






bert
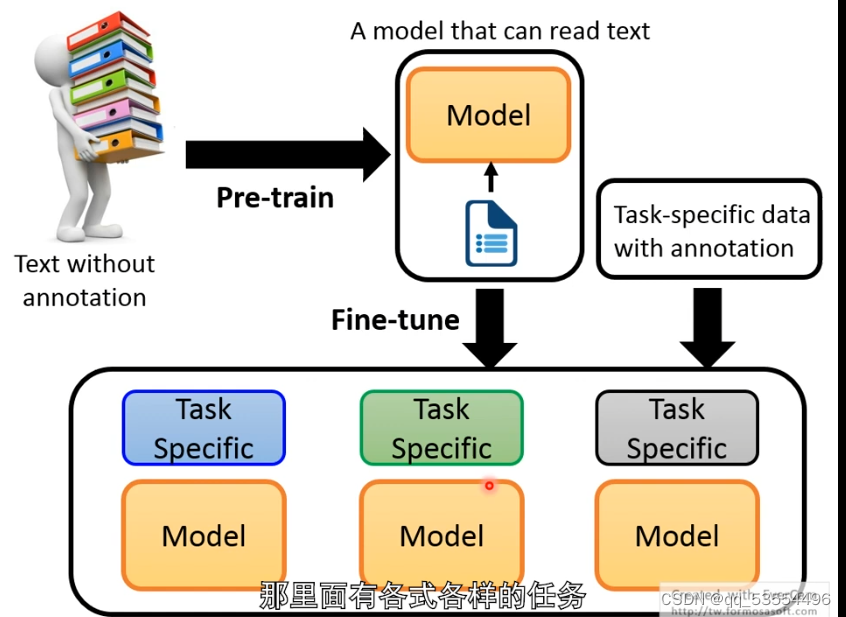
过去的模型:
以token作为输入,每个token输出一个embedding
上下文模型:
以整个句子为编码,分割token,再生成embedding
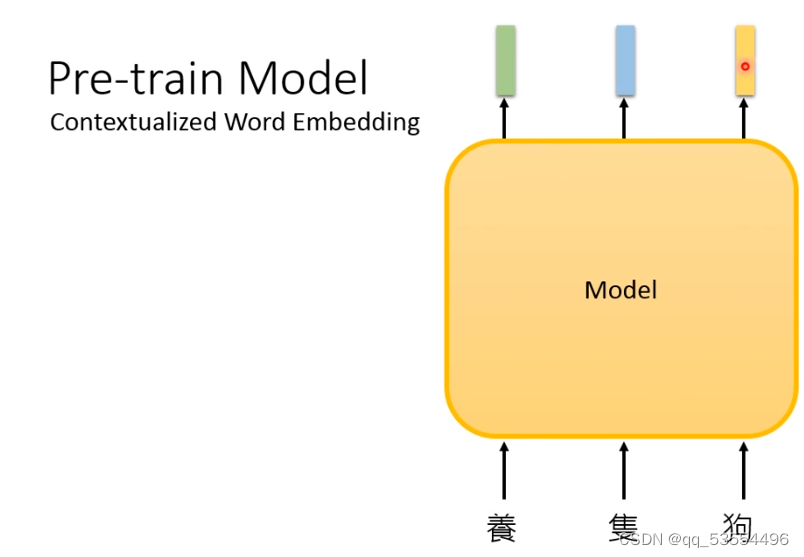
微调介绍
多句子输入:加入特殊位置标记作为token

