






1.定义
如果一个样本在特征空间中的K个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别
以图为例,若要确定圆圈的位置,以KNN思想即是对比与其他位点的距离,选取K个最近的,这K个中大多数是属于什么类别,则圆圈也属于什么类别
2.距离公式
两个样本的距离可以通过如下公式计算,又叫欧式距离
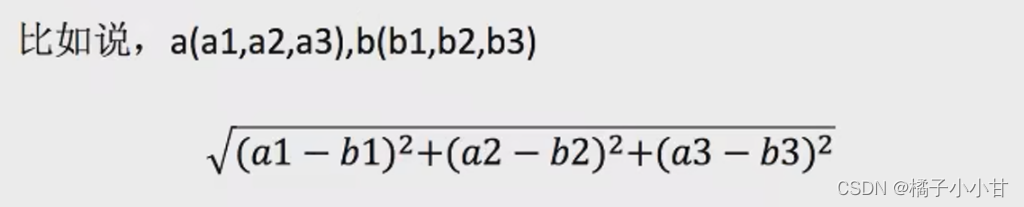
3.电影类型分析
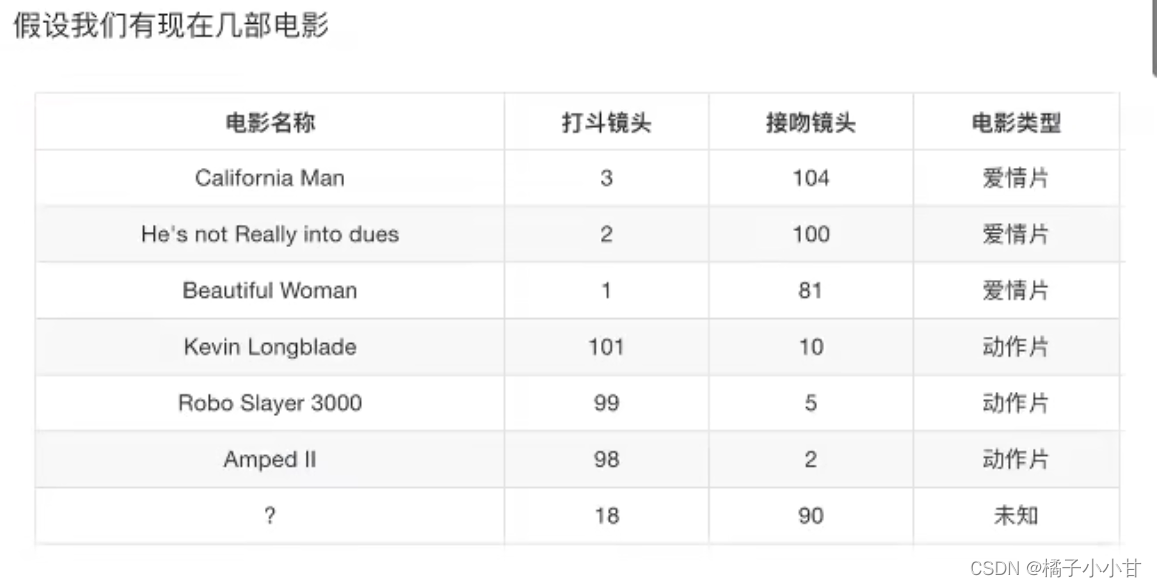
要确定未知电影类型,利用KNN算法,首先需要比对与各点的距离,具体比对结果如下

若设置K=1,选取距离最近的电影,划分为爱情片
若设置K=2,选取距离最近的两部电影,划分为爱情片
若设置K=3,选取距离最近的三部电影,划分为爱情片
若设置K=4,选取距离最近的四部电影,划分为爱情片
若设置K=5,选取距离最近的五部电影,划分为爱情片
若设置K=6,选取距离最近的六部电影,无法划分
若另外再加一部动作片且选取K为7的话,未知电影将会被划分为动作片
K值取得过小时,容易受到异常值的影响,K值取得过大时,容易受到样本不均衡的影响
4.以鸢尾花种类预测案例实际说明
案例具体步骤
- 获取数据
- 数据集划分
- 特征工程-标准化
- KNN预估器流程
- 模型评估
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
#(1)获取数据
iris=load_iris()
#(2)数据集划分
x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target,random_state=6)
