







一. 引入
写一个C文件
#include <stdio.h>
int main(){
//第一个参数为可选路径+文件名进行创建,如果没有路径,默认在当前路径下创建
//第二个参数为选项
FILE* fp = fopen("log.txt","w");
if(NULL == fp){
perror("fopen error!\n");
}
else{
char c = 'A';
for(; c <= 'Z'; ++c){
fputc(c,fp);
}
fclose(fp);
}
return 0;
}
上面程序运行,在当前目录下创建log.txt的文件,并将A…Z的字符全部写进去
1. 站在进程角度,它是怎么去访问该文件的
文件=内容+属性
Linux下一切皆文件(键盘,显示器也可当作文件来看待)
为什么会存在这些输入输出流
因为语言设计出来执行指令,肯定需要与人进行交互,为了交互,需要有这些输入输出
写入文件与显示器
size_t fwrite(const void* ptr,size_t size,size_t count,FILE* stream);
//返回值:返回实际写入基本单位个数
//参数:
// 1.写入内容地址
// 2.写入数据的基本单位大小
// 3.写入几个基本单位
// 4.往哪儿写
如:
const char* msg = "hello world\n";
fwrite(msg,strlen(msg),1,stdout);
//这里不用strlen(msg)+1把\n写入,以\n作为结尾是字符串要求,文件不会要求以\n结尾,写入\n会出问题
这里的例子我们可以直接往显示器写,也就是说,运行这段代码程序,会把hello world打印出来。
所以普通文件与显示器实际上没有什么区别,都可以被fwrite写入
2. 总
- 除了上面库函数接口,我们还有一套系统调用接口,如:open,close,read,write
- 库函数相当于对系统调用进行封装,调用库函数 == 调用系统调用
- 系统调用只有一套,就被封装成了各种语言的库函数
- 显示器,往硬盘中写数据都是给硬件写,所有的I/O操作都是往硬件上写数据,怎么写?都是OS帮我们写
二. 系统文件I/O
1. open
#include <sys/types.h>
#include <sys/stat.h>
#include <fcnt1.h>
int open(const char* pathname,int flags);
int open(const char* pathname,int flage,mode_t mode);
pathname:要打开或创建的目标文件
flags:打开文件时,可以传入多个参数选项,用下面的一个或者多个常量进行”或“运算,构成flags
参数:
O_RDONLY:只读打开
O_WRONLY:只写打开
O_RDWR:读,写打开,这三个常量,必须指定一个且只能指定一个
O_CREAT:若文件不存在,则创建它,需要使用mode选项,来指明新文件的访问权限
O_APPEND:追加写
O_TRUNC:将文件内容清空,再重新重定向写入
返回值:
成功:新打开的文件描述符
失败:-1
注:
- O_RDONLY | O_WRONLY这样相当于按位或,将不同功能组合在一起,传入更多功能
- O_RDONLY,O_WRONLY这些参数都是宏参数,二进制中只有1位或几位为1,代表不同的功能
- O_APPEND与O_TRUNC的区别,O_APPEND是不清空,直接写入,O_TRUNC是将文件内容清空,再重新重定向写入
