







python
python的组成
基本语法
基本数据类型
变量
运算符
相当于英语中的 单词(基本数据类型)、语法(基本语法)、定义的人名地点(变量)、运算方法(运算符)
语句分割符
print("hello world")
print(1+1)
在这个里面换行相当于一个语句分割符或者是一个分号,所有的语句如果不在一个流程控制中就要顶格书写
注释
单行注释使用#
多行注释使用"“”
“”"
#倒入一个datetime模块,获取时间
import datetime
#打印当前时间
print(datetime.datetime.now().strftime("%Y/%m/%d %X"))
变量
-
变量的命名
- 包含字母数字下滑线,不能以数字开头
- 不能使用保留字,即是python的特定字符
- 命名要见名知意,例如my_first_name=‘’
- 变量名应该遵循一定的命名约定,例如使用小写字母、下划线分隔单词的方式。
-
变量的特性一:反复使用
x = 1
y = 2
print(x + y)
print(x - y)
- 如果说要把x+y当作一个经常性使用的,就要把它敷给一个变量
z = x + y
- 变量值的修改
x = 10
print (x)
x = 20
print (x)
#变量只的修改会重新开辟一个空间并把x指向20,而10会被垃圾回收机制给回收掉
基本数据类型
- 整型和浮点型
- 布尔值
- 字符串
#判断一个值的类型的内置函数
x = 10
print(type(x))
#判断一个数或表达式的布尔值也有一个内置函数
x = 10
y = 2
print(x > y)
print(bool(x>y))
#零值: 所有的数据类型中都有且只有一个值的bool状态是False,该值成为此类型的零值
# 整型和浮点型的零值: 0
#字符串 “” 字典 {} 列表[]这些的布尔值为false
#构建字符串的三种方式
s1 ="dhjsbfd"
s2 = 'dadqw'
s3 = '''
ferfeffe
frefergeb
ymjytjt
'''
字符串的基本操作
1.转译符
-
将某些普通符号给予特殊的功能
-
将一些特殊功能的符号普通化
在Python中,字符串的转义是指在字符串中使用特殊的字符序列来表示一些特殊字符。在Pvthon中,字符串的转义符是反斜杠\,可以用来表示一些特殊的字符,如单引号、双引号、换行符、制表符等。以下是一些常用的字符串转义符:
-
\'表示单引号
-
\"表示双引号
-
\\表示反斜杠
-
n 表示换行符
-
\t 表示制表符
-
\r 表示回车符
-
2.格式化输出
name = "小雪"
age = 12
height = 183
# 方案一,占位
print("这个人的名字是%s,年龄是%d,身高是%d"%(name,age,height))
# 方案二,format,格式化
print(f"这个人的名字是{name},年龄是{age},身高是{height}")
字符串的序列操作
字符串一旦创建好就不能进行修改操作
字符串属于序列类型,所谓序列,指的是一块可存放多个值的连续内存空间,这些值按一定顺序排列可通过每个值所在位置的编号 (称为索引) 访问它们。
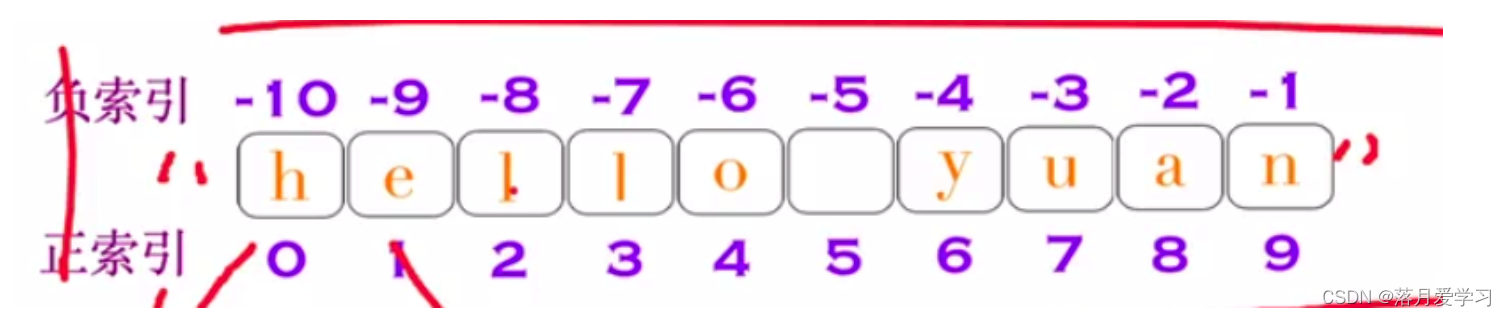
两个要素
- 容器
- 有序
s = "hello world"
b = "bio"
d = "llo"
c = 10
#1.输出单个字符
print(s[0])
print(s[-1])
#2.输出一个字符串
#切片操作,s[开始的位置:结束的位置:step:1],顾头不顾尾,默认为1,负数代表从右往左
print(s[0:5])
#截取world的字符
print(s[6:10]) #按照这种方式并不能获取的最后一个字符
print(s[6:]) #这样写就可以了
print(s[-5:])
print(s[0:6:2]) #step 2就是个一个取一个
print(s[6:0:-1]) #反方向
#3.字符串拼接 +
print(s+b)
#print("名字是:"+s+"身高:"+c) #这里会报错不能拼接一个整型
#4.计算字符串的长度
print(len(s))
#5.判断是否包含某个字符 in
print(d in s)
输入输出函数
-
输出函数print
-
输入函数input
re.findall可以获取输入的数字字母和一些符号,得到的是一个列表
可以阻碍程序运行,可以接受一个字符串的变量
#name = input("请输入姓名:") #age = input("请输入年龄:") #print(f"姓名是:{name} 年龄是:{age}") num1 = input("请输入数字:") num2 = input("请输入数字:") print(num1+num2) #第二个的结果显示会将两个获取到的字符串拼接在一块,并不是将两个数字加到一块 #这是因为input获取到的数据类型为字符串 #如果想要实现将数字字符串转化为数字可以使用int(val) print(int(num1)+int(num2))
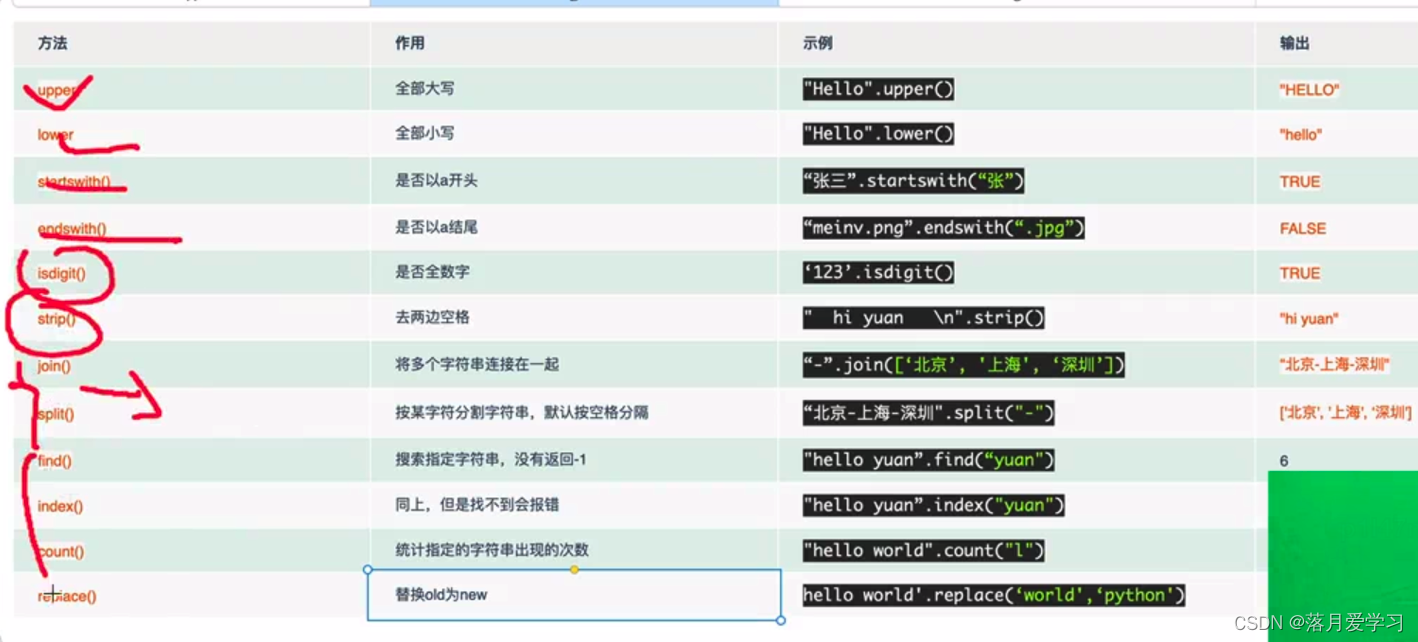
字符串的内置方法
内置方法:只能供一种数据类型使用的函数,别的数据类型使用不了的函数
使用内置方法会获取到一个新的值
| 方法名称 | 功能 |
|---|---|
| find(str, beg=0, end=len(string)) | 查找子串str第一次出现的位置,如果找到则返回相应的索引,否则返回-1 |
| rfind(str, beg=0,end=len(string)) | 类似于 find()函数,不过是从右边开始查找 |
| index(str, beg=0, end=len(string)) | 类似于find,只不过如果没找到会报异常 |
| rindex(str, beg=0 end=len(string)) | 类似于rfind,如果没有匹配的字符串会报异常 |
| upper | 将字符串中所有元素都转为大写 |
| lower | 将字符串中所有元素都转为小写 |
| swapcase | 交换大小写。大写转为小写,小写转为大写 |
| capitalize | 第一个大写,其余小写 |
| title | 每个单词的第一次字符大写,其余均为小写 |
| center(width, fillchar) | 返回一个指定的宽度 width 居中的字符串,fillchar 为填充的字符,默认为空格。 |
| ljust(width[, fillchar]) | 返回一个原字符串左对齐,并使用 fillchar 填充至长度 width 的新字符串,fillchar 默认为空格。 |
| rjust(width,[, fillchar]) | 返回一个原字符串右对齐,并使用fillchar(默认空格)填充至长度 width 的新字符串 |
| zfill (width) | 返回长度为 width 的字符串,原字符串右对齐,前面填充0 |
| split(seq=“”, num=string.count(str)) | 以 seq (默认空格)为分隔符截取字符串,如果 num 有指定值,则仅截取 num+1 个子字符串(只需num个seq分隔符)。分割后得到新列表 |
| rsplit | 与split类似,不过是从右边开始分割 |
| splitlines | 按照行进行分割,得到新的列表 |
| partition(str) | 找到字符串中第一个str,并以str为界,将字符串分割为3部分,返回一个新的元组 |
| rpartition(str) | 与partition类似,只不过是反向找 |
