







 光谱数据预处理是光谱分析重要环节,可改善数据质量。本文介绍了常见预处理步骤,如基线校正、噪声降低、归一化等,阐述了各步骤原理,并给出Python代码示例,强调预处理技术应用需结合光谱类型、样品性质和分析目标进行优化。
光谱数据预处理是光谱分析重要环节,可改善数据质量。本文介绍了常见预处理步骤,如基线校正、噪声降低、归一化等,阐述了各步骤原理,并给出Python代码示例,强调预处理技术应用需结合光谱类型、样品性质和分析目标进行优化。
一、前言
光谱数据预处理是光谱分析中的一个重要环节,它的目的是通过一系列技术改善数据质量,以提高后续分析的准确性和可靠性。以下是几个常见的光谱数据预处理步骤:
-
基线校正(Baseline Correction):去除由于仪器、样品容器或其他因素引起的基线偏移或漂移,以确保光谱反映的是样品本身的特性。
-
噪声降低(Noise Reduction):利用各种滤波技术如移动平均(Moving Average)、Savitzky-Golay滤波、小波变换(Wavelet Transform)等,以减少光谱数据中的随机噪声。
-
归一化(Normalization):将光谱的强度比例调整到相同的水平,有助于数据之间的比较,常用的方法包括向量归一化、最大值归一化、范数归一化等。
-
标准正态变量变换(Standard Normal Variate, SNV):用于矫正散射效应并进行光谱的校正。
-
多元散射校正(Multiplicative Scatter Correction, MSC):也是一种用于校正样品散射效应的技术,特别适用于固体和粉末样品的近红外(NIR)数据处理。
-
导数光谱(Derivative Spectroscopy):通过计算一阶、二阶或更高阶导数来突显光谱曲线的细节,有助于分离重叠峰,并消除基线漂移的影响。
-
去卷积(Deconvolution):是一种数学过程,用于分离光谱中的重叠信号,以获得更清晰的峰值信息。
这些预处理技术的应用取决于所处理的光谱类型(如UV-Vis、IR、NMR、MS等)、样品的性质、以及分析的目标。预处理步骤的选择和顺序将直接影响光谱分析的效果,因此在实际操作中通常需要结合具体情况进行优化。
二、具体介绍
1.基线校正
首先,生成一组模拟的光谱数据,然后对数据进行基线扣除。基线是通过选择非峰区域的数据点并拟合一个二次多项式获得的。通俗的来说,在处理光谱数据时,我们需要确定哪些部分是因为样品吸收光而产生的信号(即我们感兴趣的峰),哪些部分是背景信号或其他原因导致的不相关信号(即基线)。由于这些不相关信号可能会干扰我们对感兴趣信号的分析,我们需要将它们去除。为了做到这一点,我们首先识别出光谱中的峰值区域,然后忽略这些区域,只使用剩下的部分(即非峰值区域的数据点)来估计基线。这些非峰值区域通常认为主要包含背景信号。接下来,我们使用这些选定的数据点来创建一个数学模型,这里是一个二次多项式,它是一个简单的弯曲形状(像一个开口向上或向下的抛物线),这个模型被调整得尽可能地贴近这些选定的数据点。拟合完成后,这个二次多项式就代表了基线。
最后,代码绘制了两个子图,上面的子图显示原始数据和计算出的基线,下面的子图显示进行了基线校正后的数据。在实际应用中,基线的形状和数据的复杂性可能会要求使用更高级的基线校正方法。
完整代码如下:
import numpy as np
import matplotlib.pyplot as plt
from scipy.signal import find_peaks, peak_widths
# 创建模拟数据
np.random.seed(0) # 确保示例的可重复性
x_data = np.linspace(400, 700, 300) # 波长范围