open函数具体使用哪个,和具体应用场景相关,如目标文件不存在,需要open创建,则第三个参数表示创建文件的默认权限,否则,使用两个参数的open
返回值,成功返回新打开的文件描述符,在OS层面,其就是一个整数,从0-n;0表示标准输入,1表示标准输出,2表示标准错误。
2. 系统文件结构
因为OS一定要把打开的文件管理起来
在Linux描述文件用struct file结构
struct file{
//文件的属性信息
//文件的缓冲与存储位置
}
//这些信息在文件和硬盘上都有
同时打开文件要与进程关联,一个进程又可以打开多个文件,所以整个结构如下:
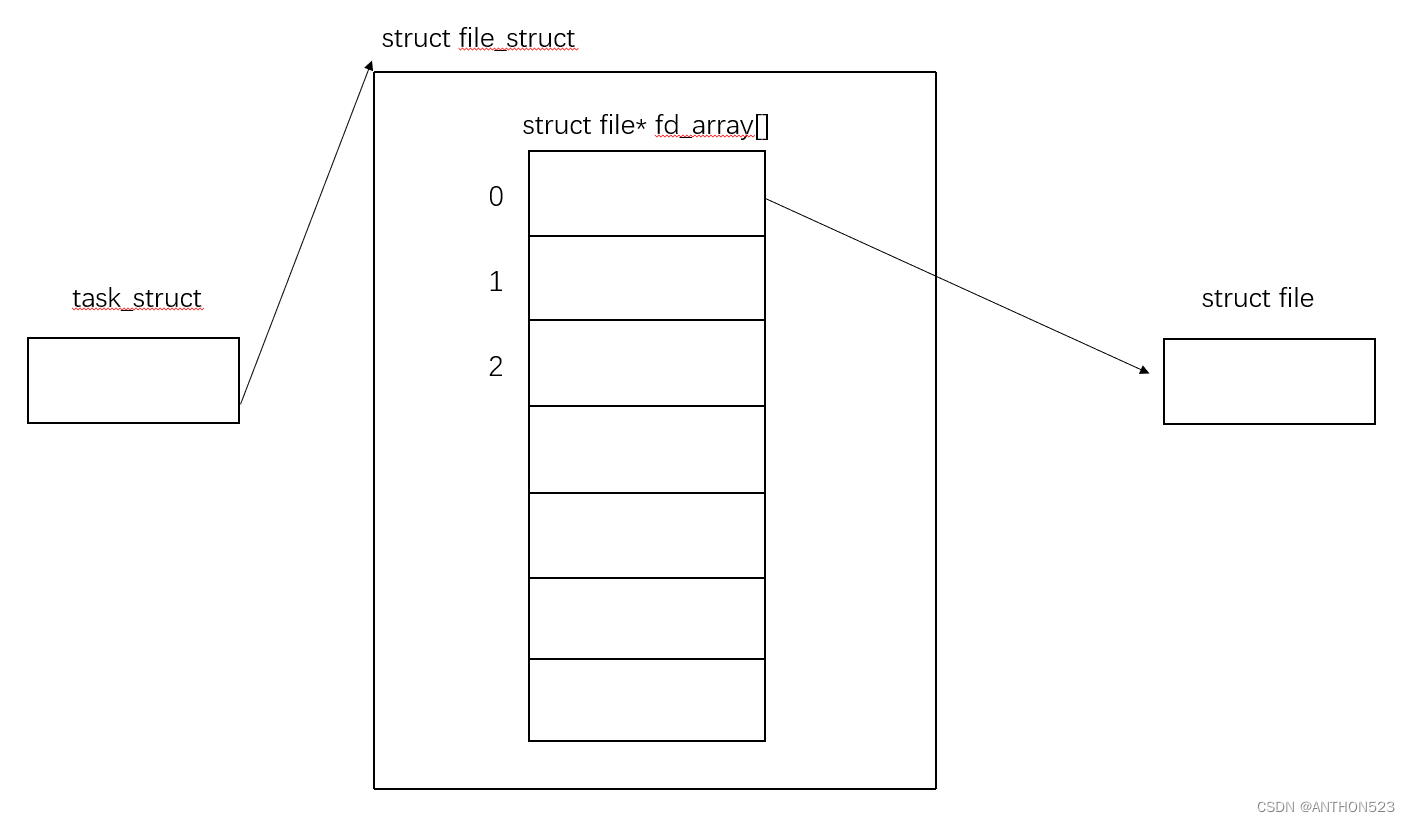
由上图可知,task_struct中有一个指针指向struct file_struct,在file_struct中有一个fd_array[]数组,其中每个位置指向一个struct file
所以就靠这样,将文件与进程关联起来,先用链表将文件信息与文件之间管理起来,然后进程用一个数组将多个文件管理起来
注:fd_array[] 默认大小为32(内核3.6.32版本)
如果超过32会升级,让你继续大,但也会有限制
如:write(4,“hello”,5);
OS找到当前进程pid,进入进程内部结构体,系统在其指向文件数组中搜4,就可以找到对应文件,找文件中内容
3. open总
- 结合后面与前面知识,open不仅处于底层是系统封装的,我们open是进程去调用,然后遍历struct file fd_array[]数组,找到最小下标没有被用过的数组空间,把新打开的文件地址填到对应的数组空间中
open把其在数组中的下标返回,这就是文件描述符
我们在一个进程中打开的第一个文件,其文件描述符为3,因为0,1,2分别为标准输入,标准输出,标准错误
4. 一些小细节
我们close(0)后,再打开第一个文件的文件描述符为0,而不为3。
close(1)与close(2)也类似
对于进程来讲,第一个文件的进程描述符为3,但如果有更小的,会把更小下标的数组空间给其使用,返回更小的数组下标
当我们close(1)后,再打开一个文件,我们在printf等打印时,发现打印不出来
因为1文件描述符之前其为标准输出所用,我们关闭其后,在fd_array[] 中下标为1的数组空间就空闲出来了;我们再打开一个文件,会将下标为1的数组空间给其使用,也就是我们新打开文件的文件描述符变成了1
但上层并不知道,它依然认为1为标准输出,依然往占用1文件描述符的文件中输入
这也是重定向的原理:
echo "hello world" > my.txt
//就是把”hello world"输入到了my.txt中
echo "hello world" >> mytxt
//相当于加了O_APPEND的选项,可追加输入
5. write与read
#include <unistd.h>
size_t write(int fd,const void* buf,size_t count);
参数:
1.写入文件的文件描述符
2.写入的字符串
3.期望写多少字节数
返回值:
成功写入的字节数,出错返回-1并设置error
stdout vs 1(文件描述符)
stdout属于C的库中。其类型是FILE*的,其中有文件描述符的信息
文件描述符1属于底层OS结构
所以文件描述符1是更靠近底层
read
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);