| join(seq) | 以指定字符串作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
| replace(old, new [, max]) | 把 将字符串中的 old 替换成 new,如果 max 指定,则替换不超过 max 次 |
| startswith(str) | 检查字符串是否以str开头,若是则返回true |
| endswith(str) | 检查字符串是否以str结尾,若是则返回true |
| count(sub, start= 0,end=len(string)) | 在字符串[start,end)范围内,计算sub字符串的个数 |
| len | len不是string的方法,是内置函数,计算字符串中的字符个数 |
| lstrip(str) | 去掉左边的str字符(不是字符串),默认为空白字符 |
| rstrip(str) | 去掉右边的str字符 |
| strip(str) | 去掉左右两边的str字符 |
| max(str) | 返回字符串 str 中最大的字母 |
| min(str) | 返回字符串 str 中最小的字母 |
运算符
#括号:
()
#幂运算:
**
#按位取反:
~
#正号、负号:
+、-
#乘、除、取模、取整除:
* 、/、 %、 //
#加、减:
+ 、-
#右移、左移:
>> 、<<
#按位 “与”:
&
#按位 “异或”,按位 “或”:
^ 、|
#比较运算符:
<= 、< 、>、 >=
#等于、不等于:
==、!=
#赋值运算符:
=、%=、/=、//=、-=、+=、*=、**=
#身份运算符:
is、is not
#成员运算符:
in、not in
#逻辑运算符:
and or not
# 虽然 Python 运算符存在优先级的关系,但写程序时不建议写很长的表达式,建议写程序时,遵守以下两点原则:
# 尽量不要把一个表达式写的过长过于复杂,如果计算过程的确需要,可以尝试将它拆分几部分来写。
# 尽量多使用 () 来控制运算符的执行顺序,使用 () 可以让运算的先后顺序变得十分清楚。
数据类型-list列表
定义
[]内以逗号分隔,按照索引,存放各种数据类型,每个位置代表一个元素
列表的特点
1.可以存放多个值
2.按照从左到右的顺序定义列表元素,下标从0开始访问,有序
3.可修改对应索引的值,可变
列表的操作
1.增加
-
增加-追加:数据追加到尾部
names = ['张三','里斯','王五'] names.append('wangmazi') names = ['张三','里斯','王五','wangmazi'] -
插入:可插入到任何位置
names = ['张三','里斯','王五'] names.insert(2,'xiaohu') names = ['张三','里斯','xiaohu','王五'] -
合并
names = ['张三','里斯','王五'] a = ['wangmazi'] a.extend(name) names = ['张三','里斯','王五','wangmazi'] -
列表嵌套
names = ['张三','里斯','王五']
a = ['wangmazi','lisi']
names.insert(2,a)
names = ['张三',['wangmazi','lisi'],'里斯','王五']
names[2][1] wangmazi
2.删除
- del删除,删除指定的下标元素
names = ['张三','里斯','王五']
del names[2]
names = ['张三','里斯']
- pop删除,默认删除最后一个元素并且返回他的值
names = ['张三','里斯','王五']
names.pop()
a = names.pop()
a = ['张三','里斯']
names = ['张三','里斯']
names.pop(1)
names = ['张三','王五']
- remove 删除从左开始找到的第一个指定的元素名称
names = ['张三','里斯','王五','里斯']
names.remove("里斯")
names = ['张三','王五','里斯']
- Clear 清除删除所有的元素
names = ['张三','里斯','王五','里斯']
names.clear()
names = []
3.查询操作
- index,返回找到第一个元素的下标
names = ['张三','里斯','王五','里斯']
a = names.index("lisi1")
a = 1
- Count ,统计元素的数量
names = ['张三','里斯','王五','里斯']
a = names.count("里斯")
a = 2
如何在不知道元素的位置的情况下,修改某个元素的值
-
首先判断这个元素是否在这个列表当中
item in list
2.取到这个元素的索引
itemindex = names.index("lisi")
- 替换该元素的值,给该下标重新赋予新的值
names[itemindex] = "王五"
4.切片操作
names = ['张三','里斯','王五','里斯']
names[0:2]
# ['张三','里斯'] 顾头不顾尾
names[0:3:2]
# ['张三','王五']步长为2
# 还可以倒着切
names[-1:-3]
#从左往右切的不能写成-3到-1
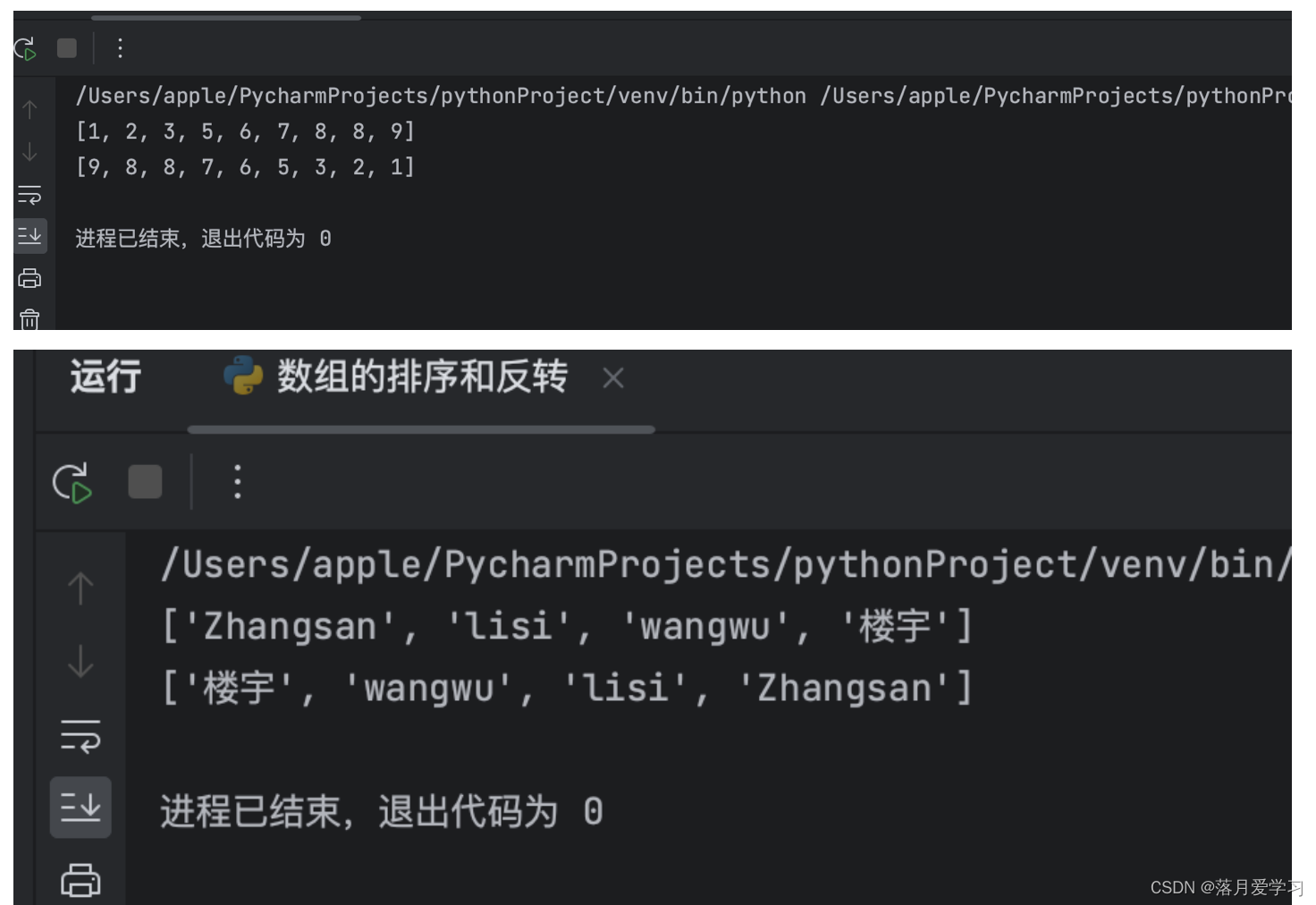
5.反转和排序
num = [9,8,8,6,7,1,3,5,2]
num.sort()
print(num)
num.reverse()
print(num)
# 如果是字母和中文组合,会优先大写字母小写字母然后在加中文
num = ['lisi','Zhangsan','wangwu','楼宇']
num.sort()
print(num)
num.reverse()
print(num)
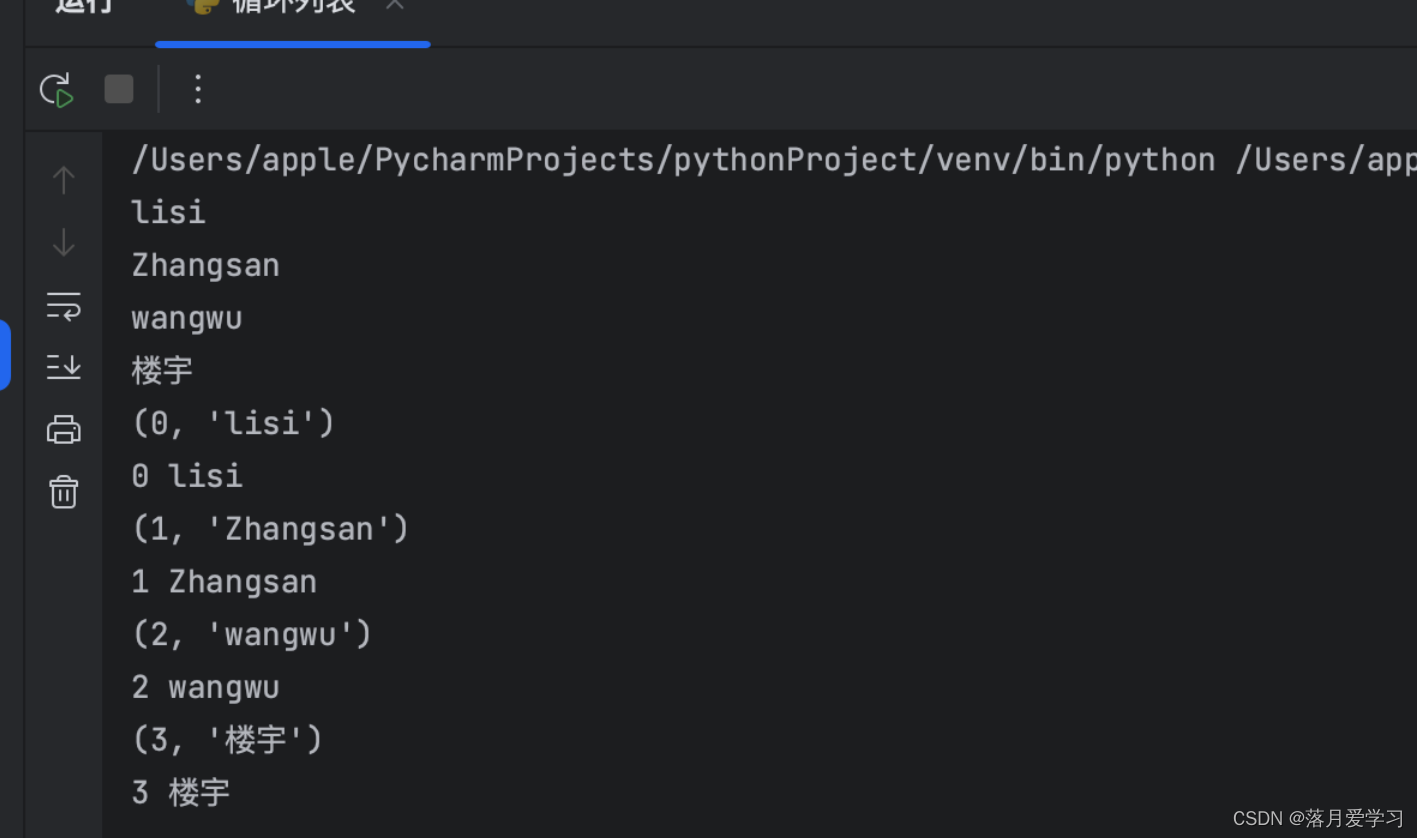
num = ['lisi','Zhangsan','wangwu','楼宇']
for i in num :
print(i)
# 获取索引和他的值
for b in enumerate(num) :
print(b)
print(b[0],b[1])
班级分组
如果在一个嵌套列表中添加数据要用到append而不是insert
grades = [
['章三',80],
['里斯',90],
['三洒家',50],
['章三ss',79],
['里斯de',69],
['三洒家e',58],
['efss',82],
['de',72],
['e',90],
]
new_grades = [
[],
[],
[],
[],
[],
]
# print (new_grades[0][1])
for i in grades :
if i[1] >= 90 :
print(i)
new_grades[0].append(i)
elif i[1] >= 80 and i[1] < 90 :
new_grades[1].append(i)
elif i[1] >= 70 and i[1] < 80:
new_grades[2].append(i)
elif i[1] >= 60 and i[1] < 70:
new_grades[3].append(i)
else:
new_grades[4].append(i)
print (new_grades)
数据类型-字典dist
grades = [
['章三',80,165,'男'],
['里斯',90,168,'女'],
['三洒家',50,170,'男'],
['章三ss',79,189,'男'],
...............
