






 本文概述了自然语言处理中的多种核心技术,如词性标注、分词、句法分析、指代消解、文本摘要、机器翻译、语法纠错、情感分析等,以及相关的任务如句子分类、真假判断、对话系统和任务导向的NLP应用,还提到了GLUE和SUPERGLUE等评估框架。
本文概述了自然语言处理中的多种核心技术,如词性标注、分词、句法分析、指代消解、文本摘要、机器翻译、语法纠错、情感分析等,以及相关的任务如句子分类、真假判断、对话系统和任务导向的NLP应用,还提到了GLUE和SUPERGLUE等评估框架。
前处理:
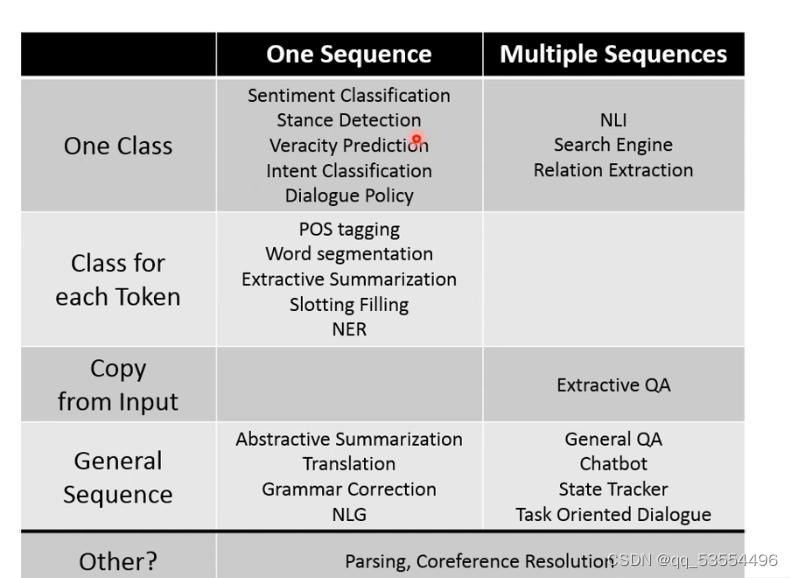
1.POS — Tagging:标记句子中每个词汇的词性。结果作为输入的一部分输入到其他模型。
2.Word Segmentation:用于中文,二值化结果,输出边界,输入downstream
3.Parsing:产生一个树状结构,作为一种额外的特征输入。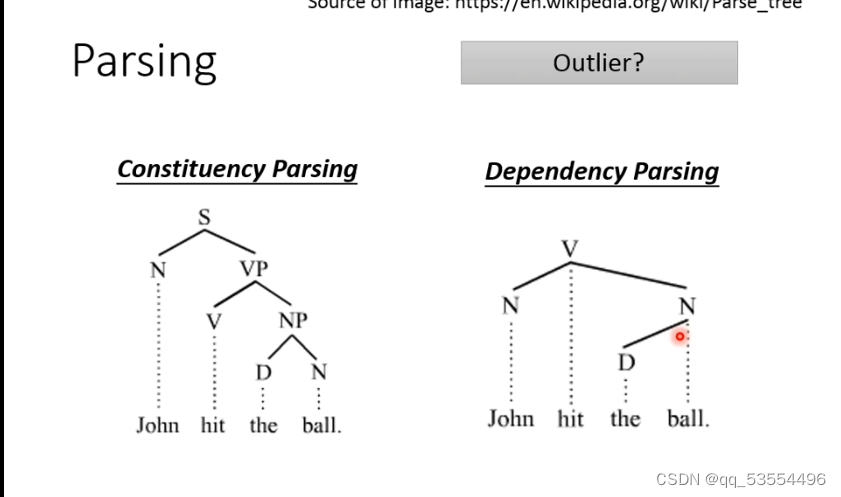
4.Coreference Resolution:指代消解,找出指代相同的词汇

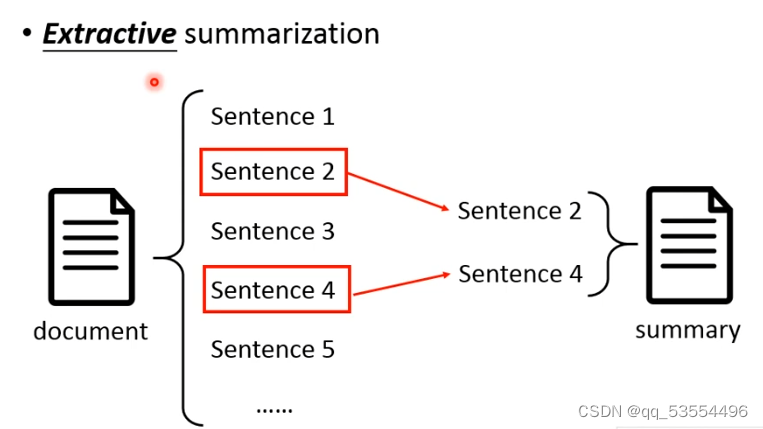