y_data = np.exp(-0.005*(x_data-500)**2) + np.random.normal(0, 0.02, x_data.size) + 0.1*(x_data-400)**2/300**2
# 基线校正(使用简单的最小二乘多项式拟合)
# 寻找峰值
peaks, _ = find_peaks(y_data, prominence=0.05)
# 峰值的宽度
widths = peak_widths(y_data, peaks, rel_height=0.5)
# 为基线拟合使用峰值外的数据
mask = np.ones_like(y_data, dtype=bool)
for peak, width in zip(peaks, widths[0]):
mask[int(peak - width):int(peak + width)] = False
# 多项式拟合基线
baseline_values = np.polyfit(x_data[mask], y_data[mask], 2)
baseline_poly = np.poly1d(baseline_values)
# 计算基线并进行校正
baseline = baseline_poly(x_data)
y_corrected = y_data - baseline
# 绘制原始数据和基线校正后结果
fig, axs = plt.subplots(2, 1, figsize=(6, 8), sharex=True)
# 原始数据
axs[0].plot(x_data, y_data, label='Original Data')
axs[0].plot(x_data, baseline, label='Baseline', linestyle='--')
axs[0].set_title('Original Spectral Data with Baseline')
axs[0].legend()
# 基线校正后的数据
axs[1].plot(x_data, y_corrected, color='orange', label='Corrected Data')
axs[1].set_title('Baseline Corrected Data')
axs[1].legend()
# 设置共同的X轴标签
for ax in axs:
ax.set_xlabel('Wavelength (nm)')
ax.set_ylabel('Intensity')
plt.tight_layout()
plt.show()
运行结果如下: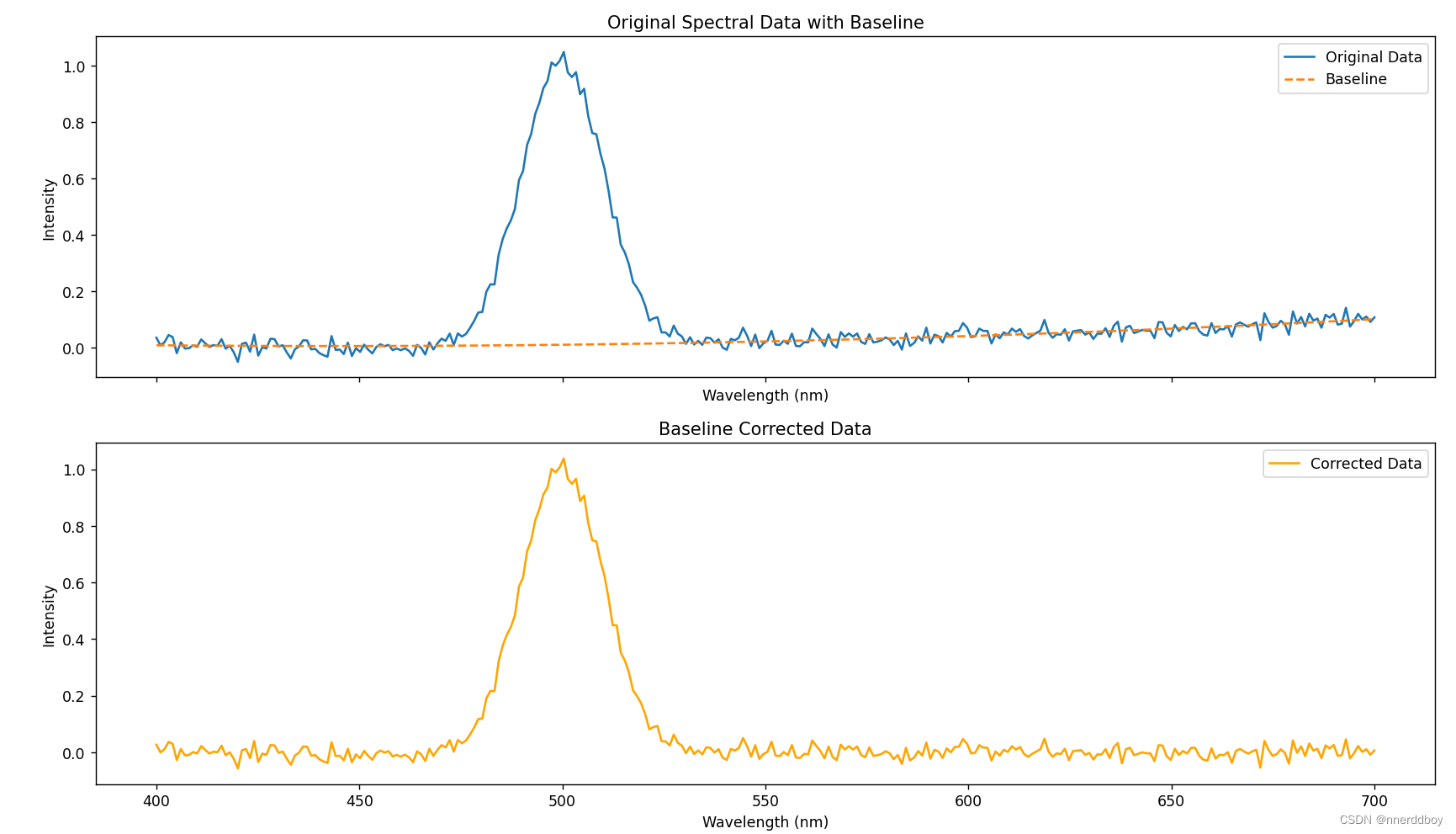
2.噪声降低
首先,创建了一组模拟的光谱数据,并在其上添加了一定量的随机噪声。然后我们使用三种不同的方法来降低噪声:
- 移动平均(Moving Average):是通过在一定窗口大小内计算平均值来平滑数据。
- Savitzky-Golay滤波器(Savitzky-Golay Filter):是通过在数据上拟合多项式并计算其在每个点的值来平滑数据。
- 小波变换去噪(Wavelet Denoising):是通过应用小波变换来分离数据中的噪声和信号,然后去除噪声。
这里可能唯一不好理解原理的就是小波变换,这个方法你一定用过多次(本人QQ名都叫Wavelet,因为这个方法用得太多了),但你不一定直观地理解了它。下面我做一个简单的解释:
