







本文主要为了解决如何用BP神经网络由历史的目标数据与因素数据去预测未来的目标数据。Bp神经网络的具体算法步骤与代码在网络上已经有很多大佬写过了,本文提供了将其应用于预测的方法。(附简单直接可使用代码)
开始我也在思考,简答来说bp神经网络从本质上来说就是个拟合的工具,用n种因素数据与训练好的权值w去以最优的非线性方式去拟合预测的目标数据。常规bp神经网络只能做到对目标数据的拟合而无法预测出未来数据。
但是当我们想要预测未来的目标数据的时候就会出现一个问题:我们没有未来的因素数据!就比如我想预测未来的地区用电量,就需要未来人口等因素数据。而我要是都知道未来的这些数据了我还要预测目标数据干什么?
好了说回正题,那么既然是一种非线性拟合的方法,那我们可以换一种思路来想这个问题。下面有三种方法:
(1)假定我们现在手里的数据有1个预测的目标数据,n种因素数据,都是1~8年的时间序列数据。
偏移对应法:
我们将1~6年的因素数据输入网络中,对应的期望预测目标数据是3~8年,将网络训练好以后再将7~8年的因素数据作为9~10年目标数据的因素数据去乘上训练完成的权重矩阵,最终就可以输出9~10年的目标预测数据。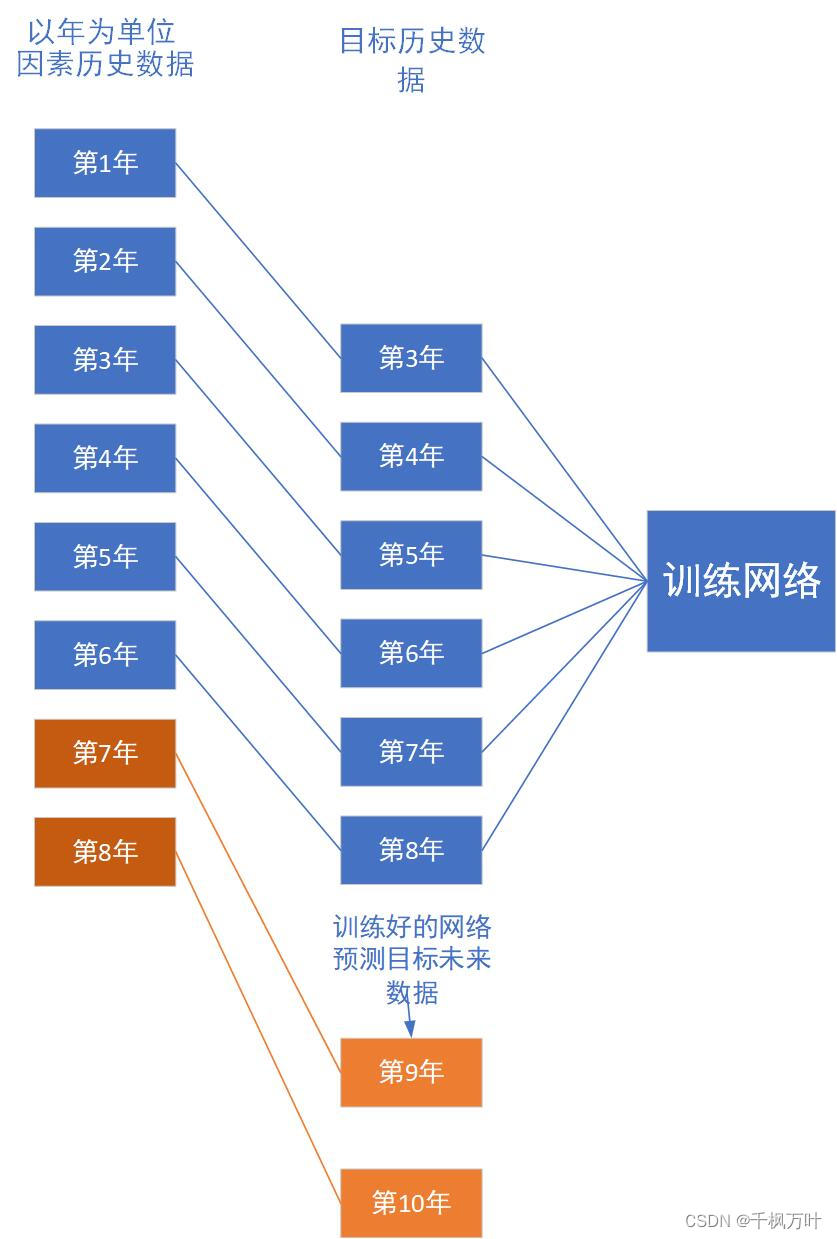
(2)如果说以上面那样的偏移对应法,为了保证精准度只能最多偏移两三年,否则过多偏移会导致数据失真,所以这里用另外一种思想。
滚动时间训练法:
开始与偏移法相同,但是这次只偏移一年,即1~7年因素数据、对应的期望预测目标数据是2~8年,训练好后用第8年的因素数据乘上训练好的权值矩阵得到第9年的目标预测数据。
然后再以上次得到第9年的目标预测为已知条件,训练新的bp网络,2~8年因素数据、对应的期望预测目标数据是3~9年相同方法预测出第10年的目标预测数据。之后以第10年的预测数据作为已知条件重复滚动。如果是想预测更多那么第一步偏移的年数可以多一点。
(3)如果你的因素数据是时间,那么就无忧了,因为未来的时间数据肯定没问题。
但要是因素都已经是时间了,其实也可以考虑用灰色预测模型。
最后小结一哈:1)预测前可以先进行准确度检验,即划分训练集和验证集。代码的话相信很多大佬已经写过很多次了,我写的一般般就放在文章最后供一点点参考(pyhton),但是清楚思路最重要。
2)可以记得运行的时候要多训练几次,bp神经网络每一次的结果都不一样,和谈恋爱时的心情一样有时好有时坏,我们选精度最高的那个模型。实测以上的几种方法的精确度下来,最好是不要预测太长时间序列,适合中短期的预测模型。
3)如果是数学建模中的话建议最好还是用标准化预测的模型,bp神经网络这种黑盒思想的方法很多老师审核不太认同。当然论文研究里适用很广。
刚写完自己的论文后思考出的一些方法和感悟,受苦于机器学习的小白一枚,若有帮助感谢各位多多点赞!