5. Summarization摘要,对句子进行二值化分类,是否放进摘要里(token是句子)
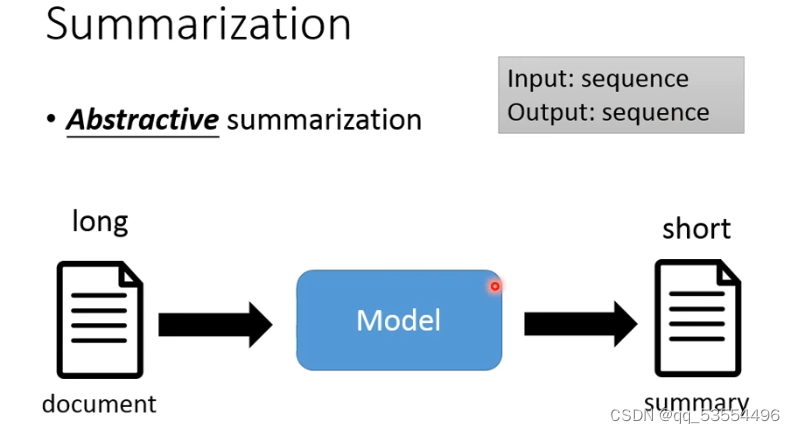
6.抽象摘要,输入很多句子,输出也是很多句子)
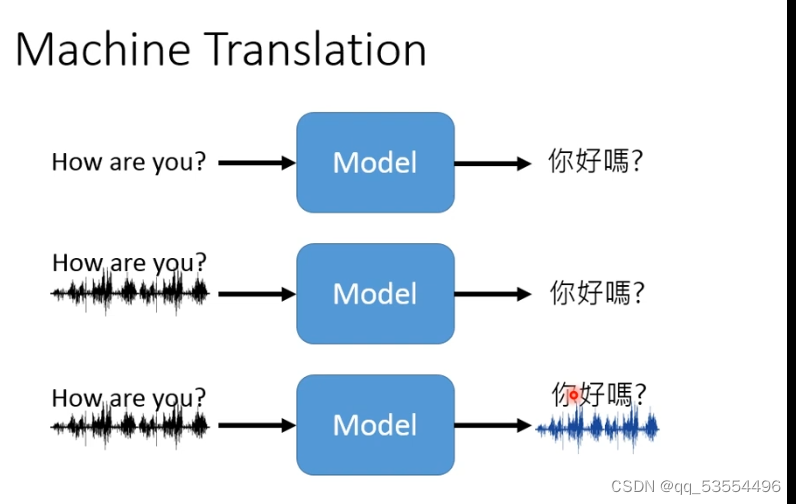
7.机器翻译(seq2seq)
8.语法改错(seq2seq)

9.句子分类&立场分析(输入连个句子),输入句子,输出句子的分类
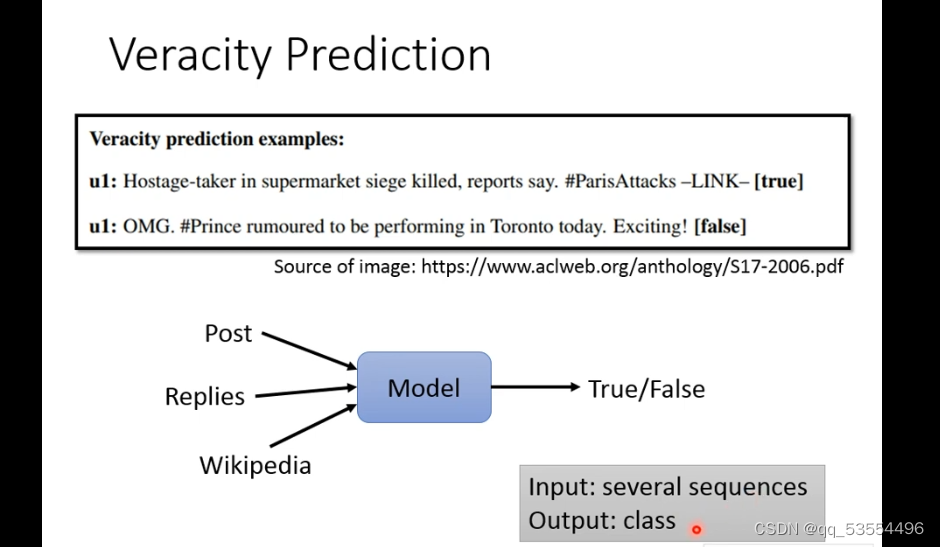
10.真假判断
