数MinLeafSize的可能性有5种
MICRO_F1_SCORE = zeros(num_i,num_j); % 初始化最后得到的结果(初始化是为了加快代码运行速度)
mywaitbar = waitbar(0); % 设置一个进度条
TOTAL_NUM = num_i*num_j*num_q; % 总共要计算多少次
now_num = 0; % 已经计算了多少次
for i = 1:num_i
for j = 1:num_j
for q = 1:num_q
rng(520) % 设定随机数种子,保证结果的可重复性(这里的520也可以换成其他的数字)
% 注意,如果超参数是字符类型的话,它是被保存在元胞数组中的,取出时需要使用大括号才能得到字符型
classificationTree = fitctree(...
predictors, ...
response, ...
'SplitCriterion', SplitCriterion{i}, ...
'MaxNumSplits', MaxNumSplits(j), ...
'MinLeafSize' , MinLeafSize(q), ...
'Surrogate', 'off', ...
'ClassNames', categorical({'变色鸢尾'; '山鸢尾'; '维吉尼亚鸢尾'}));
% 'SplitCriterion' - Criterion for choosing a split. One of 'gdi'
% (Gini's diversity index), 'twoing' for the twoing
% rule, or 'deviance' for maximum deviance reduction
% (also known as cross-entropy). Default: 'gdi'
% 'MaxNumSplits' - Maximal number of decision splits (or branch
% nodes) per tree. Default: size(X,1)-1
% Create the result struct with predict function
predictorExtractionFcn = @(t) t(:, predictorNames);
treePredictFcn = @(x) predict(classificationTree, x);
trainedClassifier.predictFcn = @(x) treePredictFcn(predictorExtractionFcn(x));
% Add additional fields to the result struct
trainedClassifier.RequiredVariables = {'VarName1', 'VarName2', 'VarName3', 'VarName4'};
trainedClassifier.ClassificationTree = classificationTree;
trainedClassifier.About = 'This struct is a trained model exported from Classification Learner R2017a.';
trainedClassifier.HowToPredict = sprintf('To make predictions on a new table, T, use: \n yfit = c.predictFcn(T) \nreplacing ''c'' with the name of the variable that is this struct, e.g. ''trainedModel''. \n \nThe table, T, must contain the variables returned by: \n c.RequiredVariables \nVariable formats (e.g. matrix/vector, datatype) must match the original training data. \nAdditional variables are ignored. \n \nFor more information, see <a href="matlab:helpview(fullfile(docroot, ''stats'', ''stats.map''), ''appclassification_exportmodeltoworkspace'')">How to predict using an exported model</a>.');
% Extract predictors and response
% This code processes the data into the right shape for training the
% model.
inputTable = trainingData;
predictorNames = {'VarName1', 'VarName2', 'VarName3', 'VarName4'};
predictors = inputTable(:, predictorNames);
response = inputTable.VarName5;
isCategoricalPredictor = [false, false, false, false];
% Perform cross-validation
partitionedModel = crossval(trainedClassifier.ClassificationTree, 'KFold', 5);
% Compute validation predictions
[validationPredictions, validationScores] = kfoldPredict(partitionedModel);
% Compute validation accuracy
validationAccuracy = 1 - kfoldLoss(partitionedModel, 'LossFun', 'ClassifError');
% 下面就是计算每一次循环得到的micro F1分数
C = confusionmat(group,validationPredictions,'Order',ClassNames);
stats = statsOfMeasure(C);
MICRO_F1_SCORE(i,j,q) = stats.microAVG(end);
% 更新进度条
now_num = now_num+1;
mystr=['计算中...',num2str(100*now_num/TOTAL_NUM),'%'];
waitbar(now_num/TOTAL_NUM,mywaitbar,mystr);
end
end
end
figure(7) % 利用子图的方式来画热力图,但是这样的效果仍然不直观
for i = 1:num_q
subplot(3,2,i) % 绘制第i个子图
h_graph = heatmap(MaxNumSplits(2:end),SplitCriterion,MICRO_F1_SCORE(:,2:end,i));
h_graph.XLabel = '最大分裂数';
h_graph.YLabel = '分裂准则';
title(['最小叶大小 = ', num2str(MinLeafSize(i))])
end
返回的热力图:

best_micro_f1_score = max(MICRO_F1_SCORE(:))
%找到MICRO_F1_SCORE第一次出现最大值的位置
ind = find(MICRO_F1_SCORE == best_micro_f1_score,1); % 线性索引
[a,b,c] = ind2sub(size(MICRO_F1_SCORE) ,ind); % 线性索引转换为下标
best_SplitCriterion = SplitCriterion{a} % 分裂准则,元胞数组用大括号取出元素
best_MaxNumSplits = MaxNumSplits(b) % 决策树的最大分裂数
best_MinLeafSize = MinLeafSize(c) % 决策树的最小叶大小十八、拓展:贝叶斯调参

绘制出的分类误差图可以看出哪个参数的效果最好,如下:

十九、阶段总结:模型选择的一般步骤
思路: 通过交叉验证比较不同模型在测试集上的表现,选择效果最好的模型。
衡量的指标:
分类问题: AUC 、 F1 分数、分类正确率等。
回归问题: RMSE、 MSE 等。
不同模型有两层意思:
(1)模型完全不一样,例如 KNN、支持向量机、随机森林等。
(2)模型名称相同,但是参数设置的不同。例如 KNN 中 K 取不同的值可以得到不同
的模型。
因此我们选择最优的模型可以分成两步走:
(1) 先单独对每个模型进行调参,得到使这个模型表现最好的那一组参数;
(2) 比较在最优的参数下,这些模型在测试集上的表现。
这样做存在的问题:(1)将每个模型都调到最好的参数的时间会很长。(2) 如果你在
论文中将每个模型都介绍一遍的话,会显得内容太冗长了!
因此,在实际操作中,我们往往可以先使用 MATLAB 的机器学习工具箱把所有模型都
尝试训练一次,缩小模型选择的范围,然后选择一至两个表现较好的模型进行调参。
这样我们得到的最终模型的表现效果也不会和上面的最优模型差的太大。
(事实上 MATLAB 训练所有的模型中,已经对部分模型设置了不同的超参数,只不过设
置的有点粗糙而已)
另外, 写论文的时候,重点介绍你最后选择的这个模型即可,其他的模型不要介绍的
太详细,简单提一些就行了。
从参加数学建模比赛的角度来说,你还要想到评委老师是不是对这个模型熟悉。如果传统
的模型表现也不错的话,尽量选择传统的模型,毕竟数学建模不是数据挖掘类型的比赛。
除非你使用这个机器学习的模型带来的结果准确率的提升非常大。
如果大家真的要在数学建模论文中使用机器学习的模型的话, 我推荐使用集成算法的
模型, 特别是使用随机森林。 在写数模论文的时候,你要交代为什么你要用这个模型,
原因可以从下面几点考虑:(不要让别人看出来你是在乱套模型!)
(1) 在我研究的这个问题中,有别的学者也用过随机森林来进行预测,效果还很好,
你可以在论文中列出相应的参考论文;
(2) 随机森林是集成学习算法,它通常比个体学习器表现的效果更好,因此你可以
找一些基础的模型和他进行对比,例如线性判别分析、逻辑回归、 knn 等;
(3) 随机森林可以给我们估计输入指标的重要性,可以帮助我们进行进行特征选择
筛选出无关的特征,有些题目就需要我们做这样的事情。
二十、随即森林的实现细节(原理)
原理图如下:

什么是袋外(out-of-bag)数据(截图来自菜菜 sklearn 机器学习的视频)
原理实在不懂的话,找几篇论文糅合一下放到自己的论文。
二十一、利用随机森林得到指标的重要性
首先运用随机森林(集成分类器里的装袋树)训练数据集,之后导出函数。
将训练集改为data1,在后面添加以下代码即可得到各指标的重要性:
importance =oobPermutedPredictorImportance(classificationEnsemble)若想将指标归一化,可用以下代码:
importance(importance<0) = 0;
importance = importance./sum(importance)返回四个指标归一化后的重要性如下(因为这个过程中具有随机性,所以每次运行的结果可能有细微区别,我们以某一次的结果为主就好了):
importance =
0.1702 0.0805 0.3953 0.3540
指标重要性可视化柱状图代码如下:
% 画一个柱状图
figure(8)
h_bar = bar(importance);
h_bar.Parent.XTickLabel =predictors.Properties.VariableNames; % 设置每个柱子的标签
% 也可以手工指定这里的指标名称
% h_bar.Parent.XTickLabel = {'萼片长','萼片宽','花瓣长','花瓣宽'};
h_bar.Parent.XTickLabelRotation = 45; % 标签旋转45度
h_bar.Parent.TickLabelInterpreter = 'none'; % 不使用latex语法提取出大于某个阈值重要性的指标(阈值默认为:1除以指标个数),代码如下:
% 提取出大于某个阈值重要性的指标
threshold = 1/length(importance); % 阈值默认为:1除以指标个数
ind = h_bar.Parent.XTickLabel(importance>threshold)该数据集完整代码为:
trainingData = data1; %改动的地方
inputTable = trainingData;
predictorNames = {'VarName1', 'VarName2', 'VarName3', 'VarName4'};
predictors = inputTable(:, predictorNames);
response = inputTable.VarName5;
isCategoricalPredictor = [false, false, false, false];
% Train a classifier
% This code specifies all the classifier options and trains the classifier.
template = templateTree(...
'MaxNumSplits', 143);
classificationEnsemble = fitcensemble(...
predictors, ...
response, ...
'Method', 'Bag', ...
'NumLearningCycles', 30, ...
'Learners', template, ...
'ClassNames', categorical({'变色鸢尾'; '山鸢尾'; '维吉尼亚鸢尾'}));
importance =oobPermutedPredictorImportance(classificationEnsemble); %改动的地方
% 可以将重要性归一化到[0 1]区间内 % https://ww2.mathworks.cn/matlabcentral/answers/783611-need-predictor-importance-in-random-forest-expressed-as-a-percentage#answer_671247
importance(importance<0) = 0;
importance = importance./sum(importance)
% 画一个柱状图
figure(8)
h_bar = bar(importance);
h_bar.Parent.XTickLabel =predictors.Properties.VariableNames; % 设置每个柱子的标签
% 也可以手工指定这里的指标名称
% h_bar.Parent.XTickLabel = {'萼片长','萼片宽','花瓣长','花瓣宽'};
h_bar.Parent.XTickLabelRotation = 45; % 标签旋转45度
h_bar.Parent.TickLabelInterpreter = 'none'; % 不使用latex语法
% 提取出大于某个阈值重要性的指标
threshold = 1/length(importance); % 阈值默认为:1除以指标个数
ind = h_bar.Parent.XTickLabel(importance>threshold)
结果显示第三个指标和第四个指标的重要性最高。
我们可以在分类学习器中只保留这两个指标重新进行训练,看看结果如何,如下。