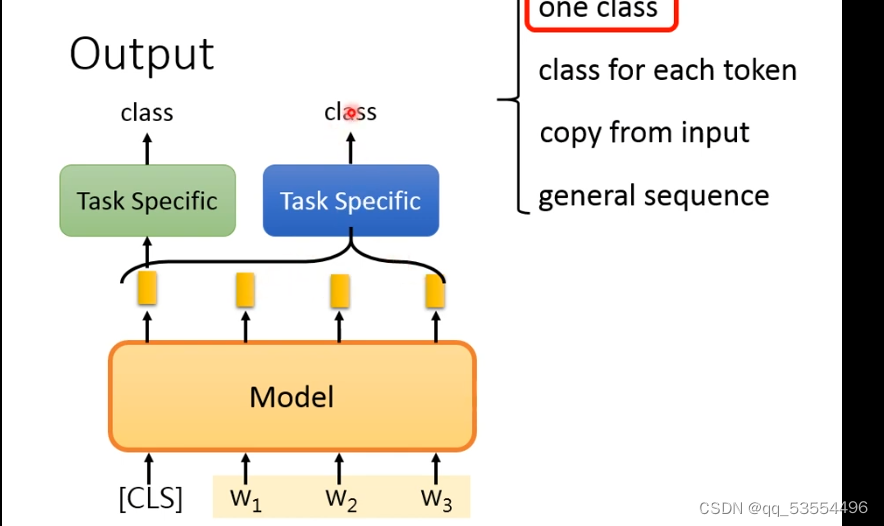
任务一:句子种类输出:加入cls标志,该标志跟整个句子信息有关,embedding输出分类
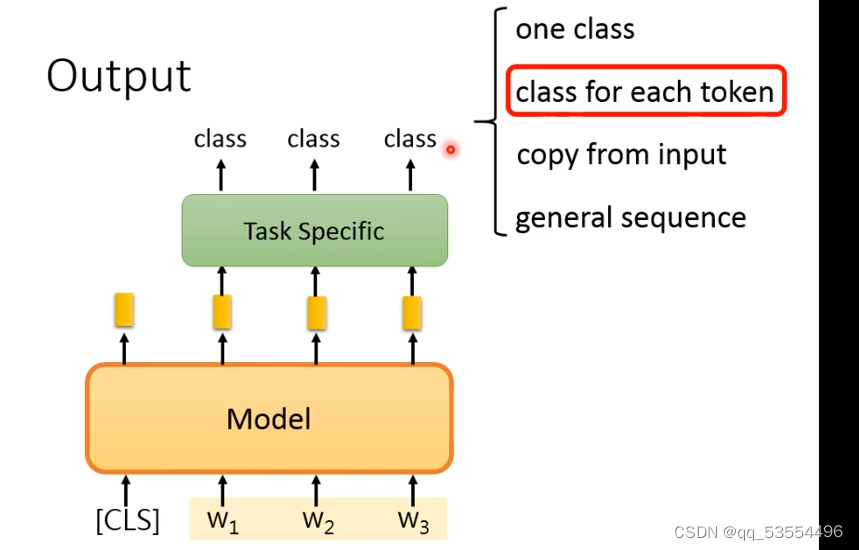
任务二:每个token进行分类
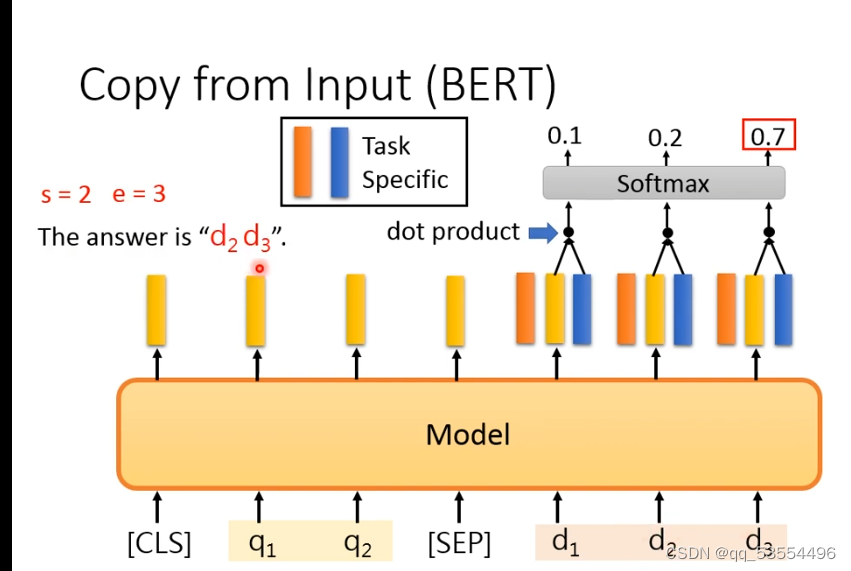
