






from sklearn.feature_extraction import DictVectorizer
data=[{'city':'北京','temperature':100},{'city':'上海','temperature':40},{'city':'广东','temperature':50},{'city':'南昌','temperature':20}]
#实例化一个转换器
transfer=DictVectorizer()
#调用fit_transform()
data_new=transfer.fit_transform(data)
print('特征名字\n',transfer.get_feature_names_out())
print('data_new\n',data_new)注意观察没有加上sparse=False参数的结果
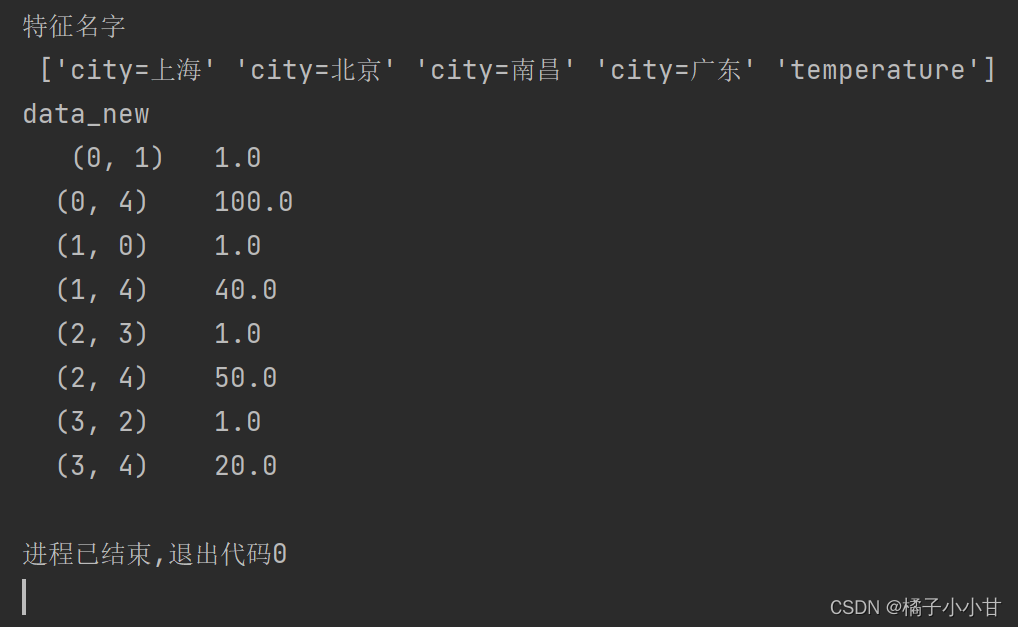
返回的是稀疏矩阵,这并不是我们想要看到的,所以加上参数,得到想要的结果
from sklearn.feature_extraction import DictVectorizer
data=[{'city':'北京','temperature':100},{'city':'上海','temperature':40},{'city':'广东','temperature':50},{'city':'南昌','temperature':20}]
#实例化一个转换器
transfer=DictVectorizer(sparse=False)
#调用fit_transform()
data_new=transfer.fit_transform(data)
print('特征名字\n',transfer.get_feature_names_out())
print('data_new\n',data_new)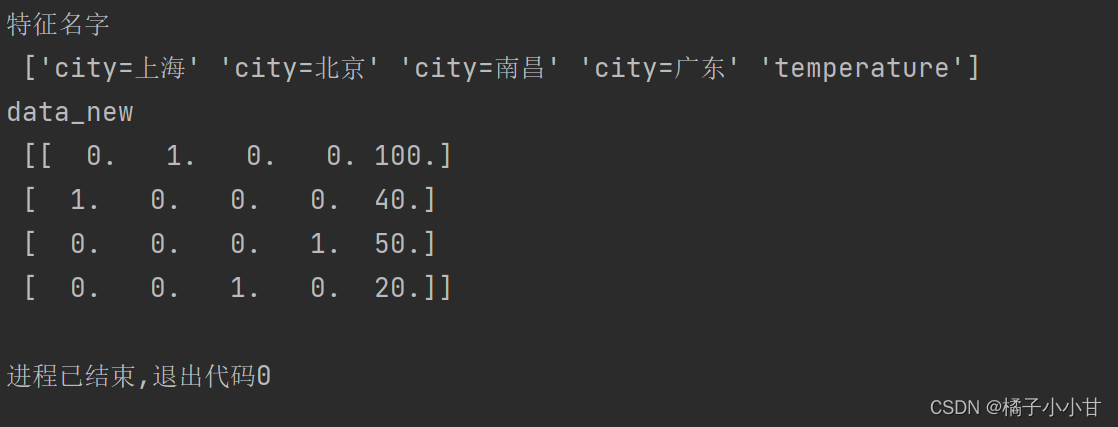
















 515
515











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