去掉特征1和特征2之后再将模型进行训练,观测模型的准确度。
二十二、特征选择的介绍(这里使用随机森林实现特征选择)
我们能用很多属性描述一个客观世界中的对象,例如对于描述一个人来说,可以获取到身高、体重、年龄、性别、学历、收入等等,但对于评判一个人的信用级别来说,往往只需要获取他的年龄、学历、收入这些信息。
换而言之,对一个学习任务来说,给定属性集,其中有些属性可能很关键、很有用,另一些属性则可能没什么用。我们将属性称为“特征” (feature),对当前学习任务有用的属性称为“相关特征” (relevant feature)、没什么用的属性称为“无关特征” (irrelevant feature)。
特征选择” (feature selection)是从数据集的诸多特征里面选择和目标变量相关的特征,去掉那些不相关的特征。
特征选择有什么作用:
(1)可以缓解维数灾难(Curse of Dimensionality),对于某些模型例如 K 最近邻(KNN)
算法,当指标个数太多时,样本在空间中的分布越呈现稀疏性,模型最后得到的效果会大
打折扣。 维数灾难的介绍请在知乎搜索:《怎样理解 Curse of Dimensionality(维数灾难) ?》
(2)降低学习任务的难度,减少训练的时间。
特征选择后模型的效果一定会更好吗?
这个不一定,可能你的每个变量都对目标变量起到作用,只不过作用的大小有大有小。
特征选择和数据降维的区别?
机器学习中最常用的数据降维的方法是主成分分析(PCA),降维后生成的主成分是原来
所有指标的线性组合。 主成分分析得到的主成分很难解释, 如果我们不在意模型的可解释
性,那么主成分分析是缓解维数灾难的很好的方法。(MATLAB 机器学习工具箱中也内置了
主成分分析的方法,但是请注意,主成分分析不会对分类变量进行降维)
勾选PCA如下:

这里成分选取准则一般默认指定方差解释,解释方差(百分比)即为累计贡献率。可自行调整解释方差(百分比)。
接下来即可再次训练调整后的模型。
若题目要求我们降维后进行解释,可以选择使用随机森林进行特征选择(更好解释一些)。
二十三、得到样本属于某一类的概率
为什么要得到属于某一类的概率?
举个例子, 假设我开了一家“清风牌电动车店”, 我通过收集问卷等形式建立了一个二
分类模型,该模型能够预测顾客是否会购买清风牌电动车。
模型的输出为 Y, 且 Y=1 表示顾客会购买, Y=0 表示顾客不会购买。假设我们能够算出 P(Y=1) ,即顾客会购买的概率,那么顾客不会购买的概率P(Y=0)=1-P(Y=1)也可以算出来。 另外, 如果顾客会购买的概率 P(Y=1)大于顾客不会购买的概率 P(Y=0),那么我们认为该顾客会购买我们的清风牌电动车。 容易证明, P(Y=1)必须大于 0.5 时顾客才会购买。
对于 P(Y=1)<0.5 的那批顾客,虽然他们现在还不会购买,但我们店铺可以通过精准营销的策略来制定一些推销活动吸引他们。如果我们知道那些暂时不会购买的顾客 P(Y=1)的值的话,我们会尽可能去挑选那些和 0.5 接近的顾客进行推销,而且和 0.5 越接近,推销成功的几率越大。 举个例子, 给 P(Y=1)=0.45 的顾客推销要比给 P(Y=1)=0.1 的顾客推销的成功率更高。
怎么计算这个概率?
在 MATLAB2017a 版本的分类学习器中, 我测试了一下, 除了支持向量机 SVM 和提升树
Boosted Trees 不能算出属于某一类的概率之外,其他的模型都算出来,而且使用方法类似。
(注意:下一小节要介绍的 RUSBoost 算法计算概率时需要修改一下,下一节会介绍)
下面我们以随机森林为例。(注意:如果模型中具有随机性,那么最后得到的结果可能会变化)
我们可以使用rng指定一个固定的随机数种子,这样我们每次运行的结果都会相同。
步骤和前面预测几乎一样,训练模型,导出代码,修改代码(注释掉第一行,加上 trainingData = data1; 在最后预测结果的时候预测的代码为 [class_hat, score] = trainedClassifier.predictFcn(data2) )。 其中class_hat为预测的结果,score为预测出的概率。
代码如下:
rng(520) % 设定随机数种子,保证结果的可重复性(这里的520也可以换成其他的数字)
trainingData = data1;
inputTable = trainingData;
predictorNames = {'VarName1', 'VarName2', 'VarName3', 'VarName4'};
predictors = inputTable(:, predictorNames);
response = inputTable.VarName5;
isCategoricalPredictor = [false, false, false, false];
% Train a classifier
% This code specifies all the classifier options and trains the classifier.
template = templateTree(...
'MaxNumSplits', 143);
classificationEnsemble = fitcensemble(...
predictors, ...
response, ...
'Method', 'Bag', ...
'NumLearningCycles', 30, ...
'Learners', template, ...
'ClassNames', categorical({'变色鸢尾'; '山鸢尾'; '维吉尼亚鸢尾'}));
% Create the result struct with predict function
predictorExtractionFcn = @(t) t(:, predictorNames);
ensemblePredictFcn = @(x) predict(classificationEnsemble, x);
trainedClassifier.predictFcn = @(x) ensemblePredictFcn(predictorExtractionFcn(x));
% Add additional fields to the result struct
trainedClassifier.RequiredVariables = {'VarName1', 'VarName2', 'VarName3', 'VarName4'};
trainedClassifier.ClassificationEnsemble = classificationEnsemble;
trainedClassifier.About = 'This struct is a trained model exported from Classification Learner R2017a.';
trainedClassifier.HowToPredict = sprintf('To make predictions on a new table, T, use: \n yfit = c.predictFcn(T) \nreplacing ''c'' with the name of the variable that is this struct, e.g. ''trainedModel''. \n \nThe table, T, must contain the variables returned by: \n c.RequiredVariables \nVariable formats (e.g. matrix/vector, datatype) must match the original training data. \nAdditional variables are ignored. \n \nFor more information, see <a href="matlab:helpview(fullfile(docroot, ''stats'', ''stats.map''), ''appclassification_exportmodeltoworkspace'')">How to predict using an exported model</a>.');
% % Extract predictors and response
% % This code processes the data into the right shape for training the
% % model.
% inputTable = trainingData;
% predictorNames = {'VarName1', 'VarName2', 'VarName3', 'VarName4'};
% predictors = inputTable(:, predictorNames);
% response = inputTable.VarName5;
% isCategoricalPredictor = [false, false, false, false];
%
% % Perform cross-validation
% partitionedModel = crossval(trainedClassifier.ClassificationEnsemble, 'KFold', 5);
%
% % Compute validation predictions
% [validationPredictions, validationScores] = kfoldPredict(partitionedModel);
%
% % Compute validation accuracy
% validationAccuracy = 1 - kfoldLoss(partitionedModel, 'LossFun', 'ClassifError');
[class_hat, score] = trainedClassifier.predictFcn(data2)返回的结果为:
class_hat =
6×1 categorical 数组
山鸢尾
维吉尼亚鸢尾
山鸢尾
变色鸢尾
维吉尼亚鸢尾
山鸢尾
score =0 1.0000 0
0 0 1.0000
0 1.0000 0
0.9333 0 0.0667
0 0 1.0000
0 1.0000 0
score中一二三列分别为 变色鸢尾; 山鸢尾 ; 维吉尼亚鸢尾的概率 。
如第一行预测为变色鸢尾的概率为0,预测为山鸢尾的概率为1,维吉尼亚鸢尾的概率为0。
第一行预测为变色鸢尾的概率为0,预测为山鸢尾的概率为0,维吉尼亚鸢尾的概率为1。
二十四、RUSboost算法解决样本不平衡问题
样本不平衡就是指分类任务中不同类别的样本数目差别很大的情况。
为什么样本不平衡会对结果造成影响?
举例来说,假如有 100 个样本,其中只有 5 个是正样本,其余 95 个全为负样本,那么学
习器只要制定一个简单的方法:所有样本均判别为负样本,就能轻松达到 95%的准确率。
而这个分类器的决策很明显并非是我们想要的判定标准。(一般将多于3 ~ 4倍的定位样本不平衡,当然,并没有绝对的标准)
在遇到样本不平衡问题时,大多数的机器学习分类算法会过多地关注多数类,从而使得少
数类样本的分类性能下降。
周志华老师的西瓜书中介绍了三种处理样本不平衡的方法:
不失一般性,假定正类样例较少,反类样例较多。
第一种: 直接对训练集里的反类样例进行“欠采样”(undersampling)。即去除一些反类使得
正、反类数目接近, 然后再进行学习。欠采样的代表性算法是 EasyEnsemble。
第二种: 对训练集里的正类样例进行“过采样”(oversampling),即增加一些正类使得正、反
类数目接近,然后再进行学习。 过采样的代表性算法是 SMOTE。
第三种: 直接基于原始训练集进行学习,但在用训练好的分类器进行预测时, 使用“阈值移
动”(threshold-moving)的策略。
MATLAB 中的 RUSboost 算法融合了欠采样和集成学习法(提升法 Boosting),可有效的应
对样本不平衡问题。
写论文时可参考该论文:

参考论文: 钟华星. 基于 RUSBoost 算法的违约风险预测模型构建与应用[J].财会月
刊,2020(10):74-80.
注意学术规范,引用别人的论文要注明。
二十五、导入众筹是否成功的数据并用全部模型训练
例题:预测众筹是否成功(详见数据集)
随着互联网技术和移动通讯技术的不断普及和发展,互联网金融在市场中的份额不断
扩大。作为互联网金融创新模式之一的众筹,近几年得到了广泛的关注。众筹是指创意者
或小微企业等项目发起人通过众筹平台身份审核后, 在众筹平台的网站上建立属于自己的
页面, 向消费者介绍项目情况来筹集小额资金的商业模式。
附件 1 是 667 个众筹项目的数据表格:
表中第 1 列是众筹项目的 id 编号。每次发布的众筹项目都对应一个唯一的编号;
表中第 2 列是该项目是否众筹成功。若项目最终获得支持的金额达到了众筹的目标总
额,项目得以成功运行,支持该项目的消费者将会获得对应的商品回报;若项目最终没有
成功募集资金,前期支持该项目的消费者的投入会返还;
表中第 3 列是该项目众筹的目标金额。根据项目类别的不同,项目发起人设置的目标
金额往往存在较大差异;
表中第 4 列是该项目众筹的持续时长。如果在规定时长内众筹金额没能达到目标金额,
则众筹失败;
表中第 5 列是项目发起人是否设置了“1 元抽奖活动”, 一般设置该活动可以吸引消费者
的参与;
表中第 6 列是项目发起人设置的可以支持的金额种类。根据支持金额的不同,支持该
项目的消费者获得的商品规格也不同;
表中第 7 列是项目发起人设置的几种可以支持的金额中,最多可以支持的那个金额;
表中第 8 列是项目发起人设置的几种可以支持的金额中,最少可以支持的那个金额;
表中第 9 列是项目发起人设置的商品发货时间。当众筹成功后,众筹发起人会利用众
筹获得的资金来生产商品,然后再发货给支持该项目的消费者;
表中第 10 列是项目发起人是否在众筹平台上展示了产品的视频介绍;
表中第 11 列是众筹项目在平台上展示的图片数量。 图片数可用来反应项目发起人对
众筹产品展示情况的详尽程度。
请根据附件 1 的数据建立一个分类模型,来预测附件 2 中的众筹项目是否会成功
注:再导入数据时,观测一下数据的类型是否符合,如下图中“是否设置了1元抽奖活动”变量类型为分类变量,在导入数据时MATLAB是自动识别为分类变量的,这时是正确的。有时候MATLAB会识别错误,比如当变量类型为“0” “1”时,这时候的变量类型也为分类变量,但MATLAB可能会识别为数值型。所以在导入数据时,需要自己一个个去识别。

根据Excel的数据透视表功能(见下图)可看出数据集中众筹成功(y)里“否”为584,“是”为83,显而易见,样本不平衡,故可用RUSBoost算法。

我们使用 MATLAB 训练全部模型时, MATLAB 会根据分类准确率评价模型的好坏,若
存在样本不平衡问题,千万不要被这个指标所迷惑了。更加好的做法是: 看一下混淆矩阵
中,对于样本较少的那个类别的分类准确率;通过下图的装袋树(其他的模型也是一样)与RUSBoost树可对比出来:因为样本不平衡装袋树在训练集上预测出的效果并不好,真实为“是”预测出为“否”的概率为高达45.8%,而RUSBoost为16.9%,显然RUSBoost效果要好一些。


还可以指定一个正类,比较不同模型的 AUC指标。
在本数据集中,分类为“是”的较少,故可将“是”定为正类。装袋树和RUSBoost的ROC曲线和AUC面积如下图:


二十六、对RUSboost调参并进行预测
网格搜索:找到使AUC最大时对应的参数(你也可以使用之前学的F1分数)
小技巧:提升法中树的大小通常要小于装袋法的大小,因此最大分裂数MaxNumSplits在提升法中要设置的小一点。(RUSBoost是提升法的一种)
trainingData = data1;
inputTable = trainingData;
predictorNames = {'VarName1', 'VarName2', 'VarName3', 'VarName4', 'VarName5', 'VarName6', 'VarName7', 'VarName8', 'VarName9'};
predictors = inputTable(:, predictorNames);
response = inputTable.VarName10;
isCategoricalPredictor = [false, false, true, false, false, false, false, true, false];
group = response; % y所在的那一列(真实的类别)
ClassNames = unique(response); % y中各类的名称
% 假设我们更关心众筹成功了,就可以让正类为“是”
kk = 2; % 指定正类,kk是正类在ClassNames中的位置
posclass = ClassNames(kk); % 正类的名称
MaxNumSplits = 10:10:100; % 网格搜索设置的最大分裂数的范围
NumLearningCycles = 10:10:100; % RUSBoost中决策树的个数范围
num_i = length(MaxNumSplits);
num_j = length(NumLearningCycles);
AUC = zeros(num_i,num_j);
mywaitbar = waitbar(0);
TOTAL_NUM = num_i*num_j;
now_num = 0;
for i = 1:num_i
for j = 1:num_j
rng(520) % 设定随机数种子,保证结果的可重复性(这里的520也可以换成其他的数字)
% Train a classifier
% This code specifies all the classifier options and trains the classifier.
template = templateTree(...
'MaxNumSplits', MaxNumSplits(i));
classificationEnsemble = fitcensemble(...
predictors, ...
response, ...
'Method', 'RUSBoost', ...
'NumLearningCycles',NumLearningCycles(j), ...
'Learners', template, ...
'LearnRate', 0.1, ...
'ClassNames', categorical({'否'; '是'}));
% Create the result struct with predict function
predictorExtractionFcn = @(t) t(:, predictorNames);
ensemblePredictFcn = @(x) predict(classificationEnsemble, x);
trainedClassifier.predictFcn = @(x) ensemblePredictFcn(predictorExtractionFcn(x));
% Add additional fields to the result struct
trainedClassifier.RequiredVariables = {'VarName1', 'VarName2', 'VarName3', 'VarName4', 'VarName5', 'VarName6', 'VarName7', 'VarName8', 'VarName9'};
trainedClassifier.ClassificationEnsemble = classificationEnsemble;
trainedClassifier.About = 'This struct is a trained model exported from Classification Learner R2017a.';
trainedClassifier.HowToPredict = sprintf('To make predictions on a new table, T, use: \n yfit = c.predictFcn(T) \nreplacing ''c'' with the name of the variable that is this struct, e.g. ''trainedModel''. \n \nThe table, T, must contain the variables returned by: \n c.RequiredVariables \nVariable formats (e.g. matrix/vector, datatype) must match the original training data. \nAdditional variables are ignored. \n \nFor more information, see <a href="matlab:helpview(fullfile(docroot, ''stats'', ''stats.map''), ''appclassification_exportmodeltoworkspace'')">How to predict using an exported model</a>.');
% Extract predictors and response
% This code processes the data into the right shape for training the
% model.
inputTable = trainingData;
predictorNames = {'VarName1', 'VarName2', 'VarName3', 'VarName4', 'VarName5', 'VarName6', 'VarName7', 'VarName8', 'VarName9'};
predictors = inputTable(:, predictorNames);
response = inputTable.VarName10;
isCategoricalPredictor = [false, false, true, false, false, false, false, true, false];
% Perform cross-validation
partitionedModel = crossval(trainedClassifier.ClassificationEnsemble, 'KFold', 5);
% Compute validation predictions
[validationPredictions, validationScores] = kfoldPredict(partitionedModel);
% 计算auc
[~,~,~,auc] = perfcurve(group,validationScores(:,kk),posclass); % 前三个输出都不需要
AUC(i,j) = auc;
% 更新进度条
now_num = now_num+1;
mystr=['计算中...',num2str(100*now_num/TOTAL_NUM),'%'];
waitbar(now_num/TOTAL_NUM,mywaitbar,mystr);
end
end
% save AUC.mat AUC % 把这个来之不易的结果保存到本地
load AUC.mat
%对计算出来的所有AUC结果可视化
figure(1)
MaxNumSplits = 10:10:100; % 网格搜索设置的最大分裂数的范围
NumLearningCycles = 10:10:100; % RUSBoost中决策树的个数范围
h_graph = heatmap(NumLearningCycles,MaxNumSplits,AUC);
h_graph.XLabel = 'RUSBoost中决策树的个数';
h_graph.YLabel = '决策树的最大分裂数';
best_AUC = max(AUC(:))
[r,c] = find(AUC== best_AUC,1);
best_MaxNumSplits = MaxNumSplits(r) % 决策树的最大分裂数
best_NumLearningCycles = NumLearningCycles(c) % RUSBoost中决策树的个数AUC可视化结果如下:

用最优的模型进行预测
注意:如果模型中具有随机性,那么最后得到的结果可能会变化。
我们可以使用rng指定一个固定的随机数种子,这样我们每次运行的结果都会相同。
rng(520) % 设定随机数种子,保证结果的可重复性(这里的520也可以换成其他的数字)
trainingData = data1;
inputTable = trainingData;
predictorNames = {'VarName1', 'VarName2', 'VarName3', 'VarName4', 'VarName5', 'VarName6', 'VarName7', 'VarName8', 'VarName9'};
predictors = inputTable(:, predictorNames);
response = inputTable.VarName10;
% Train a classifier
% This code specifies all the classifier options and trains the classifier.
template = templateTree(...
'MaxNumSplits', best_MaxNumSplits);
classificationEnsemble = fitcensemble(...
predictors, ...
response, ...
'Method', 'RUSBoost', ...
'NumLearningCycles', best_NumLearningCycles, ...
'Learners', template, ...
'LearnRate', 0.1, ...
'ClassNames', categorical({'否'; '是'}));
% Create the result struct with predict function
predictorExtractionFcn = @(t) t(:, predictorNames);
ensemblePredictFcn = @(x) predict(classificationEnsemble, x);
trainedClassifier.predictFcn = @(x) ensemblePredictFcn(predictorExtractionFcn(x));
[class_hat, score] = trainedClassifier.predictFcn(data2)
score = score./ sum(score,2) % 调整预测的概率,使其归一化二十七、补充:关于RUSboost的三个问题
关于怎么写作?
RUSBoost的准确率更高,应对样本不平衡时处理得更好,给一篇参考论文,在自己论文中引出该参考论文,表明自己有理有据。
网格搜索实现F1分数?
参考前面决策树的代码。
若出现一个三分类问题,有两类样本都很少,可以分别算出这两类的F1分数,再将这两个F1分数相加的结果为目标函数,求最优解,也可给这两类附上权重。
样本不平衡时,还能不能通过随即森林得到指标的重要性?
有些文献是用随即森林做的,有些不是,可用下面的最大相关最小冗余算法(mRMR)来得到指标的重要性。
二十八、使用mRMR算法来衡量指标的重要性
衡量指标的重要性 随机森林既能用于分类,也能用于回归。
最大相关最小冗余算法(mRMR): 只能用于分类问题(MATLAB 2019b 后才推出)
很好用,支持 MATLAB 表格的形式导入数据,但是对 MATLAB 版本要求太高了。
Rank features for classification using mRMR
此处使用的数据集为众筹数据
%上面的代码就是分类工具箱自动导出的,我这里直接搬过来了
trainingData = data1;
inputTable = trainingData;
predictorNames = {'VarName1', 'VarName2', 'VarName3', 'VarName4', 'VarName5', 'VarName6', 'VarName7', 'VarName8', 'VarName9'};
predictors = inputTable(:, predictorNames);
response = inputTable.VarName10;
%下面我们只用加上一行代码即可调用mRMR模型:
[idx,importance] = fscmrmr(predictors,response) %idx表示指标重要性从高到低的指标的编号importance是从第一个指标到最后一个指标的重要性,我们将其归一化
% % 可以将重要性归一化到[0 1]区间内
importance(importance<0) = 0;
importance = importance./sum(importance)
% % 画一个柱状图
figure(2)
h_bar = bar(importance);
h_bar.Parent.XTickLabel =predictors.Properties.VariableNames; % 设置每个柱子的标签
% 也可以手工指定这里的指标名称
tmp = "目标金额 众筹持续时长(周) 是否设置了1元抽奖活动 设置了几种支持的金额 最多支持的金额 最少支持的金额 商品发货时间(周) 有无视频 图片数量";
h_bar.Parent.XTickLabel = strsplit(tmp,' ');%此函数用于将tmp分割
h_bar.Parent.XTickLabelRotation = 45; % 标签旋转45度
h_bar.Parent.TickLabelInterpreter = 'none'; % 不使用latex语法
在得到指标的重要性之后,可以在特征选择里去掉重要性较低的指标,重新将模型训练,若模型的效果更好,说明该指标可能确实不重要,若效果变差了或没变,可能去掉的指标对结果也是有用的,可以再增加几个指标试试。
一点小脑洞:怎么衡量分类变量和其他变量的相关性?
我们之前学的相关系数通常只适合于连续型的变量,有了 mRMR 后你就可以间接的去衡量自变量对因变量的相关性了。
(当然,如果不存在样本不平衡问题时, 你也可以用随机森林进行衡量,它们的结果之间可能有差别,写作时以一个模型为准! )
参考文献:
Peng H , Long F , Ding C . Feature selection based on mutual information criteria of maxdependency, max-relevance, and min-redundancy[J]. IEEE Transactions on Pattern Analysis
& Machine Intelligence, 2005, 27(8):1226-1238.
基本思想:
互信息(Mutual Information)是衡量随机变量之间相互依赖程度的度量。
二十九、拓展:高版本MATLAB中的误分类代价
类似于施加了一个惩罚项,如下图:

对角线为0,表示预测正确了不会有任何的惩罚,而其他的1则表明预测失败了会给予1的惩罚,当对预测错的惩罚上调,重新训练模型后,模型的混淆矩阵的准确度会更好,不过模型整体的精确度可能会下降。
MATLAB的官方文档也对其有介绍,可详看视频。
三十、泰坦尼克号:在Excel中的初步分析
一、问题描述
这是数据挖掘竞赛 kaggle 平台上一道非常经典的机器学习入门题目:
1921 年 4 月,泰坦尼克号与冰山相撞, 这次事故导致 1500 多人丧生。 虽然在沉船中
幸存下来有一些运气因素,但是在运气因素之外,是否还有其他因素呢?
请运用根据题目所给的数据集, 分析哪些人群更容易幸存下来, 并预测 test.csv 数据
集中,有哪些乘客能够幸免于难。
二、 数据集描述
data.csv 中包含了 ID 为 1-891 的乘客,他(她)们是否生存题目告诉了我们;
test.csv 中是 ID892-1309 的乘客,我们需要预测他(她)们是否存活了下来。
题目提供的 data.csv 数据集包含 11 个特征,分别是:
Survived:0 代表死亡, 1 代表存活
Pclass:乘客所持票类,有三种值(1,2,3)
Name:乘客姓名
Sex:乘客性别
Age:乘客年龄(有缺失)
SibSp:乘客兄弟姐妹/配偶的个数
Parch:乘客父母/孩子的个数
Ticket:票号(字符串)
Fare:乘客所持票的价格
Cabin:乘客所在船舱(有缺失)
Embarked:乘客登船港口:S、 C、 Q(有缺失)
最开始的 PassengerId 表示乘客的编号,可以忽略
可通过Excel的数据透视表对数据进行简单的分析,

上述数据分析性别对存活概率的影响, 表明女性存活的概率比男性更大。(也可画图,更加直观)

上述数据分析乘客所持票类对存活概率的影响, 表明一等票存活的概率最大,二等票其次,三等最小。
三十一、补充:异常值的识别
在对数据进行预处理中,我们经常会遇到异常值和缺失值的情况,下面我们对这两种情况的常用技术进行介绍,希望能帮到大家。
在数据既有异常值又有缺失值时,先处理哪个并没有严格的顺序。我习惯先处理异常值,再处理缺失值。
异常值,指的是样本中的一些数值明显偏离其余数值的样本点,所以也称为离群点。常见的异常值判断方法可以分为以下两种情况:
(1) 数据有一个给定范围
例如调查问卷中,需要对某个事物进行打分,满分为 0-10 分。如果填问卷的人填了一个 30 分,那么这个数据就是异常值。
这种情况比较简单,我们可以使用 MATLAB 的逻辑运算快速的找到这些异常值:
x = [8 9 10 7 6 3 30 4 13 9 2];
x<0 | x>10 % | 表示或运算
%返回 7 和 9,意味着第 7 个位置和第 9 个位置的元素不在 0-10 的范围内。(2) 数据没有给定的范围
这种情况下我们介绍两种最常用的判定方法:
第一:3原则识别异常值
学过概率论的同学应该知道,正态分布的概率密度函数图像是关于均值点处对称的,假设总体服从均值为,标准差为的正态分布,那么从该总体中随机抽取一个样本点,该点落在区间[u- 3, u + 3
]上的概率约为 99.73%,而超出这个范围的可能性仅占不到 0.3%,是典型的小概率事件,所以这些超出该范围的数据可以认为是异常值。这就是3
原则识别异常值的理论基础。