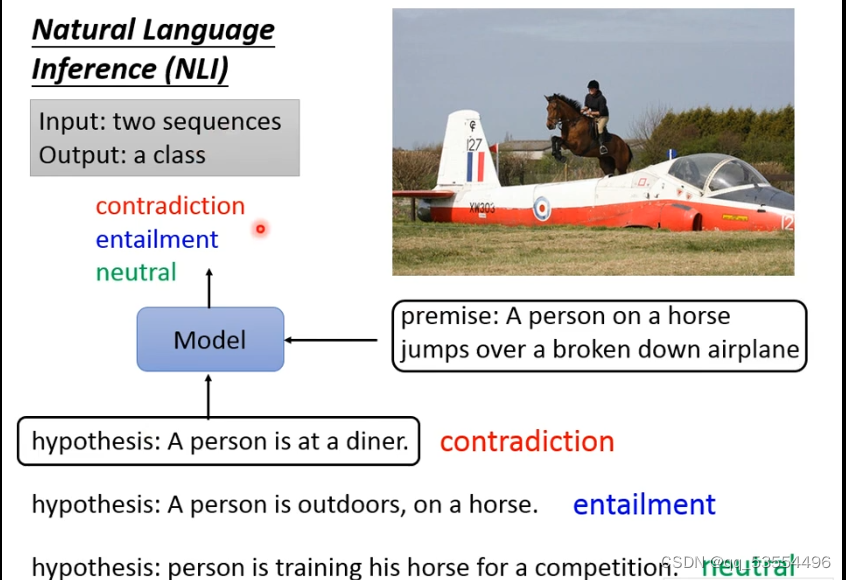
句子推理:
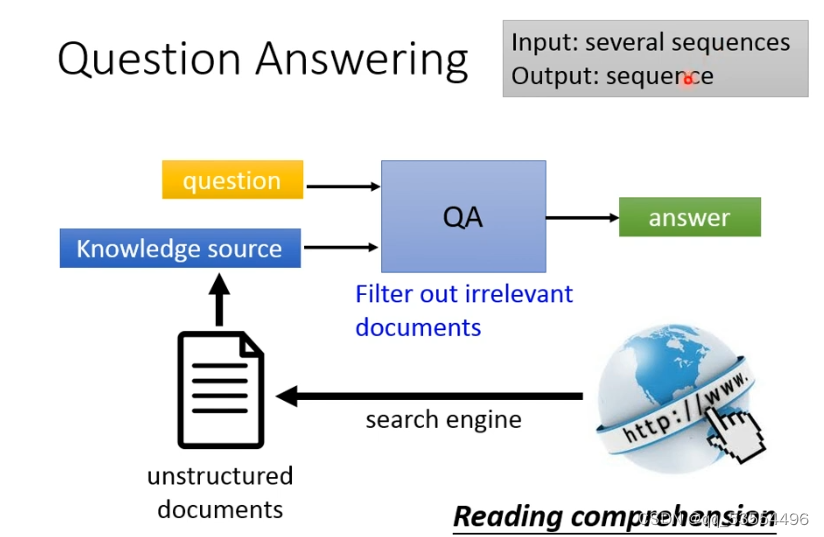
搜索引擎:

QA系统
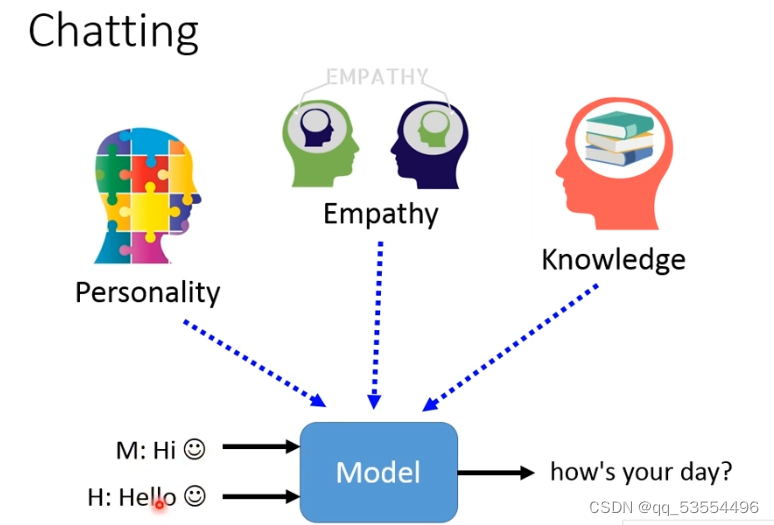
对话(chatting,要输入之前说过的话)
Task oriented
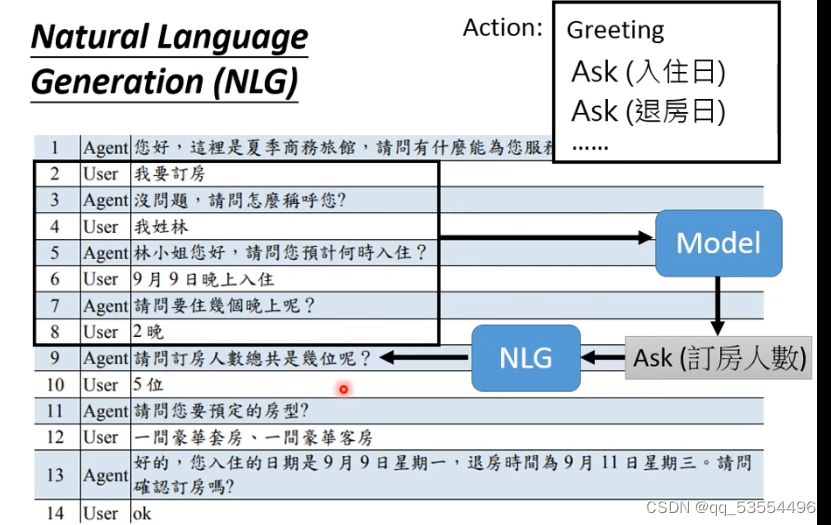
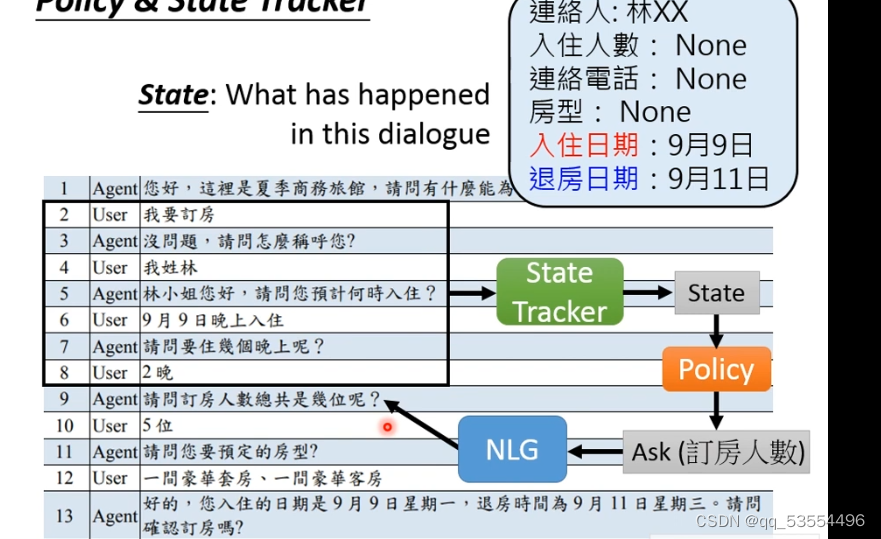
