







前言
本期依旧是大模型篇,本期笔者将介绍构建大模型的关键技术以及最后文末进行一下推理模型的介绍。当然本期是更多的是对之前几期大模型介绍的一种补充。
基础知识
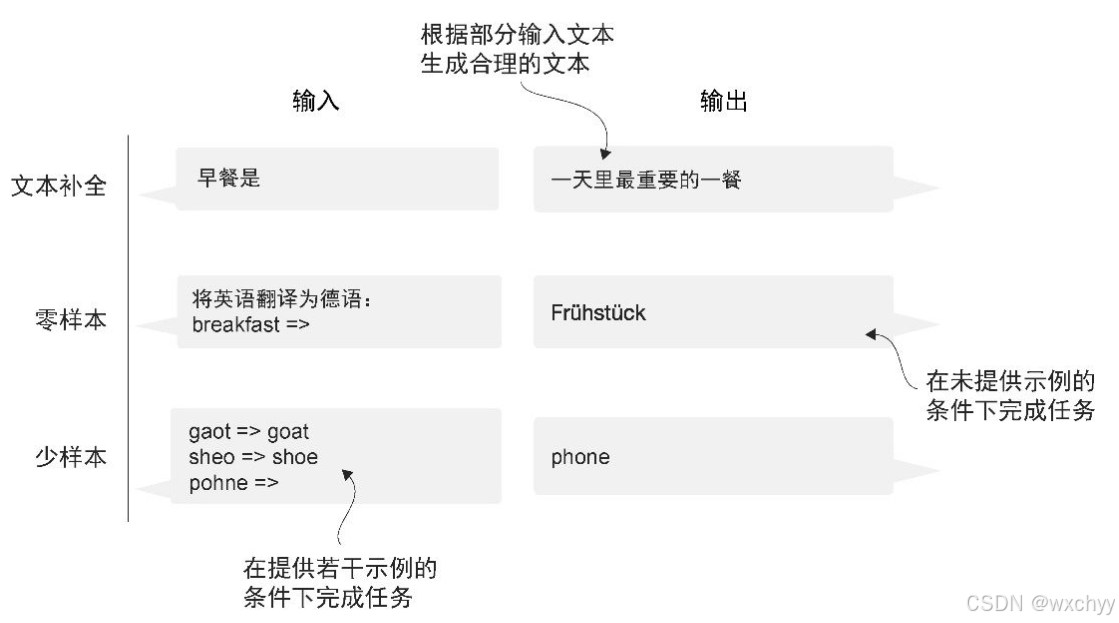
大模型的构建通常包括预训练和微调,预训练”中的“预”表明它是模型训练的初始阶段,此时模型会在大规模、多样化的数据集上进行训练,以形成全面的语言理解能力。微调阶段会在规模较小的特定任务或领域数据集上对模型进行针对性训练,以进一步提升其特定能力。现在最流行的两种微调方法是指令微调和分类任务微调。之后我将详细介绍其中的区别。此外,模型进行预测的时候,可以进行不同的输入,分为零样本学习和少样本学习,零样本学习(zero-shot learning)是指在没有任何特定示例的情况下,泛化到从未见过的任务,而少样本学习(few-shot learning)是指从用户提供的少量示例中进行学习。
构建大语言模型
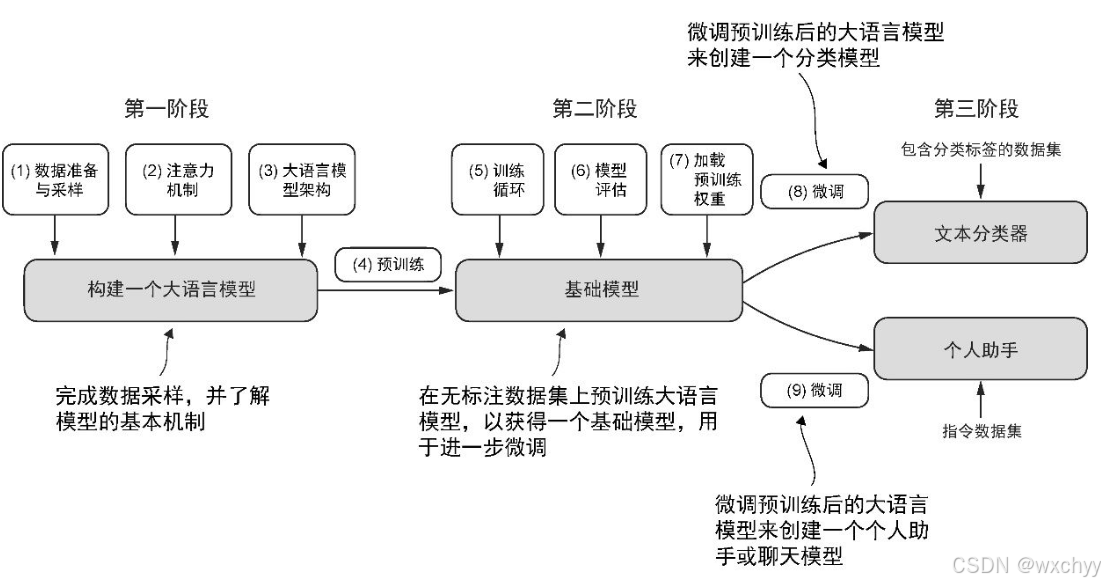
我们将大模型的构建分为三个阶段,第一阶段实现模型架构和数据准备,第二阶段预训练大模型,大三阶段微调大模型。
数据集处理
首先我们需要对文本数据进行预处理,使用字节对编码将文本分割为单词词元和子词词元,然后利用滑动窗口方式对训练样本进行采样,最后将词元转化为输入到大语言模型中的向量。
词嵌入
由于大语言模型不能直接处理原始文本,我们需要将其转化为向量格式。将数据转化为向量格式的过程通常称为嵌入。我们需要将词映射为向量给大语言模型进行处理,这称为词嵌入。尽管词嵌入是文本嵌入中最常见的形式,但也存在针对句子、段落乃至整个文档的嵌入技术。句子嵌入或者段落嵌入在RAG检索增强生成领域非常流行,通过将输入作为查询与检索(搜索外部知识库),将检索结果与输入结果,作为上下文给模型。接下来我们介绍一些常见的词嵌入方法。
主要包括Word2Vec、GloVe、FastText、BERT、ELMO等等。
1 Word2Vec
它主要包含两种训练方法CBOW、Skip-Gram:
- CBOW 模型通过上下文单词预测目标单词。例如,给定句子 “The cat sits on the mat”,若目标词是 “sits”,则输入的上下文可能是 “The cat ___ on the mat”。CBOW 适用于小规模数据集,训练速度较快。
- Skip-Gram 与 CBOW 相反,它通过目标词预测上下文单词。例如,目标词 “sits” 需要预测周围的词 “The”, “cat”, “on”, “the”, “mat”。Skip-Gram 在大型数据集中表现更好,尤其能捕捉稀有词的语义信息。
2 GloVe(Global Vectors for Word Representation)
GloVe 由斯坦福大学提出,结合了全局统计信息(如词频共现矩阵)和局部上下文窗口。例如,它统计整个语料库中 “cat” 和 “animal” 共同出现的频率,生成更具全局一致性的词向量。
3 FastText
