







主要工作:将SwinTransformer在图像恢复中应用,降低参数量的同时取得很好的效果。
一、Introduction
1 Motivation
在图像超分辨率、图像去噪、压缩等图像修复(Image restoration)任务中,卷积神经网络目前仍然是主流。但卷积神经网络有以下缺陷:
(1)图像和卷积核之间的交互是与内容无关的;
(2)在局部处理的原则下,卷积对于长距离依赖建模是无效的。
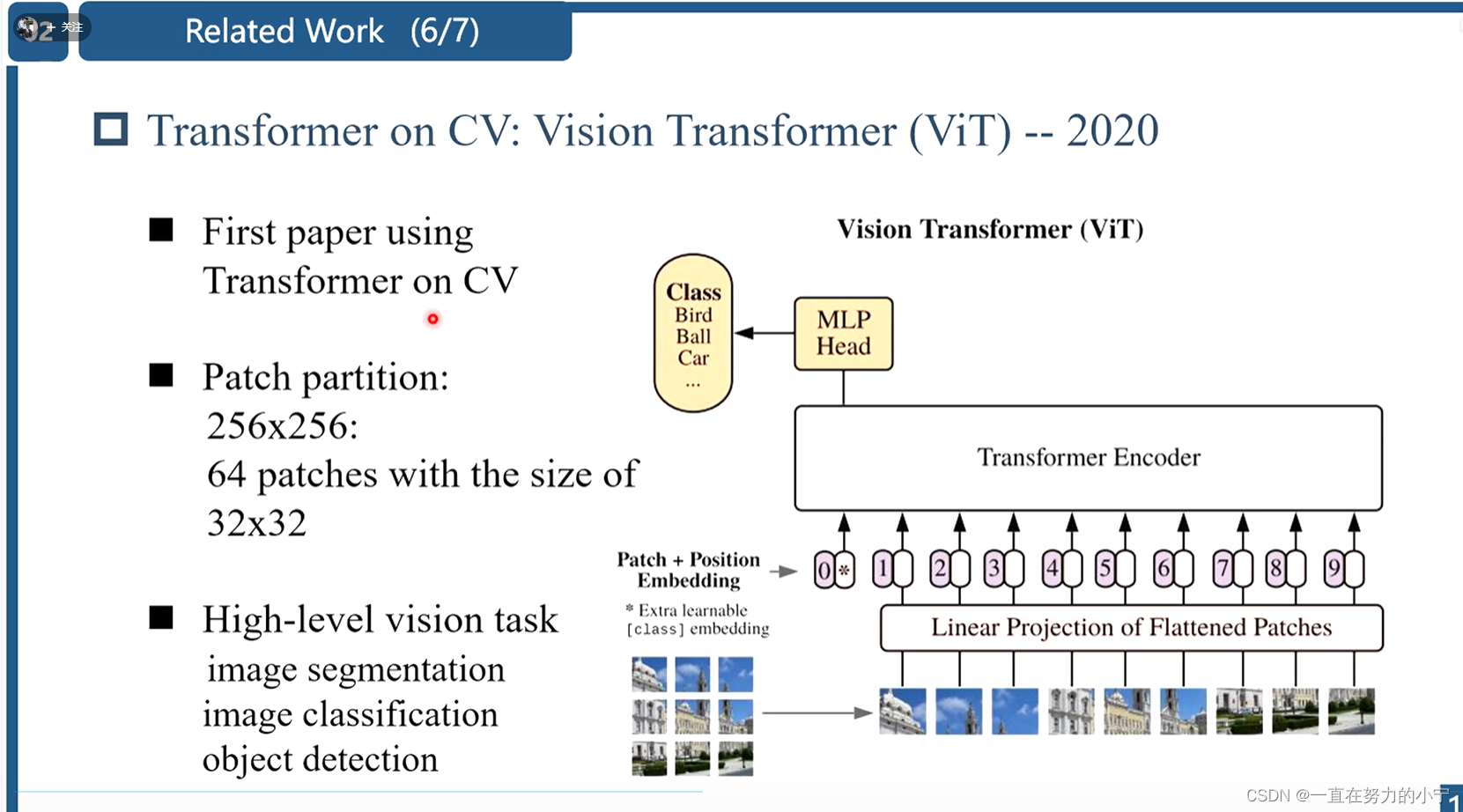
作为卷积的一个替代操作,Transformer设计了自注意力机制来捕捉全局信息,但视觉Transformer因为需要划分patch,因此具有以下两个缺点:
(1)边界像素不能利用patch之外的邻近像素进行图像恢复;
(2)恢复后的图像可能会在每个patch周围引入边界伪影,这个问题能够通过patch overlapping缓解,但会增加计算量。
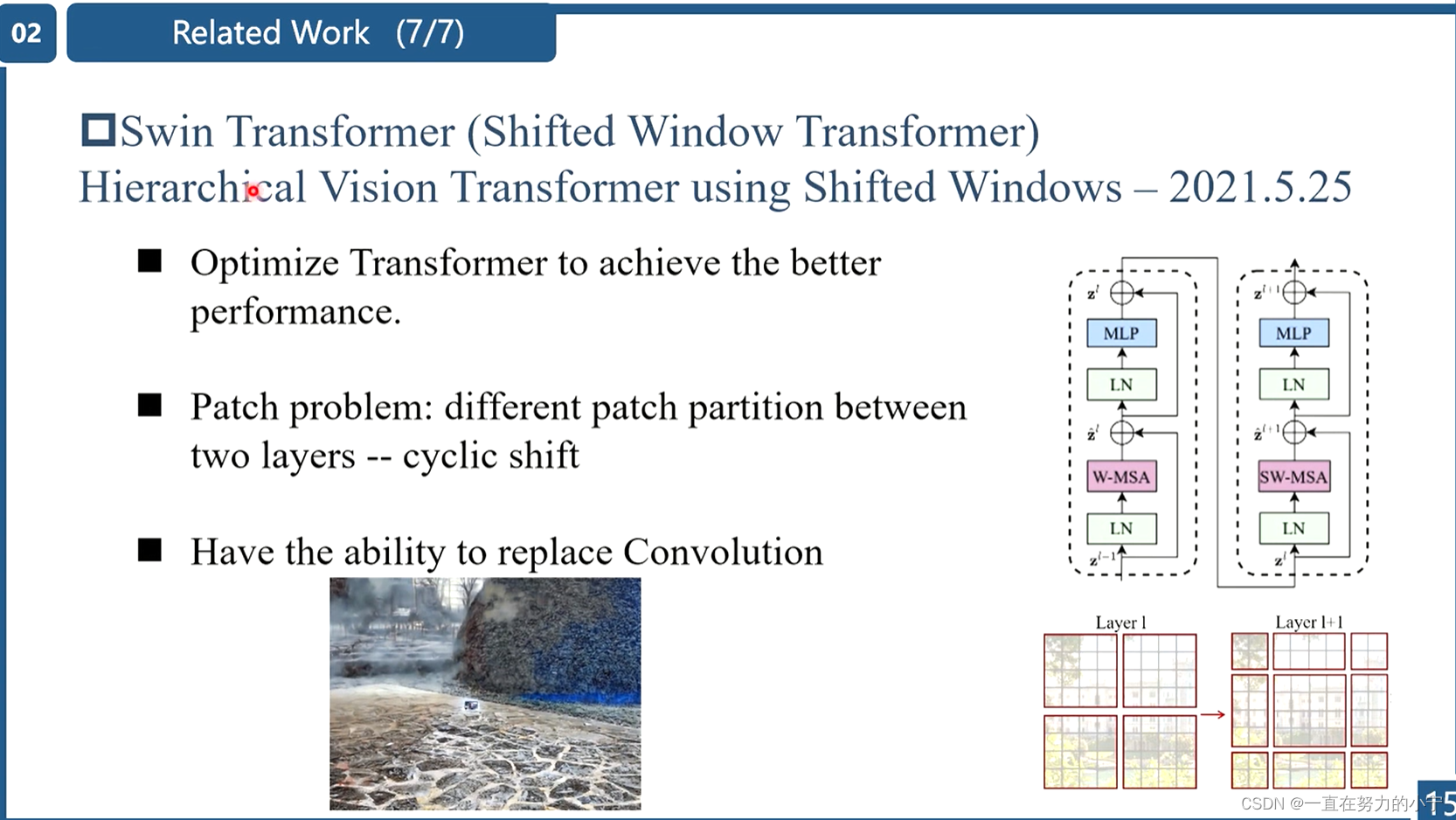
Swin Transformer结合了卷积和Transformer的优势,因此本文基于Swin Transformer提出了一种图像修复模型SwinIR。
2 Contribution
和现有的模型相比,SwinIR具有更少的参数,且取得了更好的效果。
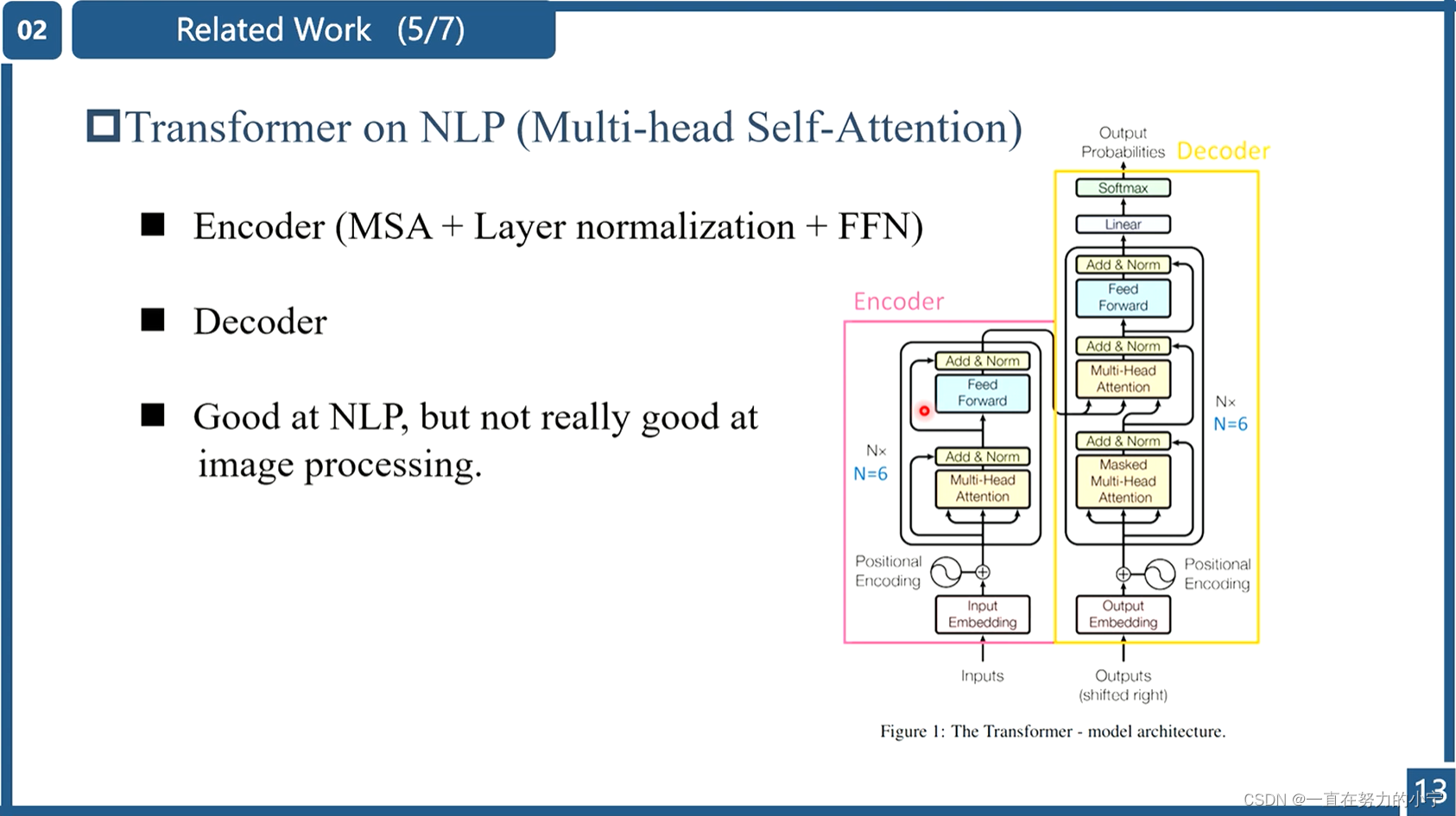