返回值:成功读取的字节数,出错返回-1并设置error
参数:
1.从哪儿读
2.读向哪儿
3.期望读多少字节数
6. 缓冲区
int main(){
close(1);
int fd = open("log.txt",O_CREAT | O_APPEND | O_WRONLY,0644);
if(fd < 0){
perror("open error");
return 1;
}
const char* str = "hello world:write\n";
const char* str2 = "hello world:printf\n";
const char* str3 = "hello world:fprintf\n";
write(1,str,strlen(str);
printf("%s",str2);
fprintf(stdout,"%s",str3);
fork();
fflush(stdout);
close(fd);
return 0;
}
fflush是为了把缓冲区的内容刷新出来,
上面代码的结果为:
当使用close(1)再打开文件,将标准输出重定向后,这些输出都输入了log.txt,当我们cat log.txt时,会显示出如下内容:
hello world:write
hello world:printf
hello world:printf
hello world:fprintf
hello world:fprintf
可发现printf与fprintf打印了两遍
当我们将close(1)注释掉
所有内容打进标准输出,发现三个输出都打印了一遍
由上面的例子我们可知
- fprintf、printf为库函数,write为系统调用。
- 缓冲区,显示器:行缓存,遇到\n才刷新出来。文件:全缓存,只有把缓冲区写满,才刷新出来
- 所以,重定向可能会影响缓冲方式
- 系统调用不受缓冲方式的影响,直接刷新出来,库函数受缓冲方式的影响
所以上面的例子为什么会出现这样的现象
但close(1)还存在时,此时缓冲方式为全缓冲,printf 与 fprintf 中的数据还存在缓冲区中,讲过fork() 之后,缓冲区中的内容为进程中的数据,父子进程各自私有,经过fflush() ,父子进程都将缓冲区的内容刷新一次,所以打了两次
总
此时的缓冲区是由库函数提供的(也就是语言提供的),为用户级别的缓冲区。这就是为什么系统调用不受缓冲区的影响。
如果系统提供,系统调用也要受缓冲区的影响
一个文件可被多个进程打开,可有多个fd与其对应’
7. 重定向操作
如果要实现追加重定向,打开文件时,加上O_APPEND即可
方法一
先关闭一个文件
close(fd);
再
int fd = open(...)打开一个文件进行重定向
方法二
#include <unistd.h>
int dup(int oldfd);
int dup2(int oldfd,int newfd);
如:想把输入文件描述符1的内容输入文件描述符fd的文件,怎么做?
dup2(fd,1);
此时文件描述符1不再指向标准输出,而是指向文件描述符fd所指向的文件,这样就完成了重定向
此时文件描述符1与文件描述符fd都指向该文件,我们可以close(fd),将fd关闭
因为维护的fd_array[]大小是有限的,也就是说打开的文件数量是有上限的,能关掉就关掉
8. 对于struct file{}
struct file{
//属性
//方法,函数指针
int (*write)(int fd,char* buf,int size);
......
