






一、概念
深度学习中的注意力机制从本质上讲和人类的选择性视觉注意力机制类似,核心目标也是从
众多信息中选择出对当前任务目标更关键的信息。
二、Encoder-Decoder 框架引入Attention注意力机制的结构图
ENcoder-Decoder参考Encoder-Decoder 框架_宠乖仪的博客-CSDN博客

生成的目标如下

推广:
yi = f1(Ci,y1,y2,y3,...,yi-1)
,一般的做法中,Ci对构成元素加权求和,即下列公式:
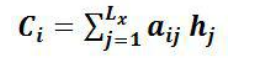

其中,Lx 代表输入句子 Source 的长度,aij 代表在 Target 输出第 i 个单词时 Source 输入
句子中第 j 个单词的注意力分配系数,而 hj 则是 Source 输入句子中第 j 个单词的语义编码(指Encoder 对输入英文单词的某种变换函数。如果 Encoder 是用的RNN 模型的话, 语义编码往往是某个时刻输入 xi 后隐层节点的状态值)。
三、Attention算法流程

流程:
1、求attention weights (注意力机制的权重)
1.1 方法
- 余弦相似度
- 一个简单的神经网络
- 矩阵变换α=hTWzα=hTWz(hT是encode层的隐藏层的输出,z是decode层的隐藏层的输出,W是hT和z相乘的权重,然后用softmax归一化得到attention weights权重)
2、求上下文连续的向量(Context Vector)
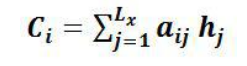
3、求attention vector (注意力机制的向量)

之后把值输出和传入到下一时刻 ,依次循环
















 2775
2775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