Recently, Swin Transformer [56] has shown great promise as it integrates the advantages of both CNN and Transformer. On the one hand, it has the advantage of CNN to process image with large size due to the local attention mechanism. On the other hand, it has the advantage of Transformer to model long-range dependency with the shifted window scheme.

二、原理分析
1 Network Architecture
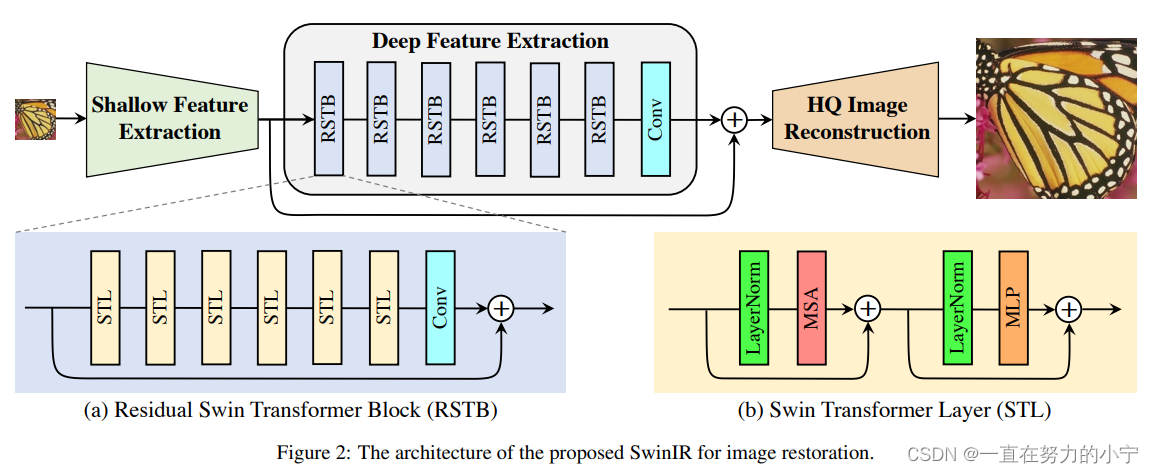
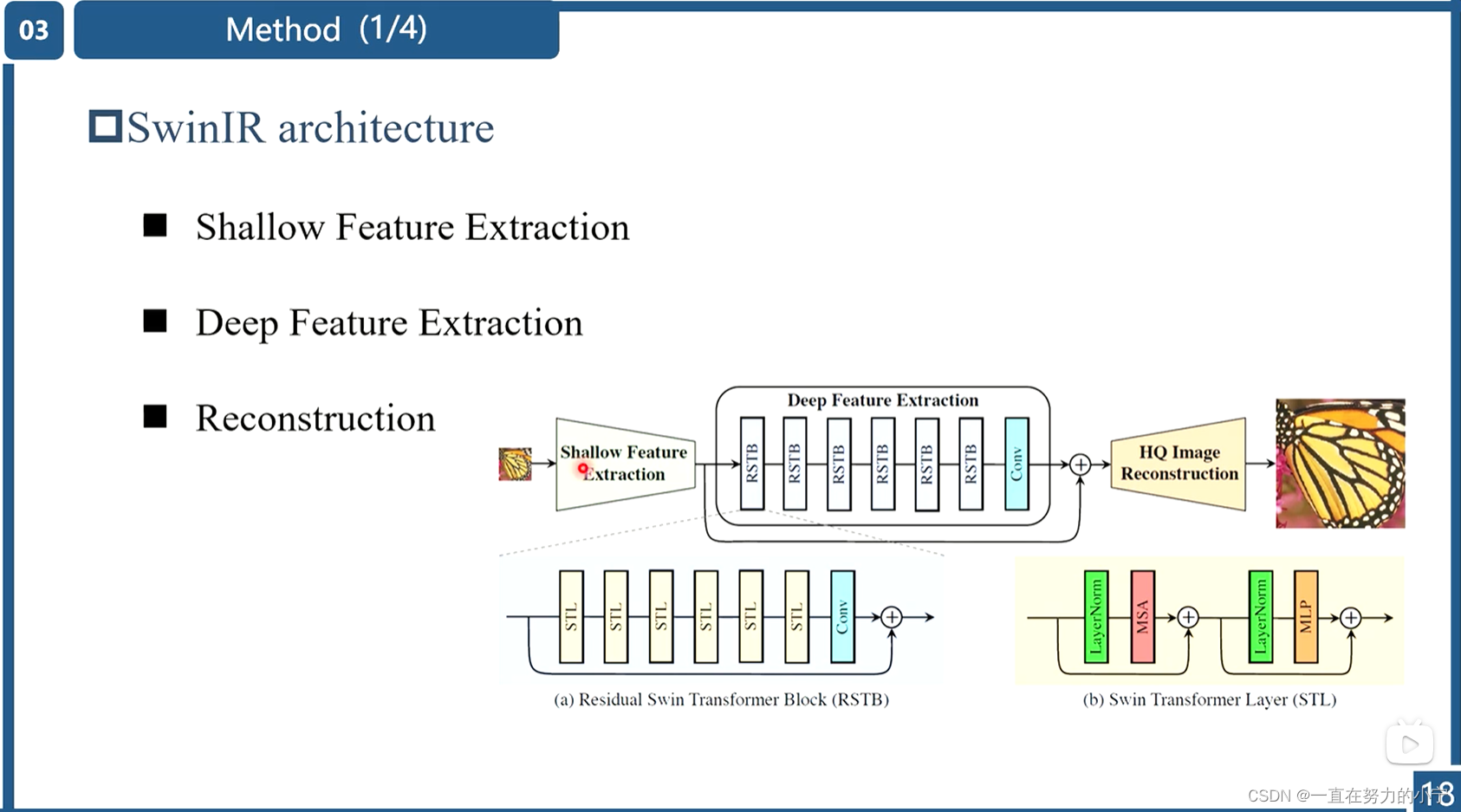
SwinIR的整体结构如下图所示,可以分为3个部分:shallow feature extraction、deep feature extraction、highquality (HQ) image reconstruction modules。对所有的复原任务采用相同的feature extraction modules,针对不同的任务采用不同的reconstruction modules。
浅层特征提取模块、深层特征提取模块和高质量图像重建模块。
其中浅层特征提取和高质量图像重建模块是基于CNN的,深层特征提取模块主要使用SwinTransformer(即若干个残差 SwInTransformer 块 (RSTB) 和卷积块构成)