]
# 如果说班级上有1000多号人,我想找到某个人的分数,用列表的话,就要将列表全遍历一次这样就会很浪费资源,这个时候就要用到字典
grades ={
'章三' : [80,165,'男'],
}
定义
{Key : value,key1 : value1}
info = {
"names" : 'zhangsan'
"age" : 18
}
: 号左边是key,右边是value
特性
1.key-value结构
2.key必须为不可变数据类型 (字符串、数字) 、必须唯一
如果说key相同的话他会把前面的值覆盖掉
3.可存放任意多个value、可修改、可以不唯一
4.无序
5,查询速度快,目不受dict的大小影响,至于为何快? 我们学完hash再解释
增删改查操作
- 增加
grades ={
'章三' : [80,165,'男'],
}
grades['lisi'] = [80,165,'男']
print(grades)
- 删除
# 删除指定key
names .pop("alex”)
#删除指定key,同pop方法
del names["oldboy"]
#清空dict
names.clear()
- 修改
dict['key'] = 'new value'
# 如果key在字典中存在,,new value'将会替代原来的value值;
- 查操作
#返回字典中key对应的值,若key不存在字典中,则报错;
dic['key']
#返回字典中key对应的值,若key不存在字典中,则返回default的值, (default默认为None)
dic.get(key,defaultdefault = None)
#若存在则返回True,没有则返回
'key' in dic
#返回一个包含字典所有KEY的列表;
dic .keys( )
#返回一个包含字典所有value的列表;
dic.values()
#返回一个包含所有 (键,值) 元组的列表;
dic.itEms()
- 循环
1、 for k in dic.keys( )
2、for k,v in dic.items()
# 推荐用这种,效率速度最快
3、for k in dic
info = {
"name": "百度",
"mission": "百度一下就知道",
"website" : "https://www.baidu.com"
}
for k in info:
print(k,info[k])
快递分拣程序
message = [
['Bob','湖南省永州市'],
['Bob','广东省深圳市'],
['Eve','湖北省武汉市'],
['Alice','湖南省邵阳市'],
['里斯','河北省石家庄市'],
['Alice','河北省石家庄市'],
['王五','广东省深圳市'],
['张三','上海市'],
['张三','湖北省廖市'],
['Eve','四川省'],
]
messagedic = {
'湖南省':{
'永州市':[],
},
'广东省':[],
'湖北省':[],
'河北省':[],
'上海市':[],
'四川省':[],
}
for i in message :
if i[1][0:6] == '湖南省永州市' :
messagedic['湖南省']['永州市'].append(i)
elif i[1][0:3] == '广东省' :
messagedic['广东省'].append(i)
elif i[1][0:3] == '湖北省' :
messagedic['湖北省'].append(i)
elif i[1][0:3] == '河北省' :
messagedic['河北省'].append(i)
elif i[1][0:3] == '上海市' :
messagedic['上海市'].append(i)
else :
messagedic['四川省'].append(i)
print(messagedic)
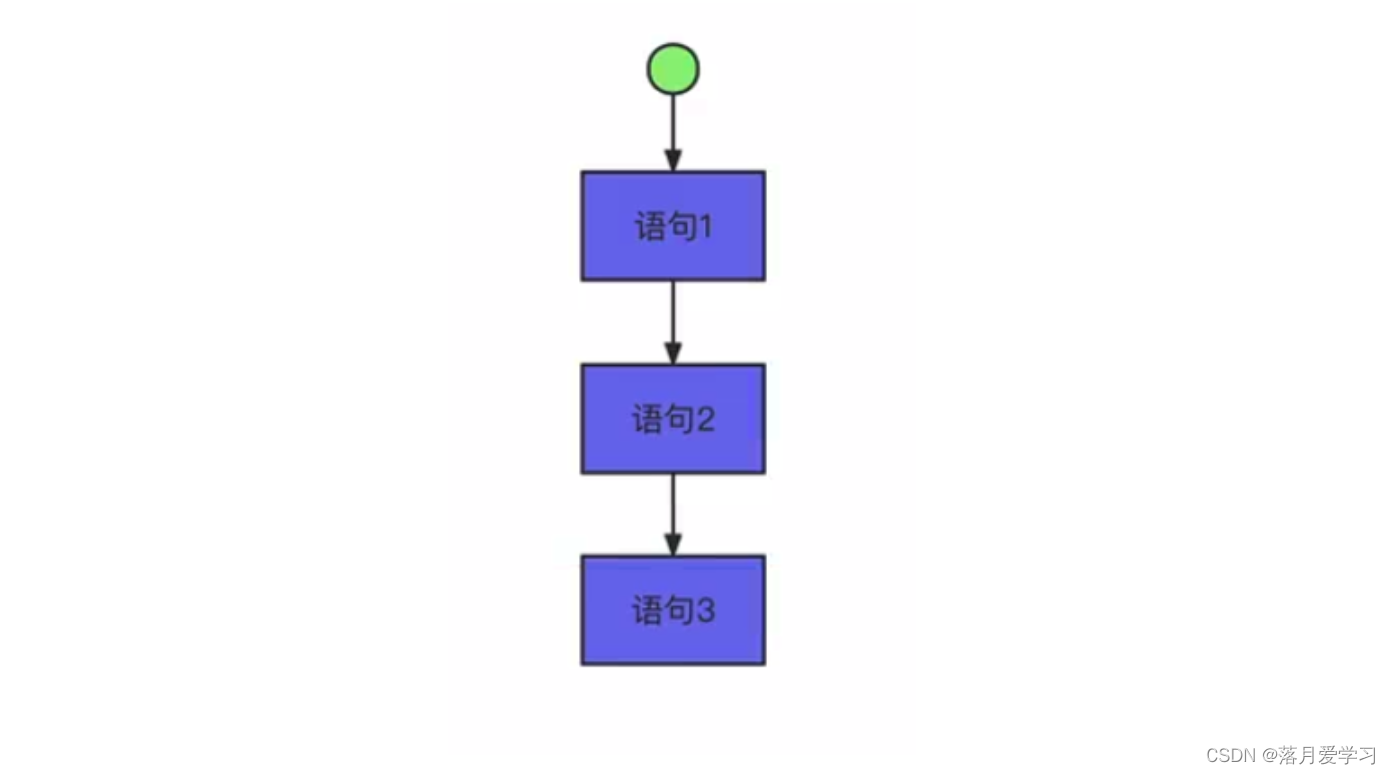
流程控制语句
顺序语句
从上往下依次执行有且执行一次
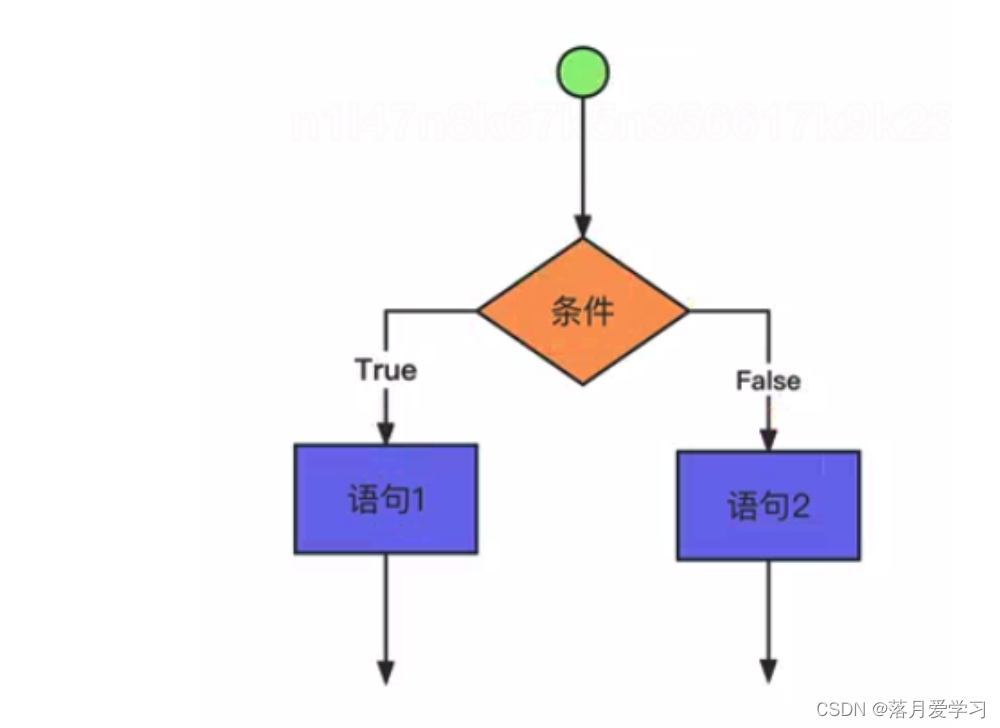
分支语句
- 双分支
if :
语句1
语句2 #语句2与语句1的缩进要保持一致不然会出现错误
else :
语句3
语句4 #语句4如果不跟语句3保持一致的话语句4将会作为分支外的一个语句按顺序执行
-
多分支
if : 语句1 语句2 #语句2与语句1的缩进要保持一致不然会出现错误 elif : 语句3 语句4 elif : 语句5 语句6 else : 语句7 语句8weight = float(input("请输入你的体重(kg):")) height = float(input("请输入你的身高(m):")) BMI = weight/(height*height) print(BMI) if BMI >= 28: print("你属于肥胖,请减肥") elif 28 > BMI >= 24: print("你属于超重,请注意") elif 24 > BMI >= 18.5: print("你属于正常,请继续保持") else: print("你属于偏瘦,请多吃一点")
- 分支嵌套
循环语句
- while循环
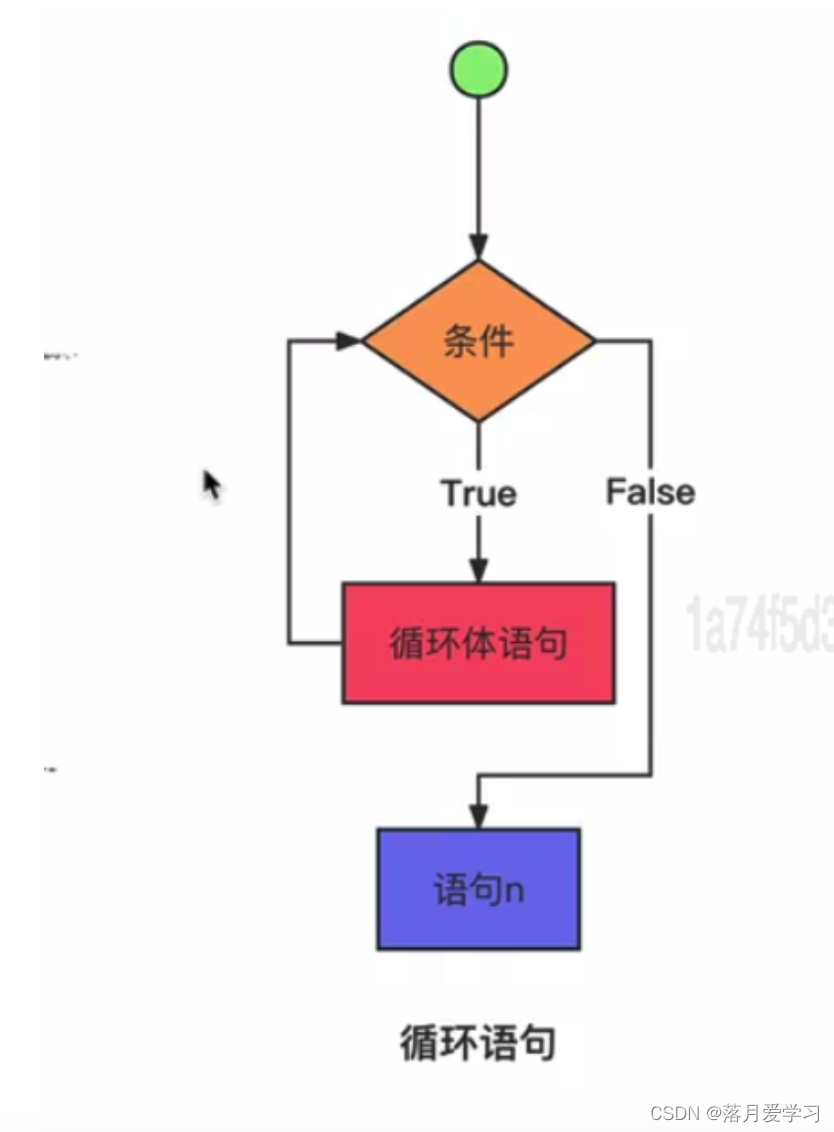
循环语句是一种编程语言的控制结构,用于在程序中重复执行一段代码,直到满足特定条件为止。循环语句可以帮助程序员简化重复性的任务,提高代码的可读性和效率。
count = 100
while count <= 100 and count>= 1 :
print(count)
count -= 1
有限循环的3个要素(初使变量,判断条件,步进语句)
- for循环
# 1.遍历字符串
strs = 'abcdefg'
for i in strs :
print(i)
# 2.遍历数组
num = [1,2,3,4,5,6,7]
for i in num :
print(i)
# 3.range函数 range(1,10) 只能取到9
num = range(1,10)
for i in num :
print(i)
#4.range函数进阶 range(startnum,endnum,step)
num = range (1,11,2)
for i in num :
print(i)
验证码的案例
# 引入一个生成随机数的函数
import random
