






论文地址:https://arxiv.org/abs/2211.10658
一、概要:
这篇文章介绍了一种名为EDGE(Editable Dance Generation)的方法,用于可编辑舞蹈生成。该方法利用基于Transformer的扩散模型和强大的音乐特征提取器Jukebox,能够生成逼真、物理可行的舞蹈,并与输入的音乐保持一致。EDGE具有强大的舞蹈编辑功能,包括关节条件约束和插值。文章还引入了一种新的物理可行性度量标准,并通过多个定量指标(包括物理可行性、节奏对齐和多样性)以及大规模用户研究对生成的舞蹈质量进行了广泛评估,证明了该方法相比先前的最先进方法的显著改进。
二、本文贡献:
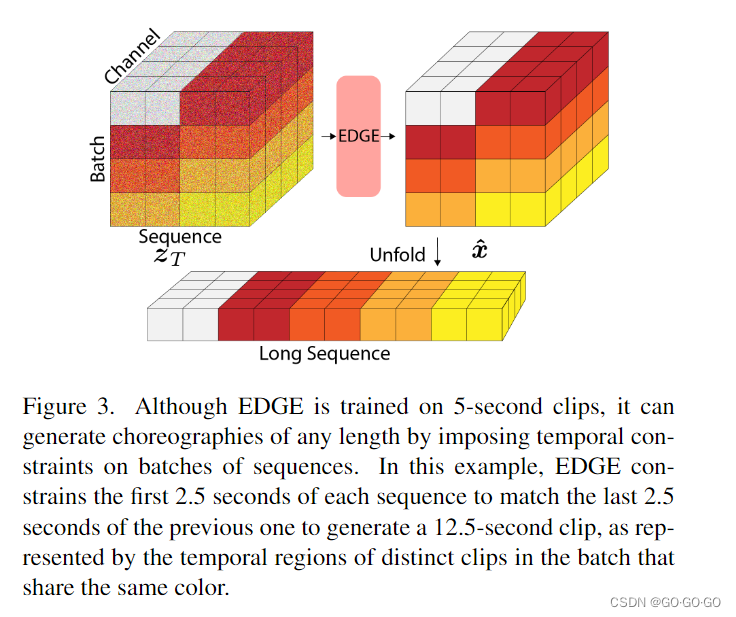
1、本文提出一种基于扩散的舞蹈生成方法,将最先进的性能与强大的编辑能力相结合,能够生成任意长的序列。(使用先进编辑能力强的 diffution 模型,对音乐进行间隔2.5s 长度 5s 进行裁剪,分别进行预测,最后通过对两个具有线性衰减权重的切片进行插值使其可以生成任意长度结果)
2、本文分析了之前工作中提出的指标,并表明它们不能准确地代表由大型用户研究报告的人工评价质量。
3、本文提出一种新方法,使用新的接触一致性损失来消除生成运动中的脚滑动物理不合理性,并引入物理脚接触评分,这是一个简单的基于加速度的新定量指标,用于评分生成的运动学运动的物理合理性,不需要明确的物理建模。(增加了 Physical Foot Contact score,PFC 物理可行性指标:通过计算舞蹈中的重心加速度和脚接触情况来评估舞蹈的真实性)
4、通过利用Jukebox[5]的音乐音频表示,改进了之前手工设计的音频特征提取策略,这是一个预训练的音乐生成模型,此前在音乐特定预测任务中表现出强大的性能。(使用了 jukebox 提取音乐特征)
三、相关工作:
1、人体运动生成,即自动生成逼真人体运动的问题,近年来,深度神经网络已经成为一种很有前途的人体运动生成替代方法。这些方法通常能够生成不同的运动,但往往无法捕捉支配人体运动的物理规律,或依赖于难以训练的强化学习解决方案。(其他网络只能生成较简单的动作,运动匹配,无法找到人体运动规律,或难以训练)
2、生成在风格上忠实于输入音乐的舞蹈这一独特的挑战性任务已经被许多研究人员解决。许多早期的方法遵循运动检索范式但往往会创建不现实的舞蹈编排,缺乏人类舞蹈的复杂性。后来的工作则是通过在大型数据集上进行训练,从零开始合成运动,并提出许多建模方法,包括对抗性学习,循环神经网络和transformer。尽管取得了令人印象深刻的性能,但许多这样的系统是复杂的,通常涉及许多层的条件反射和子网络。相比之下,所提出的方法包含了一个用简单目标训练的单一模型,但同时提供了强大的生成和编辑能力,而无需显著的手工设计。(其他网络在生成结果风格上简单,或者使用多个复杂的模型,本文方法只使用一个模型,同时结果比其他更好)
3、扩散模型是一类深度生成模型,通过反转预定的噪声过程来学习数据分布。在过去的几年中,扩散模型被证明是生成式建模的一个有前途的途径,在图像和视频生成任务中超过了最先进的水平,扩散模型也能够条件生成。最近,基于扩散的方法在生成以文本为条件的运动方面表现出了强大的性能。虽然文本到运动的任务和以音乐为条件的舞蹈生成的任务在高层次上有相似之处,但舞蹈生成任务面临更具有挑战性的计算扩展,并且由于其专业性,数据可用性要低得多。(diffution在文本生成动作领域结果很好,但是音乐生成舞蹈可用数据集较少)
四、方法
1、数据:将舞蹈表示为 24个关节点的SMPL 格式姿态数据,包含两种数据:平移 =(24*3),旋转 =(3,),本文对平移数据进行处理,每个关节使用6个自由度的旋转表示(24*3)->(24*6),同时还包括一个脚跟和脚趾的平移(4,),总数据维度=6自由度+脚跟平移+旋转(24*6 + 4 + 3 = 151),一段舞蹈为 帧数* 151 维数据。音乐为 jukebox 提取的特征 (帧数*4800)
(1)训练:n=数据长度=150=5s*30fps
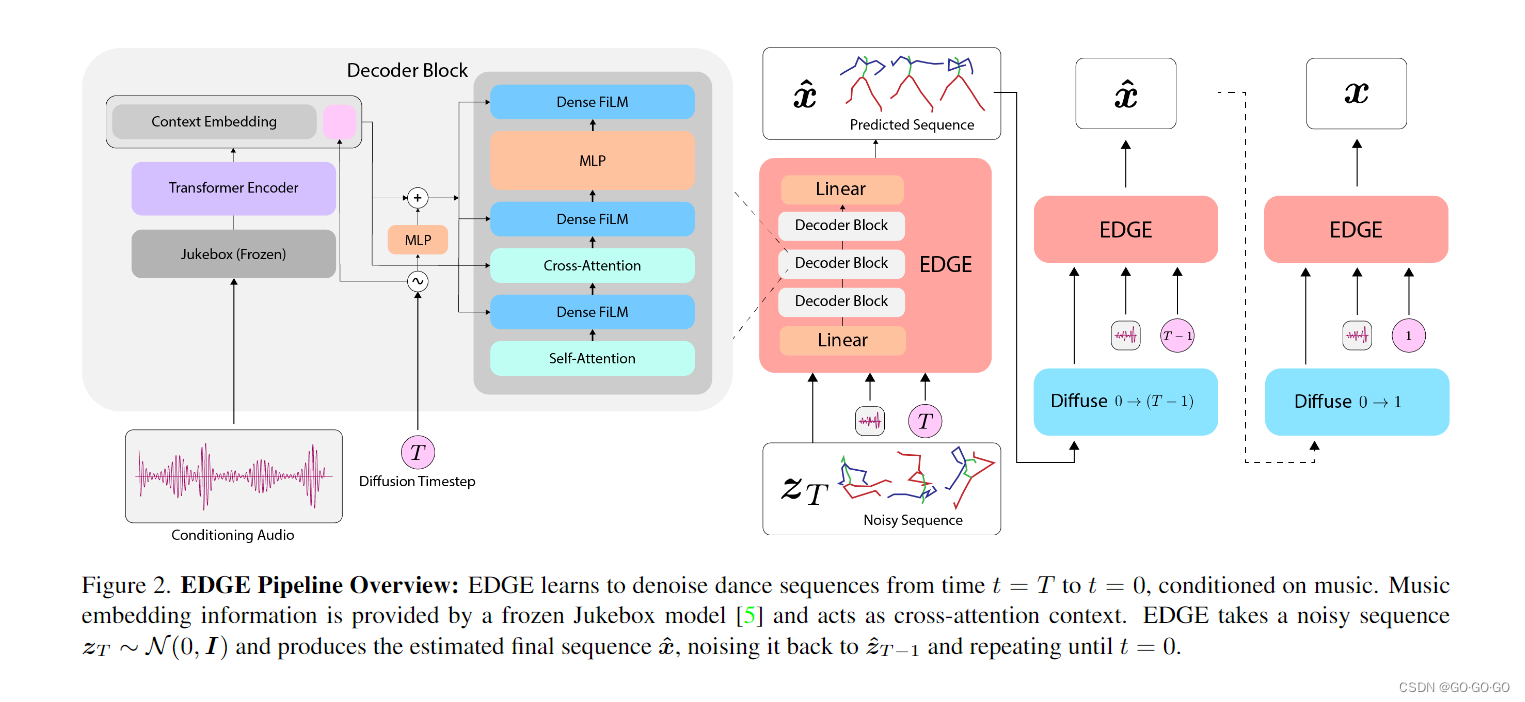