小波变换是一种工具,它可以将信号拆分成不同频率的组件,并且还能告诉我们这些组件在时间或空间上的位置。就像一个音乐等化器可以显示不同音高的音量,并且告诉你音乐的哪一部分有高音或低音一样。当我们使用小波变换对信号进行分析时,我们基本上是将信号分解成许多小波构件。这些构件在不同的尺度上展示了信号的特性。噪声通常表现为高频的部分,因为它们快速变化、无规律,就像是音乐中突兀的刺耳声。而信号的真实部分通常是更加平滑和有规律的,就像是一致的旋律线。在小波变换后,我们可以通过一个过程叫做阈值处理来移除噪声。这个过程涉及到设置一个标准(阈值),所有低于这个标准的小波构件(通常是噪声)都会被视为不重要并被移除或减小它们的强度。这就像是降低音乐等化器上的某些频率。在去除了噪声之后,剩下的构件再被组合回去,重建成一个更清晰、噪声更少的信号。总之,小波变换去噪就像是一个精细的筛子,能够筛选出真实信号中的好粒子(有用的频率成分),同时去除掉坏粒子(噪声),最后我们就能得到一个更加纯净、更接近真实情况的信号。
最后,我们绘制一个包含四个子图的图表,分别展示原始数据和三种不同噪声降低技术的效果。
首先你得装pywt库,有的可能需要更新pip才能装成功
pip install --upgrade pip
pip install PyWavelets
完整代码如下:
import numpy as np
import matplotlib.pyplot as plt
from scipy.signal import savgol_filter
import pywt
# 创建模拟数据
np.random.seed(0) # 为了可重复性
x_data = np.linspace(400, 700, 300) # 波长范围
y_data = np.exp(-0.01*(x_data-550)**2) + np.random.normal(0, 0.1, x_data.size)
# 移动平均滤波
def moving_average(data, window_size):
return np.convolve(data, np.ones(window_size)/window_size, mode='same')
# Savitzky-Golay滤波器
def savgol_filtering(data, window_size, order):
return savgol_filter(data, window_size, order)
# 小波变换去噪
def wavelet_denoising(data, wavelet, level):
coeff = pywt.wavedec(data, wavelet, mode='per', level=level)
sigma = np.median(np.abs(coeff[-1])) / 0.6745
uthresh = sigma * np.sqrt(2*np.log(len(data)))
coeff[1:] = (pywt.threshold(i, value=uthresh, mode='soft') for i in coeff[1:])
return pywt.waverec(coeff, wavelet, mode='per')
# 应用噪声降低技术
ma_data = moving_average(y_data, 5) # 窗口大小为5的移动平均
sg_data = savgol_filtering(y_data, 15, 3) # 窗口大小15,多项式阶数3的Savitzky-Golay滤波
wt_data = wavelet_denoising(y_data, 'db1', 1) # Daubechies小波,分解层数为1
# 绘制原始数据和各种降噪结果
fig, axs = plt.subplots(4, 1, figsize=(10, 12), sharex=True)
# 原始数据
axs[0].plot(x_data, y_data, label='Original Data')
axs[0].set_title('Original Spectral Data with Noise')
axs[0].legend()
