







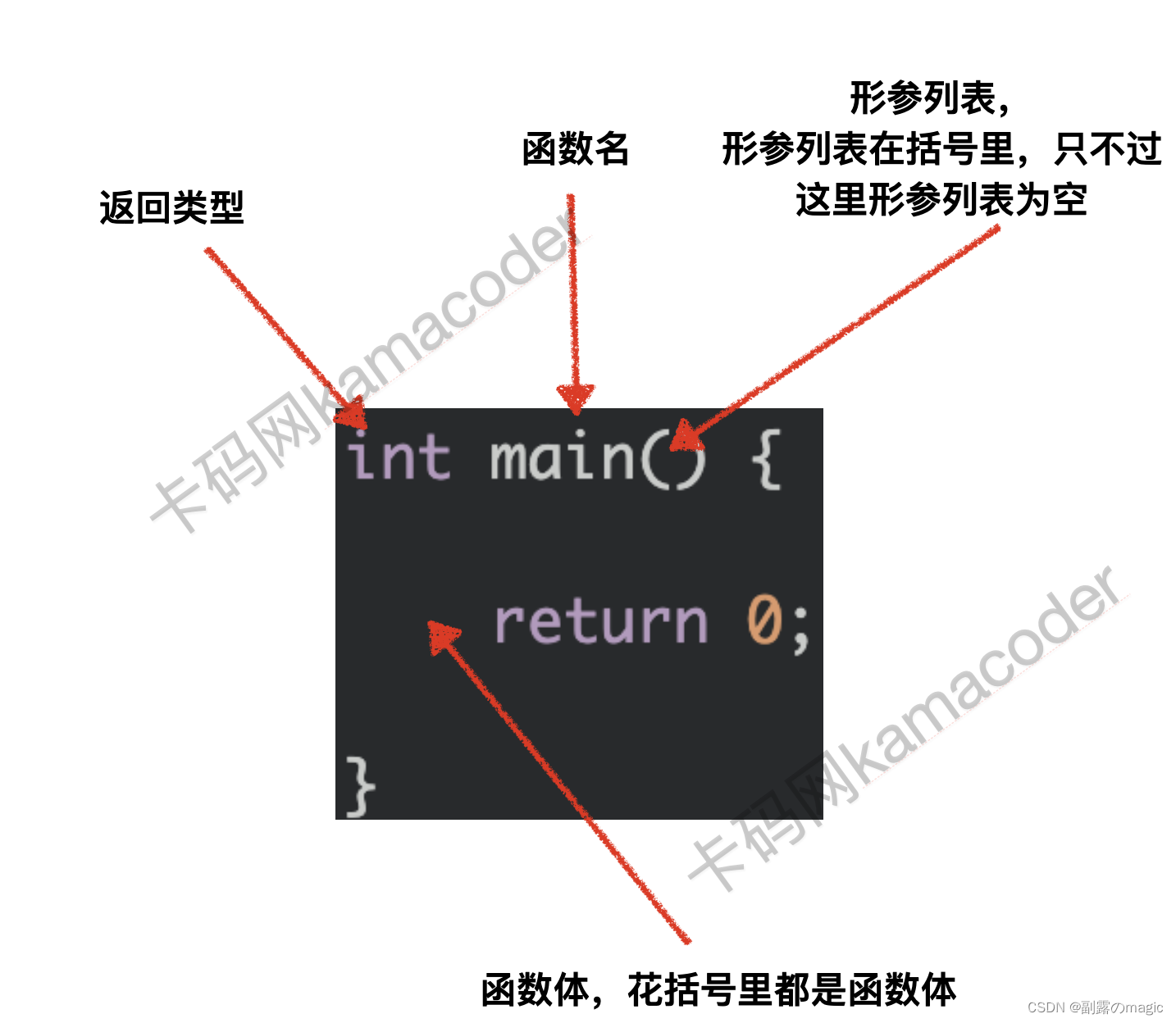
题目描述
输出一个词组中每个单词的首字母的大写组合。
输入描述
输入的第一行是一个整数n,表示一共有n组测试数据。(输入只有一个n,没有多组n的输入)
接下来有n行,每组测试数据占一行,每行有一个词组,每个词组由一个或多个单词组成;每组的单词个数不超过10个,每个单词有一个或多个大写或小写字母组成;
单词长度不超过10,由一个或多个空格分隔这些单词。
输出描述
请为每组测试数据输出规定的缩写,每组输出占一行。
输入示例
1
ad dfa fgs输出示例
ADF副露的愚蠢思考:
首先扫描给出的n,知道有几组数据要输入进去。定义string s,使用getline方法吸收一行的所有内容,遍历,在使用cin读取每一个s,收入到若干个单词,最后将每个单词的ASCII码减少32变为大写字母,通过string 的相加放到一起,组合成一个新的string再打印出来即可。
正确的思路:
首先扫描给出的n,知道有几组数据要输入进去。
使用了 getchar() 函数来吸收一个回车符,因为在输入 n 之后通常需要输入回车符才会输入下一行。
之后仍然可以使用while循环来处理n行数据,每一行数据使用getline(cin, n) 来进行接收。
之后分步行动,首先第一个字母一定会转化成大写(如果需要的话);其次,凡是当前位置是空格,而其下一个位置不是空格的也会转化成大写。因此分别处理,并用string分别加上两个部分的处理结果。(此处可以撰写一个函数来进行调用)
#include<iostream>
#include<string>
using namespace std;
int main(){
int n;
cin >> n;
// string result,s;
string s;
getchar(); //吸收一个回车符号
while(n--){
string result;
getline(cin,s);
if(s[0] >='a' && s[0] <= 'z'){
s[0] -= 32;
}
result += s[0];
for (int i = 1 ; i < s.size()-1 ;i++){
if (s[i] == ' ' && s[i+1] != ' '){
if(s[i+1]>='a' && s[i+1] <= 'z'){
s[i+1] -= 32;
}
result += s[i+1];
}
}
cout << result << endl;
}
return 0;
}未使用函数的代码如上,在此提一下中间多次出错的呆逼原因,也即在定义string是想当然的把s(用来存放每一行内容的字符串)和result(用来储存所有结果的字符串)都当成全局变量定义了,但是s每次使用之后都应重置,否则下一次读取还会读取上一次的结果,导致结果有很大偏差。应该当成一个局部变量进行操作。
函数定义
如果后面还需要将小写字符转换成大写,那我们还需要再写一次,代码就会显得有些冗余,更致命的是,如果这是一段很长的代码,并且在多个地方应用,当我们有了新的需求,需要对这一段代码进行修改时,我们需要一处处的找出再修改,这种情况下我们可以使用第一节中提到的函数,将代码模块化,并在合适的地方重用,从而增加代码的复用性和可维护性。
代码结果如下,注意result每一次依然要制空。
