






问题引入:
考虑问题:输入一堆词向量,要求输出他们每个单词的词性。例如“ I saw a saw. ”我们可以很明显地看出第二个”saw“为名词,但是若是普通的seq2seq的网络,每个向量单独经过FC层,网络很难判断第一个”saw“和第二个”saw“之间的差异,那么如何才能使网络考虑上下文信息呢?
第一个解决办法是,将词向量连接到每个邻近的FC层,来获取更多的相关信息。

这种方法相当于给每个FC层一个window的资讯,让其考虑相邻向量之间的信息。但是,这种方法明显存在极限,例如,要考虑所有sequence的信息,而sequence的长度不同,我们要统计所有sequence的长度,开出一个最大的window来连接词向量。这样做的弊端是FC层参数极大且网络极易过拟合。
第二个办法也就是本文的主角:Self-attention
在FC层前添加一个注意力模块,使得每个输入向量均联合整个sequence的资讯,对于注意力模块而言,Input的向量数目等于output的向量数目。
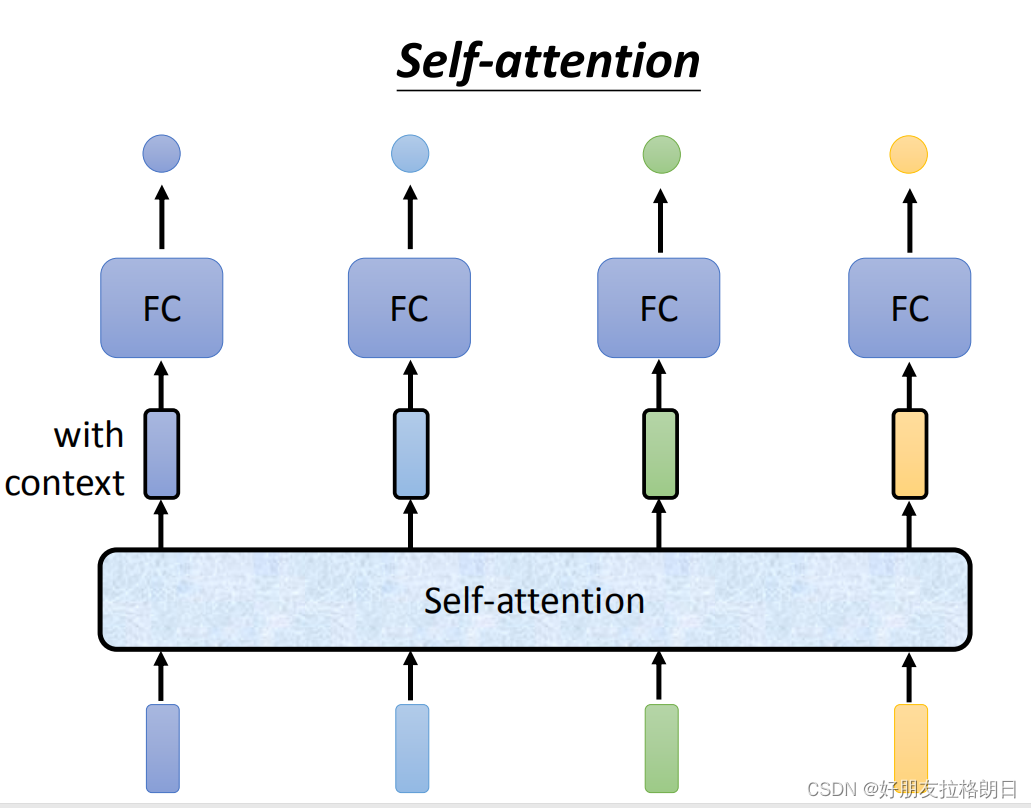
那么注意力模块到底是怎么实现让每个词向量都能联合整体信息的呢?