FastText 由 Facebook 开发,在 Word2Vec 基础上引入子词(subword)信息。例如,单词 “running” 会被拆解为 “run”, “nni”, “ing” 等子词,从而更好地处理未登录词(如 “jogging”)和词形变化。
4 BERT(Bidirectional Encoder Representations from Transformers)
BERT 是 Google 提出的基于 Transformer 的预训练模型,能生成上下文相关的词向量。例如,单词 “bank” 在 “river bank” 和 “bank account” 中会得到不同的向量表示,解决了传统词嵌入的多义词问题。
5 ELMO(Embeddings from Language Models)
ELMO 通过双向 LSTM 模型生成动态词向量。例如,它结合单词的前后上下文信息,为同一词在不同语境中赋予不同表示。
文本分词
文本分词是将输入文本分割为独立的词元。词元可以是单个单词,也可以是包括标点符号在内的特殊字符,这里我们介绍一种高效的分词方法,BPE分词。
BPE
Byte-Pair Encoding(BPE,字节对编码)是一种用于自然语言处理(NLP)的分词算法,属于子词分词(Subword Tokenization) 方法的一种。它的核心思想是通过合并高频的字符对或子词来构建动态词汇表,既能减少词汇表的大小,又能有效处理未登录词(OOV,Out-of-Vocabulary)问题。BPE 最初用于数据压缩,后被引入 NLP 领域,成为现代预训练模型(如 BERT、GPT、LLaMA 等)的重要分词基础。
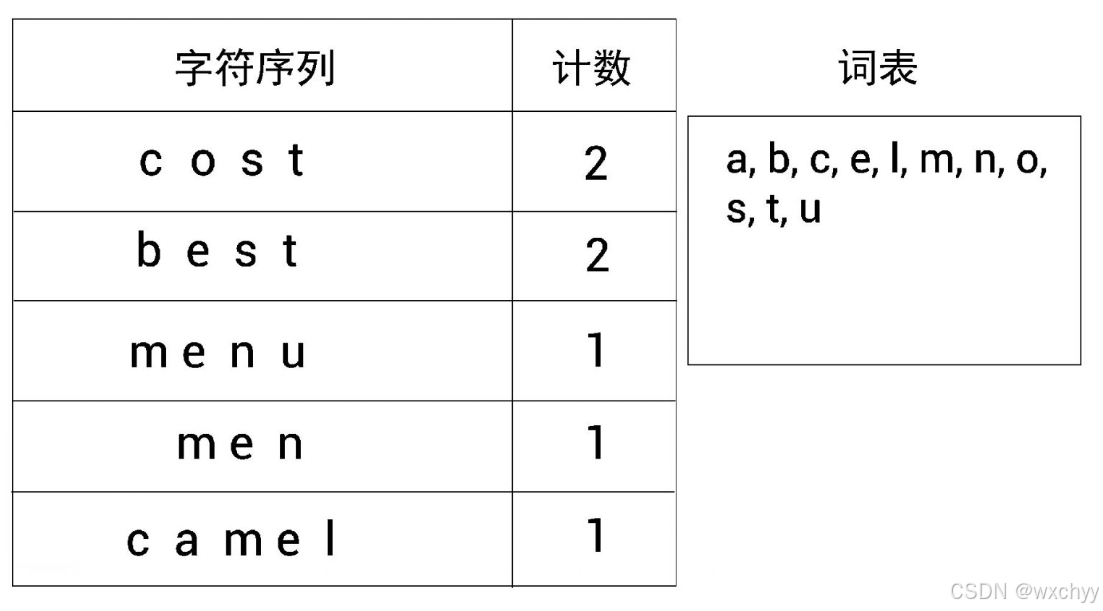
我们通过一个例子来了解字节对编码(byte pair encoding, BPE)的工作原理。假设有一个数据集,我们首先从其中提取所有的单词并计算它们出现的次数。假设从数据集中提取的单词和计数如下所示。
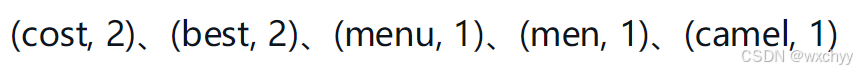
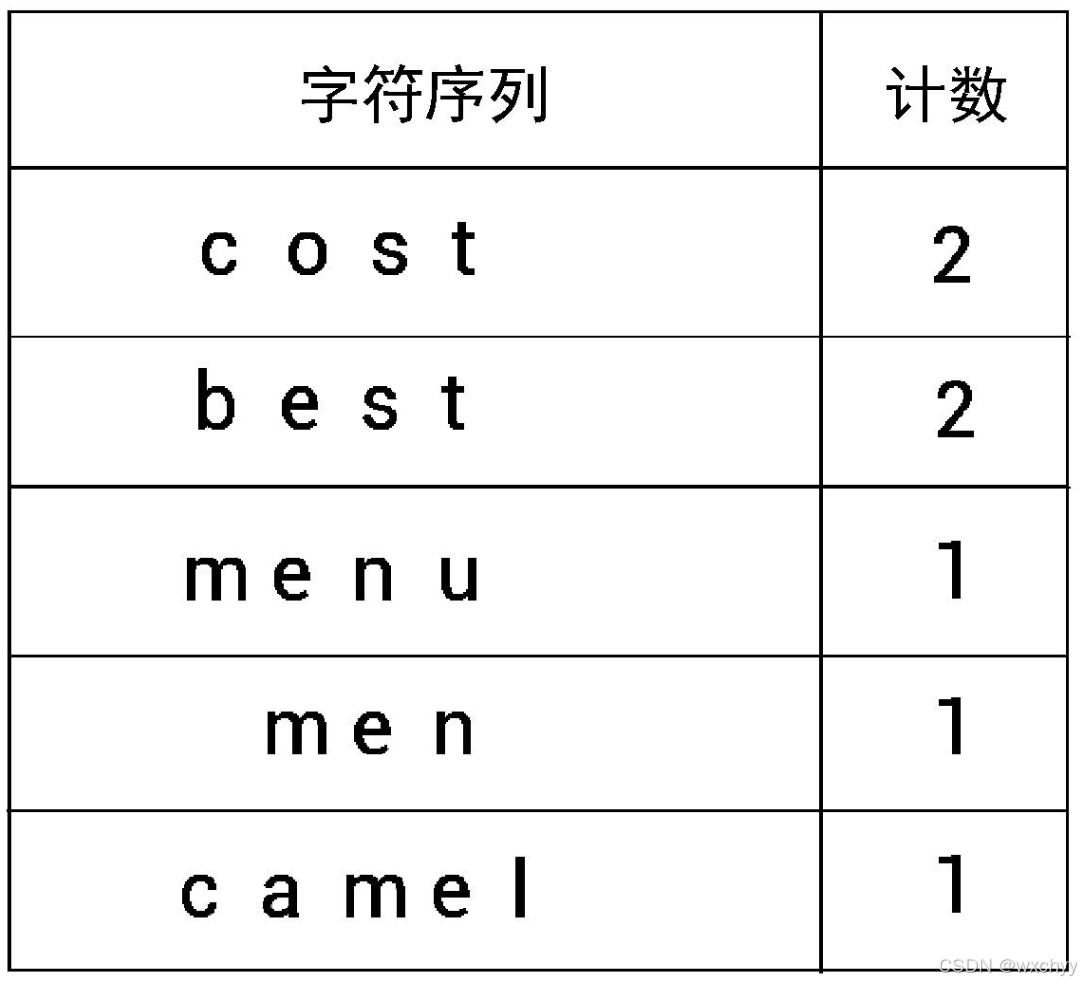
我们将所有的单词拆成字符并创建一个字符序列。
接下来,我们定义词表的大小。假设我们要创建大小为14的词表,也就是说,要创建包含14个标记的词表。现在,让我们了解如何使用字节对编码创建词表。
首先,将字符序列中的所有非重复字母添加到词表中。
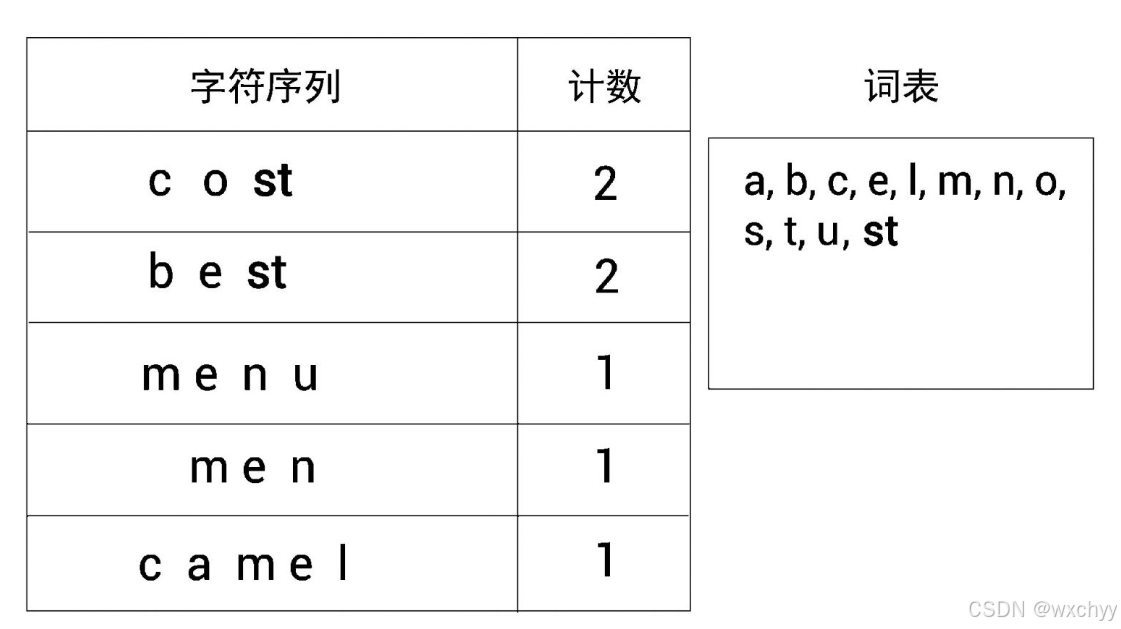
接着,在词表中添加一个新标记。我们先确定出现得最频繁的符号对,再合并,将其添加到词表中。需要重复这一步骤,直到达到词表的大小要求。我们发现出现得最频繁的符号对是s和t,因为符号对s和t出现了4次(两次是在cost中,另外两次是在best中)。因此,将s和t合并,并将其添加到词表中。
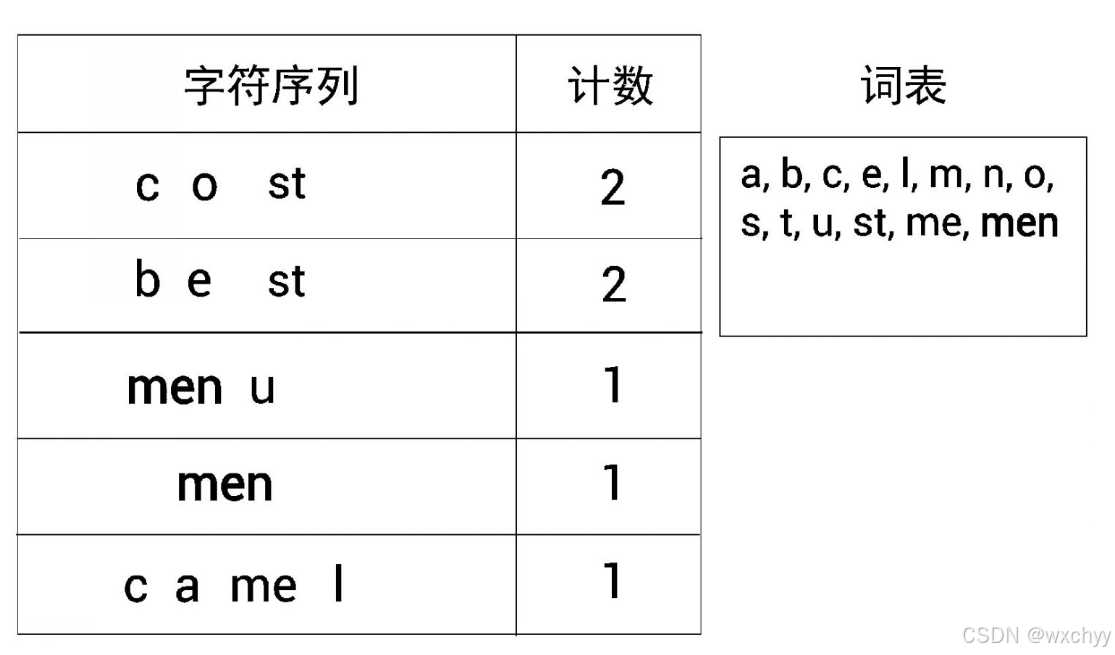
下面,重复同样的步骤,也就是说,再次检查出现得最频繁的符号对。最后构成了我们需要的词表。
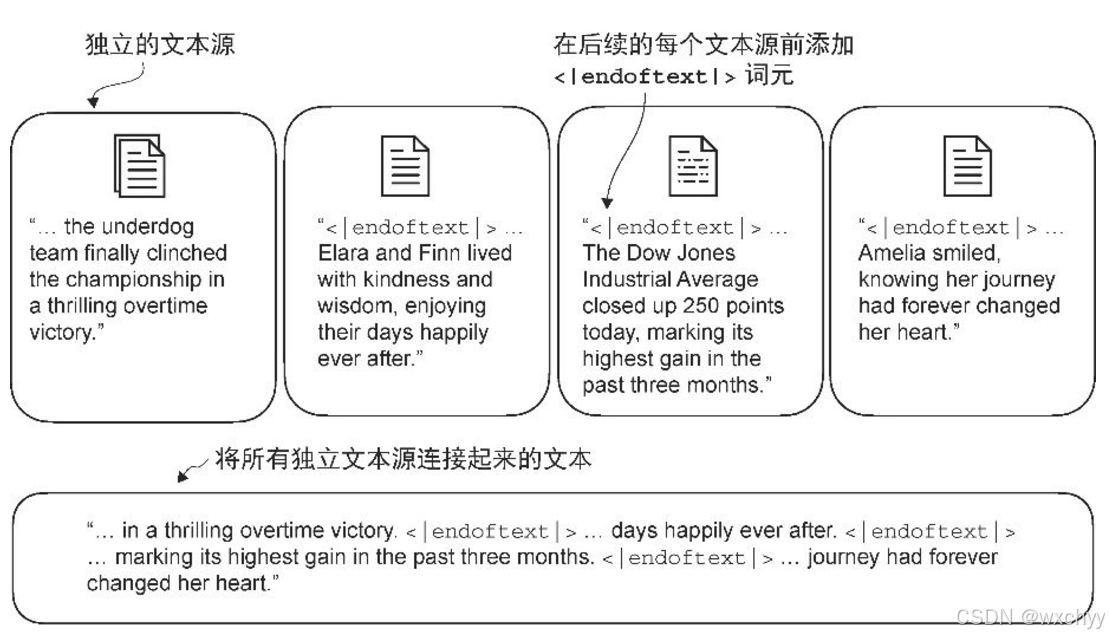