# 移动平均结果
axs[1].plot(x_data, ma_data, color='green', label='Moving Average')
axs[1].set_title('Moving Average')
axs[1].legend()
# Savitzky-Golay滤波结果
axs[2].plot(x_data, sg_data, color='red', label='Savitzky-Golay Filter')
axs[2].set_title('Savitzky-Golay Filter')
axs[2].legend()
# 小波变换去噪结果
axs[3].plot(x_data, wt_data, color='purple', label='Wavelet Denoising')
axs[3].set_title('Wavelet Denoising')
axs[3].legend()
# 设置共同的X轴标签
for ax in axs:
ax.set_xlabel('Wavelength (nm)')
ax.set_ylabel('Intensity')
plt.tight_layout()
plt.show()
运行结果如下:
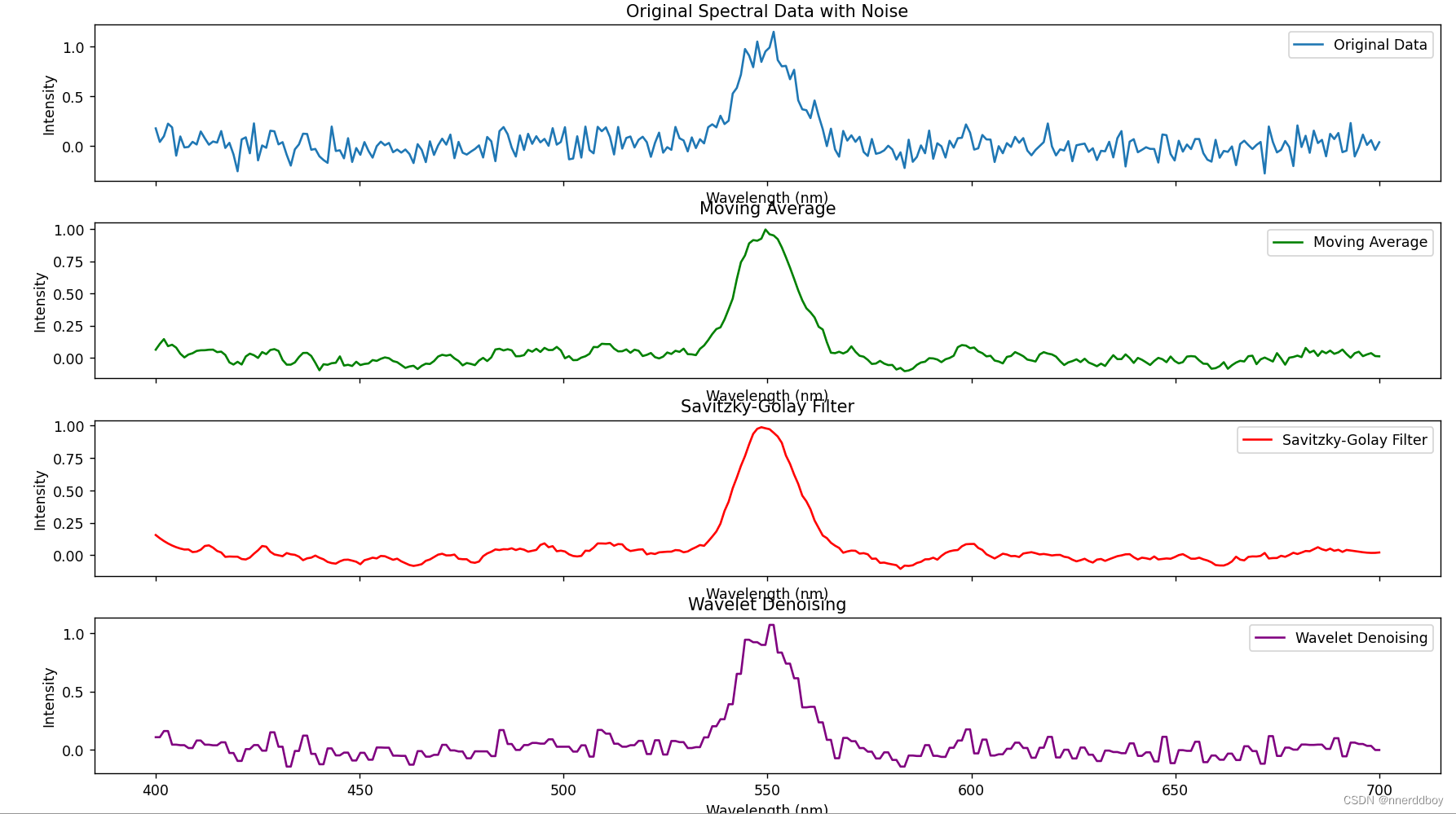
3.归一化
光谱数据归一化是处理光谱数据的常见步骤,其目的是将数据的范围调整到[0, 1]或[-1, 1]等标准区间内。原始数据和归一化结果之间在视觉上可能没有明显区别,这是因为归一化过程仅仅改变了数据的数值范围,并没有改变数据的整体形状或者模式。
完整代码如下:
import numpy as np
import matplotlib.pyplot as plt
# 创建模拟光谱数据
np.random.seed(0)
x_data = np.linspace(400, 700, 300)
# 增加原始数据的数值范围,并加入一些随机波动
y_data = (np.exp(-0.01*(x_data - 550)**2) +
np.random.normal(0, 0.1, x_data.size)) * 1000
# 归一化函数
def normalize_data(data):
min_val = np.min(data)
max_val = np.max(data)
norm_data = (data - min_val) / (max_val - min_val)
return norm_data
# 应用归一化
normalized_y_data = normalize_data(y_data)
# 绘制原始数据和归一化结果
fig, axs = plt.subplots(2, 1, figsize=(10, 8), sharex=True)
# 原始数据
axs[0].plot(x_data, y_data, label='Original Data')
axs[0].set_title('Original Spectral Data')
axs[0].set_ylabel('Intensity (Arbitrary Units)') # 明确强度单位是任意的
axs[0].legend()
# 归一化结果
axs[1].plot(x_data, normalized_y_data, color='red', label='Normalized Data')
axs[1].set_title('Normalized Spectral Data')
axs[1].set_ylabel('Normalized Intensity') # 明确强度已被归一化
axs[1].legend()
# 设置共同的X轴标签
for ax in axs:
ax.set_xlabel('Wavelength (nm)')
plt.tight_layout()
plt.show()
4.标准正态变量变换
标准正态变量变换,也称为Z分数标准化,是指将数据点转换为其与均值的距离除以标准差的值。这种转换后的数据的均值为0,标准差为1,遵循标准正态分布。
完整代码如下:
import numpy as np
import matplotlib.pyplot as plt
# 创建模拟光谱数据
np.random.seed(0)
x_data = np.linspace(400, 700, 300)
y_data = np.exp(-0.01*(x_data - 550)**2) + np.random.normal(0, 0.1, x_data.size)
# 标准正态变量变换函数
def standardize_data(data):
mean_val = np.mean(data)
std_dev = np.std(data)
standardized_data = (data - mean_val) / std_dev
return standardized_data
# 应用标准正态变量变换
standardized_y_data = standardize_data(y_data)
# 绘制原始数据和标准正态变量变换结果
fig, axs = plt.subplots(2, 1, figsize=(10, 8), sharex=True)
# 原始数据
axs[0].plot(x_data, y_data, label='Original Data')
axs[0].set_title('Original Spectral Data')
axs[0].set_ylabel('Intensity')
axs[0].legend()
# 标准正态变量变换结果
axs[1].plot(x_data, standardized_y_data, color='red', label='Standardized Data')
axs[1].set_title('Standardized Spectral Data')
axs[1].set_ylabel('Z-Score')
axs[1].legend()
# 设置共同的X轴标签
for ax in axs:
ax.set_xlabel('Wavelength (nm)')
plt.tight_layout()
plt.show()
5.多元散射校正
多元散射校正(Multiple Scatter Correction, MSC)是一种用于校正光谱数据中散射影响的技术,通常用于近红外(NIR)光谱分析中。MSC的基本思想是通过校正样品光谱,使其接近于一个参考光谱,通常是均值光谱或者一个选定的标准光谱。
通俗解释一下其数学原理,就是以下四个步骤:
-
均值光谱的计算:首先,从一系列光谱数据中计算出一个平均光谱。这个均值光谱可以被看作是包含了所有样本共有特征的一个代表。
-
线性关系的建立:MSC处理的关键在于假设每个样本的光谱可以通过一个线性变换来逼近这个均值光谱。线性变换指的是可以通过伸缩(乘以一个系数)和平移(加或减去一个常数)操作来调整一个样本光谱,使其形状尽可能接近平均光谱。
-
线性回归拟合:对于每个样本的光谱,我们通过线性回归找到最佳的伸缩系数和平移常数。这个过程类似于在散点图中找到一条最佳直线,使得所有点到这条线的距离之和最小。在MSC中,"点"就是样本光谱的每一个数据点,而"直线"则是我们通过伸缩和平移操作尝试匹配的均值光谱。
-
校正应用:一旦我们找到了最佳的伸缩系数和平移常数,我们就将这些参数应用于原样本光谱,进行调整。这样,原样本光谱就被校正为一个新的光谱,理论上应该减少了由于散射造成的变异,而更能反映样本的真实化学信息。
完整代码:
import numpy as np
import matplotlib.pyplot as plt
# 生成具有明显散射效应的模拟光谱数据
def generate_spectral_data(num_samples, num_features):
np.random.seed(0) # 保证每次运行结果一致
# 创建一个基线趋势
baseline = np.outer(np.linspace(1, 2, num_samples), np.linspace(0, 1, num_features))
# 添加一些高斯峰
peaks = np.exp(
-((np.linspace(0, num_features, num_features) - num_features / 3) ** 2) / (2 * (num_features / 20) ** 2))
peaks = np.outer(np.random.rand(num_samples), peaks) * 50
# 模拟散射效应(非线性效应)
scatter = np.outer(0.5 * (np.random.rand(num_samples) - 0.5) * np.linspace(0, 10, num_samples),
np.ones(num_features))
# 组合生成完整光谱数据
spectral_data = baseline + peaks + scatter
return spectral_data
# 进行多元散射校正(MSC)
def do_msc(input_data):
# 计算平均光谱作为参考
ref_spectrum = np.mean(input_data, axis=0)
corrected_data = np.zeros_like(input_data)
for i in range(input_data.shape[0]):
# 对每个样本进行最小二乘线性回归
fit = np.polyfit(ref_spectrum, input_data[i, :], 1)
# 应用校正
corrected_data[i, :] = (input_data[i, :] - fit[1]) / fit[0]
return corrected_data, ref_spectrum
# 生成数据
num_samples = 10
num_features = 300
spectra = generate_spectral_data(num_samples, num_features)
# 应用MSC
corrected_spectra, mean_spectrum = do_msc(spectra)
# 绘制原始和校正后的光谱数据
fig, ax = plt.subplots(2, 1, figsize=(10, 8), sharex=True)
# 绘制原始数据
for i in range(num_samples):
ax[0].plot(spectra[i, :], label=f'Sample {i + 1}' if i == 0 else None)
ax[0].set_title('Original Spectra')
ax[0].set_ylabel('Intensity')
ax[0].legend()
# 绘制MSC校正后的数据
for i in range(num_samples):
ax[1].plot(corrected_spectra[i, :], label=f'Sample {i + 1}' if i == 0 else None)
ax[1].set_title('MSC Corrected Spectra')
ax[1].set_ylabel('Intensity')