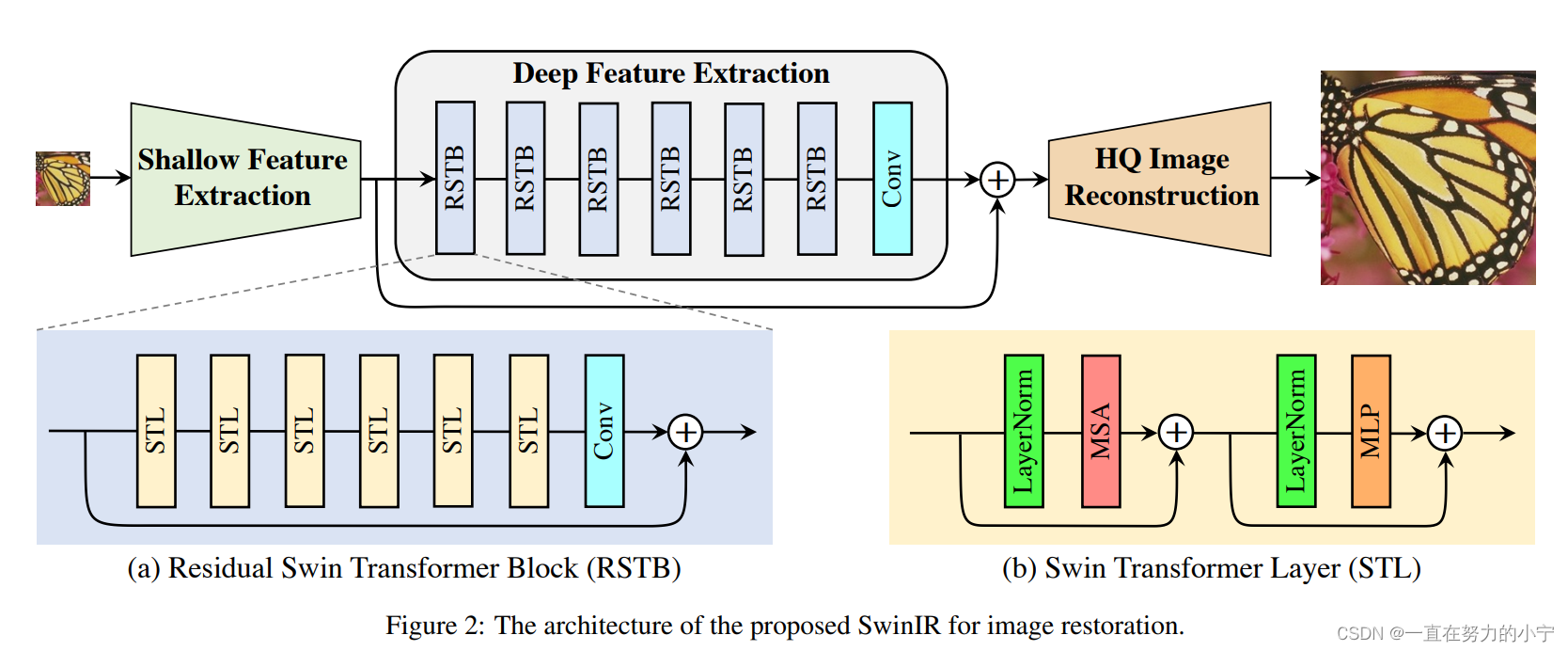
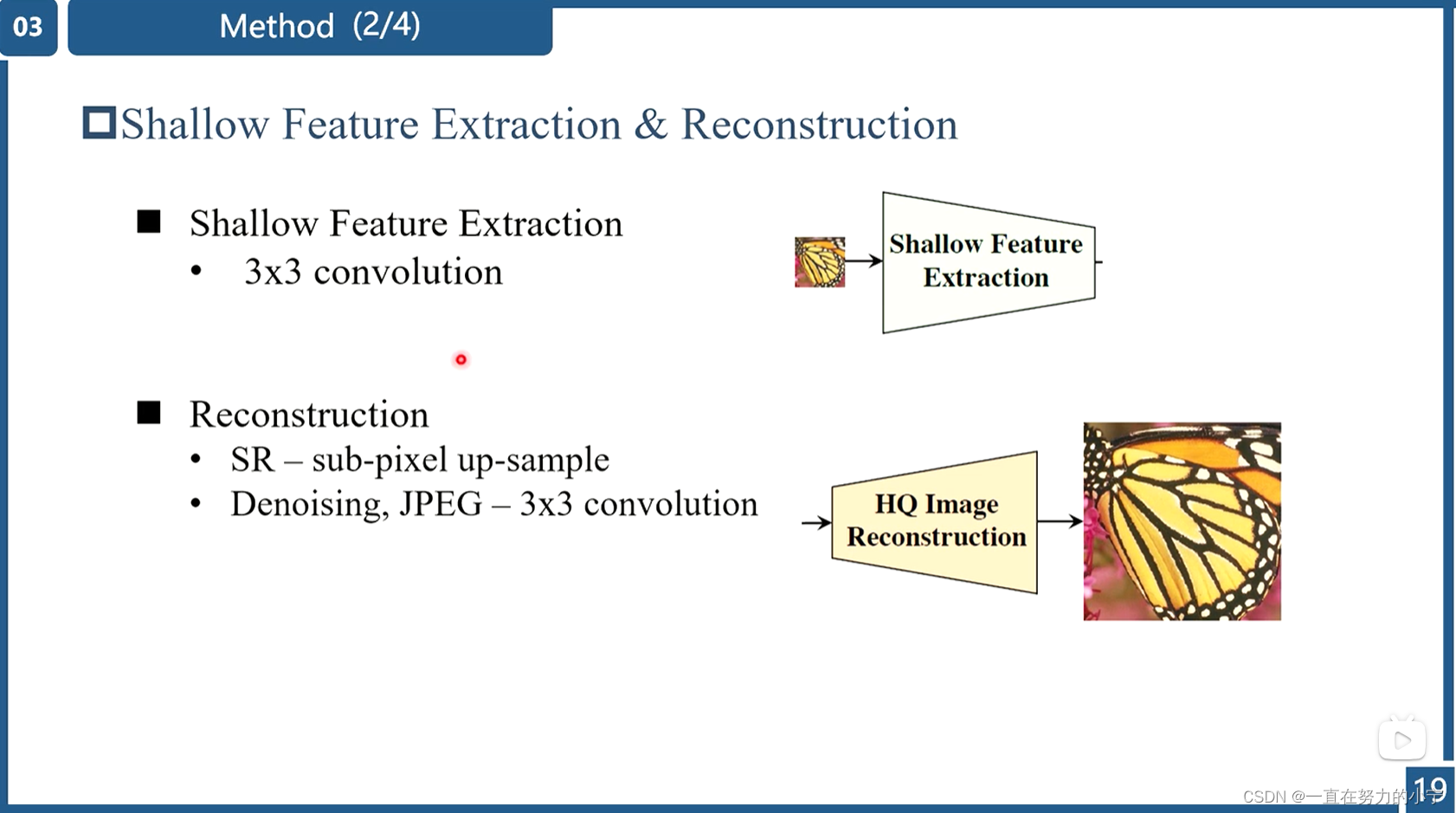
1)Shallow feature extraction
首先用一个3x3卷积HSF提取浅层特征F0

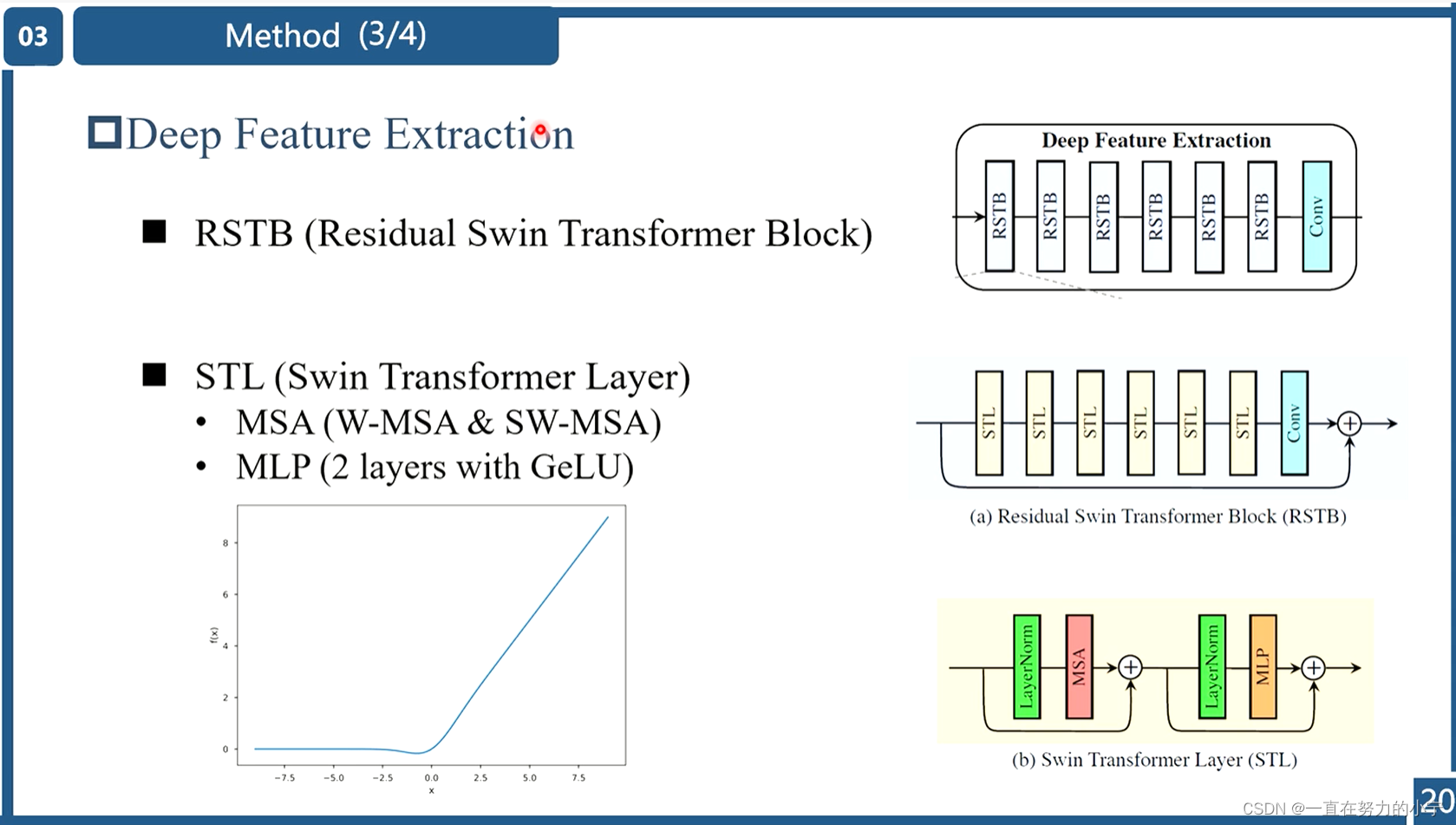
将提取到的浅层特征F0,使用深层特征提取模块HDF进一步提取特征。深层特征提取模块由K个residual Swin Transformer blocks(RSTB)和一个3×3卷积构成。

🔺浅层特征提取只使用一层卷积进行提取
2) deep feature extraction
每个RSTB的输出F1,F2,FK,以及输出的深层特征FDK如式(3)所示,式中HRSTBi表示第i个RSTB模块,HCONV表示最终的卷积层。卷积层能够将卷积的归纳偏置(inductive bias)引入基于Transformer的网络,为后续浅层、深层特征的融合奠定基础。
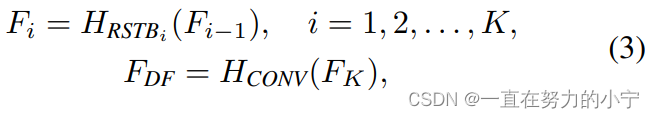
🔺深层特征提取模块由若干个残差 SwInTransformer 块 (RSTB) 和卷积块构成
(1) 首先将来自浅层特征提取模块的特征图分割成多个不重叠的 patch embeddings;
(2) 再通过多个串联的残差 SWin Transformer 块 (RSTB);
(3) 将多个不重叠的 patch embeddings 重新组合成与输入特征图分辨率一样;
(4) 最后通过一个卷积层 (1 层或3 层卷积) 输出;