1)ZT = xt 马尔可夫公式生成的噪声(下图 DDPM xt 公式)ZT 由真实标签添加噪声得到噪声数据,首先经过 linear 进行特征提取到 512 维度 x_noisy (batch,n,512)
2)Conditioning Audio = 音乐特征(采样率*秒数,),经过 jukebox 提取特征(n,4800),经过 transformer 编码输出(batch,n,512)特征 cond_tokens
3)随机初始化时间步数 (batch,)经过 mlp 转换为隐藏表示 t_hidden
4)t = 时间步 + 音乐特征平均池化 (batch,512,1)
5)cond_tokens = 音乐特征与时间步特征拼接结果
6)x_noisy -> 自注意机制 -> film( x_noisy, t ) -> 多头注意力(x_noisy,cond_tokens )-> FILM(x_noisy, t ) -> MLP -> FILM(x_noisy, t ) - > linear 调整成最终输出维度(512 ->151),训练结果输出为去噪后的预测动作(上述操作对应图2左边)
(2)代价函数:
1)总代价函数 = simple + 运动速度损失 + 计算3d 点数据损失 + 脚部损失
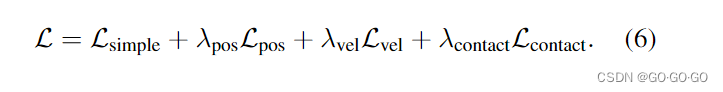
(3)推理:使用 DDIM 方法加速推理
1)x = 正态分布噪声 时间步t = (n,)维度取值为 最大步数 ~ -1 ,cond = 真实音乐数据
2)循环时间步 tx,每次使用 EDGE(x,conda,tx) 预测出 pre ,计算与当前时间步和下一个时间步相关的alpha值(alpha和alpha_next),使用 预测结果的噪声 和 随机噪声 及 预测结果 一起更新 x,送入下一个时间步继续推理,直至时间步为 -1,输出预测 x(对应图2 右侧流程)

五、实验:
1、数据:使用了AIST++,这是一个由1408个高质量的舞蹈动作与来自不同流派的音乐配对组成的数据集。我们重新使用原始数据集提供的训练/测试分割。所有的训练数据都被裁剪到5秒,30FPS长度。
