






参考官方文档:Downloading and processing files and images — Scrapy 2.5.0 documentation
一、scrapy框架里面的 image pipeline
使用方法
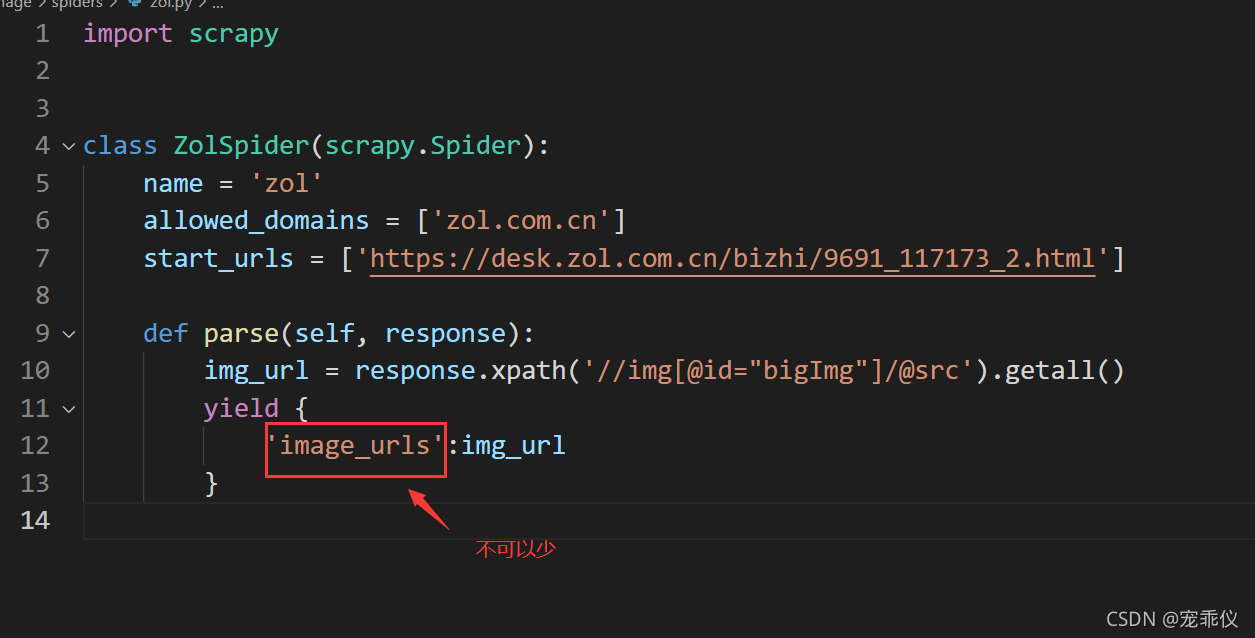
spiders 下的爬虫文件代码
import scrapy
class ZolSpider(scrapy.Spider):
name = 'zol'
allowed_domains = ['zol.com.cn']
start_urls = ['https://desk.zol.com.cn/bizhi/9691_117173_2.html']
def parse(self, response):
img_url = response.xpath('//img[@id="bigImg"]/@src').getall()
yield {
'image_urls':img_url
}
settings.py
ITEM_PIPELINES = {
# 'image.pipelines.ImagePipeline': 300,
'scrapy.pipelines.images.ImagesPipeline':200
}
# 图片下载路径
IMAGES_STORE= 'D:\python_reptile\scrapy中imagepipeline的使用\image\img'二、自定义 imagepipeline
pipeline.py
继承ImagesPipeline类
from scrapy.pipelines.images import ImagesPipeline
class ImagePipeline(ImagesPipeline):
def get_media_requests(self, item, info):
return Request(item.get('key'))
setting.py
ITEM_PIPELINES = {
'image.pipelines.ImagePipeline': 300,
# 'scrapy.pipelines.images.ImagesPipeline':200
}
# 图片下载路径
IMAGES_STORE= 'D:\python_reptile\scrapy中imagepipeline的使用\image\img'注意 这个得要一致















 1216
1216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