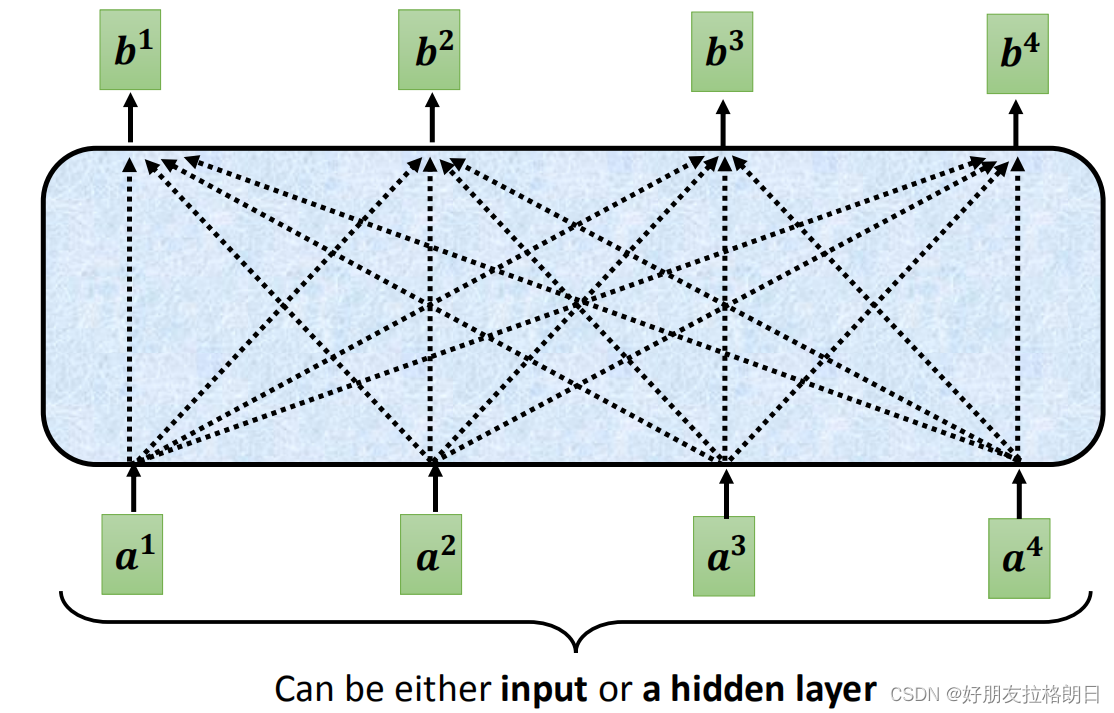
在解决这个问题前,有必要说明一下,注意力模块的输入并不一定是初始的词向量,也可以是经过网络的隐藏层处理得到的输出向量。
注意力机制的实现:
(1)计算每个输入向量之间的关联程度α
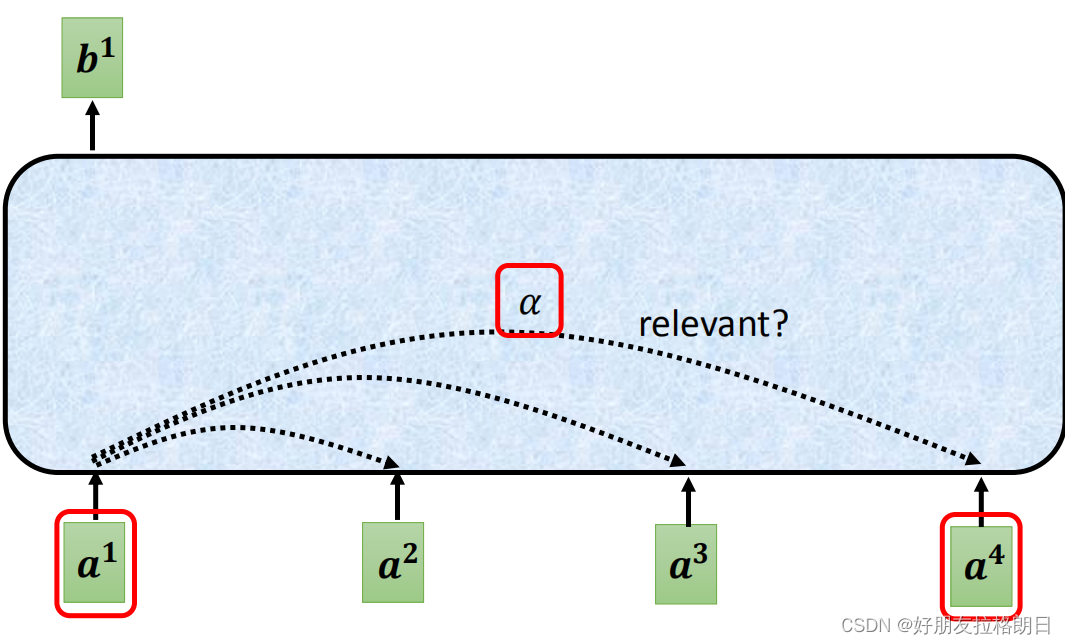
计算向量之间关联程度的方法有很多种,这里我主要总结李宏毅老师所讲的点乘方法,点乘不仅用在注意力机制这里,很多计算相似性,关联度的地方都用到了点乘。
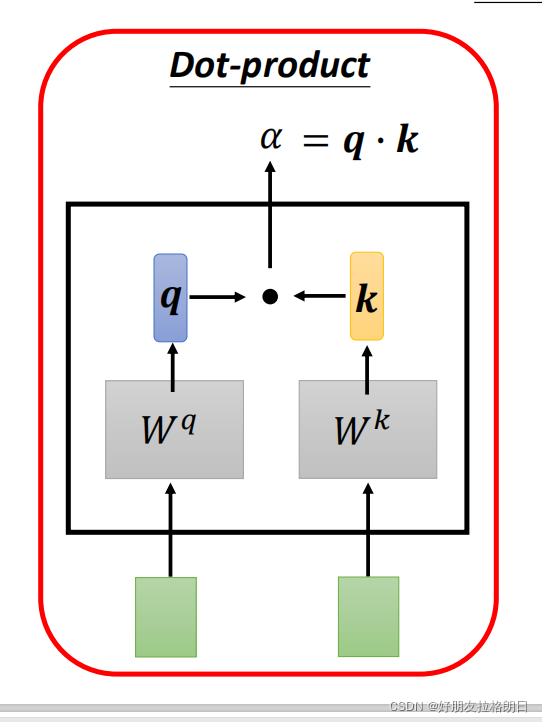
以两个输入向量为例,我们需要初始化两个权值矩阵和
,将输入*向量a1和a2分别与