任务三:QA,输入文献d,问题q,模型返(回e,s)为文献d中起止字符位数

具体过程,两个特征向量对token embedding做dot product,使用softmax输出概率最大位置
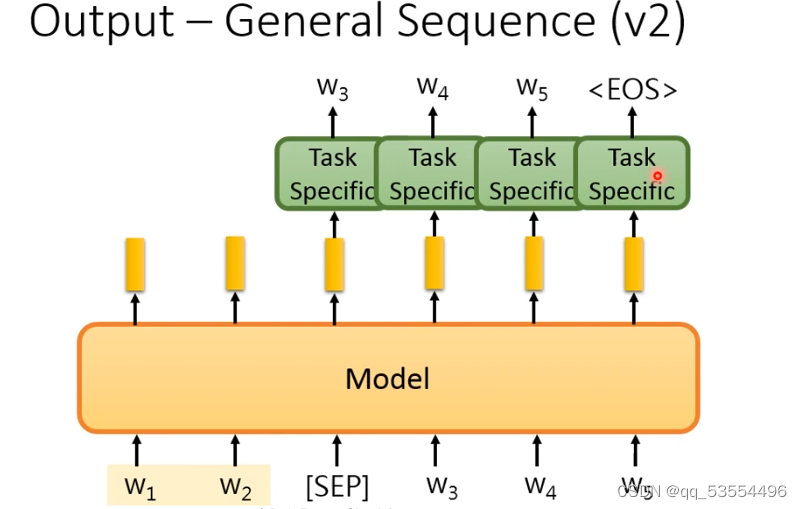
任务四:文转文,第一种架构,弊端是decoder不能使用预训练模型

架构2,将预训练模型同时用作编码器和解码器
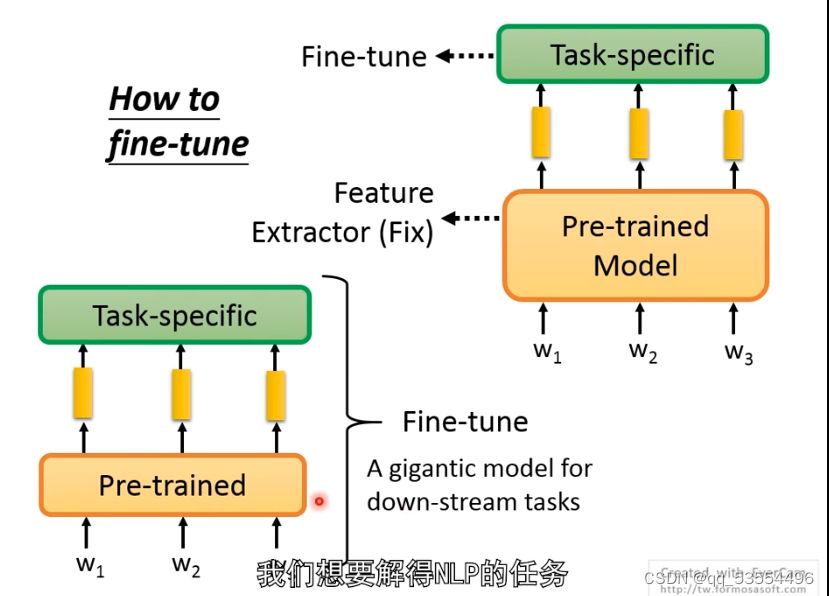