# 引入一个生成字符串的函数
import string
#定义一个空的字符用来拼接字符
s = ""
#循环四次拼接四次
for i in range(4) :
#随机小写字母拼接大写字母拼接随机数字
randomnum =string.ascii_lowercase + string.ascii_uppercase + string.digits
#随机获取一个
allchar = random.choice(randomnum)
#拼接空的字符串得到新的字符串
s = s + allchar
print(s)
Join 列表拼接字符串
"".join(["a"+"b"+""c])
# random 获取0-9的随机数
random.randint(0,9)
偶数和
#偶数和
'''
sum = 0
for i in range (2,101,2) :
sum = sum +i
print(sum)
'''
#方案二
sum =0
for i in range (1,101):
if i%2 ==0 :
sum = sum + i
print(sum)
- Break退出循环
break退出整个循环
for i in range(1,11)
print(i)
break
print("end")

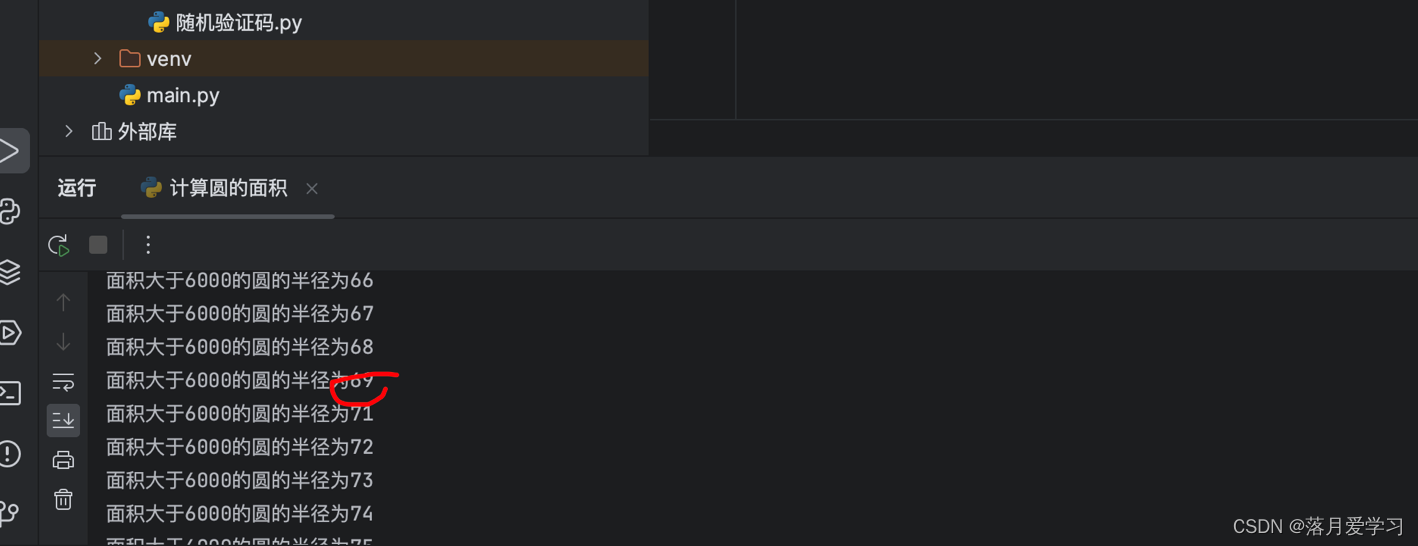
计算圆的面积的案列
# 计算1-100圆的面积
pai = 3.14
for r in range(1,101) :
s = pai * r**2
# print(f"半径为{r}的圆的面积为{s}")
#我想找到第一个面积大于6000的半径
if s > 6000 :
print(f"面积大于6000的圆的半径为{r}")
break
- continue退出当次循环
# 计算1-100圆的面积
pai = 3.14
for r in range(1,101) :
s = pai * r**2
# print(f"半径为{r}的圆的面积为{s}")
#我想找到第一个面积大于6000的半径
if s == 15386 :
#退出当次循环,当半径为170时面积等于6000
continue
print(f"面积大于6000的圆的半径为{r}")
print("end")
综合游戏案列
while 1 :
print('''进入游戏第一关你可以进行如下操作
1.增加等级
2.购买装备
3.攻击
''')
choose = int(input("请输入你的选择: "))
if choose == 1 :
print("你选择了增加等级")
elif choose == 2 :
print("你选择了购买装备")
elif choose == 3 :
print("你选择了攻击")
print('''是否继续进入第二关
1.经验装备不够继续第一关
2.进入第二关
''')
choose2 = int(input('请选择:'))
if choose2 == 1 :
print('已经回到第一关')
continue
print('''进入游戏第二关你可以操作一波了
1.击杀
2.回程
''')
choose1 = int(input("请输入你的选择: "))
if choose1 == 1:
print("你击杀了对手,干的漂亮")
elif choose == 2:
print("回程中")
break
print('游戏结束')
打印楼层房间号
for louceng in (1,5):
for i in range(1,22) :
fangjianhao = louceng*100+i
# louceng = "louceng" + "i"
print(f"所有的楼层房间号是:L{louceng}-{fangjianhao}")
打印三角形
for i in range(1,11):
if i <=5 :
print("*"*i)
elif i>5 :
print((10-i)*"*")
选择车牌号的案列
import random
import string
print('''
你已经进入选车牌程序,请你选择你的车牌号码
1.选择车牌
2.退出该系统
''')
userinput = int(input("请输入你的选择:"))
if userinput == 1:
print('进入系统')
print("请从下列车牌号中选择你想要的车牌号,你只能选择1个,有3次错误的选择机会")
count = 0
while count < 3:
#定义一个新的数组,供用户选择
carnumbers = []
for s in range(20):
#这个是用来选择一个随机的大写字母
car_num1 = random.choice(string.ascii_uppercase)
#这个是将5个随机字母数字拼接成一个字符串
car_num2 = "".join(random.sample(string.ascii_uppercase + string.ascii_lowercase + string.digits, 5))
#字符串拼接
car_num3 = f"京{car_num1}-{car_num2}"
#将结果追加到数组中供用户进行选择
carnumbers.append(car_num3)
print(car_num3)
#strip用来去除用户输入的结果中的空格和符号
chiose = input("请输入你喜欢的车牌号:").strip()
if chiose in carnumbers:
print(f"恭喜你选择了{chiose}")
break
else:
print("你选择了3次错误的号码,请明天再选择号码")
count = count + 1
elif userinput == 2:
print("成功退出系统")
年中抽奖程序
import random
people = list(range(1,300))
num = 0
while num<3:
print('''
选择抽奖类型
1.一等奖
2.二等奖
3.三等奖
''')
count = int(input('''
请输入:
'''))
if count == 1:
print("一等奖")
for d in range(3):
threepeople = random.choice(people)
print(f"恭喜{threepeople}获得了1等奖,你不可以再参与别的奖项了")
people.remove(threepeople)
print(