#(3)特征工程-标准化
transfer=StandardScaler()#实例化
x_train=transfer.fit_transform(x_train)
x_test=transfer.transform(x_test)
#(4)KNN预估器流程
estimator=KNeighborsClassifier(n_neighbors=3)#设置K=3
estimator.fit(x_train,y_train)#进行模型训练
#(5)模型评估
#方法1:直接比对真实值和预测值
y_predict=estimator.predict((x_test))
print('y_predict:\n',y_predict)
print("直接对比真实值和预测值:\n",y_test==y_predict)
#方法2:计算准确率
score=estimator.score(x_test,y_test)
print('准确率为:\n',score)输出结果
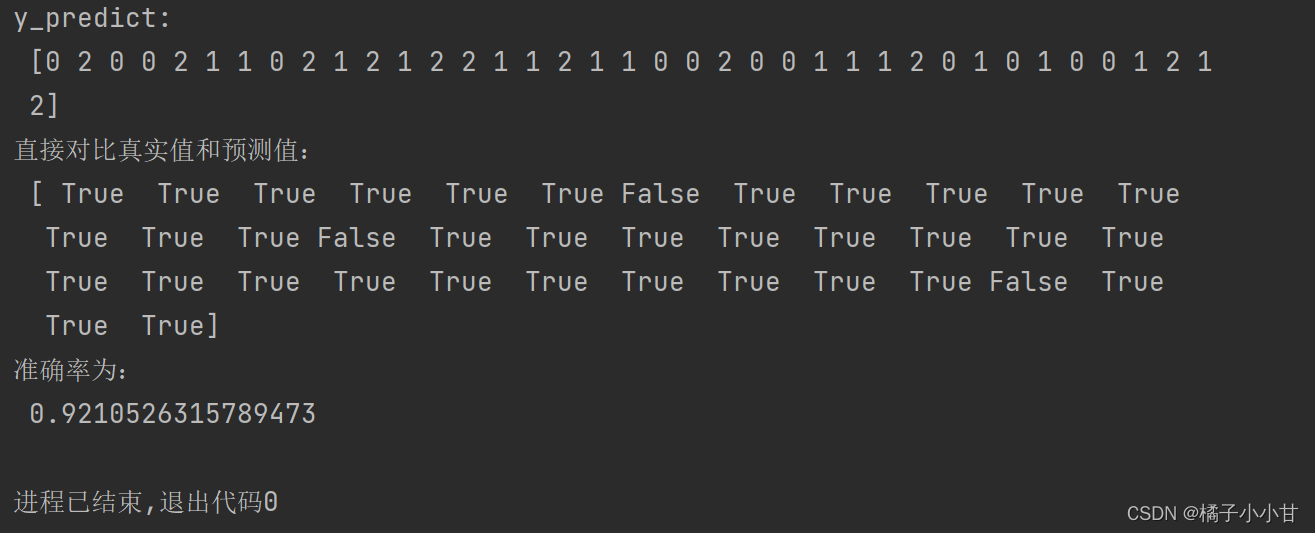
通过调整不同的K值,会得到不同的准确结果
#(4)KNN预估器流程
estimator=KNeighborsClassifier(n_neighbors=4)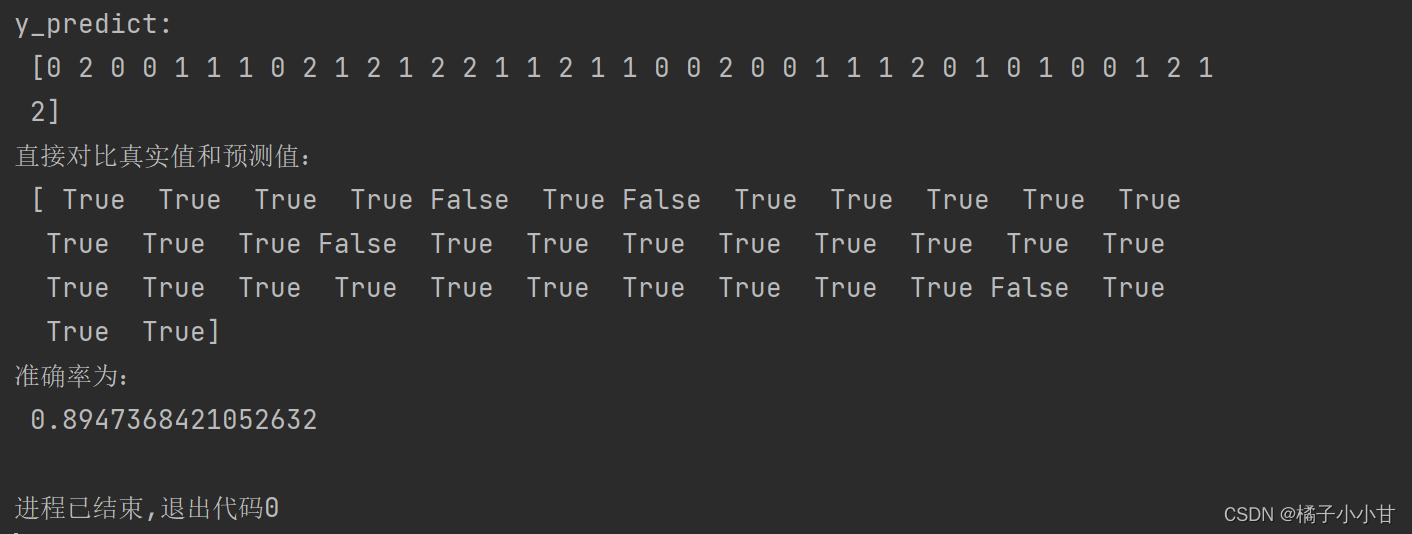
同样的,在设置K=4,修改不同的测试集比例,也会得到不同的结果
#(2)数据集划分
x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target,test_size=0.2,random_state=6)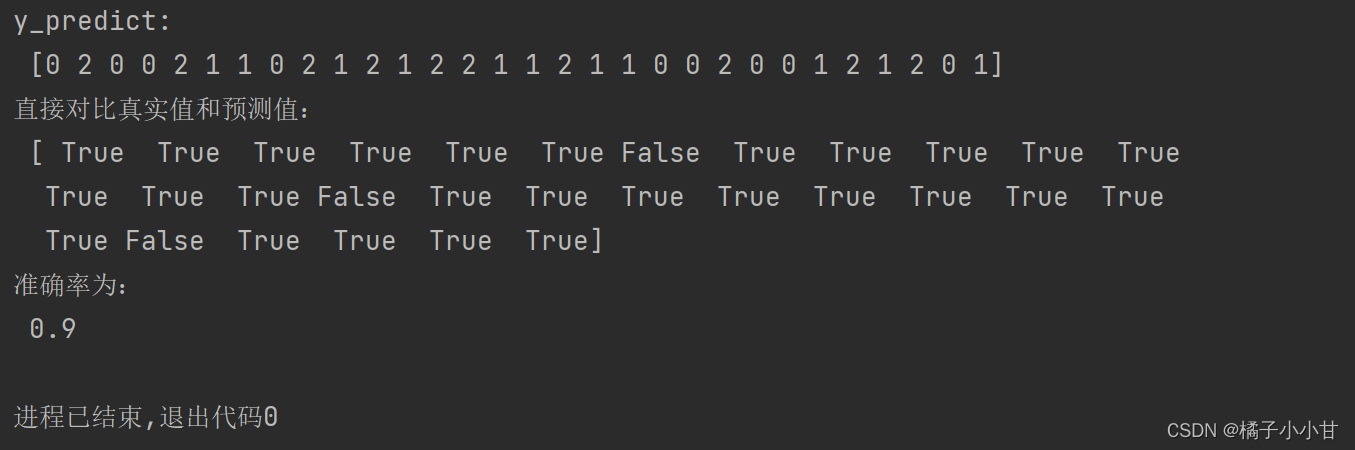