引入特殊上下文词元
我们在文本中引入一些特殊上下文词元来增强模型对上下文和其他相关信息的理解。我们会在不相关的文本之间插入特殊词元。例如,在训练类 GPT 大语言模型时,如果使用多个独立的文档或图书作为训练材料,那么通常会在每个文档或图书的开头插入一个词元<|endoftext|> ,以区分前一个文本源。
在不同的大语言模型中,研究人员可能会考虑引入如下这些特殊词元。
- [BOS](序列开始):标记文本的起点,告知大语言模型一段内容的开始。
- [EOS](序列结束):位于文本的末尾,类似 <|endoftext|>,特别适用于连接多个不相关的文本。例如,在合并两篇不同的维基百科文章(或两本不同的图书)时,[EOS] 词元指示一篇文章的结束和下一篇文章的开始。
- [PAD](填充):当使用批次大小(batch size)大于 1的批量数据训练大语言模型时,数据中的文本长度可能不同。为了使所有文本具有相同的长度,较短的文本会通过添加 [PAD] 词元进行扩展或“填充”,以匹配批量数据中的最长文本的长度。
使用滑动窗口进行数据采样
我们可以通过滑动窗口的方式将数据转化为,输入-目标对。如下图,滑动窗口大小为4,步长为1。当然,窗口大小以及步长我们可以自由设置。

位置编码
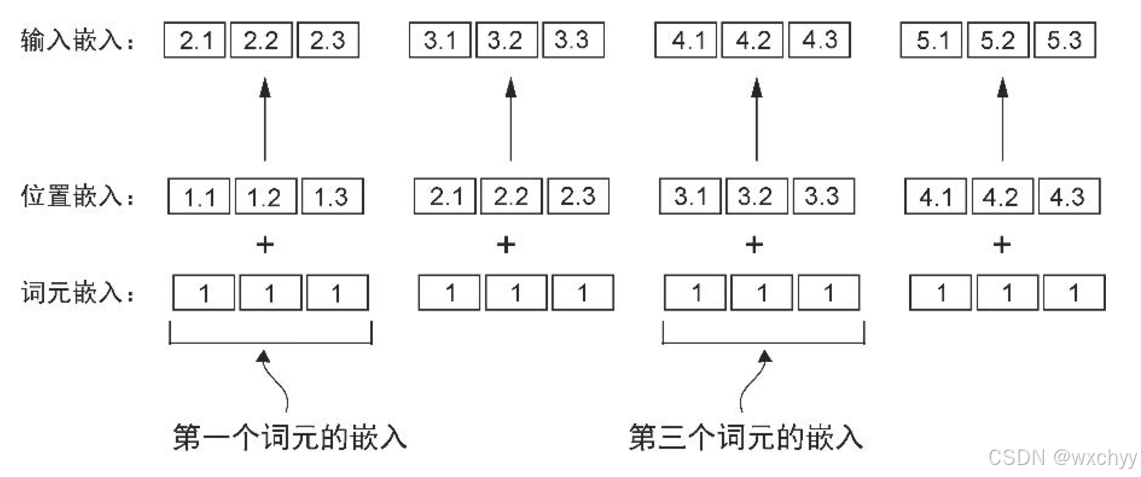
理论上,词元嵌入非常适合作为大语言模型的输入。然而,大语言模型存在一个小缺陷——它们的自注意力机制无法感知词元在序列中的位置或顺序。嵌入层的工作机制是,无论词元 ID 在输入序列中的位置如何,相同的词元 ID 始终被映射到相同的向量表示。
绝对位置嵌入
绝对位置嵌入(absolute positional embedding)直接与序列中的特定位置相关联。对于输入序列的每个位置,该方法都会向对应词元的嵌入向量中添加一个独特的位置嵌入,以明确指示其在序列中的确切位置。例如,序列中的第一个词元会有一个特定的位置嵌入,第二个词元则会有另一个不同的位置嵌入,以此类推。
相对位置嵌入
相对位置嵌入(relative positional embedding)关注的是词元之间的相对位置或距离,而非它们的绝对位置。这意味着模型学习的是词元之间的“距离”关系,而不是它们在序列中的“具体位置”。这种方法使得模型能够更好地适应不同长度(包括在训练过程中从未见过的长度)的序列。
编码注意力机制
这一块的核心在笔者的Transformer已经详细介绍过了,如果有不懂的地方,可以参考之前的博客,这里博主给出简单的代码实现。本篇的大模型只有Transformer解码器部分。
import torch
import torch.nn as nn
class CausalAttention(nn.Module):
def __init__(self, d_in, d_out, context_length, dropout, qkv_bias=False):
super().__init__()
self.d_out = d_out
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
