






今日任务:
1)347.前 K 个高频元素
2)栈与队列总结
3)二叉树理论基础篇
4)二叉树的递归遍历
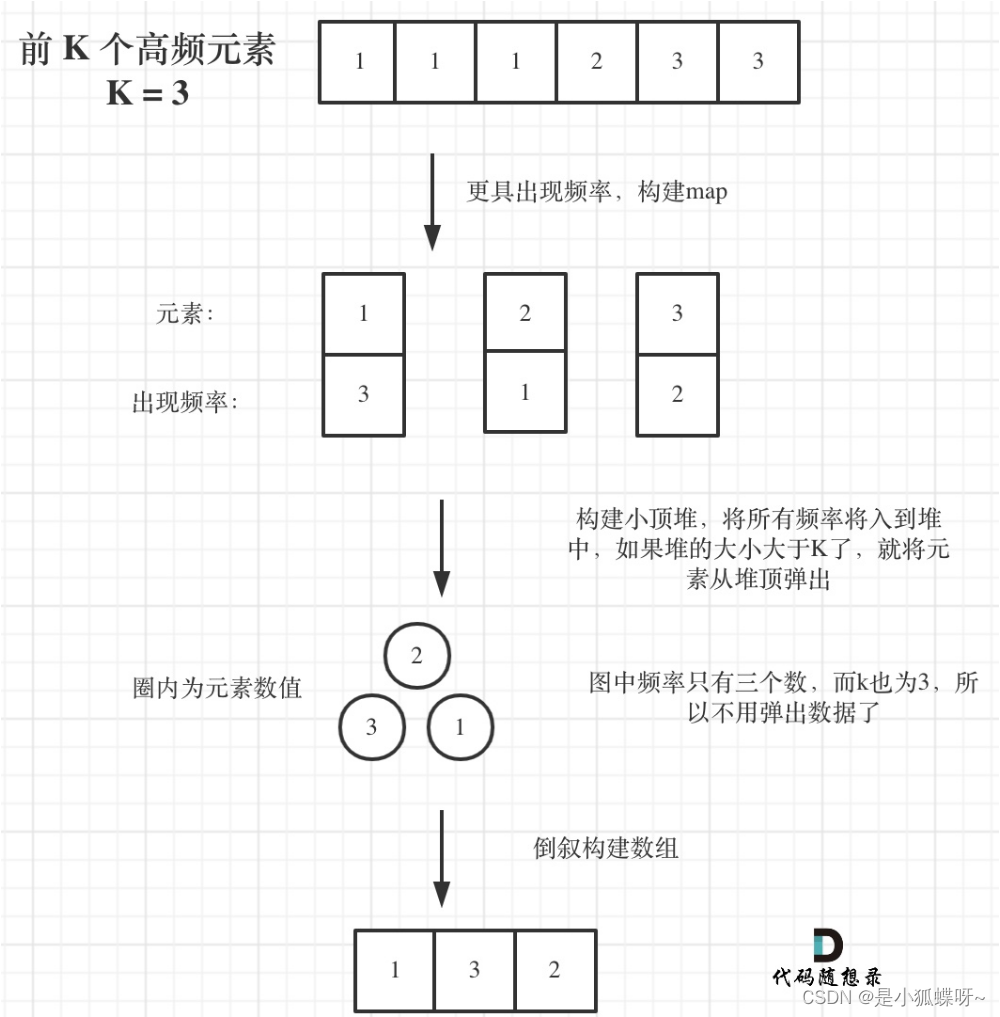
347.前 K 个高频元素
题目链接:347. 前 K 个高频元素 - 力扣(LeetCode)