🔺残差 SwInTransformer 块 (RSTB) 中的 STL 就是 SwIn Transformer Layer 的意思
(1) 首先通过一个归一化层 LayerNorm;
(2) 再通过多头自注意力 (Multi-head Self Attention) 模块;
(3) 在多头自注意力结尾引入残差;
(4) 再通过一个归一化层 LayerNorm;
(5) 最后通过一个多层感知机 MLP;
(6) 结尾同样引入残差。
3) image reconsruction modules
以图像超分辨率为例,通过融合浅层特征F0和深层特征FDK来重建高质量图片IRHQ,式中HREC为重建模块。
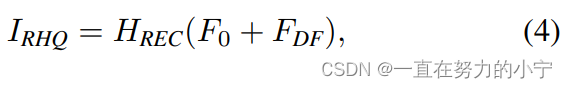
浅层特征F0主要包含低频信息,而深层特征则专注于恢复丢失的高频信息。SwinIR采用一个长距离连接,将低频信息直接传输给重建模块,可以帮助深度特征提取模块专注于高频信息,稳定训练。在图像超分辨率任务中,通过sub-pixel convolution layer将特征上采样,实现重建。在其他任务中,则是采用一个带有残差的卷积操作,如公式(5)所示。
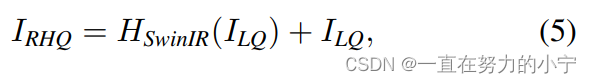
🔺图像重建模块其实就是卷积+上采样的组合,在这块论文提出 4 种结构。(注:这是一个容易改进的地方)
(1) 经典超分 (卷积 + pixelshuffle 上采样 + 卷积);
(2) 轻量超分 (卷积 + pixelshuffle 上采样);
(3) 真实图像超分 (卷积 + 卷积插值上采样 + 卷积插值上采样 + 卷积);