,
相乘得到q,k元素,每个元素均为tensor,而关联程度α就是q点乘k的值。
类似地,多个输入向量时也按此方法先计算单个向量和其他向量间的关联程度,计算出的attention score值经softmax归到0-1区间,
(2)计算经过注意力模块后的输出b
这里先贴上计算单个输出的公式,
这里引入了一个新的权重矩阵,将此矩阵与输入相乘得到元素V,对应的元素V与之前经过softmax的attention score相乘得到整合所有信息的输出b。

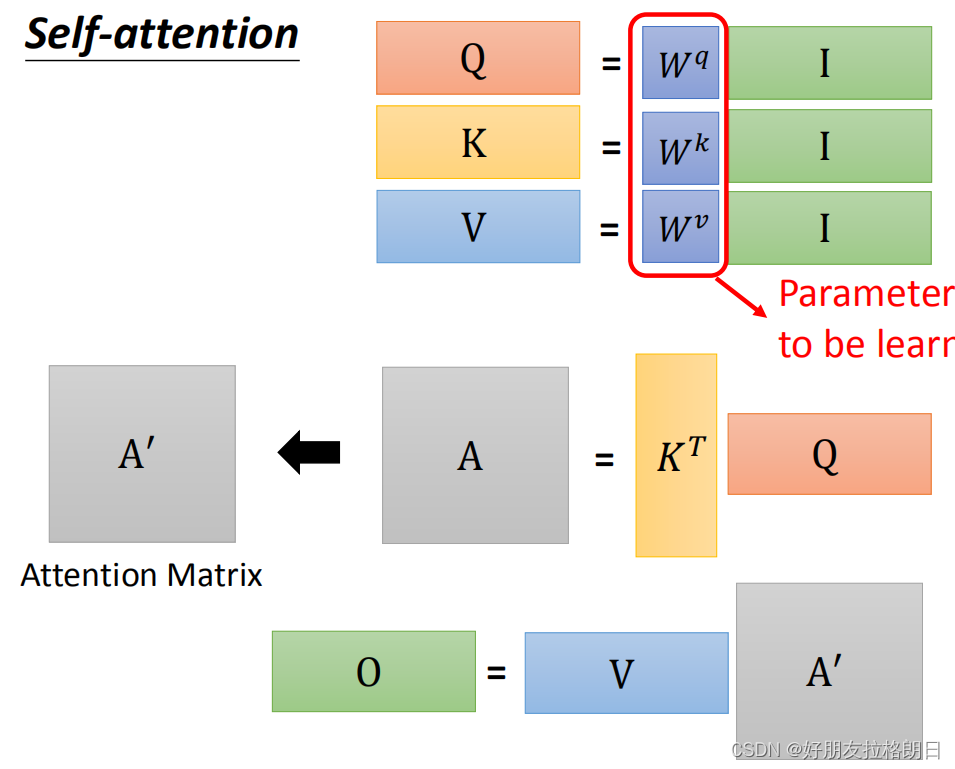
总结:上面给出的是单个向量的计算方式,下面会给出多个向量的矩阵计算形式。