'''
一等奖已经抽完了,请继续抽别的奖项
'''
)
num += 1
elif count == 2:
print("二等奖")
for b in range(6):
threepeople = random.choice(people)
print(f"恭喜{threepeople}获得了2等奖,你不可以再参与别的奖项了")
people.remove(threepeople)
print(
'''
二等奖已经抽完了,请继续抽别的奖项
'''
)
num += 1
elif count == 3:
print("三等奖")
for s in range(30):
threepeople = random.choice(people)
print(f"恭喜{threepeople}获得了3等奖,你不可以再参与别的奖项了")
people.remove(threepeople)
print(
'''
三等奖已经抽完了,请继续抽别的奖项
'''
)
num += 1
print("所有的奖项都抽完了哟,goodluck")
python操作文件
编码
unicode 万国码
- 支持所有国家的语言
- 跟所有国家的编码有映射关系2-4字节来存一个字符
- 比ASCII编码,要多一倍。
- 为了优化unicode的占空间
- utf-8
英文占1个字节
西欧占2个
中文占3个
可变长的编码
存到文件里,或者网络发送,用utf-8但是在内存里,依然是unicode,这是py3的一个特点。
在py2里,内存里的字符,默认是ascii
mac Linux 默认系统编码是utf-8
windows中国版,默认是gbk
如何处理乱码
windows ,gbk发送到mac上怎么办? utf8在mac上正常显示
gbk—>utf-8
2 种办法
1、直接转成unicode
py3内存里所有字符都是unicode , unicode 是万国码
py3默认是utf-8
py2 ascii
2、转成utf-8
python操作文件流程
用word操作一个文件的流程如下:
1.找到文件,双击打开
2.读或修改
3.保存&关闭
用python操作文件也差不多
f=open(filename) # 打开文件
f.write("我是野生程序员”) # 写操作
f.read()#读操作
f.close()#保存并关闭
不过有一点跟人肉操作word文档不同,就是word文档只要打开了,就即可以读、又可以修改。
但python只能以读、创建、追加 3种模式中的任意一种打开文件,不能即写又读。
文件打开模式(文本模式)
- r 只读模式
- w 创建模式,若文件已存在,则覆盖旧文件
- a 追加模式,新数据会写到文件未尾
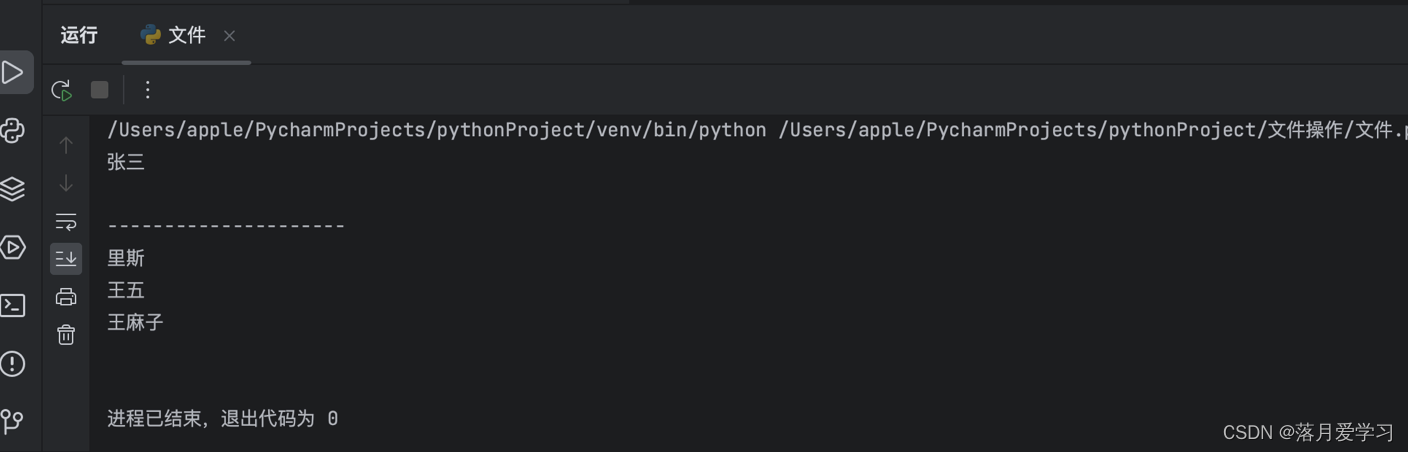
#f = open("name_list",mode='w')
#f.write('张三\n')
#f.write('里斯\n')
#f.write('王五\n')
#f.write('王麻子\n')
#f.close()
f = open("name_list",mode='r')
#f = open("name_list")
print(f.readline())
print("---------------------")
print(f.read())
循环文本
f = open("phone",'r')
# 循环文本
for line in f :
#将文本转换成列表
a = line.split()
if int(a[2]) >170 and int(a[3])<60 :
print(a)
如果操作得是图片或者是视频
这个时候要将图片或者视频以二进制的形式进行解析
# 可以用2进制模式打开文件
# rb 2进制只读模式
# wb 2进制创建模式,若文件已了在,则覆盖旧文件到文件未尾
# ab 2进制追加模式,新数据会写到文件末尾
# 这样,你读出来的数据,就是bytes字节类型了,当然写进去的也必须是bytes格
f = open("gbk file2","wb")
f.write("哈".encode("gbk”) )
# 写入的文本要用字节类型
其它功能
f.seek # 跳到任意位置修改
f.flush # 将文件强制刷新到硬盘中
f.tell # 返回当前文件光标操作的位置
文件打开模式(混合模式)
打开文件其实还有3种混合模式
w+ 写读,这个功能基本没什么意义,它会创建一个新文件,写一段内容,可以再把写的内容读出用。
r+ 读写,能读能写,但都是写在文件最后,跟追加一样。
a+ 追加读,文件 一打开时光标会在文件尾部,写的数据全会是追加的形式。
文件修改
当要替换或者是追加一些文字的时候,在python中他会把一些内容给覆盖掉,而不是挤出来一个位置
f =open("list_data",'r+')
#1.加载到内存
data = f.read()
new_data = data.replace("吉贝尔","路飞学城")
print(new_data)
# 2.清空文件
f.seek(0)
#截断文件
f.truncate()
# 3.把新内容写回硬盘f.write(new_data)
sys
sys.argv[]是一个列表
sys.argv[0]是被调用的脚本文件名或全路径
sys.argv[1:]之后的元素就是我们从程序外部输入的,而非代码本身的,想要看到它的效果,就要将程序保存,从外部运行程序并给参数,这也是我们在cmd里面运行的原因
全局检索文字并替换
import sys
print(sys.argv)
old_str = sys.argv[1]
new_str = sys.argv[2]
file_name = sys.argv[3]
f = open(file_name,'r+')
# 加载到内存
data = f.read()
new_data = data.replace(old_str,new_str)
old_strnum = data.count(old_str)
#清空文件的内容
f.seek(0)
f.truncate()
#重新把新的数据存贮起来
f.write(new_data)
函数
函数编程的作用
- 函数能够减少重复的代码
- 使程序变得可扩展
- 使程序变得易维护


函数的定义
函数是什么 ?
函数一词来源于数学,但编程中的函数概念,与数学中的函数是有很大不同的,具体区别,我们后面会讲,编程中的函数在英文中也有很多不同的叫法。在BASIC中叫做subroutine(子过程或子程序),在C中只有function 在Java里面叫做method 。