state只与关心的信息有关,记录这些信息,过滤无关信息。policy觉得根据现在的状态采取什么问题。
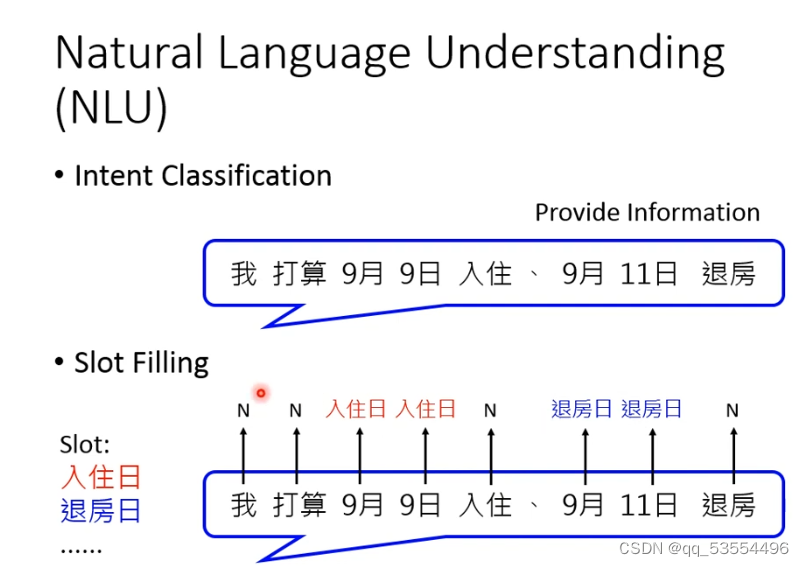
NLU
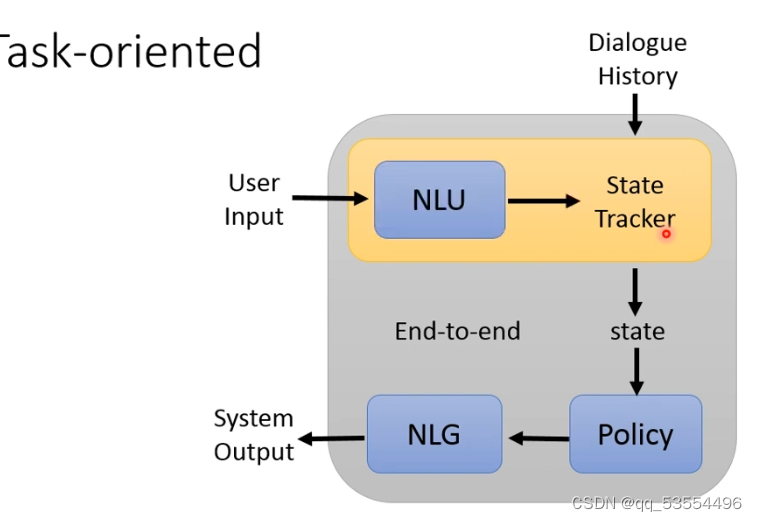
知识图谱

GLUE:用一个模型评价多个语言任务
SUPER GLUE:更加困难的分类任务
任务综述:















 744
744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