(4) 像去噪和 JPEG 压缩去伪影 (卷积 + 引入残差)。
4) loss function
图像超分辨率任务采用L1损失,通过优化SwinIR生成的高质量图像IRHQ及其对应的标签IHQ的来优化模型。
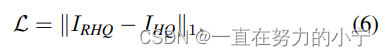
图像去噪任务和压缩任务采用Charbonnier loss,式中ɛ通常设置为10-3。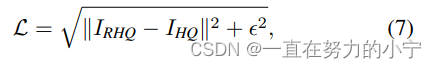
2 Residual Swin Transformer Block
如下图所示,residual Swin Transformer block (RSTB)由残差块、Swin Transformer layers (STL)、卷积层构成。卷积操作有利于增强平移不变性,残差连接则有利于模型融合不同层级的特征。
Swin Transformer layer (STL)取自论文:Swin transformer: Hierarchical vision transformer using shifted windows,和原版Transformer中multi-head self-attention的不同之处主要有局部注意力(local attention)和滑动窗口机制(shifted window mechanism)。首先,将大小为H×W×C的输入特征reshape为(HW/M2)×M2×C,即将其划分为HW/M2个M×M的local windows,然后对每个windows计算自注意力,具体如式(10)、(12)所示。第一个式子表示Query、Key、Value的计算过程,三个权重在不同的window间共享参数;第二个式子表示multi-head self-attention以及add and norm;第三个式子表示feed forward network以及add and norm。