ax[1].set_xlabel('Wavelength Index')
ax[1].legend()
plt.tight_layout()
plt.show()
运行结果:
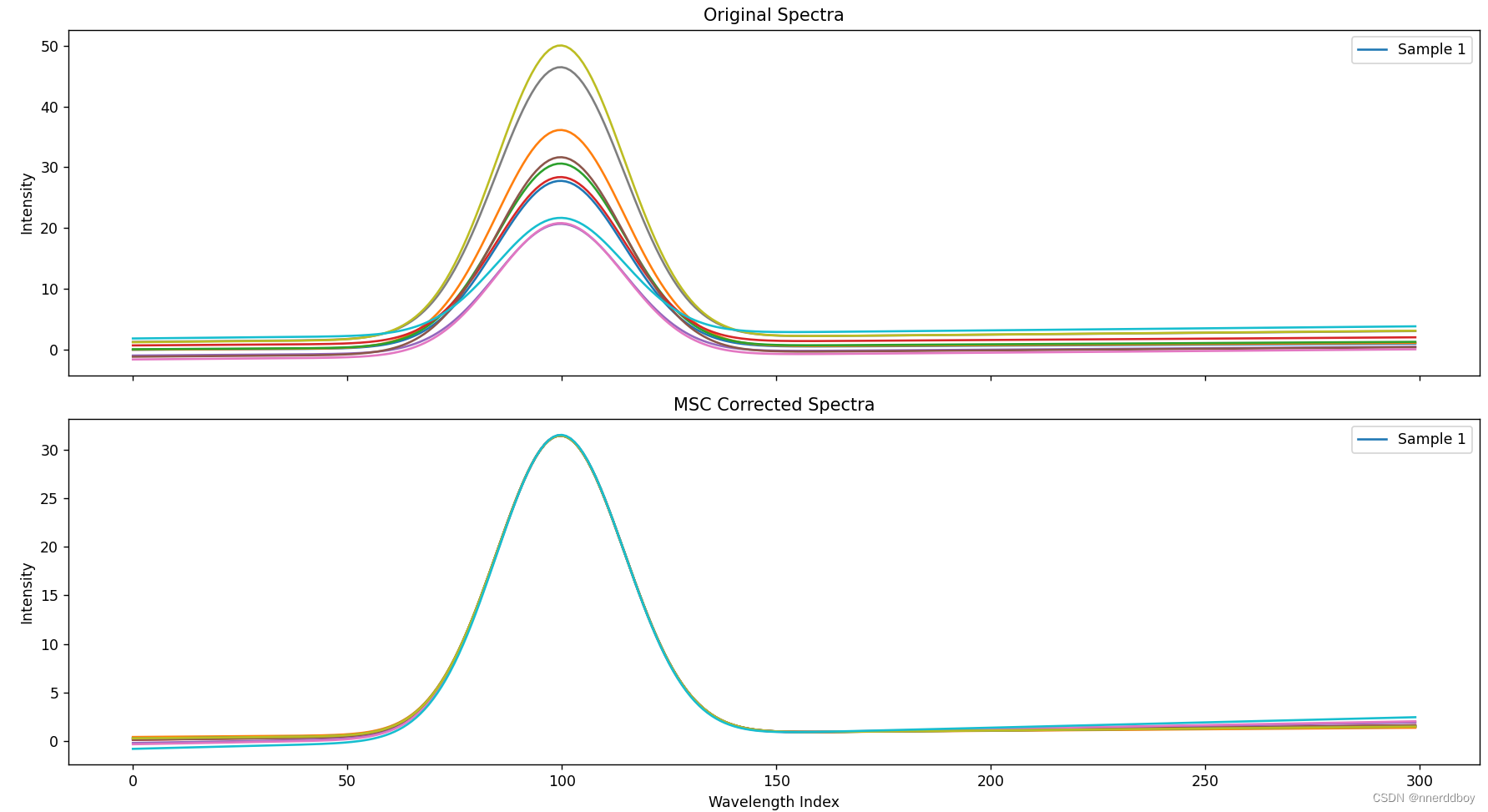
6.一阶导数光谱
一阶导数光谱的数学原理基本上和任何函数的一阶导数原理是相同的。在数学中,一阶导数描述了一个函数在某一点上的斜率,也就是说,它可以告诉我们这个函数在这一点上是怎样增加或减少的。
将这个概念应用到光谱分析上,一个光谱通常是将吸收或发射的光强度与波长(或频率)的关系图表。当我们对这个关系图表进行一阶导数处理时,我们得到的新曲线不再直接显示光强度随波长的变化,而是显示光强度变化速率随波长的变化。换句话说,这个导数光谱告诉我们随着波长的增加,光强度是如何快速增加或减少的。
这在分析光谱时是非常有用的,因为它可以帮助我们识别光谱中的细微特征,这些细微特征在原始光谱中可能不是很明显。比如,一阶导数光谱可以更清晰地显示出光谱中的峰值和谷值,因为它强调了光强度变化的地方(即原始光谱的斜率最大的地方)。这些峰值和谷值通常对应于特定的物质吸收或发射光的特征波长,因此可以用于识别和分析这些物质。
完整代码:
import numpy as np
import matplotlib.pyplot as plt
# 模拟生成光谱数据
def generate_spectral_data(num_samples, num_features):
x = np.linspace(400, 700, num_features) # 假设波长范围从400到700纳米
spectra = np.zeros((num_samples, num_features))
for i in range(num_samples):
# 生成基线
baseline = np.polyval([1e-4, -0.1, 10], x) * (0.5 + np.random.rand() / 2)
# 添加高斯峰
peak = np.exp(-((x - 500 - np.random.rand() * 100) ** 2) / (2 * (25 ** 2)))
spectra[i, :] = baseline + peak * np.random.rand() * 100
return x, spectra
# 计算导数光谱
def calculate_derivative(x, spectra):
# 使用numpy的差分函数计算一阶导数
dx = np.diff(x)
# 注意这里,我们用dx[0]来近似所有波长间的差值,这是一个简化假设,通常光谱波长间隔是均匀的
derivative_spectra = np.diff(spectra) / dx[0]
# x坐标为原始x坐标的中点
x_mid_points = (x[:-1] + x[1:]) / 2
return x_mid_points, derivative_spectra
# 生成光谱数据
num_samples = 5
num_features = 1000
x, spectra = generate_spectral_data(num_samples, num_features)
# 计算导数光谱
x_deriv, derivative_spectra = calculate_derivative(x, spectra)
# 绘制图形
fig, axes = plt.subplots(2, 1, figsize=(8, 10), sharex=True)
# 绘制原始光谱
for i in range(num_samples):
axes[0].plot(x, spectra[i, :], label=f'Sample {i + 1}')