self.dropout = nn.Dropout(dropout)
self.register_buffer(
'mask',
torch.triu(torch.ones(context_length, context_length), diagonal=1)
)
def forward(self, x):
b, num_tokens, d_in = x.shape
keys = self.W_key(x)
queries = self.W_query(x)
values = self.W_value(x)
attn_scores = queries @ keys.transpose(1, 2)
attn_scores.masked_fill_(
self.mask.bool()[:num_tokens, :num_tokens], -torch.inf
)
attn_weights = torch.softmax(
attn_scores / keys.shape[-1]**0.5, dim=-1
)
attn_weights = self.dropout(attn_weights)
context_vec = attn_weights @ values
return context_vec
class MultiHeadAttentionWrapper(nn.Module):
def __init__(self, d_in, d_out, context_length,
dropout, num_heads, qkv_bias=False):
super().__init__()
self.heads = nn.ModuleList(
[CausalAttention(
d_in, d_out, context_length, dropout, qkv_bias
)
for _ in range(num_heads)]
)
def forward(self, x):
return torch.cat([head(x) for head in self.heads], dim=-1)
```
# 训练
## 计算文本生成损失
在机器学习和深度学习中,交叉熵损失是一种常用的度量方式,用于衡量两个概率分布之间的差异——通常是标签(在这里是数据集中的词元)的真实分布和模型生成的预测分布(例如,由大语言模型生成的词元概率)之间的差异。在机器学习的背景下,特别是在像 PyTorch 这样的框架中,交叉熵函数可以对离散的结果进行度量,类似于给定模型生成的词元概率时目标词元的负平均对数概率。因此,在实践中,“交叉熵”和“负平均对数概率”这两个术语是相关的,且经常可以互换使用。

## 困惑度
`困惑度`通常与`交叉熵损失`一起用来评估模型在诸如语言建模等任务中的性能。它可以提供一种更易解释的方式来理解模型在预测序列中的下一个词元时的不确定性。困惑度可以衡量模型预测的概率分布与数据集中实际词汇分布的匹配程度。与损失类似,较低的困惑度表明模型的预测更接近实际分布。困惑度可以通过perplexity = torch.exp(loss) 计算得出,在先前计算的损失上应用该公式会得到 tensor(48725.8203)。困惑度通常被认为比原始损失值更易于解释,因为它表示模型在每一步中对于有效词汇量的不确定性。在给定的示例中,这意味着模型不确定在词汇表的 48 725 个词元中应该生成哪个来作为下一个词元。