定义: 函数是指将一组语句的集合通过一个名字(函数名)封装起来要想执行这个函数,只需调用其函数名即可
函数的参数
1.形参
2.实参
在这里a,b是实参,x,y是形参
x,y相当于占位符,且只在函数内生效
def count(x,y) :
sum =x+y
print(sum)
a = 4
b = 5
count(a,b)
3.默认参数,默认参数意思是大多数都是这种情况,默认参数一定要写到最后面

4.关键参数(指定参数)
正常情况下,给函数传参数要按顺序,不想按顺序就可以用关键参数,只需指定参数名即可(指定了参数名的参数就叫关键参数),但记住一个要求就是,关键参数必须放在位置参数(以位置顺序确定对应关系的参数)之后

5.非固定参数
若你的函数在定义时不确定用户想传入多少个参数,就可以使用非固定参数
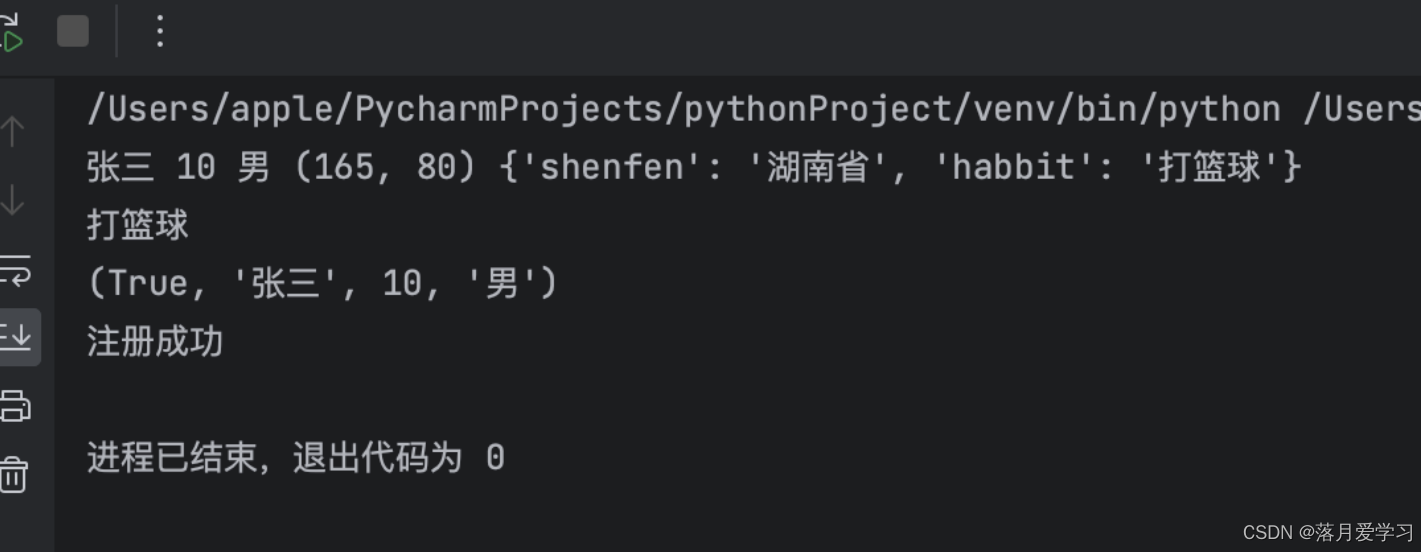
def count(name,age,sex,*args,**kwargs) :
print(name,age,sex,args,kwargs)
print(kwargs.get("habbit"))
# *args 获取到的值是一个列表
# *kargs 获取到的值是一个字典
# 获取到字典当中的值要用到get
count("张三",10,"男",165,80,shenfen = "湖南省",habbit = "打篮球")
函数的返回值
返回值return
函数外部的代码要想获取函数的执行结果,就可以在函数里用return语句把结果返回,外部获得结果判断是否注册成功,同时还能返回值
def count(name,age,sex,*args,**kwargs) :
print(name,age,sex,args,kwargs)
print(kwargs.get("habbit"))
if age>30 :
return False
else:
return True,name,age,sex
# *args 获取到的值是一个列表
# *kargs 获取到的值是一个字典
# 获取到字典当中的值要用到get
status = count("张三",10,"男",165,80,shenfen = "湖南省",habbit = "打篮球")
print(status)
if status :
print("注册成功")
else :
print("失败")
注意:
函数在执行过程中只要遇到return语句,就会停止执行并返回结果, 也可以理解为 return 语句代表着函数的结束,如果未在函数中指定return,那这个函数的返回值为None。
局部变量和全局变量
name = "张三"
def names() :
name = "里斯"
print(name,"是傻b")
names()
print(name,"是猪")
为什么在函数内部改了name的值后,在外面print的时候却没有改呢? 因为这两个name根本不是一回事
- 在函数中定义的变量称为局部变量,在程序的一开始定义的变量称为全局变量。
- 全局变量作用域(即有效范围)是整个程序,局部变量作用域是定义该变量的函数
- 变量的查找顺序是局部变量>全局变量
- 当全局变量与局部变量同名时,在定义局部变量的函数内,局部变量起作用;在其它地方全局变量起作用。
- 在函数里是不能直接修改全局变量的
列表和字典的特殊现象:函数可以修改列表和字典的全局变量的值,这是因为列表和字典就像一个口袋装着苹果,口袋和苹果都是独立的地址,所以说不能修改口袋,但是可以修改他们里面的值。
message = {
"name" : "张三",
"age" : 19,
"weight" : 165,
"sex" : "男"
}
list = ["里斯","20","170","女"]
def names() :
message["sex"] = "女"
list.append("打篮球")
print(message)
print(list)
names()
常用内置函数
| 内置函数名称 | 解析 |
|---|---|
| abs() | 取绝对值 |
| all() | 判断里面的值的布尔值所有的值为真时才为真 |
| bool() | 判断里面的值的布尔值 |
| any() | 是任意一个值为真 |
| chr() | 打应对应的ascall |
| dir() | 打印当前程序所有的变量名 |
| locals() | 打印当前程序所有的变量名和值 |
| map() | |
| ord() | 打印对应ascal码的数值 |
| zip() | 将两个列表随机配对 |
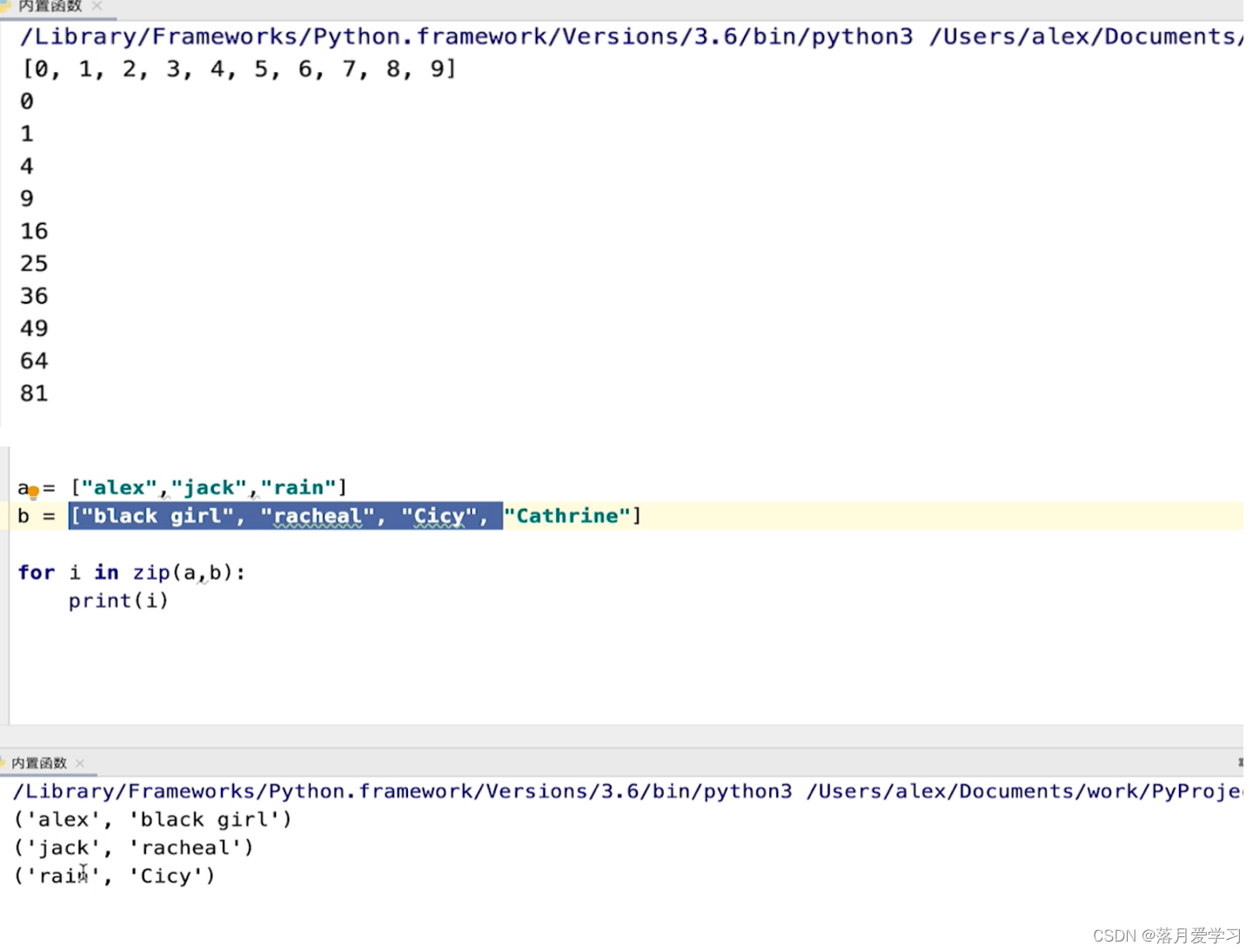
模块编程
模块和包
在Python中,模块(Modules)和包(Packages)是组织和管理代码的两个重要概念。
模块(Modules):
-
定义: 模块是一个包含Python代码的文件,它可以包含变量、函数和类等。在Python中,一个文件就是一个模块。
-
作用: 模块的主要作用是将代码组织成一个独立的单元,使代码更易于维护和复用。
-
使用: 通过使用
import关键字,可以在一个Python脚本或模块中引入另一个模块的功能。例如:pythonCopy code # 引入math模块 import math # 使用math模块的sqrt函数 result = math.sqrt(25) print(result)
模块一旦调用就相当于执行当前的文件
使用模块避免变量名冲突
模块的分类
- 内置标准模块(标准库)
- 第三方开源模块
- 自定义模块
自定义模块的引用
要用到sys模块

包(Packages):
-
定义: 包是一种用于组织模块的层次结构。一个包是一个包含特殊文件
__init__.py的目录,该文件通常为空。 -
作用: 包的主要作用是将相关的模块组织在一起,使得项目的结构更加清晰,也有助于避免命名冲突。
-
使用: 通过使用点操作符
.,可以从一个包中引入模块。例如:pythonCopy code # 引入包中的模块 import mypackage.mymodule # 使用模块中的函数 result = mypackage.mymodule.my_function()
总体而言,模块和包是Python中组织和管理代码的基本工具,它们有助于提高代码的可读性、可维护性,并促使开发者采用模块化的设计思想。
如何创建一个包?