下面总结3原则识别异常值的步骤:(1)计算这组数据的均值u和标准差(注意:我们得到的数据一般是样本数据,因此这里的标准差为样本标准差。如果总体的均值和标准差是已知的,那么就用总体的均值和标准差)。(2)判断这组数据中的每个值是否都位于 [u- 3
, u + 3
]这个区间内,如果不在这个区间内就标记为异常值。
注意事项:使用3 原则确定异常值时,样本数据要来自正态分布总体或者近似于正态分布总体,这一点需要根据历史经验或统计检验来进行判断。
下面给出 MATLAB 的代码(MATLAB 版本 2017a,其他低版本请自行测试)
x = [48 51 57 57 49 86 48 53 59 50 48 47 53 56 60];
u = mean(x,'omitnan'); % 假设 x 是取自正态分布的样本
sigma = std(x,'omitnan');
lb = u - 3*sigma; % 区间下界,low bound 的缩写
ub = u + 3*sigma; % 区间上界,upper bound 的缩写
tmp = (x < lb) | (x > ub);
ind = find(tmp)
%返回 6,意味着第 6 个位置是异常值 第二:箱线图识别异常值
箱线图又称为盒须图、盒式图或箱形图,是一种用作显示数据分散情况资料的统计图,因形状如箱子而得名。下方左侧给出了一个用来反映某班男女同学身高分布情况的箱线图,右侧是箱线图上各元素所代表的含义。可以看到,箱线图可以反映数据的许多统计信息,例如均值、中位数、上四分位数和下四分位数。另外,箱线图中规定了数据的异常值,因此我们可以借助箱线图来识别数据的异常值,下面我们来介绍箱线图中异常值的定义方法。(注意:箱线图的画法不唯一,下面给的是一种典型画法)

首先回顾下中位数的定义:我们将数据按从小到大的顺序排列,在排列后的数据中居于中间位置的数就是中位数,我们用 Q2 表示。
下四分位数则是位于排列后的数据 25%位置上的数值,我们用 Q1 表示;上四分位数则是处在排列后的数据 75%位置上的数值,我们用 Q3 表示。

然后我们要定义一个叫做四分位距(IQR: interquartile range)的指标,它是上四分位数(Q3,即位于 75%)与下四分位数(Q1,即位于 25%)的距离,因此 IQR=Q3-Q1。四分位距反映了中间 50%数据的离散程度,其数值越小,说明中间的数据越集中;其数值越大,说明中间的数据越分散。
接下来的工作和3原则识别异常值类似,我们需要给出一个合理的区间,位于该区间内的值是正常的数值,而在区间外的值就是我们定义异常值。在箱线图中,该区间一般为[Q1 - k × IQR, Q3 + k × IQR], k是控制区间长度的一个正数,通常k取为 1.5。因此,我们只需要判断这组数据中的每个值是否都位于[Q1 -1.5 × IQR, Q3 + 1.5 × IQR]这个区间内,如果不在这个区间内就标记为异常。另外,如果我们将k取为 3,在这个区间外的异常值被称为极端异常值。和 3
原则相比,箱线图并没有对数据服从的分布作任何限制性要求(原则要求数据服从正态分布或近似服从正态分布),其判断异常值的标准主要以四分位数和四分位距为基础。在总体分布未知的情况下,使用箱线图识别异常值的结果更加客观。(通常,箱线图识别出来的异常值要多余 3
原则)
下面给出 MATLAB 的代码:
x = [48 51 57 57 49 86 48 53 59 50 48 47 53 56 60];
% 计算分位数的函数需要 MATLAB 安装了统计机器学习工具箱
Q1 = prctile(x,25); % 下四分位数
Q3 = prctile(x,75); % 上四分位数
IQR = Q3-Q1; % 四分位距
lb = Q1 - 1.5*IQR; % 下界
ub = Q3 + 1.5*IQR; % 上界
tmp = (x < lb) | (x > ub);
ind = find(tmp)
%返回 6,意味着第 6 个位置是异常值识别出异常值后,我们通常可以将异常值视为缺失值,然后交给缺失值处理方法来处理。
代码:x(ind) = nan (注意:如果有多列数据都需要处理,可以写一个循环。)
当模型预测的效果不好时,可以试试检测一下异常值,可能是数据中存在异常值的问题。
三十二、补充:缺失值的处理
如何处理数据的缺失值是一门很深的学问,事实上数据缺失在许多研究领域都是一个复
杂的问题。下面我们介绍的只是一些比较简单的处理方法。
首先我们要计算异常值缺失的数量。举一个具体的例子,这是我随机生成的 20 个北京
二手房价的数据,每一列是一个指标,每一行是一个样本:
可以看到,“购买时价格”这个指标的缺失值有 14 个,占到总样本数的 70%,缺失的有点太多了,所以这一个指标我们可以考虑删除。至于存在多大比例的缺失值我们可以接受,这个并没有一个标准,总之缺失值越少越好,缺的过多就要考虑删除。
另外,我们可以看到,位于 BCDG 四列的指标都有一个缺失值,但是这个缺失值都位于第 4 行的样本中,因此我们可以考虑直接删除这个样本。当然,如果你觉得样本搜集的成本过高或者样本量太少,你也考虑使用后面介绍的缺失值填补的方法。
MATLAB中计算缺失值数量的函数非常简单,我们可以使用ismissing函数和sum函数,
下面举个例子:
A = [3 NaN 5 6 7 NaN NaN 9];
TF = ismissing(A)
% TF = 1x8 的逻辑数组(为 1 的位置表示是缺失值)
% 0 1 0 0 0 1 1 0
sum(TF)
%对 TF 向量求和,结果为 3,代表有 3 个缺失值 另外,ismissing 函数也可以对矩阵或者表格数据类型判断缺失值,有兴趣的同学可以查询 MATLAB 官网。https://www.mathworks.cn/help/matlab/ref/ismissing.html
(技巧:MATLAB 的 table 表格数据类型非常灵活好用,类似于 python 中的 pandas 包,
想进阶学习 MATLAB 的同学一定要好好学习这方面的知识。目前市面上这方面的资料较少,
大家可以在官网自学各种函数,官网帮助文档非常详细)
下面我们再来介绍缺失值填补,我们需要对缺失的数据类型进行区分:横截面数据和时
间序列数据。这两种数据的缺失值处理方法有所不同。
横截面数据是指在某一时点收集的不同对象的数据,例如北京、上海、广州、深圳等 30个城市今天的最高气温;时间序列数据是指对同一对象在不同时间连续观察所取得的数据,例如北京今年来每天的最高气温。
横截面数据

时间序列数据

对于横截面数据,我们通常使用某个具体的数值来代替缺失值,例如非缺失数据的平均值、中位数或者众数。
MATLAB 的 fillmissing 函数可以很方便的帮助我们实现这个功能。
语法:F = fillmissing(A,'constant',v) 使用常数 v 填充缺失的数组或表。
A = [2 3 nan 3 nan nan 8 4];
v = mean(A,'omitnan'); % 平均值
% v = median(A,'omitnan'); % 中位数微信公众号《数学建模学习交流》
% v = mode(A); % 众数,常用于离散变量的缺失值
F = fillmissing(A,'constant',v)
%非缺失值数据的平均值是 4,所以将缺失值 nan 代替为 4
2 3 4 3 4 4 8 4 
更多介绍请看帮助文档:https://ww2.mathworks.cn/help/matlab/ref/fillmissing.html

当然,我们这里介绍的方法比较简单,如果你专门做数据挖掘,还可以使用一些其他的
方法来填补缺失值,例如 KNN 填补、随机森林填补、多重插补等方法。这里我们就不介绍
了,有兴趣的同学可以自己搜索相关的论文或者博客学习。
三十三、泰坦尼克号:导入MATLAB中并查看缺失值
导入数据前对Excel的数据做一下处理,将不要的指标删掉(第一列序号),将y列调整到最后。将数据拆分成有y的和无y的。
首先修改工作文件夹到有数据的那个文件夹
clear; clc
cd 'E:\建模清风\机器学习进阶课程配套文件\机器学习进阶课程配套文件\3.泰坦尼克号生存预测'导入数据,偷懒的方法就是使用MATLAB的导入数据功能,然后自动生成脚本
这是我设置的数据类型:

这里的数据类型很有讲究,我们常用的是数值和分类两种数据类型。
数值型比较好理解,我们来看看分类型:
(1)有些分类变量很明显,例如性别:男和女 读取进来后MATLAB会自动帮我们识别为分类型。
(2)有些分类变量是用数值表示的,例如填问卷用1234分别表示四个选项,这时候MATLAB读进来的时候可能给我们默认是数值型,你得改成分类型。
分类型和文本型的区别是什么?
通常来说分类型中包含的类别比较少,而文本型中每个样本的区别都很大。
通常我们在模型中不引入文本型的变量,除非你自己提取文本型中有用的信息来生成新的指标。
%导入数据脚本
filename = 'data.csv';
delimiter = ',';
startRow = 2;
formatSpec = '%f%C%C%q%C%f%f%f%q%f%C%C%[^\n\r]';
fileID = fopen(filename,'r');
dataArray = textscan(fileID, formatSpec, 'Delimiter', delimiter, 'TextType', 'string', 'EmptyValue', NaN, 'HeaderLines' ,startRow-1, 'ReturnOnError', false, 'EndOfLine', '\r\n');
fclose(fileID);
data = table(dataArray{1:end-1}, 'VariableNames', {'PassengerId','Survived','Pclass','Name','Sex','Age','SibSp','Parch','Ticket','Fare','Cabin','Embarked'});
%% 清除临时变量
clearvars filename delimiter startRow formatSpec fileID dataArray ans;Survived:0代表死亡,1代表存活
Pclass:乘客所持票类,有三种值(1,2,3)
Name:乘客姓名
Sex:乘客性别
Age:乘客年龄(有缺失)
SibSp:乘客兄弟姐妹/配偶的个数(整数值)
Parch:乘客父母/孩子的个数(整数值)
Ticket:票号(字符串)
Fare:乘客所持票的价格(浮点数,0-500不等)
Cabin:乘客所在船舱(有缺失)
Embarked:乘客登船港口:S、C、Q(有缺失)
最开始的PassengerId表示乘客的编号,可以忽略。
MATLAB表格的用法:https://ww2.mathworks.cn/help/matlab/tables.html
head(data,10) % 查看表的前10行
summary(data) % 返回表中各个指标的信息
N = height(data) % 表的高度,即样本量
data.Properties.VariableNames % 变量名称一般我们先不用考虑数据异常值的情况,除非遇到了下面几种情况:
(1)题目明确要求我们要处理数据中的异常值。
(2)有些指标中的数据出现了明显的错误,例如不在合理的范围内,例如满分为10分,出现了30分。
(3)后面模型的预测效果特别差,可能是数据中存在异常值导致的。
下面我们关注数据中的缺失值,首先查看数据的缺失情况
missing_num = sum(ismissing(data),1) % 每一个指标缺失值的数目
missing_ratio = missing_num / N % 每一个指标缺失值所占的比例
ind = find(missing_ratio) % 看看哪几列有缺失
missing_ratio(ind) % 分别缺失了多少比例的数据Cabin乘客所在船舱缺失的太多了,可以删除它。
(MATLAB2018a版本推出的removevars函数可以删除不要的指标,2017版本请使用下面的方法)
data.Cabin = [];Age乘客年龄缺失的比例接近20%,可以考虑填补
Embarked乘客登船港口只缺失了两个,可以填补
三十四、泰坦尼克号:存活率的可视化和缺失值填补
在填补缺失值之前,我们可以做一下数据的可视化。
我们想看看各个指标对乘客是否存活的影响。
(1)Pclass:乘客所持票类
x = data.Pclass; % 使用点可以取出表中的某一列
% Pclass在data里面的第三列,也可以用data{:,3}取出
% 小括号data(:,3)取出时返回的是一个表格
x_unique_value = unique(x) % 找出唯一值
len_x = length(x_unique_value);
res = zeros(len_x,1); % 初始化下每个类别对应的存活率
for i = 1:len_x
ind = (x == x_unique_value(i)); % 生成一个逻辑数组
tmp = data.Survived(ind); % 取出data.Survived中逻辑数组为1的位置的元素
res(i) = sum(tmp == categorical(1)) / length(tmp); % 注意,这里的数值1要转换为分类变量
end
res
figure(1) % 创建编号为1的图形
h_bar = bar(res); % 画一个柱状图
h_bar.Parent.XTickLabel ={'第1种票','第2种票','第3种票'}; % 修改横坐标的标签
h_bar.Parent.XTickLabelRotation = 45; % 标签旋转45度
h_bar.Parent.TickLabelInterpreter = 'none'; % 不使用latex语法
ylabel('存活率') % 设置纵轴标签返回结果:

分析:第1种票的存活率最高,第3种票存活率最低。
(2)Sex:乘客性别
x = data.Sex; % 使用点可以取出表中的某一列
x_unique_value = unique(x) % 找出唯一值
len_x = length(x_unique_value);
res = zeros(len_x,1); % 初始化下每个类别对应的存活率
for i = 1:len_x
ind = (x == x_unique_value(i)); % 生成一个逻辑数组
tmp = data.Survived(ind); % 取出data.Survived中逻辑数组为1的位置的元素
res(i) = sum(tmp == categorical(1)) / length(tmp);
end
res
figure(2)
h_bar = bar(res); % 画一个柱状图
h_bar.Parent.XTickLabel ={'女性','男性'}; % 修改横坐标的标签
h_bar.Parent.XTickLabelRotation = 45; % 标签旋转45度
h_bar.Parent.TickLabelInterpreter = 'none'; % 不使用latex语法
ylabel('存活率') % 设置纵轴标签返回结果:

由图可知,女性存活率远远高于男性。
(3)Age:乘客年龄
data_backup = data; % 备份原来的数据data,等会要还原的
data = data(~ismissing(data.Age),:) % 取出age非缺失值的这些行的数据,波浪号~在此处表示取反
tabulate(data.Age) % 统计各个年龄出现的频数和频率
% 由于年龄是一个连续数据,我们可以做一个直方图看看数据分布情况
figure(3)
histogram(data.Age)
% 我们可以根据生活常识对年龄进行一个分组
% 未成年: [0-18),青年人:[18-40),中年人:[40,60),老年人:大于等于60
edges = [0 18 30 60 max(data.Age)];
x = discretize(data.Age,edges); % 该函数可将数据划分到类别中
x_unique_value = unique(x);
len_x = length(x_unique_value);
res = zeros(len_x,1); % 初始化下每个类别对应的存活率
for i = 1:len_x
ind = (x == x_unique_value(i)); % 生成一个逻辑数组
tmp = data.Survived(ind); % 取出data.Survived中逻辑数组为1的位置的元素
res(i) = sum(tmp == categorical(1)) / length(tmp);
end
res
figure(4)
h_bar = bar(res); % 画一个柱状图
h_bar.Parent.XTickLabel ={'未成年','青年人','中年人','老年人'}; % 修改横坐标的标签
h_bar.Parent.XTickLabelRotation = 45; % 标签旋转45度
h_bar.Parent.TickLabelInterpreter = 'none'; % 不使用latex语法
ylabel('存活率') % 设置纵轴标签
data = data_backup; % 还原一下data数据返回结果:


其他的变量的分析思路类似,我们这里就不一一绘图了。。。。。。
MATLAB画图比较麻烦,推荐Excel。
下面我们来填补缺失值:
这是横截面数据,我们可以使用某个固定的数值进行填充。
Age乘客年龄是连续型变量,可以考虑用平均值或者中位数填补
age = data.Age;
v = mean(age,'omitnan'); % 平均值
% v = median(age,'omitnan'); % 中位数
F = fillmissing(age,'constant',v); % 利用fillmissing函数填补缺失值
data.Age = F; % 用F替换表格中的AgeEmbarked 乘客登船港口是分类变量,可以用众数填补
embarked = data.Embarked;
v = mode(embarked); % 众数
% F = fillmissing(embarked,'constant',v); % 新版本的MATLAB可以使用这一行语句
% 我的2017a版本需要修改下,改成下面的语句
F = fillmissing(embarked,'constant',string(v)); % 利用fillmissing函数填补缺失值
data.Embarked = F; % 用F替换表格中的Embarked
sum(ismissing(data)) % 再次计算缺失值个数三十五、泰坦尼克号:使用分类学习器比较不同模型
首先将所有的模型都训练一遍,选取准确度最高的几个模型来比较(此处数据没有样本不平衡的问题)。