#include<iostream>
#include<string>
using namespace std;
char getbigchar(char a){
if(a >='a' && a <= 'z'){
a -= 32;
}
return a;
}
int main(){
int n;
cin >> n;
string result,s;
getchar(); //吸收一个回车符号
while(n--){
result = ""; //记得要将result制空
getline(cin,s);
// // if(s[0] >='a' && s[0] <= 'z'){
// // s[0] -= 32;
// // }
// result += s[0];
result += getbigchar(s[0]);
for (int i = 1 ; i < s.size()-1 ;i++){
if (s[i] == ' ' && s[i+1] != ' '){
// if(s[i+1]>='a' && s[i+1] <= 'z'){
// s[i+1] -= 32;
// }
// result += s[i+1];
result += getbigchar(s[i+1]);
}
}
cout << result << endl;
}
return 0;
}形参和实参
实参和形参是与函数调用相关的两个很重要的概念,用于在函数调用时传递数据和接收数据。
形参是函数定义中声明的参数,位于函数的参数列表中。形参的作用是定义函数接受的参数的类型和名称,定义的形参只在函数执行期间有效,在函数执行完毕后会被销毁。而且它作用的范围(作用域)仅限于函数体内部,因此它们与函数外部的变量名称可以相同,而不会发生冲突。
实参是函数调用中传递给函数的具体值或变量,实参传递的值必须与函数的形参类型匹配,否则会发生类型错误。当函数执行时,实参的值会复制一份给形参,因此在函数中的修改只会影响形参的值,不会影响传递的实参。
引用
在定义函数的时候,我们写形参列表的时候使用了&a的形式,这里的&表示参数a是一个引用,这里的“引用”是什么意思呢?
引用实际上是为变量起了另外一个名字,并且在引用上执行的操作会影响到引用所指向的原始变量。在声明引用时,需要在变量名前使用 & 符号。引用必须在声明时进行初始化,并且一旦初始化,就不能改变引用的目标。
引用常常作为函数参数来使用,以便在函数内部修改函数调用时传递的变量,比如下面的示例:
#include <iostream>
using namespace std;
void changeValue(int & a) {
a = 100; // 修改调用方传递的变量的值
}
int main() {
int x = 10;
cout << x << endl;
changeValue(x); // 传递x的引用给函数
cout << x << endl; // x的值被函数修改为100
return 0;
}
也即修改了外部参数。使用原因是:当函数传递参数时,通常会创建参数的副本。使用引用参数可以避免不必要的参数复制,这对于大型数据结构(如数组)尤其有用,因为复制这些数据结构会产生显著的开销。
如有错误,敬请指正,不胜感激!

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