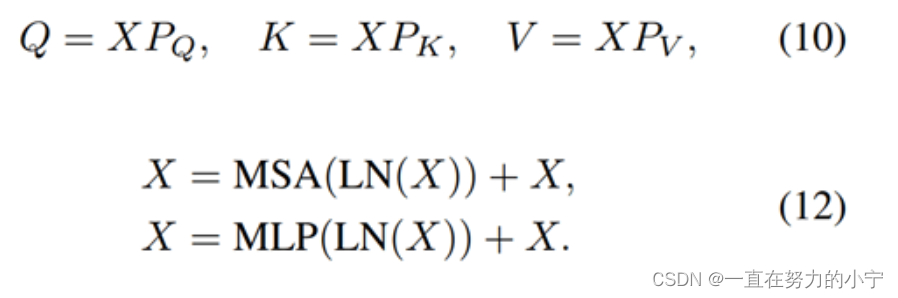
由于在local windows之间没有信息交互,因此本文交替使用常规窗口划分和滑动窗口划分来实现window间的信息交互。
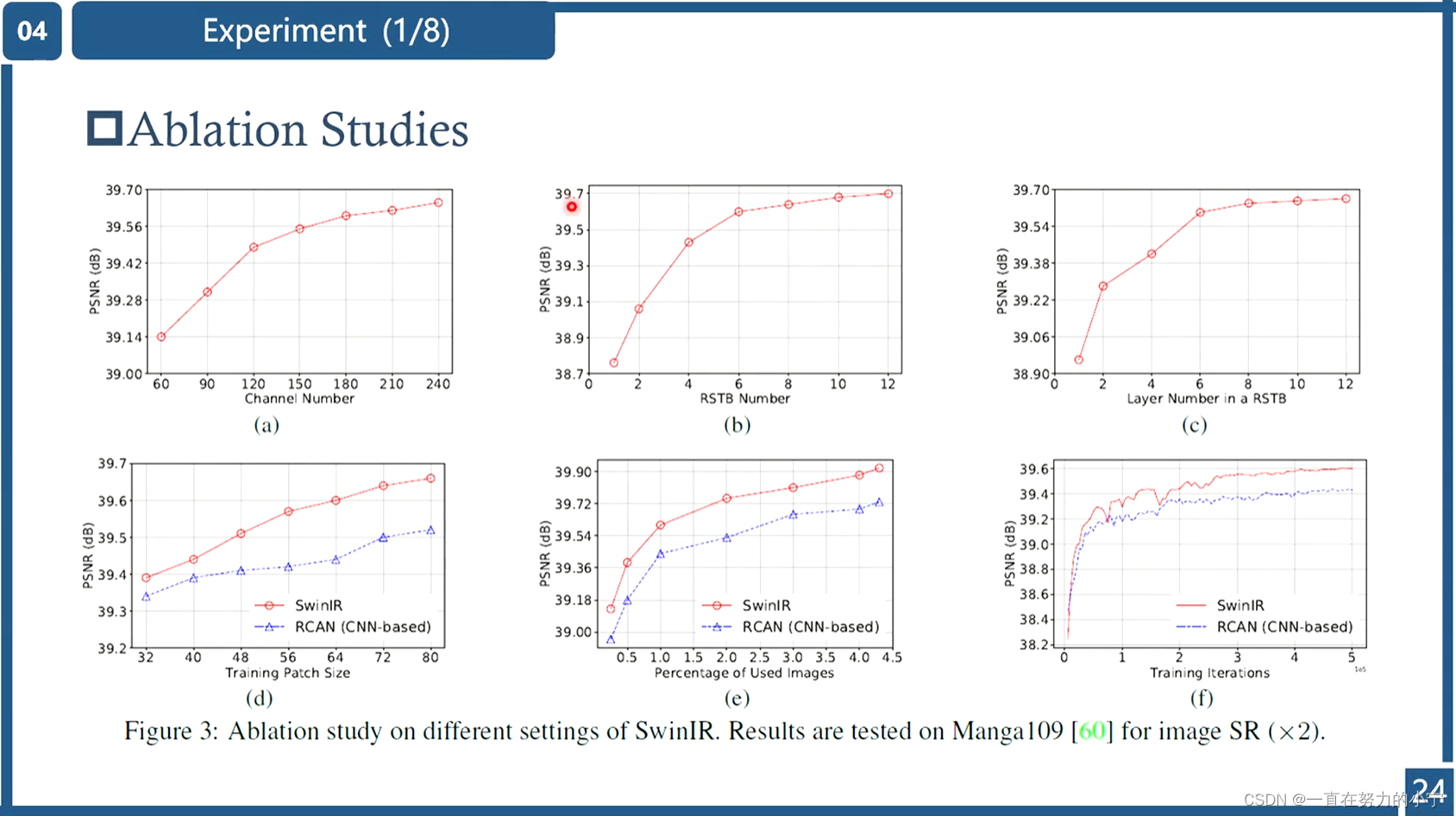
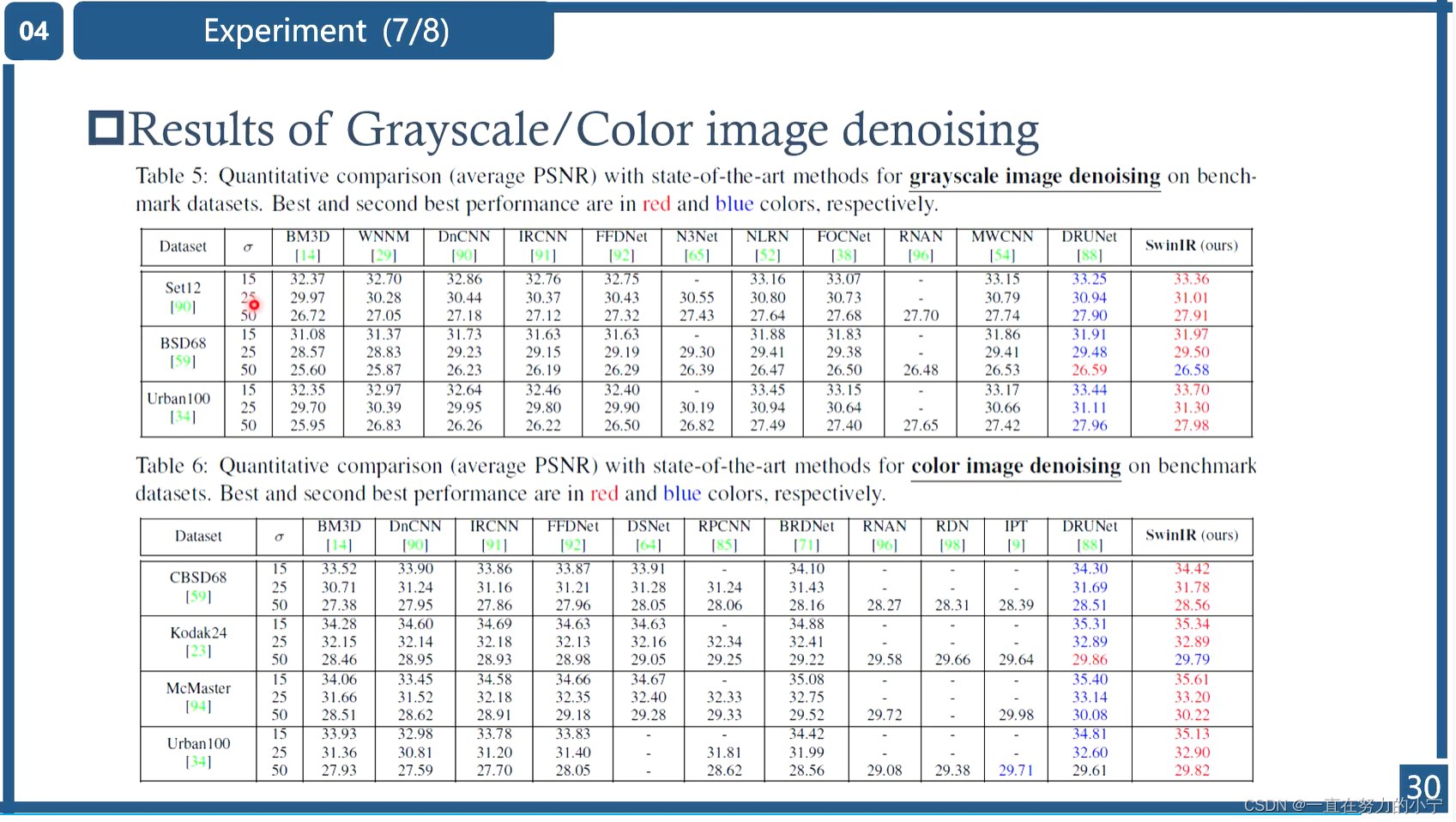
三、实验结果
部分实验结果如下所示(仅选取了图像超分辨率相关的实验结果),包括经典图像超分辨率(Classical image SR)、轻量级图像超分辨率(Lightweight image SR)、真实世界图像超分辨率(Real-world image SR)。
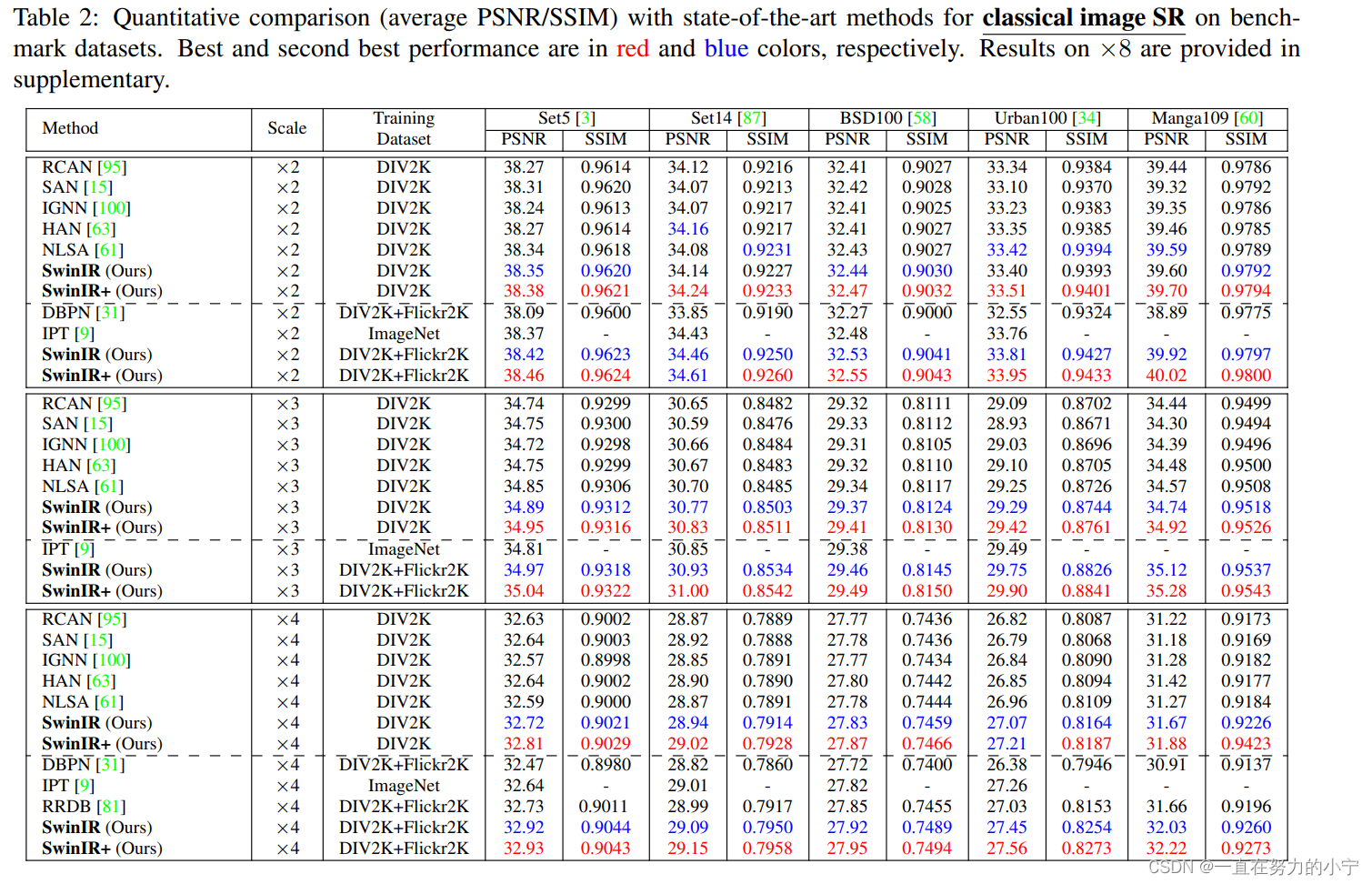
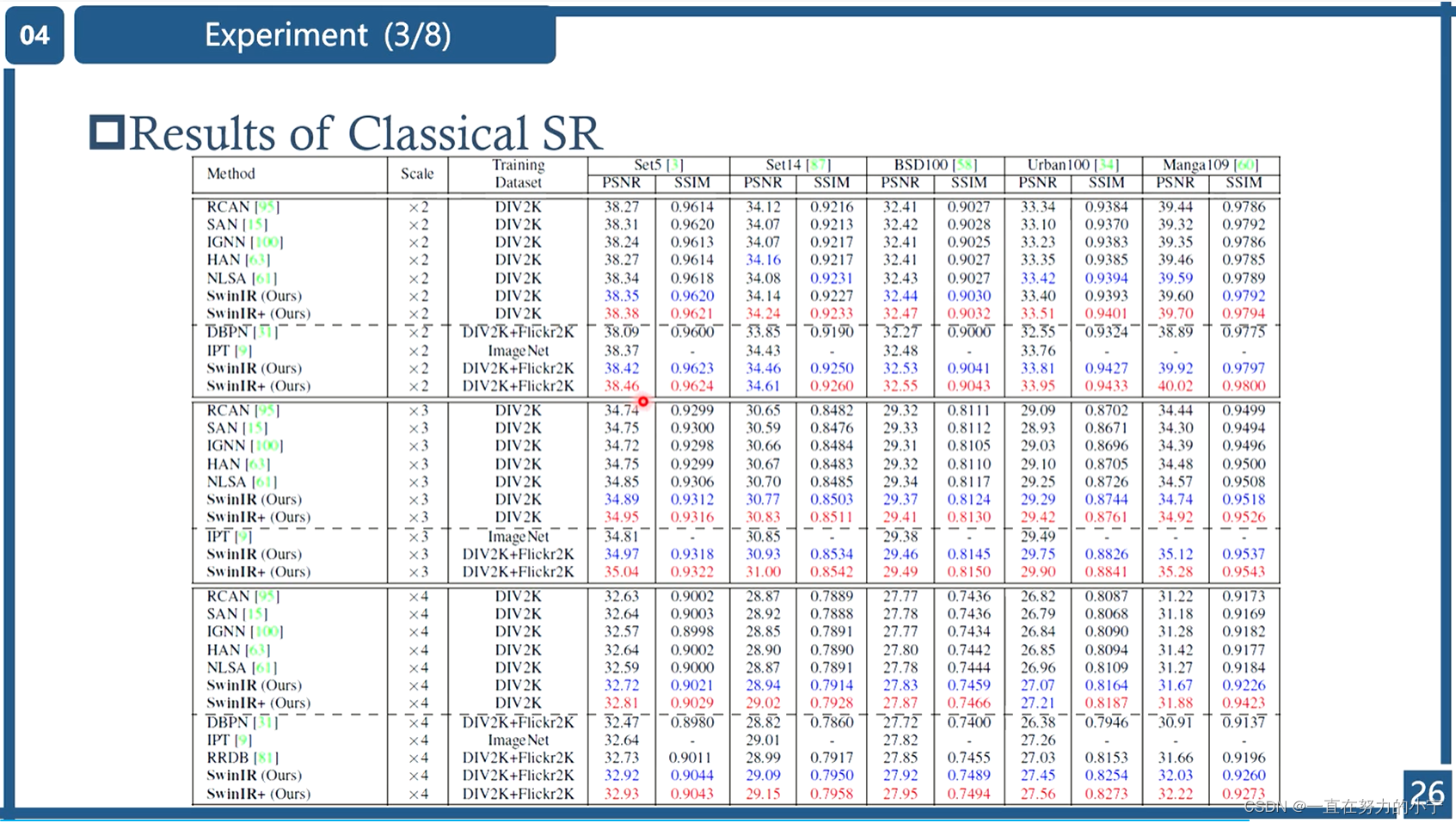
1 经典图像超分辨率(Classical image SR)
作者对比了基于卷积神经网络的模型(DBPN、RCAN、RRDB、SAN、IGNN、HAN、NLSA IPT)和最新的基于transformer的模型(IPT)。得益于局部窗口自注意力机制和卷积操作的归纳偏置,SwinIR的参数量减少至11.8M,明显少于IPT的115.5M,甚至少于部分基于卷积神经网络的模型;模型的训练难度也随之减少,不再需要ImageNet那样的大数据集来训练模型。仅使用DIV2K数据集训练时,SwinIR的精度就超过了卷积神经网络模型;再加上Flickr2K数据集后,精度就超越了使用ImageNet训练、115.5M参数的IPT模型。