# 控制随机性的解码策略
在自然语言生成任务中,控制随机性的解码策略对于平衡生成文本的多样性和质量至关重要。以下是几种常见的控制随机性的解码策略:
1 贪婪搜索(Greedy Search)
最简单的解码策略,每一步都选择概率最高的词元。这种方法计算效率高但容易产生重复和单调的输出。
实现步骤:
1. 在每个时间步计算所有候选词元的概率分布
2. 选择概率最高的词元作为当前输出
3. 将选定的词元作为下一个时间步的输入
2 集束搜索(Beam Search)
在贪婪搜索的基础上保持多个候选序列,平衡了计算成本和生成质量。
典型参数设置:
- 集束宽度(beam width):通常为5-10
- 长度惩罚(length penalty):调节生成文本长度的超参数
3 随机采样(Random Sampling)
直接从概率分布中采样,增加生成多样性。
**控制方法**:
- 温度参数(Temperature):控制采样分布的尖锐程度
- 高温(>1.0):平坦化分布,增加多样性
- 低温(<1.0):锐化分布,减少随机性
- Top-k采样:限制采样池大小为k个最高概率词元
- Top-p采样(核采样):从累计概率超过p的最小词元集合中采样
接下来我们将介绍随机采样中的两种关键技术(温度缩放和 Top-k 采样)
## 温度缩放(Temperature Scaling)
温度缩放,这是一种在下一个词元生成任务中添加概率选择过程的技术。具体实现方式是对softmax函数进行修改,温度大于 1 会导致词元概率更加均匀分布,而小于 1的温度将导致更加自信(更尖锐或更陡峭)的分布。:
```python
def softmax_with_temperature(logits, temperature):
scaled_logits = logits / temperature
return torch.softmax(scaled_logits, dim=0)
```
温度参数对采样行为的影响:
- **高温(T>1)**:使概率分布更平缓,增加随机性。例如当T=2时,原本[0.7,0.2,0.1]的概率会变成约[0.55,0.30,0.15]
- **低温(T<1)**:放大高概率token的权重,降低随机性。例如当T=0.5时,同样概率会变成约[0.85,0.11,0.04]
- **T=1**:保持原始概率分布不变
## Top-k 采样
我们现在已经实现了一种结合温度缩放的概率采样方法,以此来增加输出结果的多样性。我们发现,较高的温度值会导致下一个词元的概率分布更均匀,从而产生更多样化的输出,因为它降低了模型重复选择最可能词元的可能性。这种方法允许探索概率较低但可能更具创造性和趣味性的生成路径。然而,这种方法的一个缺点是,它有时会导致语法不正确或完全无意义的输出,比如 every effort moves you pizza。通过与概率采样和温度缩放相结合,Top-k 采样可以改善文本生成结果。