注意力机制最重要的就是三个权重矩阵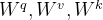 ,通过这三个权重矩阵与输入的乘积得到元素Q, K, V。
,通过这三个权重矩阵与输入的乘积得到元素Q, K, V。
关于Q,K,V的作用:其中的Q和K是为了计算输入之间的相互关系,即attention score,而添加V则是为了保留输入特征,这样的输出才合理。
一句话来说,注意力机制就是通过权重矩阵自发地计算输入之间的关系,以此来得到整合所有资讯的输出。
矩阵形式的计算方式:
(1)Q, K, V的计算:
同样,引入三个权重矩阵,上公式:,
,
, 将a1,a2,a3,a4拼凑为矩阵
,与
相乘得到的q1,q2,q3,q4拼凑为矩阵Q, 同理得到矩阵K和V。
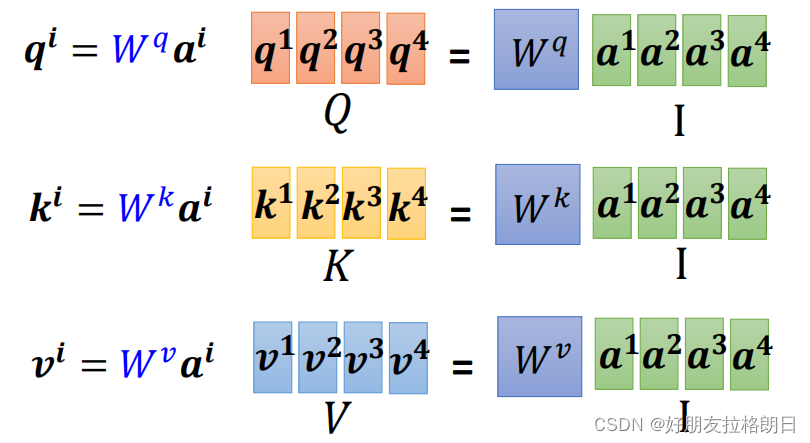
(2)attention score的计算
还是先上公式, ,将计算出单个向量与其他向量的attention score拼凑为一列,以输入a1为例:
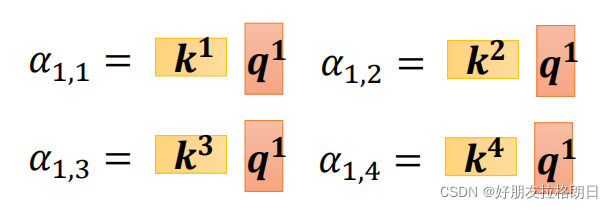
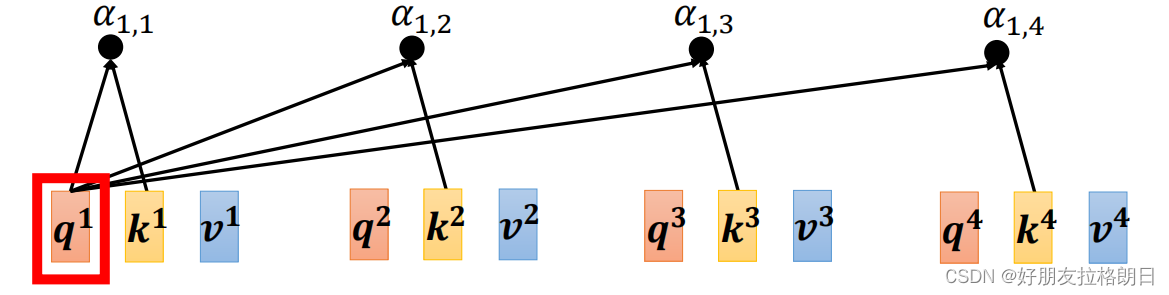

按此方式计算出每个向量的相互关系,按列拼凑为attention score的矩阵A,而之前的均已拼凑为矩阵K, Q,故其计算方式如下:

(3)输出的计算方式:
上公式,,这里先以b2为例:
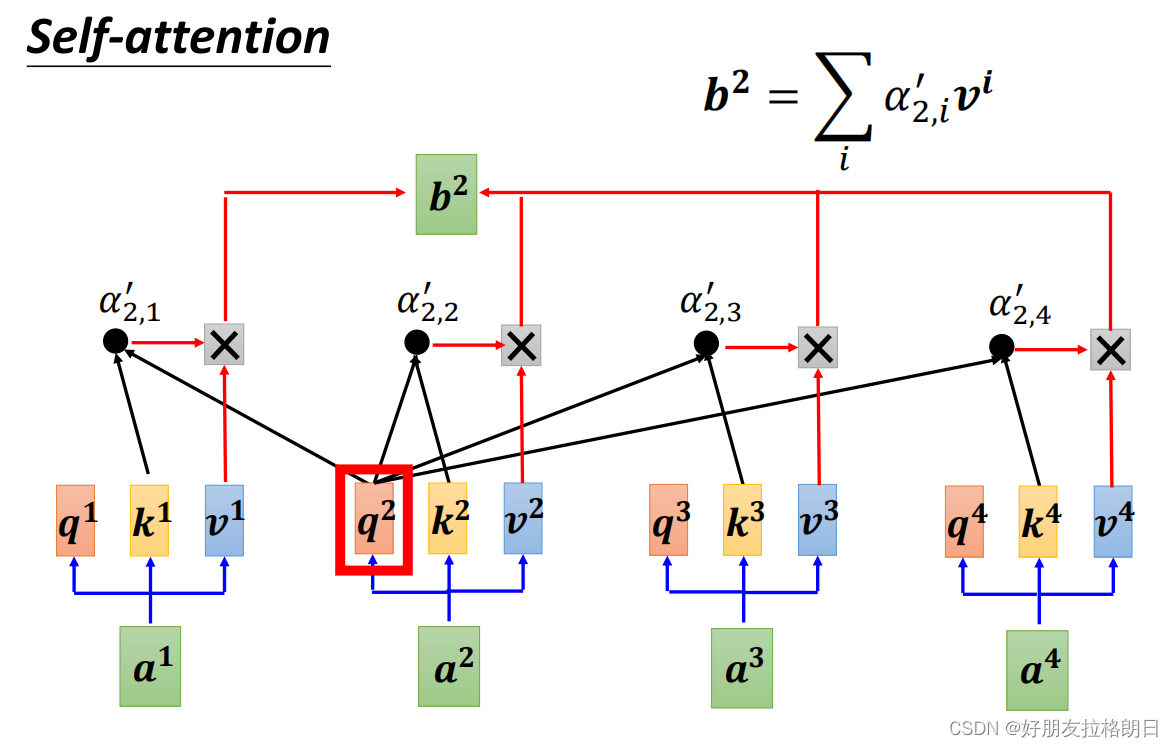 而之前的attention score已经拼凑为矩阵A,
而之前的attention score已经拼凑为矩阵A, 已经拼凑为矩阵V,若将输出拼凑为矩阵O,则可得以下矩阵运算:
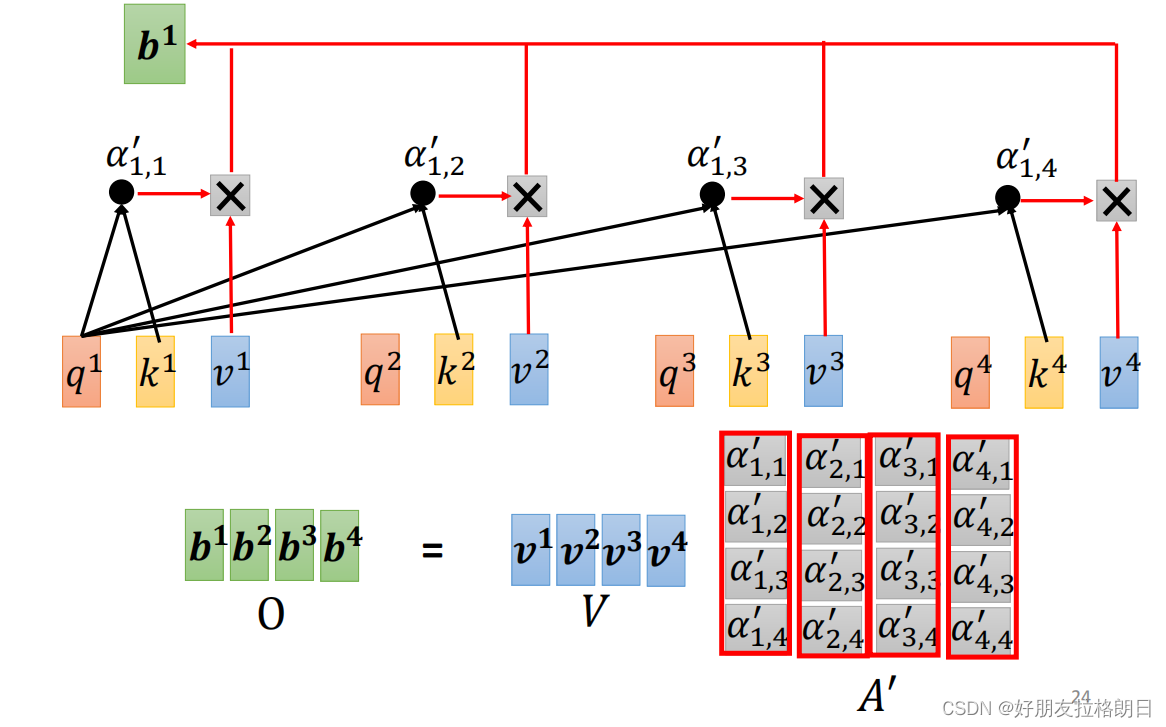
若将输入向量拼凑为矩阵I, 则可以用下面这个图完整表示注意力机制的运算过程:
注:以上内容均来自李宏毅老师的课程讲解及个人的一点理解
新手学习,如若有误,还请指正!














 4591
4591











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