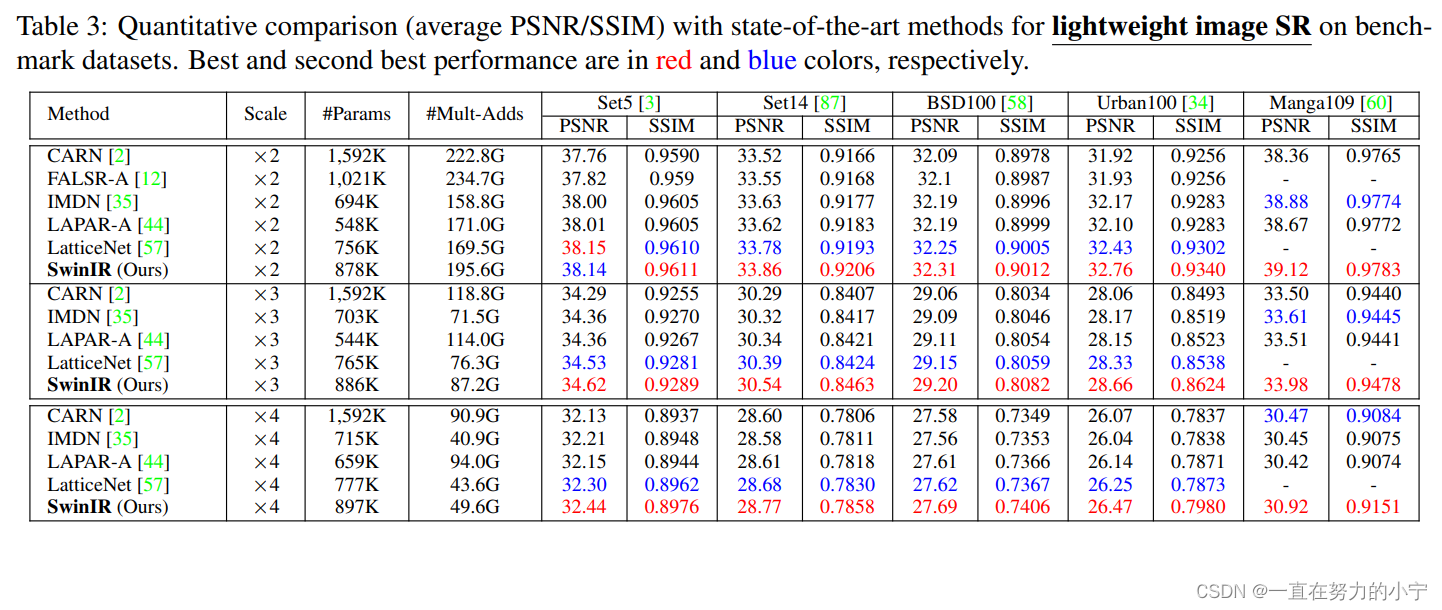
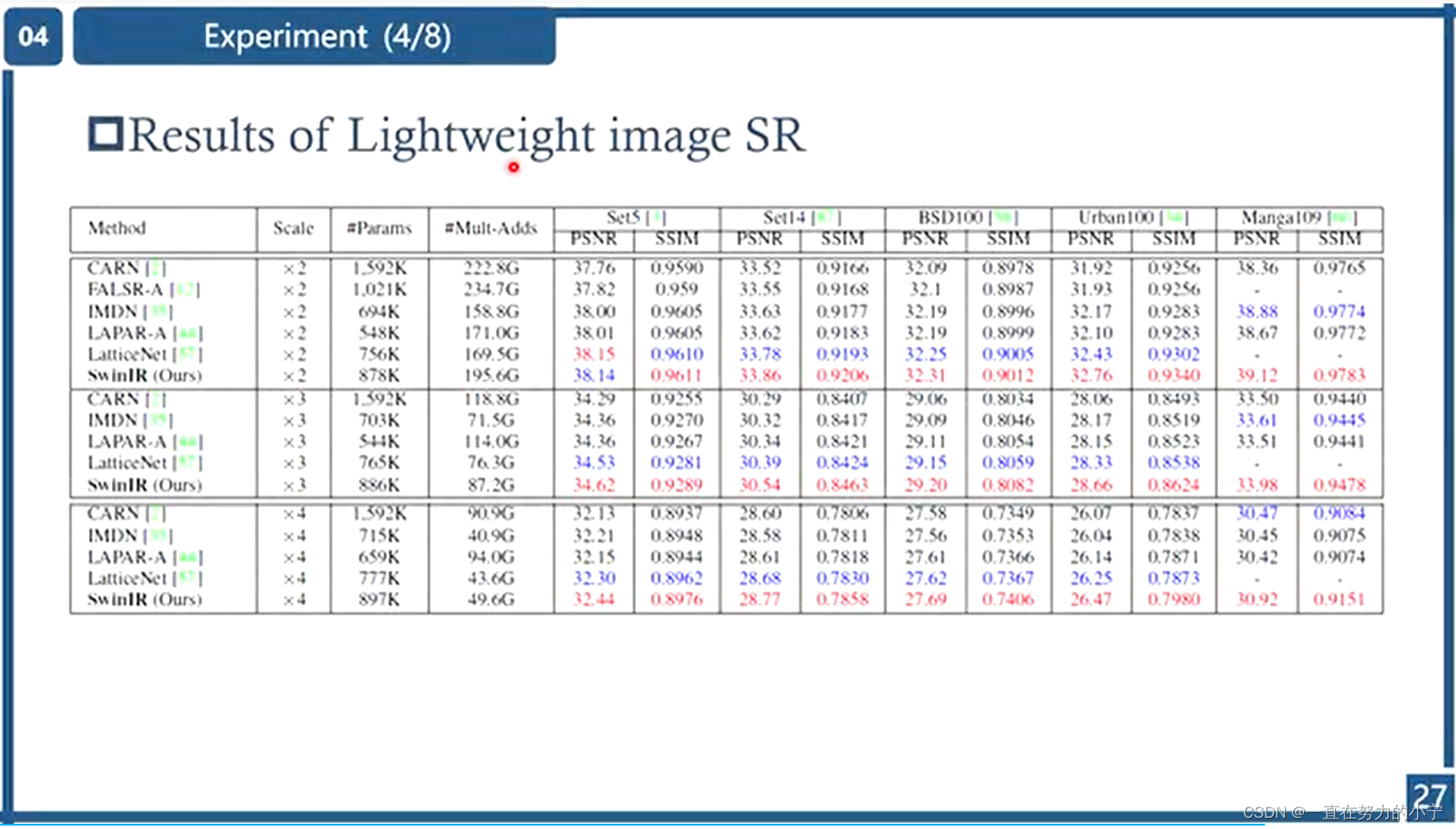
2 轻量级图像超分辨率(Lightweight image SR)
作者对比了几个轻量级的图像超分模型(CARN、FALSR-A、IMDN、LAPAR-A、LatticeNet),如下图所示,在相似的计算量和参数量的前提下,SwinIR超越了诸多轻量级超分模型,显然SwinIR更加高效。
3 Real-world image SR
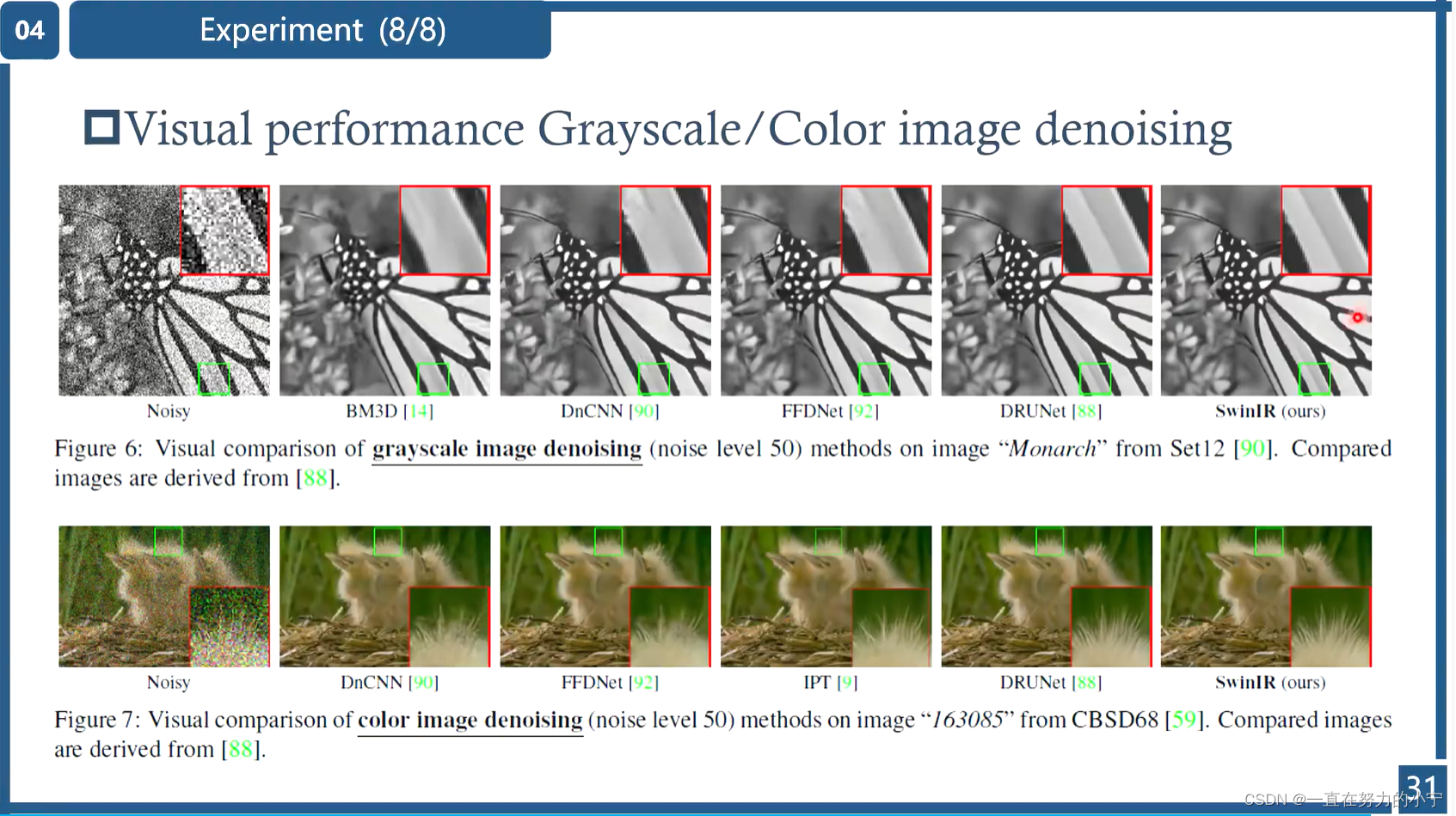
图像超分辨率的最终目的是应用于真实世界。由于真实世界图像超分任务没有GT图像,因此作者对比了几种真实世界图像超分模型的可视化结果(ESRGAN、RealSR、BSRGAN、Real-ESRGAN)。SwinIR能够产生锐度高的清晰图像。

四、小结
Transformer在视觉领域魔改至今,Swin Transformer当属其中最优、运用最多的变体。因此SwinIR进一步把Swin Transformer中的block搬到了图像处理任务里,模型则仍然遵循目前超分网络中head+body+tail的通用结构,改进相对比较小。
另一方面,Swin Transforme把卷积神经网络中常用的多尺度结构用在了基于Transforme的模型中,但图像超分辨率中一般不用多尺度结构,这或许就是SwinIR不如Swin Transforme效果好的原因。
五、链接及代码
Github链接 https://github.com/JingyunLiang/SwinIR?tab=readme-ov-file论文链接https://arxiv.org/pdf/2108.10257
https://github.com/JingyunLiang/SwinIR?tab=readme-ov-file论文链接https://arxiv.org/pdf/2108.10257
关于 SwinIR 中涉及 CNN 的部分代码非常简单,就不在此单独列出,这里主要注释一下其中有关 Swin Transformer 的实现代码。另外针对不构成主要网络结构的部分代码进行了删减,完整代码请移步:
(1) GitHub 链接:https://github.com/JingyunLiang/SwinIR
(2) CSDN 链接:https://download.csdn.net/download/Wenyuanbo/40284900
(3) 详尽注释代码:https://download.csdn.net/download/Wenyuanbo/40284085
SwinIR代码讲解高质量文章https://blog.csdn.net/Wenyuanbo/article/details/121264131
六、相关视频讲解及PPT

























 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









