







论文资源:https://arxiv.org/abs/1603.06937
一,总结概述
本文使用全卷积网络解决人体姿态分析问题,截至2016年5月,在MPII姿态分析竞赛中暂列榜首,PCKh(误差小于一半头高的样本比例)达到89.4%。与排名第二的CPM(Convolutiona Pose Machine)1方法相比,思路更明晰,网络更简洁。该论文体现了从模块到网络再到完整网络的设计思想。
使用的初级模块称为Residual Module,得名于其中的旁路相加结构。
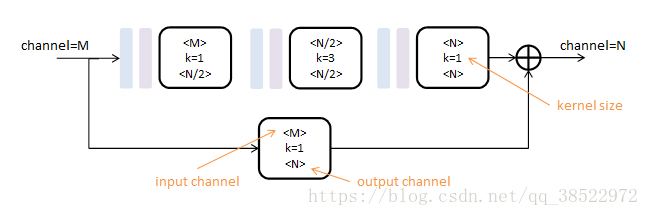
作用:Residual模块提取了较高层次的特征(卷积路),同时保留了原有层次的信息(跳级路)。不改变数据尺寸,只改变数据深度。可以把它看做一个保尺寸的高级“卷积”层。
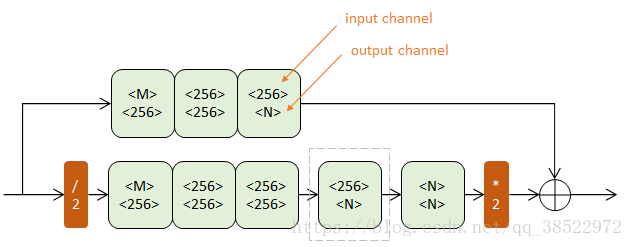
上下两个半路都包含若干Residual模块(浅绿),逐步提取更深层次特征。但上半路在原尺度进行,下半路经历了先降采样(红色/2)再升采样(红色*2)的过程。
降采样使用max pooling,升采样使用最近邻插值。n阶Hourglass子网络提取了从原始尺度到1/2 n 1/2n1/2^n尺度的特征。不改变数据尺寸,只改变数据深度。
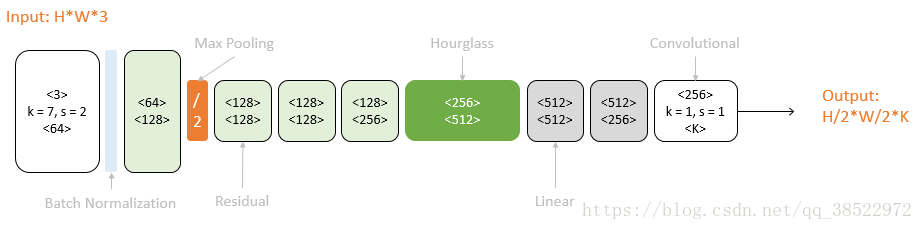
以一个Hourglass(深绿色)为中心,可以从彩色图像预测K个人体部件的响应图。原始图像经过一次降采样(橙色),输入到Hourglass子网络中。Hourglass的输出结果经过两个线性模块(灰色),得到最终响应图。期间使用Residual模块(浅绿)和卷积层(白色)逐步提取特征。而本文用的是以两个Hourglass(深绿色)为中心的二级网络。二级网络重复了一级网络的后半结构。第二个Hourglass的输入包含三路: 第一个Hourglass的输入数据 ,第一个Hourglass的输出数据 ,第一级预测结果 。这三路数据通过串接(concat)和相加进行融合,它们的尺度不同,体现了当下流行的跳级结构思想。如下图所示:

总结起来SHN的方法值得学习的地方有四点:使用模块进行网络设计 ,先降采样,再升采样的全卷积结构 , 跳级结构辅助升采样 ,中继监督训练。
评测数据集:在FLIC数据集上的PCK@0.2分别elbows(99%),elbows(97%)
二,论文翻译
摘要
这项工作介绍了一种新的卷积网络架构的任务人体姿势估计。特征在所有尺度上进行处理,并加以合并,以最好地捕捉与身体相关的各种空间关系。我们展示了如何结合中间监控来重复自底向上、自顶向下的处理对提高网络的性能至关重要。我们将架构称为“堆叠沙漏”网络,它基于池和上采样的连续步骤,这些步骤用于生成最终的预测集。最先进的结果是实现在FLIC和MPII基准竞争所有最近的方法。
1引言
在图像和视频中理解人物的关键步骤是准确的姿势估计。给定单个RGB图像,我们希望确定身体的重要关键点的精确像素位置。了解一个人的姿势和肢体清晰度对于高级任务如动作识别是有用的,而且在人机交互和动画领域也是基本的工具。
姿态估计是视觉领域中一个公认的问题,多年来一直困扰着研究人员,面临着各种严峻的挑战。一种好的姿势估计系统必须对遮挡和严重变形具有鲁棒性,对于稀有和新颖的姿态是成功的,并且对于服装和照明等因素引起的外观变化是不变的。早期的工作利用鲁棒的图像特征和复杂的结构化预测[1-9]解决了这些困难:前者用于产生局部解释,而后者用于推断全局一致的姿态。
然而,这种传统的管道已经被Curvu极大地改造了。人工神经网络(CuNETs)〔10—14〕,爆炸发展后的主要驱动力在许多计算机视觉任务中提高性能。最近的姿态估计系统[15-20]已经普遍采用ConvNets作为它们的主要构建块,在很大程度上取代了手工制作的特征和图形模型;这种策略已经对标准基准[1,21,22]产生了巨大的改进。
我们沿着这条轨迹继续前进,引入了一个新的“堆积沙漏”。 人体姿势预测的网络设计网络捕获和整合图像的所有尺度的信息。我们将该设计称为沙漏,基于我们对用于获得网络最终输出的汇集和后续上采样步骤的可视化。像许多产生像素级输出的卷积方法一样,沙漏网络汇聚到一个非常低的分辨率,然后对多个分辨率的特征进行上采样和组合[15,23]。另一方面,沙漏不同于先前的设计,主要是在其更对称的拓扑结构中。
我们通过连续放置多个沙漏,在一个沙漏上展开。模块一起端到端。这允许重复的自下而上、自上而下的跨尺度推理。结合中间监督的使用,重复的双向推理对网络的最终性能是至关重要的。最终的网络体系结构实现了对两个标准姿态估计基准(FLIC[1]和MPI Human Pos)的最新状态的显著改进。E〔21〕。在MPII上,所有接头的平均精度都有超过2%的提高,而对于更困难的接头则有高达4-5%的提高。就像膝盖和脚踝一样。
2相关工作
随着ToeHeV等对于“DeepPose”的引进介绍。〔24〕人类研究姿态估计开始从经典方法(1—9)转移到深度网络。使用他们的网络直接回归关节的X,Y坐标。[15]取而代之的是,通过并行地通过多个分辨率库运行图像以同时捕获各种尺度的特征来生成热图。我们的网络设计主要基于他们的工作,探索如何跨比例尺捕获信息,并调整他们的方法以结合不同分辨率的特征。
Tompson等人提出的方法的一个关键特征。〔15〕是节理使用VANNET和图形模型。他们的图形模型学习典型关节间的空间关系。其他人最近以类似的方式[17、20、25]解决了这个问题,对如何生成单项评分和对相邻关节进行成对比较进行了修改。 Chen 等人。[25]将检测聚类为典型方向,以便当分类器进行预测时,可获得指示相邻关节的可能位置的附加信息。在没有使用图形模型或任何明确的人体建模的情况下,我们可以获得更好的性能。
有几个例子的方法进行连续预测姿态估计。 Carreira等。[19]使用他们所谓的迭代错误反馈。输入中包括一组预测,每个通过网络的预测进一步细化这些预测。他们的方法需要多阶段训练,并且在每次迭代中共享权重。 Wei等。〔18〕基于多姿态机器(26)的工作,但现在采用了特征提取的神经网络。考虑到我们使用了中间监督,我们的工作在精神上与这些方法相似,但是我们的构建块(沙漏模块)是不同的。Hu&Ramanan[27]的架构更类似于我们的架构,也可以用于多个预测阶段,但是它们的模型将自下而上和自上而下的计算部分以及跨迭代的权重联系起来。
Tompson等人。建立在他们的工作在[ 15 ]级联改进预测。这有助于提高效率并减少其方法的内存使用,同时在高精度范围内改善定位性能[16]。一个考虑因素是,对于许多故障情况,局部窗口内的位置细化不会提供很大的改进,因为错误情况通常由闭塞或错误属性肢体组成。对于这两种情况,任何在局部尺度上的进一步评估都不会改善预测。
姿势估计问题有变化,包括使用额外的特征,如深度或运动线索。〔28—30〕也有 多人同时标注更具挑战性的任务〔17, 31〕。此外, Oliveira等人也有类似的工作。〔32〕基于完全卷积网络进行人类部分分割[23 ]。我们的工作仅集中于从RGB图像中的单个人的姿势的关键点定位的任务。
我们在叠加之前的沙漏模块与全卷积网络[23]和其他设计紧密相连,这些设计在多个尺度上处理空间信息以便进行密集预测[15,33-41]。谢等。〔33〕对典型体系结构进行了总结。我们的沙漏模块不同于这些设计,主要在于它在自底向上处理(从高分辨率到低分辨率)和自顶向下处理(从低分辨率到高分辨率)之间的更对称的容量分布。例如,完全卷积网络[23]和整体嵌套架构[33]在自底向上处理中都很重,但在自顶向下处理中却很轻,这仅包括跨多个尺度的预测的(加权)合并。完全卷积网络也被训练在多个阶段。
堆叠前的沙漏模块也与CONV DECONV和 编码器解码器结构〔42—45〕。Noh等。〔42〕使用
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4876
4876











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