在Top-k 采样中,可以将采样的词元限制在前k个最可能的词元上,并通过掩码概率分数的方式来排除其他词元。
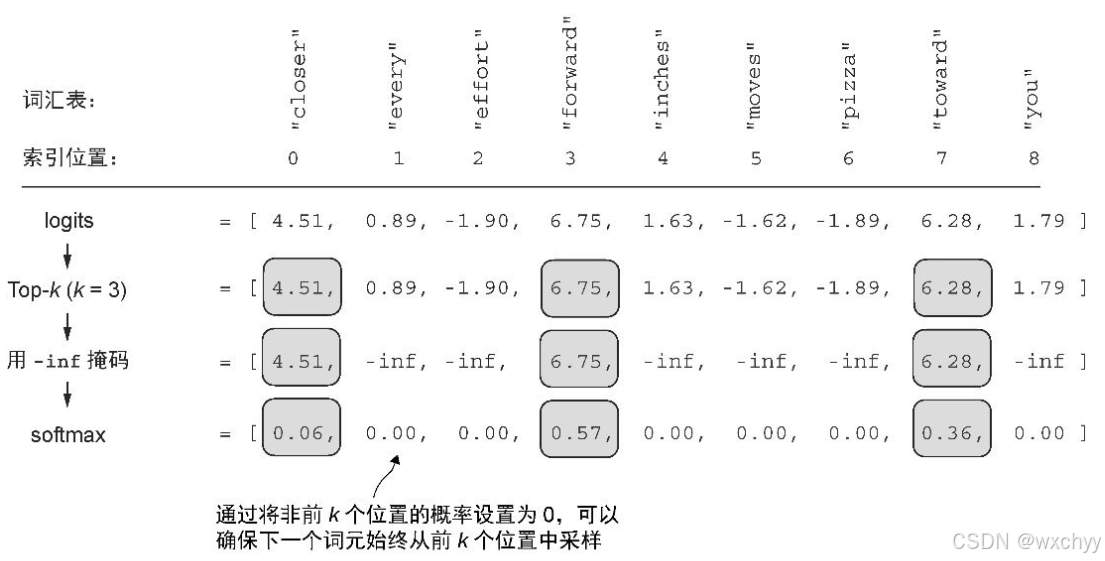
我们看一下简单的对比示例:
输入:"The cat sat on the"
- Top-1采样可能总是生成"mat"
- Top-5采样可能生成"mat"/"sofa"/"table"等
- Top-20采样可能偶尔生成不常见的如"windowsill"
# 评估方法
## ROUGE
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)是自然语言处理(NLP)中用于评估文本生成任务(如摘要、翻译、对话生成)的核心指标,通过衡量生成文本与参考文本的 n-gram 重叠度 和 语义覆盖度 来量化信息召回能力。
n-gram 召回率计算:ROUGE-N计算生成文本与参考文本中连续 N 个词(n-gram)的重叠比例:

最长公共子序列:ROUGE-L,不要求 n-gram 连续,只需顺序一致(如 “猫 吃 鱼” 与 “小猫 鱼 吃” 的 LCS 为 “猫 鱼”,召回率为 2/3),更贴近语义连贯性评估。
加权n-gram:ROUGE-W,对连续 n-gram 加权(如连续 3 个词的权重高于分散的 3 个词),突出文本流畅性。
跳过 n-gram:ROUGE-S,允许 n-gram 间有间隔(跳过部分词),适应更灵活的语义匹配。
最后介绍一下推理模型。
# 推理模型
2024年,大语言模型领域呈现出日益专业化的趋势。除了预训练(pre-training)和微调(fine-tuning),我们还见证了诸如 RAG(检索增强生成)、代码助手等专业应用程序的兴起。预计 2025年这一趋势将加速发展,并且更加注重领域和应用场景的特定优化(“专业化”),如下图所示。
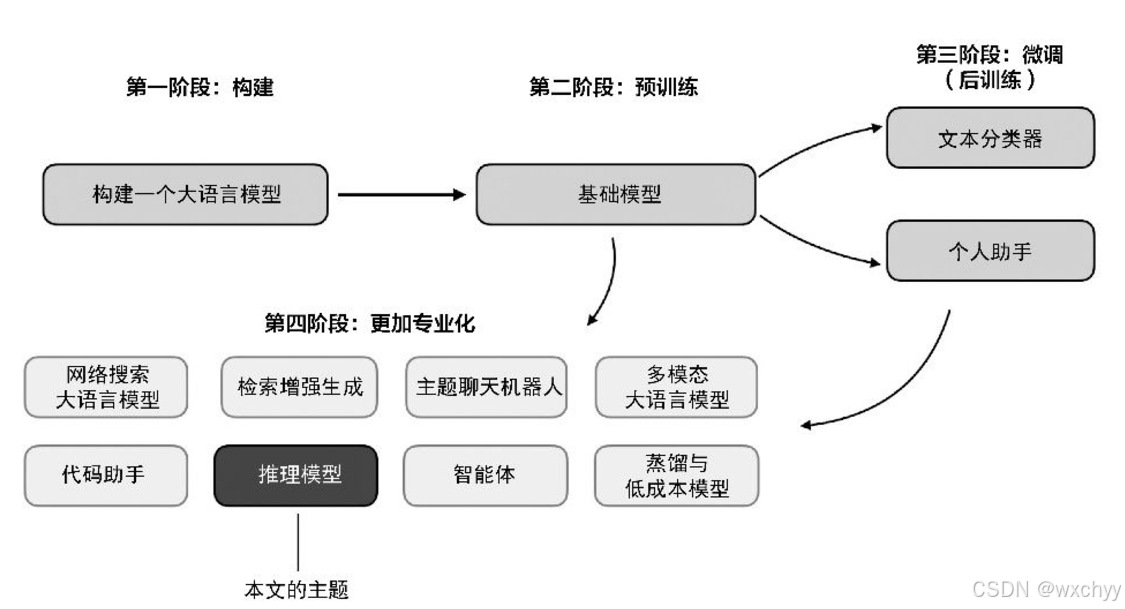
第一阶段至第三阶段是开发大语言模型的常见流程,第四阶段则专注于将大语言模型应用于特定的场景推理模型的开发是这些专业化方向之一。这意味着,我们需要进一步优化大语言模型,使其能够在需要多步推理的复杂任务(如解谜题、数学推导和解决复杂的编程问题)上表现得更好。
# 定义推理模型
推理可以定义为解答一些复杂,需要多步骤生成并包含中间过程的复杂问题的过程。
推理模型的中间推理步骤主要以两种方式呈现,一是直接体现在回答中,二是在内部进行多轮迭代。接下来在正式介绍推理模型的四种构建方法之前,我们先来看一下DeepSeek R1的训练过程。
# DeepSeek R1的训练过程
DeepSeek 并未发布单一的 R1 推理模型,而是推出了3个不同的变体:DeepSeek-R1-Zero、DeepSeek-R1 和 DeepSeek-R1-Distill。
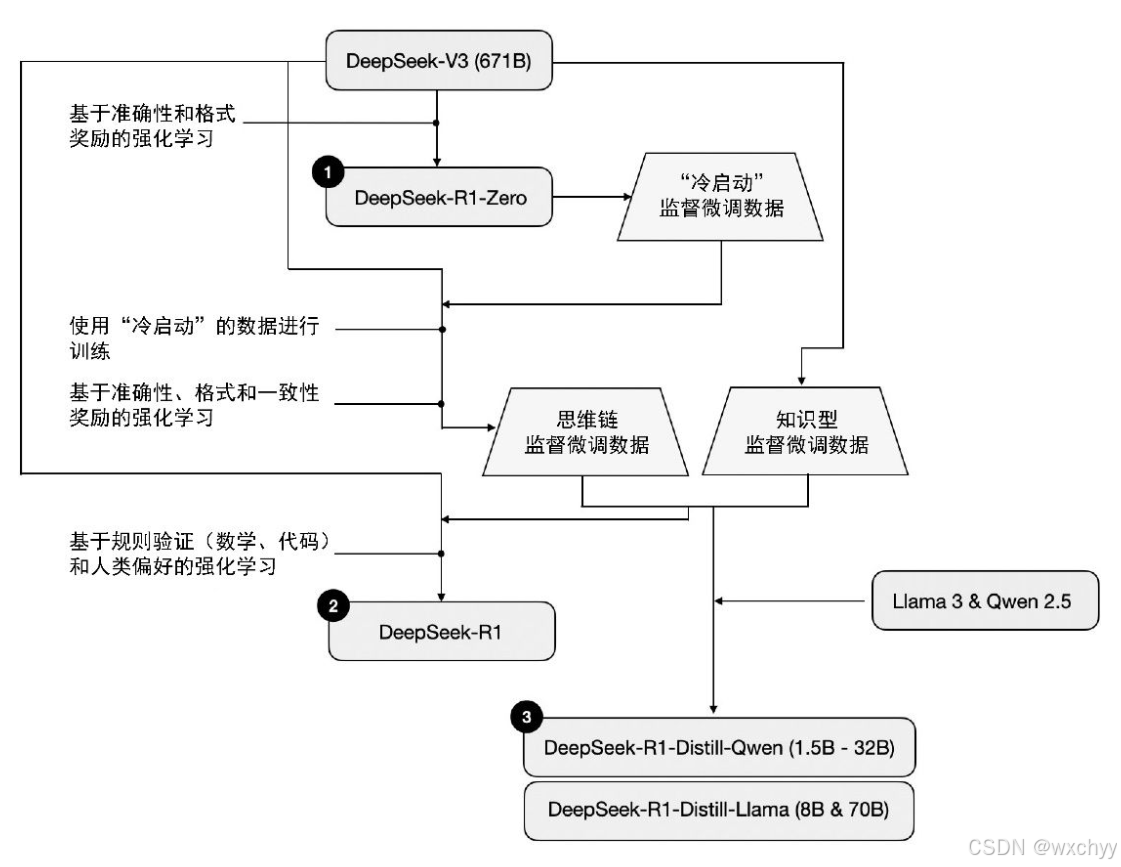