只需要在目录下创建一个空的 initpy 文件,这个目录就变成了包。这个文件叫包的初始化文件,一般为空,当然也可以写东西,当你调用这个包下及其任意子包的的任意模块时, 这个 init ·py 文件都会先执行。
以下有a、b 2个包,a2是a的子包,b2是b的子包

import sys
print(sys.path)
from 文件操作.包.b import bmoudle
os模块
os 模块是Python标准库中的一个模块,用于与操作系统进行交互。它提供了许多与操作系统相关的功能,使得在不同平台上执行文件和目录操作变得更加方便。以下是 os 模块中一些常用功能的详细解释:
-
获取当前工作目录:
pythonCopy code import os current_directory = os.getcwd() print("Current Directory:", current_directory) -
改变当前工作目录:
pythonCopy code import os os.chdir("/path/to/new/directory") -
列出目录下的文件和子目录:
pythonCopy code import os files_and_dirs = os.listdir("/path/to/directory") print("Files and Directories:", files_and_dirs) -
创建目录:
pythonCopy code import os os.mkdir("/path/to/new/directory") -
递归创建目录:
pythonCopy code import os os.makedirs("/path/to/new/directory/with/subdirectories", exist_ok=True) -
删除目录:
pythonCopy code import os os.rmdir("/path/to/directory") -
递归删除目录及其内容:
pythonCopy code import shutil shutil.rmtree("/path/to/directory") -
重命名文件或目录:
pythonCopy code import os os.rename("old_name", "new_name") -
获取文件或目录的详细信息:
pythonCopy code import os file_info = os.stat("filename") print("File Info:", file_info) -
检查文件或目录是否存在:
pythonCopy code import os exists = os.path.exists("path/to/check") is_file = os.path.isfile("path/to/check") is_dir = os.path.isdir("path/to/check") -
拼接路径:
pythonCopy code import os path = os.path.join("path", "to", "file.txt")
sys模块
sys 模块是Python标准库中的一个模块,提供了与解释器相关的功能。它允许你访问和操作Python解释器的一些变量和功能。以下是 sys 模块中一些常用功能的详细解释:
-
获取Python解释器的版本信息:
pythonCopy code import sys print("Python Version:", sys.version) print("Python Version Info:", sys.version_info) -
获取命令行参数:
pythonCopy code import sys # 命令行参数是一个列表,其中第一个元素是脚本的名称 script_name = sys.argv[0] arguments = sys.argv[1:] print("Script Name:", script_name) print("Arguments:", arguments) -
修改默认的编码:
pythonCopy code import sys # 获取和设置默认编码 default_encoding = sys.getdefaultencoding() sys.setdefaultencoding('utf-8') # 注意: 在 Python 3 中,此方法已被移除 print("Default Encoding:", default_encoding) -
获取和设置最大递归深度:
pythonCopy code import sys max_recursion_depth = sys.getrecursionlimit() sys.setrecursionlimit(1500) print("Max Recursion Depth:", max_recursion_depth) -
退出程序:
pythonCopy code import sys sys.exit() # 退出程序,参数为退出码,默认为0表示成功,非0表示出错 -
清除模块缓存:
pythonCopy code import sys # 清除模块缓存,使得模块在下次导入时重新加载 sys.modules.clear() -
获取文件系统默认编码:
pythonCopy code import sys default_filesystem_encoding = sys.getfilesystemencoding() print("Default Filesystem Encoding:", default_filesystem_encoding) -
获取Python路径:
pythonCopy code import sys python_path = sys.path print("Python Path:", python_path)
time模块常用方法
time 模块是Python标准库中的一个模块,提供了与时间相关的功能。以下是 time 模块中一些常用的函数的解释:
-
获取当前时间戳:
pythonCopy code import time timestamp = time.time() print("Current Timestamp:", timestamp) -
将时间戳转换为时间元组:
pythonCopy code import time timestamp = time.time() time_tuple = time.gmtime(timestamp) # 或者使用 localtime() 获得本地时间 print("Time Tuple:", time_tuple) -
将时间元组转换为格式化的时间字符串:
pythonCopy code import time time_tuple = (2023, 11, 23, 12, 30, 0, 0, 0, 0) formatted_time = time.strftime("%Y-%m-%d %H:%M:%S", time_tuple) print("Formatted Time:", formatted_time) -
获取格式化的当前本地时间字符串:
pythonCopy code import time local_time_string = time.ctime() print("Local Time String:", local_time_string) -
休眠指定秒数:
pythonCopy code import time print("Sleeping for 2 seconds...") time.sleep(2) print("Awake!") -
获取CPU时间:
pythonCopy code import time cpu_time = time.process_time() print("CPU Time:", cpu_time) -
计算时间差:
pythonCopy code import time start_time = time.time() # 执行一些操作 end_time = time.time() elapsed_time = end_time - start_time print("Elapsed Time:", elapsed_time) -
计时器:
pythonCopy code import time with time.Timer() as timer: # 执行一些操作 print("Elapsed Time:", timer.elapsed)
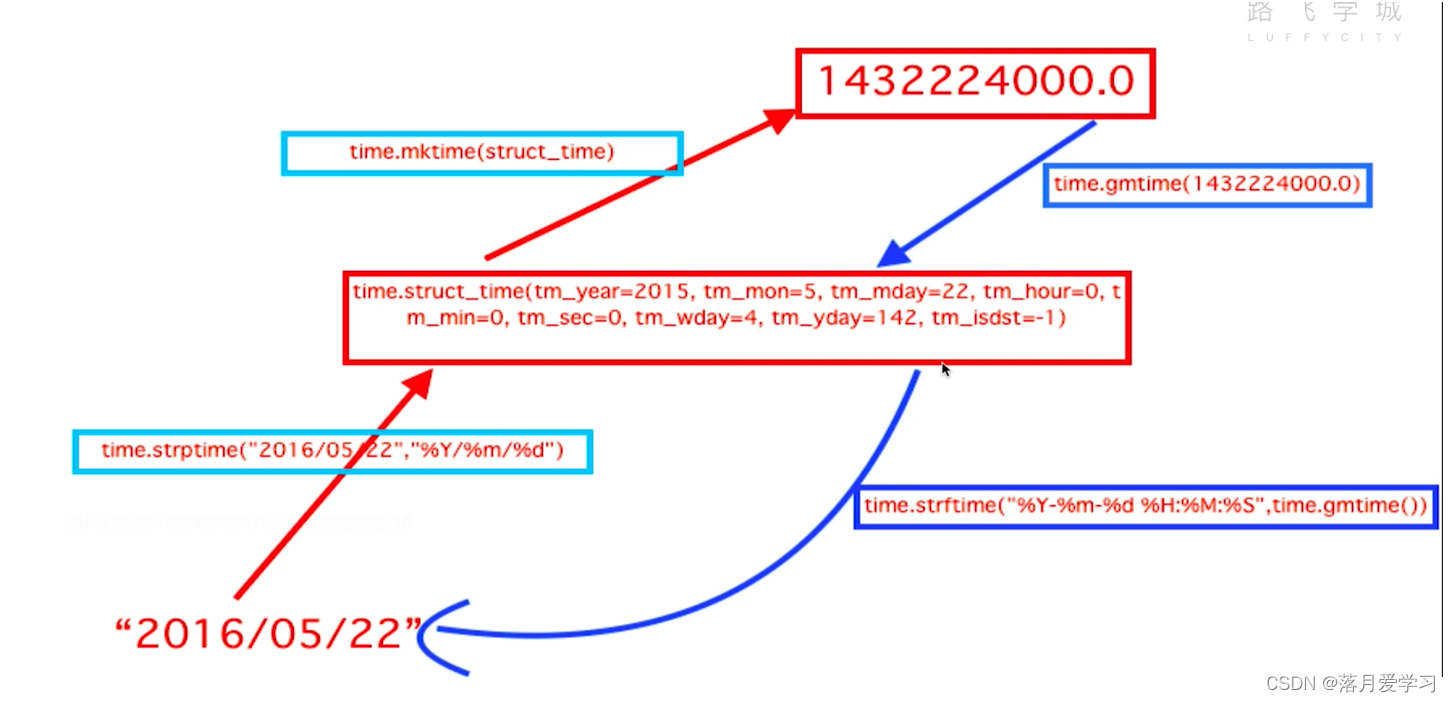
datetime模块
datetime 模块是Python标准库中用于处理日期和时间的模块。它提供了 datetime 类型,以及一些其他与日期时间相关的类和函数。以下是一些 datetime 模块的常用功能:
-
获取当前日期和时间:
pythonCopy code from datetime import datetime current_datetime = datetime.now() print("Current Datetime:", current_datetime) -
创建特定日期和时间的
datetime对象:pythonCopy code from datetime import datetime specific_datetime = datetime(2023, 11, 23, 12, 30, 0) print("Specific Datetime:", specific_datetime) -
从字符串解析日期和时间:
pythonCopy code from datetime import datetime date_string = "2023-11-23 12:30:00" parsed_datetime = datetime.strptime(date_string, "%Y-%m-%d %H:%M:%S") print("Parsed Datetime:", parsed_datetime) -
将
datetime对象格式化为字符串:pythonCopy code from datetime import datetime current_datetime = datetime.now() formatted_datetime = current_datetime.strftime("%Y-%m-%d %H:%M:%S") print("Formatted Datetime:", formatted_datetime) -
执行日期和时间的算术运算:
pythonCopy code from datetime import datetime, timedelta current_datetime = datetime.now() future_datetime = current_datetime + timedelta(days=7) print("Current Datetime:", current_datetime) print("Future Datetime:", future_datetime) -
获取
datetime对象的各个部分:pythonCopy code from datetime import datetime current_datetime = datetime.now() year = current_datetime.year month = current_datetime.month day = current_datetime.day hour = current_datetime.hour minute = current_datetime.minute second = current_datetime.second print("Year:", year) print("Month:", month) print("Day:", day) print("Hour:", hour) print("Minute:", minute) print("Second:", second) -
比较两个
datetime对象:pythonCopy code from datetime import datetime first_datetime = datetime(2023, 11, 23) second_datetime = datetime(2023, 11, 24) if first_datetime < second_datetime: print("First Datetime is earlier.")
random模块
random 模块是Python标准库中用于生成伪随机数的模块。它提供了多种生成随机数的函数,以及用于控制随机数生成过程的函数。以下是 random 模块中一些常用功能的详细解释:
-
生成随机浮点数:
pythonCopy code import random random_float = random.random() # 生成 [0.0, 1.0) 范围内的随机浮点数 print("Random Float:", random_float) -
生成指定范围内的随机整数:
pythonCopy code import random random_integer = random.randint(1, 10) # 生成 [1, 10] 范围内的随机整数 print("Random Integer:", random_integer) -
从序列中随机选择一个元素:
pythonCopy code import random my_list = [1, 2, 3, 4, 5] random_element = random.choice(my_list) print("Random Element:", random_element) -
打乱序列中的元素顺序:
pythonCopy code import random my_list = [1, 2, 3, 4, 5] random.shuffle(my_list) print("Shuffled List:", my_list) -
生成具有正态分布的随机数:
pythonCopy code import random mean = 0 standard_deviation = 1 random_normal = random.gauss(mean, standard_deviation) print("Random Normal:", random_normal) -
生成随机实数:
pythonCopy code import random random_float = random.uniform(1.0, 2.0) # 生成 [1.0, 2.0) 范围内的随机实数 print("Random Float:", random_float) -
生成随机字符串:
pythonCopy code import random import string random_string = ''.join(random.choice(string.ascii_letters) for _ in range(5)) print("Random String:", random_string) -