}
对于不同的硬件或文件,如硬盘,显示器,键盘,其实我们要使用不同的方法进行写入和读取。但我们通过函数指针,虽然函数指针指向的方法不同,但是在上层看来,我们调用同一个接口write,read即可,相当于在上层做了一层虚拟层(这也是为什么Linux下一切可当作文件看待),这样会使我们的使用更便捷、高效
三. inode
文件=属性+内容,属性也会占空间
1. 属性
我们把文件属性集合在一起给其定结构叫做inode
ls -i file查看file文件的inode号
一个文件只有一个inode
2. 内容
内容在Linux中一般是纯内容,被保存在block内存块中
一个文件可能有多个block
3. filesystem
描述分区的情况
filesystem{
//基本情况
//空间一共是多大
//有多少已经使用 || 多少没有被使用
//inode
//block
//group
//方法,后面解析
}
我们使用ls -l时看到了很多文件元数据
-rwxr-xr-x. 1 root root 7438 "9月 13 14:56" a.out
1. 模式
2. 硬链接数
3. 文件所有者
4. 组
5. 大小
6. 最后修改的时间
7. 文件名
磁盘文件系统图
OS去管理
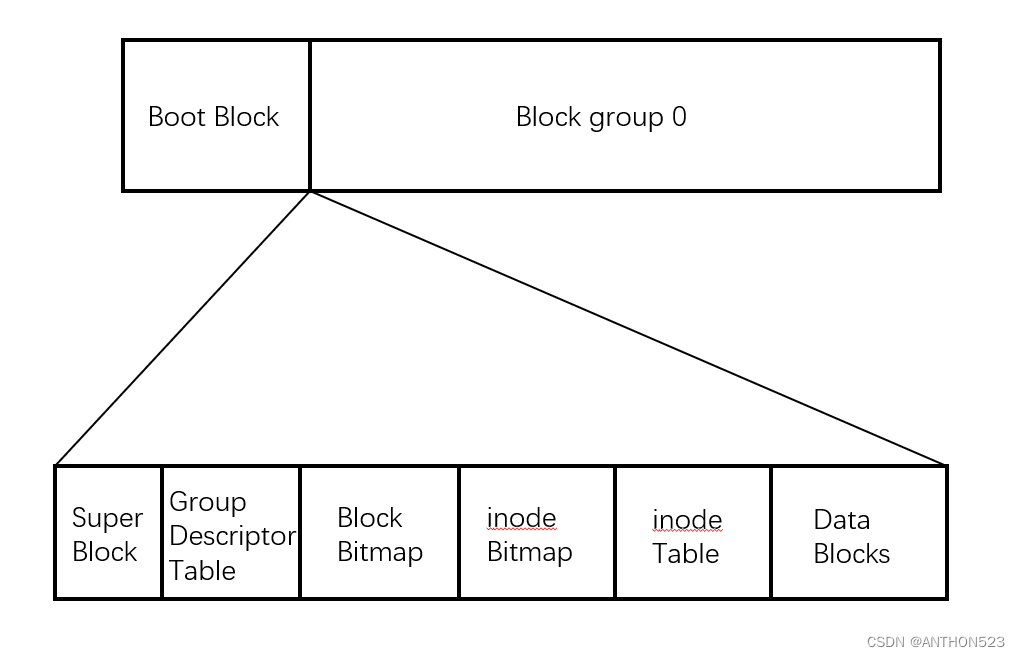
- Block Group:ext2文件系统会根据分区的大小划分为数个Block Group。而每个Block Group都有着相
同的结构组成。政府管理各区的例子 - 超级块(Super Block):存放文件系统本身的结构信息。记录的信息主要有:bolck 和 inode的总量,
未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的
时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个
文件系统结构就被破坏了 - GDT,Group Descriptor Table:块组描述符,描述块组属性信息,有兴趣的同学可以在了解一下
- 块位图(Block Bitmap):Block Bitmap中记录着Data Block中哪个数据块已经被占用,哪个数据块没
有被占用 - inode位图(inode Bitmap):每个bit表示一个inode是否空闲可用。
- i节点表:存放文件属性 如 文件大小,所有者,最近修改时间等
- 数据区:存放文件内容
总
inode:文件的属性 文件 :inode = 1 :1
Data blocks:数据 文件 :inode :data block = 1 :1 :1(orn)
inode必须包含datablocks对应的映射关系
找一个文件,先找inode
-
我们怎么去寻找inode
每一个inode id标识一个inode -
如何去找文件