2、训练:模型有49M个总参数,并在4块NVIDIA A100 gpu 上训练了16个小时,batch size 为512。
3、推理:当遇到超过 5 s 的音乐,对音乐进行间隔2.5s 长度 5s 进行裁剪,分别进行预测,最后通过对两个具有线性衰减权重的切片之间进行插值来强制重叠2.5秒的切片的一致性,这种方法足以生成平滑,一致的结果。
4、音乐特征提取:测试了 librosa 提取节拍和伴奏的特征、使用jukebox提取音乐特征并降采样30fps,两种特征提取方法
六、结果比较:
1、人工评估:147名人工评价者,
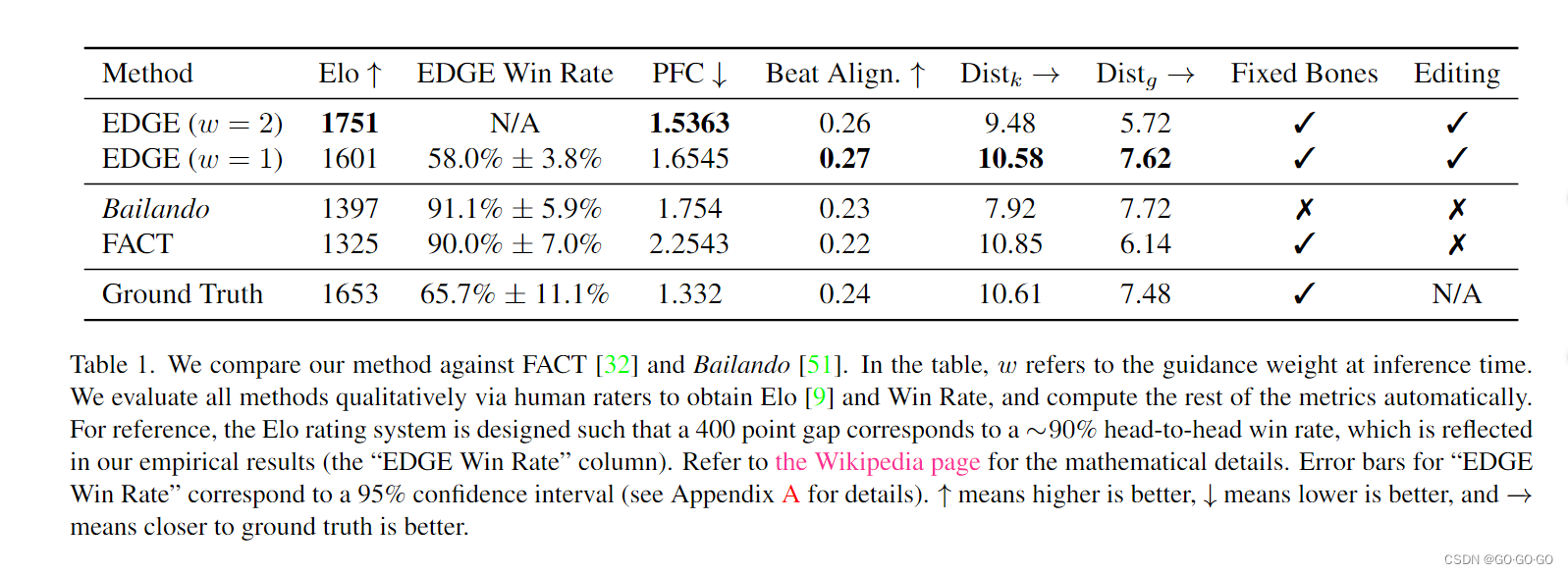
1、野外音乐评估
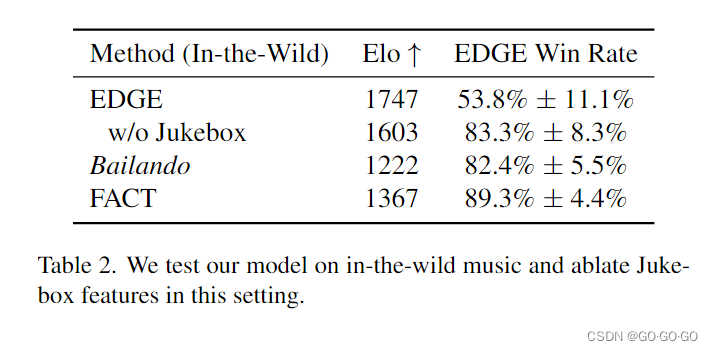
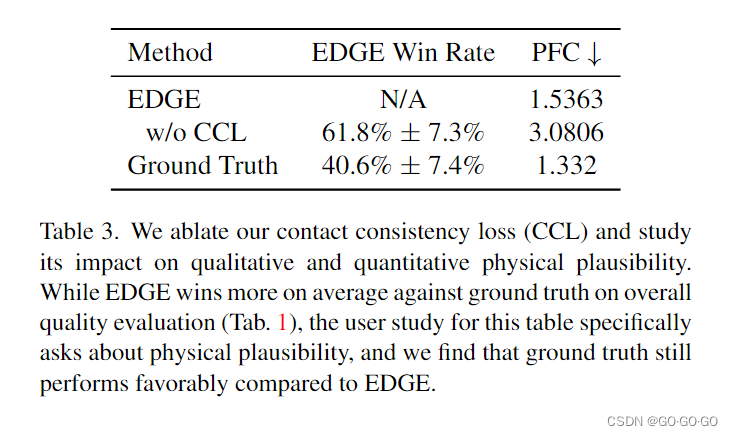
3、PFC 评估指标
七、结论
本文提出一种基于扩散的模型,可以生成以音乐为条件的逼真的长舞蹈序列。我们在多个自动化指标(包括我们提出的PFC)和一个大型用户研究上评估了我们的模型,发现它在aist++数据集上取得了最先进的结果,并很好地泛化到野外音乐输入。重要的是,证明了该模型具有强大的编辑功能,允许用户自由指定时间和联合约束。可编辑舞蹈生成的引入为未来的工作提供了多种有希望的途径。虽然所提出方法能够通过链接局部一致的较短剪辑来创建任意长的舞蹈序列,但它不能生成具有非常长期依赖关系的编排。未来的工作可能会探索非均匀采样模式的使用。
(本模型使用基于扩散模型的方式在aist++数据集上表现是最好的,对其他音乐结果也很好,可以允许用户自由指定时间和联合约束,缺点,不能生成长依赖的舞蹈,只能通过才裁剪然后拼接插值方式。

















 1432
1432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