设置随机数种子:
pythonCopy code import random random.seed(42) # 设置随机数种子,使得随机数可复现
excel文件处理
首先在pycharm中安装openpyxl
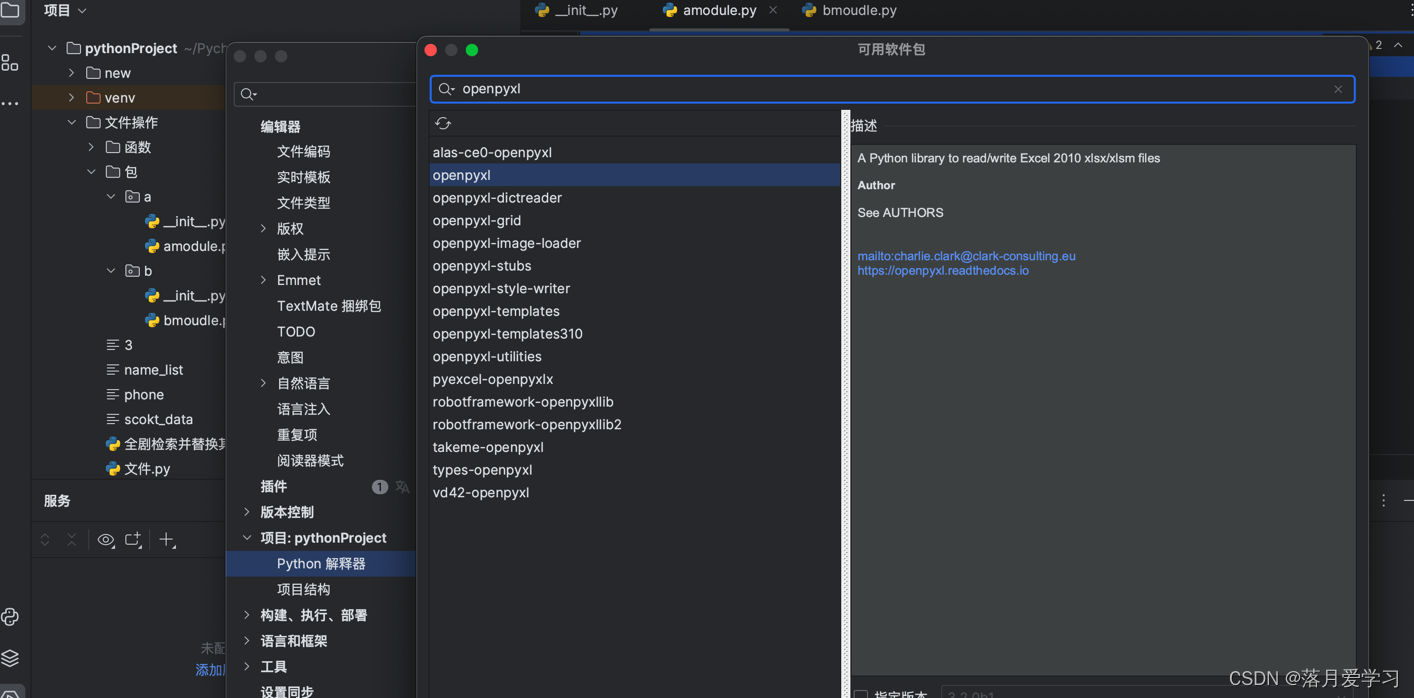
打开文件
1.创建表格
from openpyxl import Workbook
# 实例化
wb = Workbook()
# 获取当前active的sheet
ws = wb.active
print(ws)
print(ws.title) # 打印sheet表名
# 改sheet 名
ws.title ="salary"
print(ws.title)
# 保存xlsx
wb.save('salary.xlsx')
2.打开已有的表格
from openpyxl import Workbook,load_workbook
wb = load_workbook("salary.xlsx")
3.添加数据
- 方式一添加到单元格中
from openpyxl import Workbook,load_workbook
# 实例化
wb = Workbook()
# 获取当前active的sheet
ws = wb.active
print(ws)
print(ws.title) # 打印sheet表名
# 改sheet 名
ws.title ="salary"
#往表格里面添加数据
ws["A1"] = "1111"
ws["B1"] = "哈哈哈"
print(ws.title)
# 保存xlsx
wb.save('salary.xlsx')
- 方式二可以附加行,从第一列开始加(从最下方空白处,最左开始,可以输入多行)
ws.append([1,2,3])
ws.append(["black","2","3"])
- python类型会自动被转换
sheet['A3'] = datetime.datetime.now().strftime("%Y-%m-%d")
python发送邮件
想实现发送邮件需经过以下几步:
1.登录 邮件服务器
2.构造符合邮件协议规则要求的邮件内容 (email模块)
3.发送
Python对SMTP支持有 smtplib和emai1 两个模块,email负责构造邮件,smtplib 负责发送邮件,它对smtp协议进行了简单的封装。。
import schedule
import time
import smtplib
from email.mime.text import MIMEText
from email.header import Header
def send_email():
sender = '2263393389@qq.com' # 发送邮箱
receivers = ['1225691076@qq.com'] # 接收邮箱
auth_code = "ftxmodpsgtwheadg" # 授权码
message = MIMEText('小哥哥,你好呀,我这啥都有', 'plain', 'utf-8')
message['From'] = Header("Sender<%s>" % sender) # 发送者
message['To'] = Header("Receiver<%s>" % receivers[0]) # 接收者
subject = '美女荷官在线发牌'
message['Subject'] = Header(subject, 'utf-8')
try:
server = smtplib.SMTP_SSL('smtp.qq.com', 465)
server.login(sender, auth_code)
server.sendmail(sender, receivers, message.as_string())
print("邮件发送成功")
server.close()
except smtplib.SMTPException as e:
print(f"Error: 无法发送邮件 - {e}")
# 定义定时任务,每天的固定时间执行发送邮件的函数
schedule.every(10).seconds.do(send_email) # 每隔十秒执行任务
#schedule.every().day.at("09:00").do(send_email) 每天9点发送
# 主循环
while True:
schedule.run_pending()
schedule使用文档
https://schedule.readthedocs.io/en/stable/installation.html
装饰器
作用
装饰器就是在不改变原有功能代码的基础上,增加新的功能
def wrapper(fn): #fn是你要装饰的函数
def inner(*args,**kwargs): #innner可以装饰各种参数
print("你已登录成功")
ret = fn (*args,**kwargs)
return ret #返回结果
return inner
def add():
print("添加一个文件")
def select():
print("查询文件")
def modify():
print("修改文件")
add = wrapper(add) #从这里开始add变成wrapper的inner
add() #inner
装饰器的使用和传参数
def wrapper(fn): #fn是你要装饰的函数
def inner(username,password,key): #innner可以装饰各种参数
print("你已登录成功")
ret = fn (username,password,key)
return ret #返回结果
return inner
#这才是装饰器的写法
@wrapper
def add(username,password,key):
print("添加一个文件",username,password,key)
def select():
print("查询文件")
def modify():
print("修改文件")
#add = wrapper(add) #从这里开始add变成wrapper的inner
#add() #inner
#传递参数
add("haha","1231444","11")
如果有两个方法都要使用到这个装饰器,涉及到的参数数量不一样这个时候就不能独立传参,要使用到arg以及kwarg这两个参数。
def wrapper(fn): #fn是你要装饰的函数
# arg位置参数,kwargs字典
def inner(*args,**kwargs): #innner可以装饰各种参数
print("你已登录成功")
ret = fn (*args,**kwargs)
return ret #返回原函数的结果
return inner
@wrapper
def add(username,password,key):
print("添加一个文件",username,password,key)
@wrapper
def select(username,password):
print("查询文件")
def modify():
print("修改文件")
#add = wrapper(add) #从这里开始add变成wrapper的inner
#add() #inner
add("haha","1231444","11")
select("垃圾",'123')
设置一个状态位,就不用每次都要去登录
flag = False
def login():
global flag
while 1:
username = input("请输入用户名:")
password = input("请输入密码:")
if username == 'admin' and password == 'password':
print("登录成功")
flag = True
break
else :
print("请重新登录")
def wrapper(fn): #fn是你要装饰的函数
def inner(*args,**kwargs): #innner可以装饰各种参数
if flag == False :
login()
ret = fn (*args,**kwargs)
return ret #返回结果
return inner
@wrapper
def add(username,password,key):
print("添加一个文件",username,password,key)
@wrapper
def select(username,password):
print("查询文件",username,password)
def modify():
print("修改文件")
#add = wrapper(add) #从这里开始add变成wrapper的inner
#add() #inner
add("haha","1231444","11")
select("垃圾",'123')
迭代器
标准
特点:
1、只能向前,不能反复
2、只能使用一次。一旦取完最后一个结果继续取会报错StopIteration
3、特别省内存。(结合生成器来看)
4、惰性机制(必须调用__next_)才会获取数据
统一了一些数据类型的循环方式。
优点是:特别省内存
list,dict,set, tuple, str
__iter__ -> 获取迭代器
所有的迭代器都可以执行一个的功能意思是从迭代器中获取到下一个数据
__next__
能够遍历:但是只能向前不能往后,一次性的再取就是报错了
如果一个数据有____iter____我们称这个数据为可迭代对象
如果一个数据有____next____我们称这个数据为迭代器
#list = [1,2,3,4,5,6].__iter__()
#print(list.__next__())
#这个其实就是for循环的原理
def xunhuan(data):
from collections_abc import Iterable
if isinstance(data,Iterable): #判断这个数据是否为可迭代数据
it = data.__iter__()
while 1:
# 这里用到太try来试图运行这个代码
try:
print(it.__next__())
# 这里是截取错误信息
except StopIteration as e: # 错误的类型赋值为一个变量
print("报错了")
break
xunhuan([11,22,33,44,55])
生成器
生成器函数
函数中如果包含了yield,通过yield来返回数据的话。这个函数就是生成器函数
def fun():
yield 111
特点:fun()这个时候不是在运行函数,这个时候是在创建生成器
def fun():
print("你是猪")
yield 111
print("哈哈哈")
yield 222
it = fun()
print(it.__next__()) # it generator 生成器
#这样才会返回函数的返回值
#生成器的本质就是迭代器
print(it.__next__())
#像这样操作存进列表会开辟空间会占用内存,数据量大了就不好了
list = []
for num in range(10) :
list.append(num)
print(list)
list1 = []
def addlist1 ():
for i in range(15):
yield i
num1 = addlist1() #这个是生成器,本质是迭代器,也可以进行循环
#这样向列表里添加数据是不会占用空间的,可以节省内存
for a in num1 :
list1.append(a)
print(list1)
生成器的推导式和表达式
推导式
list = []
for i in range(10):
list.append(i)
print(list)
#这个就是推导式
#第一位就是你要往列表里追加的值
#第二位就是循环
#第三位就是条件
#列表推导式 list = [结果 for循环 if条件]
#字典推导式 dict = {key:value for循环 if条件}
#集合推导式 sun = {key for循环 if条件}
list1 = [i for i in range(10) if i%2 == 0]
print(list1)
元组没有推导式
表达式
#生成器表达式
# list = (结果 for循环 if条件)
list2 = (i for i in range(10) if i%2 == 0)
for a in list2:
print(a)
#这样子写不会占内存
面试题
def fun ():
print(111)
yield 222
g = fun() #生成器
g1 = (i for i in g) #生成器
g2 = (i for i in g1)
#无论一什么样的顺序,都是找g把g拿空了就没有了
print(list(g))
print("--------")
print(list(g1))
print("--------")
print(list(g2))

lambda表达式
lambda表达式相当于一个简单的函数,复杂的函数不建议用lambda表达式
lambda表达式其实是一个匿名函数,要将这个函数赋值给一个变量,这样才能调用
#格式 : 函数名 = lambda 变量名1,变量名2,变量名3 :返回值
fun = lambda a,b : a+b
print(fun(1,2))
一般会结合内置函数(已经声明给你的可以直接调用)使用
filter 筛选的
#filter 用来实现筛选
lis = ["苹果","栗子","西红柿",'蓝莓','车厘子']
def se(item) :
return len(item) == 2
#在这个函数里面是将可迭代对象中的元素一个一个传进去
f = filter(se,lis) #list 是iterable可迭代的对象
#filter其实是生成器,要调用一下才会往下运行
print(list(f))
#格式 : 函数名 = lambda 变量名1,变量名2,变量名3 :返回值
#fun = lambda a,b : a+b
#print(fun(1,2))
#filter 用来实现筛选
lis = ["苹果","栗子","西红柿",'蓝莓','车厘子']
#def se(item) :
# return len(item) == 2
#在这个函数里面是将可迭代对象中的元素一个一个传进去
#f = filter(se,lis) #list 是iterable可迭代的对象
#filter其实是生成器,要调用一下才会往下运行
#filter需要两个参数,一个是函数,一个是可迭代对象
#函数可用lambda来实现
f = filter(lambda item:len(item) == 2,lis) #list 是iterable可迭代的对象
print(list(f))
map
sorted














 63万+
63万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