(1) DeepSeek-R1-Zero:该模型基于参数量为671B的Deepseek-V3预训练基础模型构建,采用强化学习(RL)进行训练,并使用了两种奖励机制。这种方法被称为“冷启动”训练,因为它没有采用SFT。
(2) DeepSeek-R1:这是 DeepSeek的主力推理模型,基于 DeepSeek-R1-Zero 构建。团队在 DeepSeek-R1-Zero的基础上增加了额外的监督微调训练阶段,并继续使用强化学习进行训练,进一步提升了R1-Zero 这一“冷启动”模型的能力。
(3)这是 DeepSeek的主力推理模型,基于 DeepSeek-R1-Zero 构建。团队在 DeepSeek-R1-Zero的基础上增加了额外的监督微调训练阶段,并继续使用强化学习进行训练,进一步提升了R1-Zero 这一“冷启动”模型的能力。
DeepSeek 团队使用 DeepSeek-R1-Zero 生成了他们所称的“冷启动”监督微调数据。“冷启动”是指这些数据是由 DeepSeek-R1-Zero 模型生成的,而该模型本身并未接受任何监督微调数据的训练。在获得这些“冷启动”监督微调数据后,DeepSeek 团队对模型进行了指令微调(instruction fine-tuning),随后又进行了一个强化学习阶段。这个强化学习阶段沿用了DeepSeek-R1-Zero中的奖励机制,包括准确性奖励(验证数学和代码问题的正确性)和格式奖励(确保输出符合预期格式)。
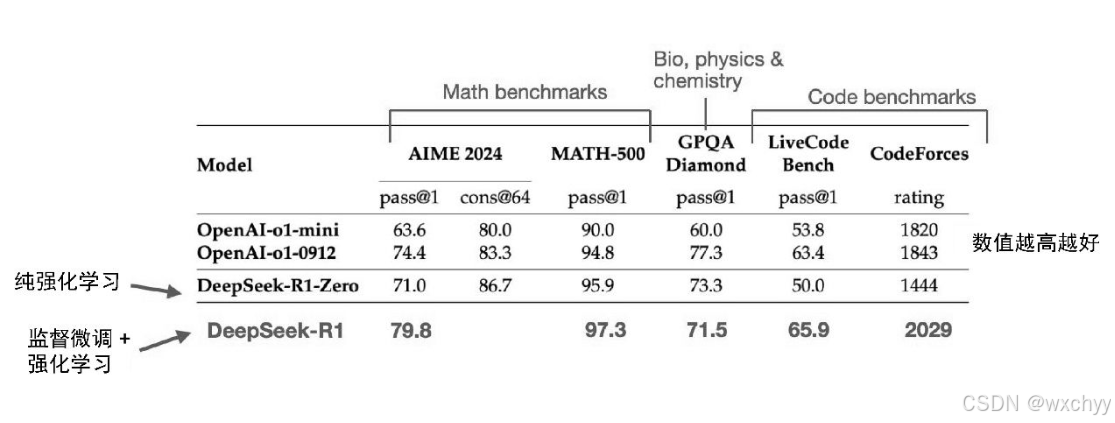
除此之外,他们还新增了一个一致性奖励,以避免模型在回答中混用多种语言的问题。在强化学习阶段之后,他们进行了新一轮的监督微调数据收集。在这一阶段中,他们使用最新的模型检查点(checkpoint)生成了60 万条思维链监督微调样本,同时还基于 DeepSeek-V3 基础模型生成了20 万条基于知识的监督微调样本。随后,这 80(20+60)万条监督微调数据被用于指令微调 DeepSeek-V3 基础模型,然后又进行最后一轮的强化学习训练。在这一阶段,他们继续使用基于规则的方法对数学和编程问题的答案给予准确性奖励,而对其他类型的问题引入了基于人类偏好标签的奖励机制。总体而言,这一过程与常规的基于人类反馈的强化学习非常相似,不同之处在于监督微调数据中包含了更多的思维链示例。此外,除了基于人类偏好的奖励,强化学习还引入了可验证的奖励机制。得益于额外的监督微调和强化学习阶段,最终生成的模型——DeepSeek-R1,在性能上相较于 DeepSeek-R1-Zero 有了显著提升,具体表现可以参考下图中的数据对比。
# 构建推理模型的核心方法
## 推理时间扩展
一种简单的推理时间扩展方法是提示词工程(prompt engineering),其中最典型的例子是思维链(chain-of-thought,CoT)提示。在思维链提示中,我们会在输入提示词(prompt)中加入类似“一步步思考”(think step by step)这样的短语,鼓励模型先生成中间推理步骤,而不是直接输出最终答案。