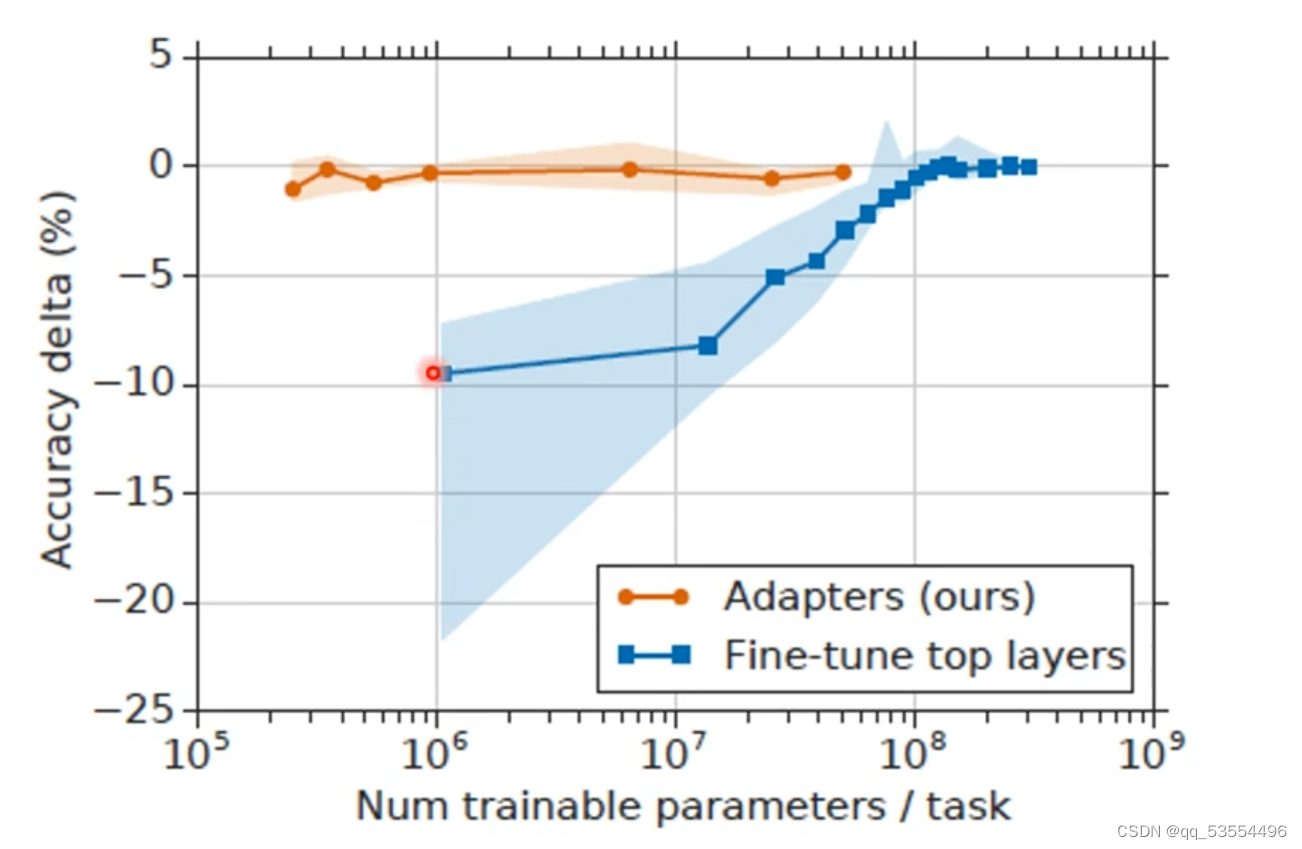
微调分类:全局微调和局部微调,全局微调效果更好。
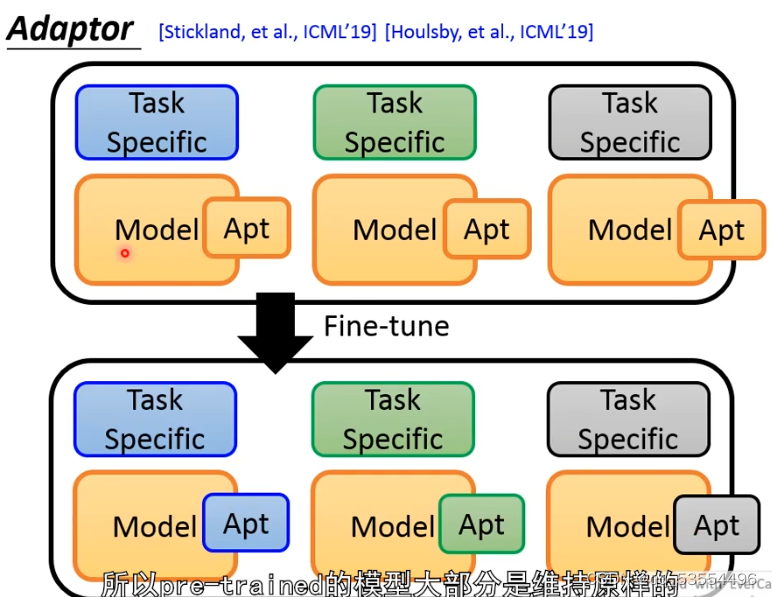
全局微调会产生多个big的预训练model,存在弊端

在预训练模型中加入apt层,只微调apt层,固定其余部分,节省空间,同样达到优秀效果