axes[0].set_title('Original Spectra')
axes[0].set_ylabel('Intensity')
axes[0].legend()
# 绘制一阶导数光谱
for i in range(num_samples):
axes[1].plot(x_deriv, derivative_spectra[i, :], label=f'Sample {i + 1}')
axes[1].set_title('First Derivative of Spectra')
axes[1].set_xlabel('Wavelength (nm)')
axes[1].set_ylabel('First Derivative Intensity')
axes[1].legend()
plt.tight_layout()
plt.show()
运行结果:
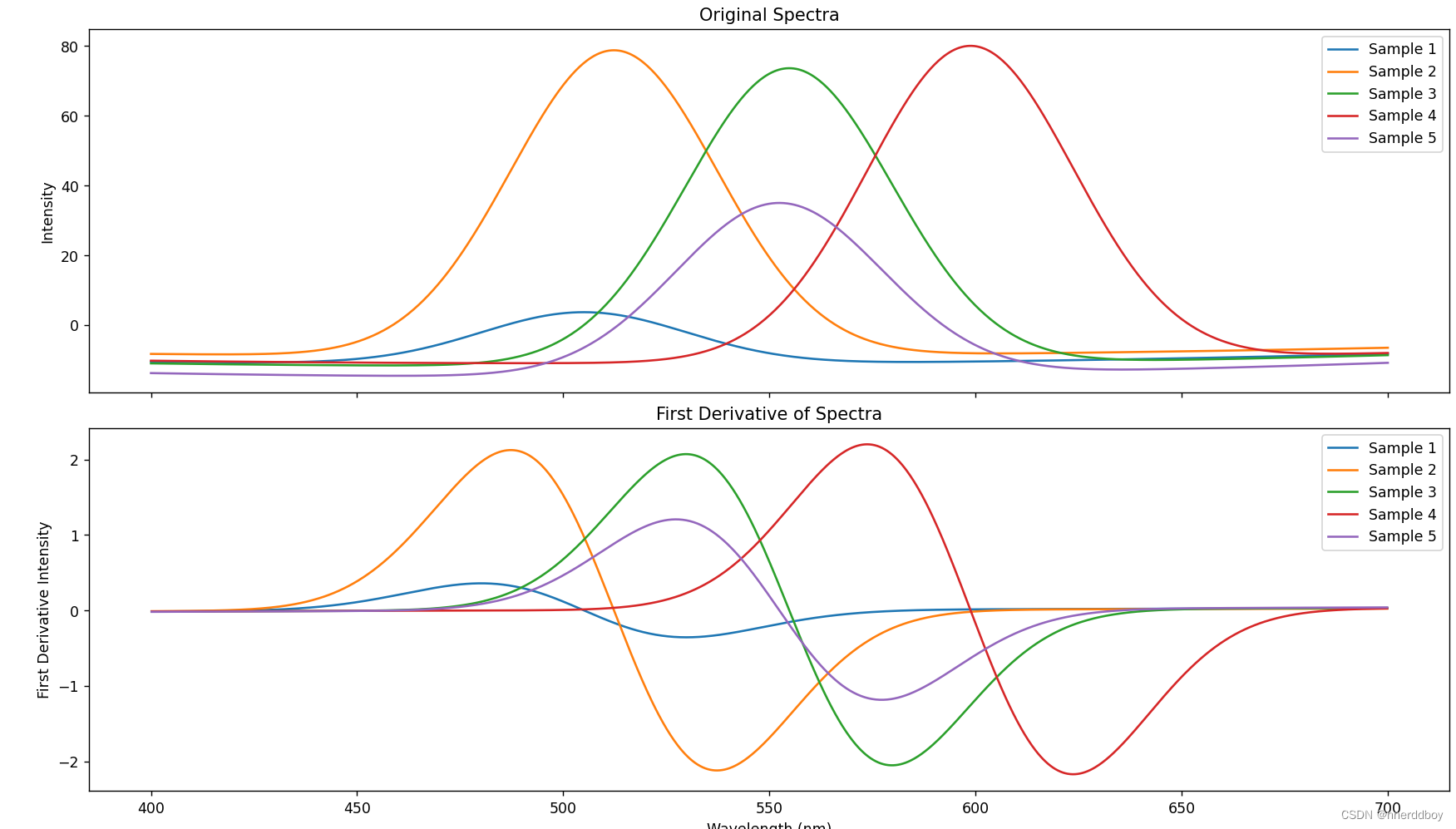
7.去卷积
光谱数据去卷积通常是指从测量的光谱中移除仪器宽化效应(比如光谱仪的光谱分辨率限制)的过程,以获得更接近真实信号的光谱。在许多情况下,这可以通过一种称为“去卷积”的数学操作来完成,该操作试图逆转光谱宽化过程。
完整代码:
import numpy as np
import matplotlib.pyplot as plt
from scipy.signal import wiener
# 模拟生成光谱数据
def generate_spectral_data(num_points):
# 设定波长范围
x = np.linspace(400, 700, num_points)
# 生成模拟光谱,这里我们只模拟一个峰值
spectra = np.exp(-((x - 550) ** 2) / (2 * (20 ** 2))) + np.random.normal(0, 0.02, num_points)
return x, spectra
# 去卷积函数
def deconvolve_spectra(spectra):
# 使用维纳滤波进行去卷积
return wiener(spectra, mysize=None, noise=None)
# 生成光谱数据
num_points = 1000
x, original_spectra = generate_spectral_data(num_points)
# 去卷积
deconvolved_spectra = deconvolve_spectra(original_spectra)
# 绘制图形
fig, axes = plt.subplots(2, 1, figsize=(8, 10), sharex=True)
# 绘制原始光谱
axes[0].plot(x, original_spectra, label='Original Spectra')
axes[0].set_title('Original Spectra')
axes[0].set_ylabel('Intensity')
# 绘制去卷积后光谱
axes[1].plot(x, deconvolved_spectra, label='Deconvolved Spectra', color='red')
axes[1].set_title('Deconvolved Spectra')
axes[1].set_xlabel('Wavelength (nm)')
axes[1].set_ylabel('Intensity')
plt.tight_layout()
plt.show()
运行结果:



















 4820
4820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