另一种推理时间扩展方法是使用投票和搜索算法。一个简单的例子是多数投票法,即让大语言模型生成多个答案,然后我们通过多数投票来选出最有可能的正确答案。同样,我们还可以使用束搜索(beam search)或其他搜索算法来生成更优质的答案。
## 纯强化学习
DeepSeek 团队发现推理能力作为一种行为可以通过纯强化学习自发涌现。DeepSeek-R1-Zero 完全通过强化学习进行训练,没有经历初始的监督微调阶段。在奖励机制方面,与通过人类偏好训练的奖励模型不同,DeepSeek 团队采用了两种奖励方式:准确性奖励和格式奖励。
- 准确性奖励:通过使用 LeetCode 编译器来验证代码答案的正确性,并通过一个确定性的系统来评估数学答案的准确性。
- 格式奖励:依赖大语言模型来确保回答遵循预期的格式,比如在<think>标签内放置推理步骤。虽然 R1-Zero 并不是表现最优秀的推理模型,但它通过生成中间的“思考”步骤展示了推理能力。

虽然 R1-Zero 并不是表现最优秀的推理模型,但它通过生成中间的“思考”步骤展示了推理能力。
## 监督微调+强化学习(SFT+RL)
在获得“冷启动”监督微调数据后,DeepSeek 团队对Deepseek-R1-Zero模型进行了指令微调(instruction fine-tuning),随后又进行了一个强化学习阶段。在强化学习阶段之后,他们进行了新一轮的监督微调数据收集。在这一阶段中,他们使用最新的模型检查点(checkpoint)生成了60 万条思维链监督微调样本,同时还基于 DeepSeek-V3 基础模型生成了20 万条基于知识的监督微调样本。随后,这 80(20+60)万条监督微调数据被用于指令微调 DeepSeek-V3基础模型,然后又进行最后一轮的强化学习训练。
## 蒸馏
DeepSeek的蒸馏方法是通过使用 DeepSeek-V3 和 DeepSeek-R1的中间检查点生成的监督微调数据集,来对较小的大语言模型(如参数量为 80 亿或 700 亿的 Llama 模型以及参数量为 5 亿~320 亿的 Qwen 2.5 模型)进行指令微调。值得注意的是,这个蒸馏过程中使用的监督微调数据集与训练 DeepSeek-R1 时使用的数据集完全相同。经过发现蒸馏后的模型同样具备推理能力。
# 写在文末
本期简单介绍了一些构建大语言模型的一些技术,不过由于技术过多,这里仅是简单列了一些,还有很多需要进行补充,像位置编码的方式就很有多种,子词分词方法还包括BBPE、WordPiece等等。
# 写在文末
 有疑问的友友,**欢迎在评论区交流**,笔者看到会**及时回复**。
><center>
><font color=Red>
>请大家一定一定要关注!!!<br>
>请大家一定一定要关注!!!<br>
>请大家一定一定要关注!!!<br>
>友友们,你们的支持是我持续更新的动力~<br>
---
<center>
<font color=Red> 创作不易,求关注,点赞,收藏,谢谢~ </font>


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