文字及视频讲解:代码随想录 (programmercarl.com)
思路:
方法一:(暴力法)
1)采用字典的容器,求一下每个值出现的次数
2)对值进行sorted排序
3)找到前k个次数对应的key
方法二:(优先队列法)
1)采用字典的容器,求一下每个值出现的次数
2)然后采用优先队列去对频率排序,维护前k个元素,有一点要注意,应该采用小顶堆实现,每次弹出堆顶的最小数,把大数留下来
方法一:(暴力法)
class Solution(object):
def topKFrequent(self, nums, k):
"""
:type nums: List[int]
:type k: int
:rtype: List[int]
"""
nums_dict = {}
result = []
for num in nums:
if num not in nums_dict.keys():
nums_dict[num] = 1
else:
nums_dict[num] += 1
values = sorted(nums_dict.values(),reverse = True)
for i in range(k):
for key,value in nums_dict.items():
# 注意一下要判断key是否已经存在result里面,否则次数一样的数值会重复添加到result
if value == values[i] and key not in result:
result.append(key)
return result方法二:(优先队列法)
#时间复杂度:O(nlogk)
#空间复杂度:O(n)
import heapq
class Solution:
def topKFrequent(self, nums: List[int], k: int) -> List[int]:
#要统计元素出现频率
map_ = {} #nums[i]:对应出现的次数
for i in range(len(nums)):
map_[nums[i]] = map_.get(nums[i], 0) + 1
#对频率排序
#定义一个小顶堆,大小为k
pri_que = [] #小顶堆
#用固定大小为k的小顶堆,扫描所有频率的数值
for key, freq in map_.items():
heapq.heappush(pri_que, (freq, key))
if len(pri_que) > k: #如果堆的大小大于了K,则队列弹出,保证堆的大小一直为k
heapq.heappop(pri_que)
#找出前K个高频元素,因为小顶堆先弹出的是最小的,所以倒序来输出到数组
result = [0] * k
for i in range(k-1, -1, -1):
result[i] = heapq.heappop(pri_que)[1]
return result感想:
直接暴力法可以求解出来,时间复杂度也可以通过。队列优先法之前没有了解过,一开始写不出。
栈与队列总结
文字及视频讲解:代码随想录 (programmercarl.com)
二叉树理论基础篇
文字及视频讲解:代码随想录 (programmercarl.com)
二叉树的递归遍历
题目链接:144. 二叉树的前序遍历 - 力扣(LeetCode)
文字及视频讲解:算法打卡Day12-CSDN博客
思路:
递归算法的三个要素:
确定递归函数的参数和返回值: 确定哪些参数是递归的过程中需要处理的,那么就在递归函数里加上这个参数, 并且还要明确每次递归的返回值是什么进而确定递归函数的返回类型。
确定终止条件: 写完了递归算法, 运行的时候,经常会遇到栈溢出的错误,就是没写终止条件或者终止条件写的不对,操作系统也是用一个栈的结构来保存每一层递归的信息,如果递归没有终止,操作系统的内存栈必然就会溢出。
确定单层递归的逻辑: 确定每一层递归需要处理的信息。在这里也就会重复调用自己来实现递归的过程。
题目一:(前序遍历)
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution(object):
def preorderTraversal(self, root):
"""
:type root: TreeNode
:rtype: List[int]
"""
# 递归
result = []
# 确定递归函数的参数和返回值,python不需要返回值
def fun_iteration(node):
# 确定终止条件:在递归的过程中,如何算是递归结束了呢?
# 当然是当前遍历的节点是空了,那么本层递归就要结束了,所以如果当前遍历的这个节点是空,就直接return
if node == None:
return
# 确定单层递归的逻辑:前序遍历是中左右的顺序,所以单层递归的逻辑是要先取中节点的数值
result.append(node.val)
fun_iteration(node.left)
fun_iteration(node.right)
fun_iteration(root)
return result题目二:(后序遍历)
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution(object):
def postorderTraversal(self, root):
"""
:type root: TreeNode
:rtype: List[int]
"""
result = []
def iteration(node):
if node == None:
return
iteration(node.left)
iteration(node.right)
result.append(node.val)
iteration(root)
return result
题目三:(中序遍历)
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution(object):
def inorderTraversal(self, root):
"""
:type root: TreeNode
:rtype: List[int]
"""
result = []
def iteration(node):
if node == None:
return
iteration(node.left)
result.append(node.val)
iteration(node.right)
iteration(root)
return result感想:
递归的思想是自己调用自己,需要明确知道三个要素,也就是输入和输出,以及跳出的条件,还有单层逻辑。















 445
445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









