






效果如图:
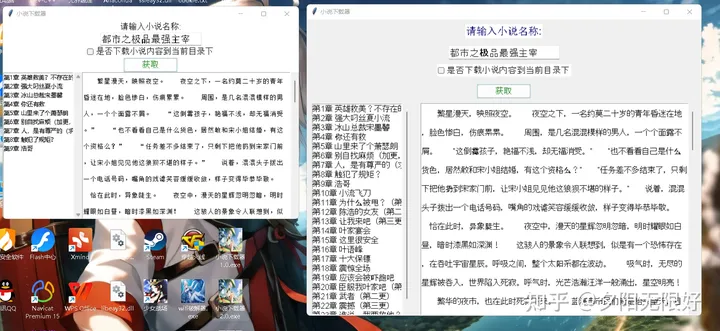
源码如下:
import tkinter as tk
from tkinter import ttk, messagebox
import threading
from selenium.webdriver.chrome.options import Options
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import os
from lxml import etree
class NovelDownloader:
def __init__(self, root):
self.root = root
self.root.title("小说下载器")
self.root.geometry("800x600")
self.setup_styles()
self.create_widgets()
self.chapters = {}
def setup_styles(self):
style = ttk.Style()
style.configure('TFrame', background='white')
style.configure('TLabel', background='white', font=('Arial', 13), foreground='navy')
style.configure('TButton', background='lightblue', font=('Arial', 13), foreground='green')
style.configure('TCheckbutton', background='white', font=('Arial', 13))
style.configure('TListbox', background='white', font=('Arial', 12))
style.configure('TText', background='white', font=('Arial', 13))
def create_widgets(self):
ttk.Label(self.root, text="请输入小说名称:", font=('Arial', 16)).pack(pady=10)
self.entry = ttk.Entry(self.root, font=('Arial', 14))
self.entry.pack(pady=5)
self.save_checkbox_var = tk.BooleanVar()
ttk.Checkbutton(self.root, text="是否下载小说内容到当前目录下", variable=self.save_checkbox_var, style="TCheckbutton").pack(pady=5)
ttk.Button(self.root, text="获取", command=self.search_novel, style="TButton").pack(pady=10)
self.create_listbox_frame()
self.create_chapter_text_frame()
def create_listbox_frame(self):
listbox_frame = ttk.Frame(self.root)
listbox_frame.pack(side=tk.LEFT, fill=tk.Y, padx=10)
scrollbar = ttk.Scrollbar(listbox_frame)
scrollbar.pack(side=tk.RIGHT, fill=tk.Y)
self.listbox = tk.Listbox(listbox_frame, selectmode=tk.SINGLE, yscrollcommand=scrollbar.set, font=('Arial', 12))
self.listbox.pack(side=tk.LEFT, fill=tk.BOTH, expand=True)
scrollbar.config(command=self.listbox.yview)
self.listbox.bind("<<ListboxSelect>>", self.show_chapter_content)
def create_chapter_text_frame(self):
chapter_text_frame = ttk.Frame(self.root)
chapter_text_frame.pack(side=tk.RIGHT, fill=tk.BOTH, expand=True, padx=10)
chapter_text_scrollbar = ttk.Scrollbar(chapter_text_frame)
chapter_text_scrollbar.pack(side=tk.RIGHT, fill=tk.Y)
self.chapter_text = tk.Text(chapter_text_frame, yscrollcommand=chapter_text_scrollbar.set, font=('Arial', 12))
self.chapter_text.config(spacing1=10, spacing2=20)
self.chapter_text.pack(side=tk.LEFT, fill=tk.BOTH, expand=True)
chapter_text_scrollbar.config(command=self.chapter_text.yview)
def search_novel(self):
keyword = self.entry.get()
if not keyword:
messagebox.showwarning("警告", "请输入小说名称")
return
threading.Thread(target=self.crawl_novel, args=(keyword,)).start()
def update_display(self):
self.listbox.delete(0, tk.END)
self.listbox.insert(tk.END, *self.chapters.keys())
def show_chapter_content(self, event):
selected_title = self.listbox.get(self.listbox.curselection())
self.chapter_text.delete("1.0", tk.END)
self.chapter_text.insert(tk.END, self.chapters[selected_title])
def crawl_novel(self, keyword):
options = Options()
options.headless = True
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
options.add_argument("--window-size=1920,1080")
options.add_argument("user-agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'")
driver = webdriver.Chrome(options=options)
try:
driver.get("https://www.bige3.cc/")
search_input = driver.find_element(By.XPATH, "/html/body/div[4]/div[1]/div[2]/form/input[1]")
search_input.send_keys(keyword)
search_input.send_keys(Keys.ENTER)
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, "/html/body/div[5]/div/div/div/div/div[2]/h4/a")))
elements = driver.find_elements(By.XPATH, "/html/body/div[5]/div/div/div/div/div[2]/h4/a")
if not elements:
messagebox.showinfo("提示", "没有找到相关小说")
return
for element in elements:
element.click()
driver.switch_to.window(driver.window_handles[-1])
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, "//*[@class='listmain']/dl/dd/a")))
chapter = driver.find_elements(By.XPATH, "//*[@class='listmain']/dl/dd/a")[0]
chapter.click()
while True:
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, "//*[@id='read']/div[5]/div[3]/h1")))
chapter_title = driver.find_element(By.XPATH, "//*[@id='read']/div[5]/div[3]/h1")
chapter_content = driver.find_element(By.XPATH, "//*[@id='chaptercontent']")
html = chapter_content.get_attribute("innerHTML")
tree = etree.HTML(html)
content = tree.xpath("string(.)")
chapter_title_text = chapter_title.text.replace("、", "")
content = content.replace("无弹窗,更新快,免费阅读!", "")
content = content.replace("请收藏本站:https://www.bige3.cc。笔趣阁手机版:https://m.bige3.cc", "")
content = content.replace("『点此报错』『加入书签』", "")
if self.save_checkbox_var.get():
book_dir = os.path.join(os.getcwd(), keyword)
if not os.path.exists(book_dir):
os.makedirs(book_dir)
chapter_path = os.path.join(book_dir, f"{chapter_title_text}.txt")
with open(chapter_path, "w", encoding="utf-8") as f:
f.write(content)
self.chapters[chapter_title_text] = content
self.update_display()
try:
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.XPATH, '//div[@class="Readpage pagedown"]/a[@id="pb_next"]')))
next_button = driver.find_element(By.XPATH, '//div[@class="Readpage pagedown"]/a[@id="pb_next"]')
next_button.click()
except:
break
driver.back()
except Exception as e:
messagebox.showinfo("提示", "运行完毕")
finally:
driver.close()
driver.quit()
if self.save_checkbox_var.get():
messagebox.showinfo("提示", "小说下载完成")
if __name__ == "__main__":
root = tk.Tk()
app = NovelDownloader(root)
root.mainloop()感谢朋友们阅读,下期再见!!!

















 763
763

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