先找区,块,组,在inode table中找到它inode信息,根据映射,去找数据 -
如何删除
在位图中,将inode对应的编号删除
(删没有清除数据,其是可以有办法恢复)
目录也是文件 = inode+数据块
目录中存的是文件名(inode id)到inode的映射关系,文件名是给人看到的,inode id是OS中辨别inode的
所以我们去找目录文件信息,是先在目录中找到inode id及其对应关系,去inode表中找具体信息
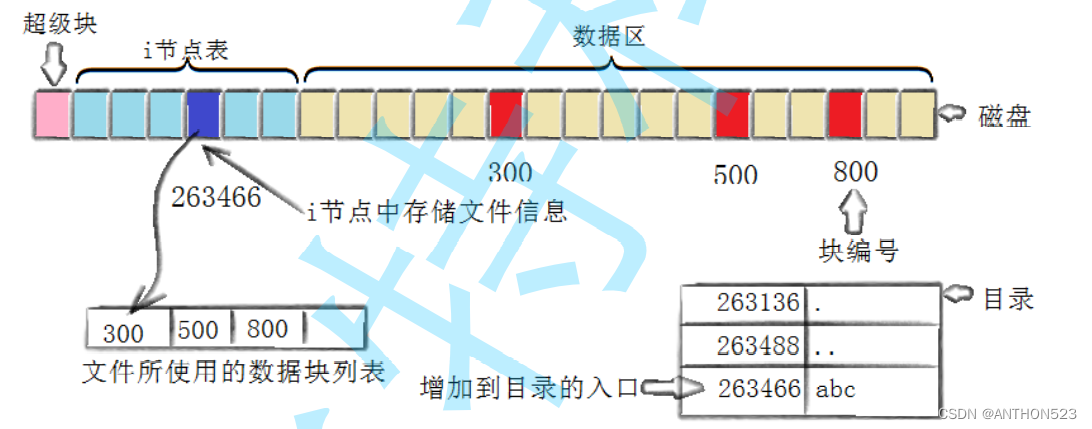
创建一个新文件主要有以下四个操作:
- 存储属性
内核先找到一个空闲的 i 节点。内核把文件信息记录到其中 - 存储数据
该文件需要存储在三个磁盘块,内核找到了三个空闲块:300,500,800。将内核缓冲区的第一块数据复制到300,下一块复制到500,以此类推 - 记录分配情况
文件内容按顺序300,500,800存放。内核在inode上的磁盘分布区记录了上述块列表 - 添加文件名到目录
新的文件名为abc,内核将入口(i ,abc)添加到目录文件,文件名和inode之间的对应关系将文件名和文件的内容及属性连接起来。
四. 软链接和硬链接
1. 软链接
具有独立的inode,是一个独立的文件(相当于windows中的快捷方式)
如何建立:
ln -s 文件路径文件名 新文件名
//在此目录下,可直接./运行
2. 硬链接
和指向的文件共享同一个inode,不是一个独立的文件
硬链接是什么:在目录下对于一个文件名及其inode的链接关系,又加了一个不同文件名与其inode链接关系
如何建立:
ln 文件名 新文件名
当我们mkdir创建一个目录,其硬链接数为2。因为目录中有一个文件 . 指向当前目录
当我们在一个目录x 下创建一个新目录y 时,x 的硬链接数为3。因为在y中有一个 . .指向上级目录x
3. 删除文件
硬链接:
- 在目录中,将文件名(inode id)与inode的关联记录删除
- 将硬链接数-1,如果为0,则直接将其对于的磁盘释放
软链接:
软链接文件是一个独立的文件,有自己的inode节点。这个文件保存的是源文件路径,通过访问的路径放问源文件
如果源文件被删除,则找不到源文件,这时软链接失效
题
对于一个目录运用 chmod u-r x/ 去除x目录的读权限
我们再次ls x/时将会报错,我们不能看该目录下的文件
而我们可以 ls x/y -al(y为x中的文件)去访问该文件的信息
因为我们去除了目录的读权限,我们不能去读目录数据块的所有内容
但我们对该 x 目录有进入权限,并且我们对文件 y 有读取权限。但我们还是需要找文件inode,但我们指明了文件名,系统中可以通过其他方式去找到。















 9536
9536











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