此处对x_train,x_test,y_train,y_test做具体解释
- train_test_split()是sklearn包的model_selection模块中提供的随机划分训练集和测试集的函数;使用train_test_split函数可以将原始数据集按照一定比例划分训练集和测试集对模型进行训练
- x,y是原始的数据集。X_train,y_train 是原始数据集划分出来作为训练模型的,fit模型的时候用。
- X_test,y_test 这部分的数据不参与模型的训练,而是用于评价训练出来的模型好坏,score评分的时候用。
- test_size=0.2 测试集的划分比例。如果为浮点型,则在0.0-1.0之间,代表测试集的比例;如果为整数型,则为测试集样本的绝对数量;如果没有,则为训练集的补充。
- random_state:是随机数的种子。固定随机种子时,同样的代码,得到的训练集数据相同。不固定随机种子时,同样的代码,得到的训练集数据不同。
————————————————
以上解释转载自原文链接:https://blog.csdn.net/skyejy/article/details/90647363
5.K-近邻总结
- 优点
简单,易于理解,易于实现,无需训练
- 缺点
- 懒惰算法,对测试样本分类时的计算量大,内存开销大
- 必须指定K值,K值选择不当则分类精度不能保证
- 使用场景
小数据场景,几千~几万样本,具体场景具体业务去测试
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