这三个的效果都还不错,我们就导出它们的代码。
(1)Medium gaussian svm 中等规模的高斯核支持向量机
rng(111)
trainingData = data;
inputTable = trainingData;
predictorNames = {'Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked'};
predictors = inputTable(:, predictorNames);
response = inputTable.Survived;
classificationSVM = fitcsvm(...
predictors, ...
response, ...
'KernelFunction', 'gaussian', ...
'PolynomialOrder', [], ...
'KernelScale', 2.6, ...
'BoxConstraint', 1, ...
'Standardize', true, ...
'ClassNames', categorical({'0'; '1'}));
predictorExtractionFcn = @(t) t(:, predictorNames);
svmPredictFcn = @(x) predict(classificationSVM, x);
trainedClassifier.predictFcn = @(x) svmPredictFcn(predictorExtractionFcn(x));
trainedClassifier.RequiredVariables = {'Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked'};
trainedClassifier.ClassificationSVM = classificationSVM;
trainedClassifier.About = 'This struct is a trained model exported from Classification Learner R2017a.';
trainedClassifier.HowToPredict = sprintf('To make predictions on a new table, T, use: \n yfit = c.predictFcn(T) \nreplacing ''c'' with the name of the variable that is this struct, e.g. ''trainedModel''. \n \nThe table, T, must contain the variables returned by: \n c.RequiredVariables \nVariable formats (e.g. matrix/vector, datatype) must match the original training data. \nAClassNamesditional variables are ignored. \n \nFor more information, see <a href="matlab:helpview(fullfile(docroot, ''stats'', ''stats.map''), ''appclassification_exportmodeltoworkspace'')">How to predict using an exported model</a>.');
inputTable = trainingData;
% Perform cross-validation
partitionedModel = crossval(trainedClassifier.ClassificationSVM, 'KFold', 5);
% Compute validation predictions
[validationPredictions, validationScores] = kfoldPredict(partitionedModel);
% 计算F1score,绘制ROC曲线,计算AUC值
ClassNames = unique(response); % y中各类的名称
kk = 1; % 指定正类,kk是正类在ClassNamesd中的位置
posclass = ClassNames(kk); % 正类的名称
group = response;
[x1,y1,~,auc1] = perfcurve(group,validationScores(:,kk),posclass);
auc1
%绘制ROC曲线,下同
figure(5)
plot(x1,y1)
%别忘了把statsOfMeasure.m这个文件放到当前文件夹(进阶课程的第一个视频有介绍
C = confusionmat(group,validationPredictions,'Order',ClassNames);
stats = statsOfMeasure(C)
F1_score1 = stats.classes(end,kk) % 二分类用
(2)Boosted trees 提升树Adaboost
rng(111)
trainingData = data;
inputTable = trainingData;
predictorNames = {'Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked'};
predictors = inputTable(:, predictorNames);
response = inputTable.Survived;
template = templateTree(...
'MaxNumSplits', 20);
classificationEnsemble = fitcensemble(...
predictors, ...
response, ...
'Method', 'AdaBoostM1', ...
'NumLearningCycles', 30, ...
'Learners', template, ...
'LearnRate', 0.1, ...
'ClassNames', categorical({'0'; '1'}));
predictorExtractionFcn = @(t) t(:, predictorNames);
ensemblePredictFcn = @(x) predict(classificationEnsemble, x);
trainedClassifier.predictFcn = @(x) ensemblePredictFcn(predictorExtractionFcn(x));
trainedClassifier.RequiredVariables = {'Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked'};
trainedClassifier.ClassificationEnsemble = classificationEnsemble;
trainedClassifier.About = 'This struct is a trained model exported from Classification Learner R2017a.';
trainedClassifier.HowToPredict = sprintf('To make predictions on a new table, T, use: \n yfit = c.predictFcn(T) \nreplacing ''c'' with the name of the variable that is this struct, e.g. ''trainedModel''. \n \nThe table, T, must contain the variables returned by: \n c.RequiredVariables \nVariable formats (e.g. matrix/vector, datatype) must match the original training data. \nAdditional variables are ignored. \n \nFor more information, see <a href="matlab:helpview(fullfile(docroot, ''stats'', ''stats.map''), ''appclassification_exportmodeltoworkspace'')">How to predict using an exported model</a>.');
partitionedModel = crossval(trainedClassifier.ClassificationEnsemble, 'KFold', 5);
[validationPredictions, validationScores] = kfoldPredict(partitionedModel);
% 计算F1score,绘制ROC曲线,计算AUC值
ClassNames = unique(response); % y中各类的名称
kk = 1; % 指定正类,kk是正类在ClassNamesd中的位置
posclass = ClassNames(kk); % 正类的名称
group = response;
[x2,y2,~,auc2] = perfcurve(group,validationScores(:,kk),posclass);
auc2
%绘制ROC曲线
figure(6)
plot(x2,y2)
C = confusionmat(group,validationPredictions,'Order',ClassNames);
stats = statsOfMeasure(C);
F1_score2 = stats.classes(end,kk) % 二分类用
(3)Bagged trees 装袋树的升级版:随机森林
rng(111)
trainingData = data;
inputTable = trainingData;
predictorNames = {'Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked'};
predictors = inputTable(:, predictorNames);
response = inputTable.Survived;
template = templateTree(...
'MaxNumSplits', 890);
classificationEnsemble = fitcensemble(...
predictors, ...
response, ...
'Method', 'Bag', ...
'NumLearningCycles', 30, ...
'Learners', template, ...
'ClassNames', categorical({'0'; '1'}));
predictorExtractionFcn = @(t) t(:, predictorNames);
ensemblePredictFcn = @(x) predict(classificationEnsemble, x);
trainedClassifier.predictFcn = @(x) ensemblePredictFcn(predictorExtractionFcn(x));
trainedClassifier.RequiredVariables = {'Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked'};
trainedClassifier.ClassificationEnsemble = classificationEnsemble;
trainedClassifier.About = 'This struct is a trained model exported from Classification Learner R2017a.';
trainedClassifier.HowToPredict = sprintf('To make predictions on a new table, T, use: \n yfit = c.predictFcn(T) \nreplacing ''c'' with the name of the variable that is this struct, e.g. ''trainedModel''. \n \nThe table, T, must contain the variables returned by: \n c.RequiredVariables \nVariable formats (e.g. matrix/vector, datatype) must match the original training data. \nAdditional variables are ignored. \n \nFor more information, see <a href="matlab:helpview(fullfile(docroot, ''stats'', ''stats.map''), ''appclassification_exportmodeltoworkspace'')">How to predict using an exported model</a>.');
partitionedModel = crossval(trainedClassifier.ClassificationEnsemble, 'KFold', 5);
[validationPredictions, validationScores] = kfoldPredict(partitionedModel);
% 计算F1score,绘制ROC曲线,计算AUC值
ClassNames = unique(response); % y中各类的名称
kk = 1; % 指定正类,kk是正类在ClassNamesd中的位置
posclass = ClassNames(kk); % 正类的名称
group = response;
[x3,y3,~,auc3] = perfcurve(group,validationScores(:,kk),posclass);
auc3
%绘制ROC曲线
figure(7)
plot(x3,y3)
C = confusionmat(group,validationPredictions,'Order',ClassNames);
stats = statsOfMeasure(C);
F1_score3 = stats.classes(end,kk) % 二分类用
将三个模型的结果放在一起(注:此处的最优模型的AUC和F1分数应保持一致,如在AUC里auc3最大,则F1_score也应该最大,如果此处两个结果不一致则可以调整随机数种子的值,一直改到两者一致):
auc = [auc1 auc2 auc3] % 所有的AUC汇总
F1_score = [F1_score1 F1_score2 F1_score3] % 所有的F1分数汇总ROC曲线画在同一张图上:
close
figure(8)
plot(x1,y1,'r');
hold on
plot(x2,y2,'g');
plot(x3,y3,'b');
% 使用中括号来拼接字符,字符之间用逗号或者空格隔开
string1 = ['高斯核SVM' , ',AUC = ', num2str(round(auc1,3))];
string2 = ['Adaboost算法', ',AUC = ' , num2str(round(auc2,3))];
string3 = ['随机森林', ',AUC = ' , num2str(round(auc3,3))];
legend(string1,string2,string3,'Location','Best') % location可以设置放置的位置,best是自动放到最佳的位置
xlabel('假正类率FPR'); ylabel('真正类率TPR');返回ROC曲线结果:

注:此处的最优模型是随机森林,与其相对比的两个模型有点高级,实际应用中可以不用选取这两个进行对比,选择朴素的即可。
三十六、泰坦尼克号:调参、衡量指标重要性以及进行预测
下面以Bagged trees为例进行网格搜索:
MaxNumSplits : [100 300 500 700 890] 最大分裂的数量 (可以自己根据需求给定,MATLAB默认是样本数减去1)
NumLearningCycles:10:10:200 弱分类器个数,即决策树的个数
本次网格搜索的目标是找到最大的F1_score,你也可以找AUC最大
trainingData = data;
inputTable = trainingData;
predictorNames = {'Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked'};
predictors = inputTable(:, predictorNames);
response = inputTable.Survived;
MaxNumSplits = [100 300 500 700 890];
NumLearningCycles = 10:10:200;
num_i = length(MaxNumSplits);
num_j = length(NumLearningCycles);
F1_SCORE = zeros(num_i,num_j);
mywaitbar = waitbar(0);
TOTAL_NUM = num_i*num_j;
now_num = 0;
for i = 1:num_i
for j = 1:num_j
rng(111) % 设定随机数种子,保证结果的可重复性(这里的111也可以换成其他的数字)
template = templateTree(...
'MaxNumSplits', MaxNumSplits(i));
classificationEnsemble = fitcensemble(...
predictors, ...
response, ...
'Method', 'Bag', ...
'NumLearningCycles', NumLearningCycles(j), ...
'Learners', template, ...
'ClassNames', categorical({'0'; '1'}));
predictorExtractionFcn = @(t) t(:, predictorNames);
ensemblePredictFcn = @(x) predict(classificationEnsemble, x);
trainedClassifier.predictFcn = @(x) ensemblePredictFcn(predictorExtractionFcn(x));
trainedClassifier.RequiredVariables = {'Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked'};
trainedClassifier.ClassificationEnsemble = classificationEnsemble;
trainedClassifier.About = 'This struct is a trained model exported from Classification Learner R2017a.';
trainedClassifier.HowToPredict = sprintf('To make predictions on a new table, T, use: \n yfit = c.predictFcn(T) \nreplacing ''c'' with the name of the variable that is this struct, e.g. ''trainedModel''. \n \nThe table, T, must contain the variables returned by: \n c.RequiredVariables \nVariable formats (e.g. matrix/vector, datatype) must match the original training data. \nAdditional variables are ignored. \n \nFor more information, see <a href="matlab:helpview(fullfile(docroot, ''stats'', ''stats.map''), ''appclassification_exportmodeltoworkspace'')">How to predict using an exported model</a>.');
partitionedModel = crossval(trainedClassifier.ClassificationEnsemble, 'KFold', 5);
[validationPredictions, validationScores] = kfoldPredict(partitionedModel);
C = confusionmat(group,validationPredictions,'Order',ClassNames);
stats = statsOfMeasure(C);
F1_SCORE(i,j) = stats.classes(end,kk);
now_num = now_num+1;
mystr=['计算中...',num2str(100*now_num/TOTAL_NUM),'%'];
waitbar(now_num/TOTAL_NUM,mywaitbar,mystr);
end
end
save F1_SCORE.mat F1_SCORE
load F1_SCORE.mat
画F1分数矩阵的热力图:
figure(9)
MaxNumSplits = [100 300 500 700 890];
NumLearningCycles = 10:10:200;
h_graph = heatmap(NumLearningCycles,MaxNumSplits,F1_SCORE);
h_graph.XLabel = '随机森林中决策树的个数';
h_graph.YLabel = '决策树的最大分裂数';返回的热力图:

best_f1_score = max(F1_SCORE(:)) % 最佳的F1分数
[r,c] = find(F1_SCORE== best_f1_score,1); % 最佳的F1分数对应的行列
best_MaxNumSplits = MaxNumSplits(r) % 决策树的最大分裂数
best_NumLearningCycles = NumLearningCycles(c) % 随机森林中决策树的个数将最佳的参数重新代入进行模型:
rng(111) % 设定随机数种子,保证结果的可重复性
trainingData = data;
inputTable = trainingData;
predictorNames = {'Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked'};
predictors = inputTable(:, predictorNames);
response = inputTable.Survived;
template = templateTree(...
'MaxNumSplits', best_MaxNumSplits);
classificationEnsemble = fitcensemble(...
predictors, ...
response, ...
'Method', 'Bag', ...
'NumLearningCycles', best_NumLearningCycles, ...
'Learners', template, ...
'ClassNames', categorical({'0'; '1'}));
predictorExtractionFcn = @(t) t(:, predictorNames);
ensemblePredictFcn = @(x) predict(classificationEnsemble, x);
trainedClassifier.predictFcn = @(x) ensemblePredictFcn(predictorExtractionFcn(x));
trainedClassifier.RequiredVariables = {'Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked'};
trainedClassifier.ClassificationEnsemble = classificationEnsemble;
trainedClassifier.About = 'This struct is a trained model exported from Classification Learner R2017a.';
trainedClassifier.HowToPredict = sprintf('To make predictions on a new table, T, use: \n yfit = c.predictFcn(T) \nreplacing ''c'' with the name of the variable that is this struct, e.g. ''trainedModel''. \n \nThe table, T, must contain the variables returned by: \n c.RequiredVariables \nVariable formats (e.g. matrix/vector, datatype) must match the original training data. \nAdditional variables are ignored. \n \nFor more information, see <a href="matlab:helpview(fullfile(docroot, ''stats'', ''stats.map''), ''appclassification_exportmodeltoworkspace'')">How to predict using an exported model</a>.');
partitionedModel = crossval(trainedClassifier.ClassificationEnsemble, 'KFold', 5);
[validationPredictions, validationScores] = kfoldPredict(partitionedModel);
ClassNames = unique(response); % y中各类的名称
kk = 1; % 指定正类,kk是正类在ClassNamesd中的位置
posclass = ClassNames(kk); % 正类的名称
group = response;
C = confusionmat(group,validationPredictions,'Order',ClassNames);
stats = statsOfMeasure(C);
f1_score = stats.classes(end,kk)我们还可以看看哪个指标对预测的结果最重要
如果自变量中有分类变量的话,得到的指标重要性的结果可能是有偏的,我们需要更改决策树中的设置
template = templateTree('PredictorSelection','curvature', ...
'MaxNumSplits', best_MaxNumSplits);
classificationEnsemble = fitcensemble(...
predictors, ...
response, ...
'Method', 'Bag', ...
'NumLearningCycles', best_NumLearningCycles, ...
'Learners', template, ...
'ClassNames', categorical({'0'; '1'}));因为这里给输入变量加入噪声的过程具有随机性,因此每次可能得到的结果有所不同
oobPermutedPredictorImportance(classificationEnsemble)为了让结果更加稳健,我们这里可以重复计算Q次,然后取一个平均的结果
(运行一次的速度较慢,这里的Q也别给的太大了,不然计算时间太长)
Q = 10;
importance = 0;
for q = 1:Q
importance =oobPermutedPredictorImportance(classificationEnsemble)+importance;
end
importance = importance / Q;
% 可以将重要性归一化到[0 1]区间内
importance(importance<0) = 0;
importance = importance./sum(importance)指标较多时,横坐标的标签可能显示的不全,保险起见我们可以加上" h_bar.Parent.XTick = 1:length(importance); " 这一行
如果图中右侧留下的空白过多,可以加上" h_bar.Parent.XLim = [0, length(importance)+1]; " 这一行
还可以调整y轴的范围,这样柱子显得更加自然,可以加上 " h_bar.Parent.YLim = [0, max(importance)*1.1]; " 这一行
% 画一个柱状图
figure(10)
h_bar = bar(importance);
h_bar.Parent.XTickLabel =predictors.Properties.VariableNames;
h_bar.Parent.XTickLabelRotation = 45;
h_bar.Parent.TickLabelInterpreter = 'none';
h_bar.Parent.XTick = 1:length(importance);
h_bar.Parent.XLim = [0, length(importance)+1]; % 设置x轴的范围
h_bar.Parent.YLim = [0, max(importance)*1.1]; % 设置y轴的范围
% % 提取出大于某个阈值重要性的指标
% threshold = 1/length(importance); % 阈值默认为:1除以指标个数
% ind = h_bar.Parent.XTickLabel(importance>threshold)
% 怎么在柱子上加上数值?
xtips = h_bar.XData;
ytips = h_bar.YData;
labels = string(round(h_bar.YData,4)); % 保留小数点后四位小数
% 垂直对齐设置为底部对齐 , 水平对齐设置为居中,字体大小设置为9
text(xtips,ytips,cellstr(labels),...
'VerticalAlignment','bottom',...
'HorizontalAlignment','center',...
'FontSize' , 9)
% 还可以更改柱子的属性 https://ww2.mathworks.cn/help/matlab/ref/bar.html
h_bar.BarWidth = 0.7; % 修改柱子的宽度,默认值是0.8
h_bar.FaceColor = [0.8500 0.3250 0.0980]; % 设置柱子的填充颜色,这里的向量表示RGB三色返回的柱状图:

导入需要我们预测的数据,进行预测啦!(下面是导入数据工具箱自动生成的脚本)
filename = 'test.csv';
delimiter = ',';
startRow = 2;
formatSpec = '%f%C%q%C%f%f%f%q%f%C%C%[^\n\r]';
fileID = fopen(filename,'r');
dataArray = textscan(fileID, formatSpec, 'Delimiter', delimiter, 'TextType', 'string', 'EmptyValue', NaN, 'HeaderLines' ,startRow-1, 'ReturnOnError', false, 'EndOfLine', '\r\n');
fclose(fileID);
data2 = table(dataArray{1:end-1}, 'VariableNames', {'PassengerId','Pclass','Name','Sex','Age','SibSp','Parch','Ticket','Fare','Cabin','Embarked'});
clearvars filename delimiter startRow formatSpec fileID dataArray ans;预测之前先对数据进行清理
head(data2,5) % 查看前五行
missing_num = sum(ismissing(data2)) % 缺失值个数Age和Fare有缺失值,它们都是连续型变量,我们可以使用均值填充
age = data2.Age;
v = mean(age,'omitnan'); % 平均值
F = fillmissing(age,'constant',v); % 利用fillmissing函数填补缺失值
data2.Age = F; % 用F替换表格中的Age
fare = data2.Fare;
v = mean(fare,'omitnan'); % 平均值
F = fillmissing(fare,'constant',v); % 利用fillmissing函数填补缺失值
data2.Fare = F; % 用F替换表格中的Fare调用我们前面的模型进行预测:
[class_hat, score] = trainedClassifier.predictFcn(data2)把结果保存到本地,两种方法:
(1)先把数据弄到表格中,然后使用writetable函数将其保存为csv的文件。
my_answer = table(class_hat, score); % 创建一个表格
writetable(my_answer,'my_answer.csv','Delimiter',',','QuoteStrings',true)
% 将'Delimiter'设置为 ','表示csv文件的每一列的间隔是逗号
% 将'QuoteStrings'设置为true可以排除部分列中也存在英文逗号的干扰
% 注意:如果你的数据中有中文,而且导出的csv中出现了中文乱码,请尝试下面的两行代码
% writetable(my_answer,'my_answer.csv','Delimiter',',','QuoteStrings',true,'Encoding','UTF-8')
% writetable(my_answer,'my_answer.csv','Delimiter',',','QuoteStrings',true,'Encoding','gbk')(2)打开工作区的变量,自己手动复制粘贴到excel里面
后续的讨论:
(1)挖掘更多有用的信息出来
比如我们没有用到的指标:Name:乘客姓名和Ticket:票号
(2)缺失值的处理我们可以尝试使用其他方法
三十七、补充:衡量100个指标的重要性该如何可视化
将所有的指标都可视化出来?太多了,画出来的图很丑。
可以将所有指标的重要性都求出来,放入Excel里,对其进行排序,取重要性最大的十个指标作图。
三十八、回归学习器
见实时脚本
也可参考官方文档
https://ww2.mathworks.cn/help/stats/regressionlearner-app.html

















 784
784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