pyhton代码:
这里的代码是以1999到2021年的数据操作,采用的是第一种偏移对应法,因素数据选1999-2018对应的目标数据是2002到2021年,偏移对应的年份是三年,所以最后输入2019-2021年的因素数据到训练好的网络时得到的是2022-2024年的目标数据预测。
刚自己写了一个可以套用的函数,你可以在选择偏移年份处将k改为自己想要往后预测的年份,再导入你的数据,最后在结尾处有输出预测值(要是中间的算法部分看不懂也可以用)。
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
#导入你的数据
df=pd.read_excel('datanew.xlsx')
x=df[['全年平均日照', '可支配收入','人户','发电量','实际居民用电量']]
y=df[['用水量']]
time = []
print(x.head(),y.head())
#选择偏移对应的年份(这里是偏移了三年也就是往后预测三年)
k = 3#(输入往后预测的年份)
def pianyi(k):
b = len(y)
xunlianx = x[0:b-k]#因素数据选1999-2018
xunliany = y[k:b]#用于最后预测未来目标数据
zongx = x[0:b]#用于最后预测未来目标数据
return xunlianx,xunliany,zongx
xunlianx,xunliany,zongx = pianyi(k)
#对数据进行最大最小值归一化
x_scaler=MinMaxScaler(feature_range=(-1,1))
y_scaler=MinMaxScaler(feature_range=(-1,1))
x=x_scaler.fit_transform(xunlianx)
y=y_scaler.fit_transform(xunliany)
zongx2 = x_scaler.transform(zongx)
#对样本进行转置,矩阵运算
sample_in=x.T
sample_out=y.T
zongx2 = zongx2.T
#BP神经网络网络参数
max_epochs=60000 #循环迭代次数
learn_rate=0.001 #学习率
mse_final=6.5e-4 #设置一个均方误差的阈值,小于它则停止迭代
sample_number=xunlianx.shape[0] #样本数
input_number=xunlianx.shape[1] #输入特征数
output_number=xunliany.shape[1] #输出目标个数
hidden_units=12 #隐含层神经元个数
#定义激活函数Sigmod
# import math
def sigmoid(z):
return 1/(1+np.exp(-z))
def sigmoid_delta(z): #偏导数
return 1/((1+np.exp(-z))**2)*np.exp(-z)
#一层隐含层
#W1矩阵:M行N列,M等于该层神经元个数,N等于输入特征个数
W1=0.5*np.random.rand(hidden_units,input_number)-0.1
b1=0.5*np.random.rand(hidden_units,1)-0.1
W2=0.5*np.random.rand(output_number,hidden_units)-0.1
b2=0.5*np.random.rand(output_number,1)-0.1
mse_history=[] #空列表,存储迭代的误差
#不设置激活函数
for i in range(max_epochs):
#FP
hidden_out=sigmoid(np.dot(W1,sample_in)+b1) #np.dot矩矩阵相乘,hidden_out1结果为8行20列
network_out=np.dot(W2,hidden_out)+b2 #np.dot矩阵相乘,W2是2行8列,则output结果是2行20列
#误差
err=sample_out-network_out
mse_err=np.average(np.square(err)) #均方误差
mse_history.append(mse_err)
if mse_err<mse_final:
break
#BP
#误差向量
delta2=-err #最后一层的误差
delta1=np.dot(W2.transpose(),delta2)*sigmoid_delta(hidden_out) #前一层的误差向量,这一层对hidden_out用了sigmoid激活函数,要对hidden_out求偏导数;注意最后一步是两个矩阵的点乘,是两个完全相同维度矩阵
#梯度:损失函数的偏导数
delta_W2=np.dot(delta2,hidden_out.transpose())
delta_W1=np.dot(delta1,sample_in.transpose())
delta_b2=np.dot(delta2,np.ones((sample_number,1)))
delta_b1=np.dot(delta1,np.ones((sample_number,1)))
W2-=learn_rate*delta_W2
b2-=learn_rate*delta_b2
W1-=learn_rate*delta_W1
b1-=learn_rate*delta_b1
#模型预测输出和实际输出对比图
hidden_out=sigmoid(np.dot(W1,sample_in)+b1)
network_out=np.dot(W2,hidden_out)+b2
#反转获取实际值:
network_out=y_scaler.inverse_transform(network_out.T)
sample_out=y_scaler.inverse_transform(y)
#zongx2
hidden_out3 = sigmoid(np.dot(W1,zongx2)+b1)