调apt层效果接近全局微调,蓝色线为只调预训练模型的部分层
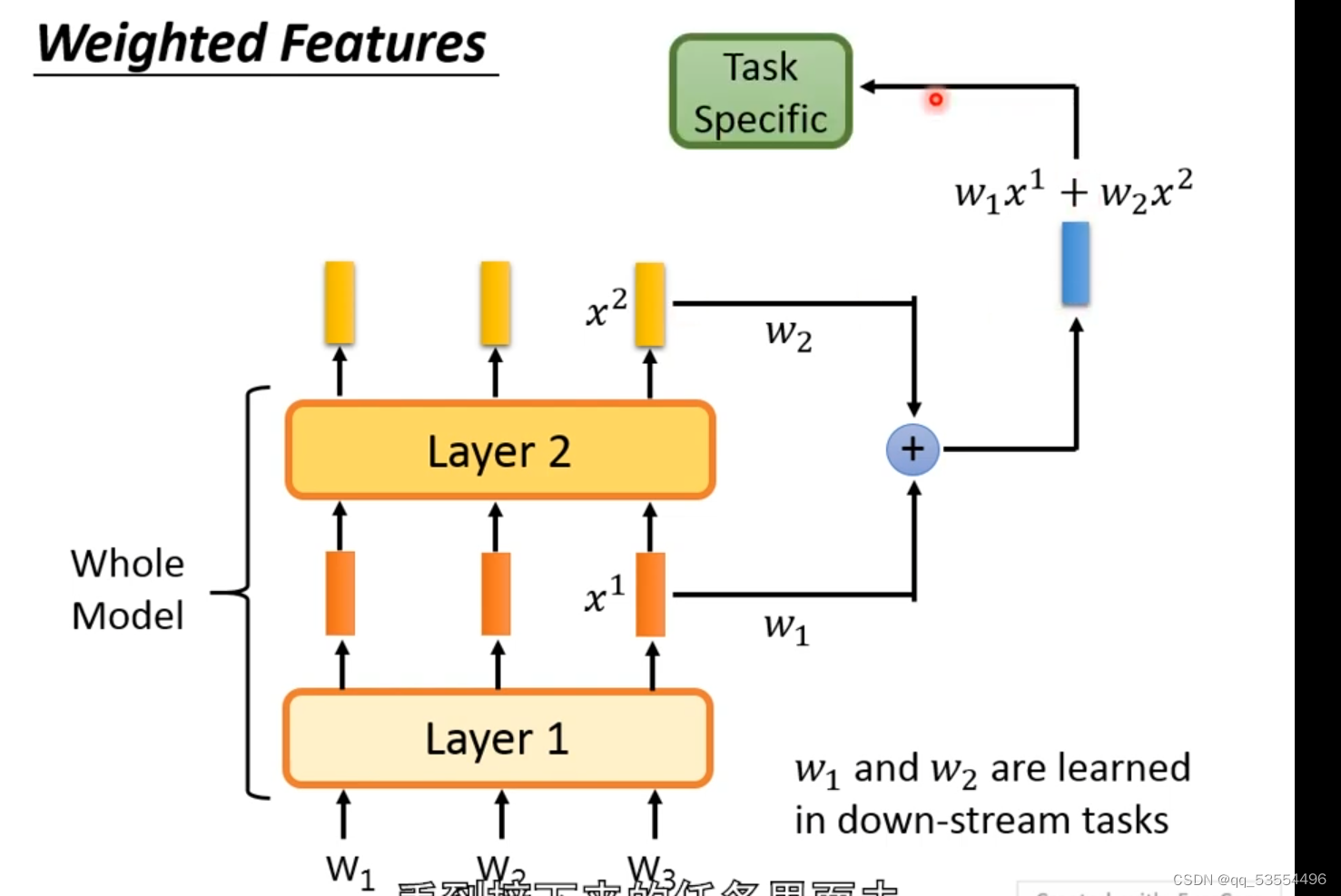
权重学习,学习w1和w2参数
微调具有更高的general 特性。越平缓,泛化性越好
















 1044
1044

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