network_out3 = np.dot(W2,hidden_out3)+b2
network_out3 = y_scaler.inverse_transform(network_out3.T)
#损失值画图
p1 = plt.figure(figsize=(12, 12))
pip1 = p1.add_subplot(2, 2, 1)
#print(mse_history)
loss=np.log10(mse_history)
min_mse=min(loss)
plt.plot(loss,label='loss')
plt.plot([0,len(loss)],[min_mse,min_mse],label='min_mse')
plt.xlabel('iteration')
plt.ylabel('MSE loss')
plt.title('Log10 MSE History',fontdict={'fontsize':18,'color':'red'})
plt.legend()
#解决中文无法显示
plt.rcParams['font.sans-serif'] = [u'SimHei']
plt.rcParams['axes.unicode_minus'] = False
b = len(network_out3)
time = np.linspace(k,b,b-k)
pip2 = p1.add_subplot(2, 2, 2)
plt.plot(time,network_out[:,0],label='pred')
plt.plot(time,xunliany,'r.',label='actual')
plt.xlim()
plt.title('用水量(训练过程) ',)
plt.legend()
pip = p1.add_subplot(2,2,3)
hk = np.linspace(k,b+k,b)
plt.plot(hk,network_out3,label='pred')
plt.plot(time,xunliany,'r.',label='actual')
plt.title('用水量(预测过程)')
plt.legend()
plt.show()
#最终预测结果保存在network_out3
b = len(network_out3)
print("在偏移对应训练下的(",k,"到",(k+b),")年预测结果:",network_out3)
print("在偏移对应训练下往后",k,"年预测结果:")
for i in range(k):
print(network_out3[b-k+i][0],end=",")
数据格式:
| 全年平均日照 | 可支配收入 | 人户 | 发电量 | 实际居民用电量 | 用水量 | |
| 1999 | 840.5 | 5589 | 520.21 | 30.51 | 312980 | 5545 |
| 2000 | 842.1 | 6223 | 518.36 | 33.68 | 306900 | 5376 |
| 2001 | 1072.1 | 6543 | 520.16 | 37.82 | 367864 | 5614 |
| 2002 | 1140.1 | 7042 | 521.86 | 50.02 | 451943 | 5372 |
| 2003 | 972.9 | 7179 | 527.52 | 62.28 | 393755 | 6262 |
| 2004 | 990 | 7708 | 529.07 | 65.25 | 427215 | 7191 |
| 2005 | 1147.3 | 8201 | 530.71 | 71.22 | 540428 | 7191 |
| 2006 | 941.5 | 9054 | 533.30 | 85.23 | 561570 | 7404 |
| 2007 | 1321.8 | 10473 | 537.95 | 74.09 | 622800 | 7523 |
| 2008 | 1177.8 | 12200 | 540.71 | 60.48 | 652500 | 7593 |
| 2009 | 1218.2 | 13701 | 544.65 | 76.73 | 684846 | 7637 |
| 2010 | 10030.5 | 15516 | 541.87 | 90.69 | 700724 | 7695 |
| 2011 | 953.1 | 17998 | 543.36 | 91.48 | 730771 | 7731 |
| 2012 | 1201 | 20775 | 545.40 | 92.43 | 874755 | 8386 |
| 2013 | 1071.1 | 23100 | 547.38 | 97.60 | 839934 | 8943 |
| 2014 | 1490 | 25341 | 548.78 | 97.60 | 920299 | 9177 |
| 2015 | 1021.5 | 27170 | 545.48 | 99.3 | 945717 | 9787 |
| 2016 | 1233.4 | 29407 | 545.18 | 101.5 | 965165 | 10356 |
| 2017 | 1294.2 | 31822 | 536.82 | 102.6 | 995815 | 10986 |
| 2018 | 1274.2 | 34411 | 536.20 | 104.8 | 1070855 | 11065 |
| 2019 | 1468 | 37454 | 531.29 | 106.7 | 1181301 | 12223 |
| 2020 | 1054.6 | 39680 | 528.51 | 110.8 | 1283382 | 12604 |
| 2021 | 1257.8 | 42107 | 537.4 | 114.1 | 1289008 | 13164 |


















 774
774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









