







回顾,上节课我们学了什么?
聚焦爬虫
数据解析方式分类:正则表达式;bs4模块;xpath模块
F12查看网页标签的html格式
正则表达式详细表示方法
正则匹配
import re
list=re.findall(pattern,string,flags)
创建文件夹
爬取和保存页面所有图片格式
目录
1.聚焦爬虫:爬取页面中指定的页面内容。
2.编码流程:
- 指定url
- 发起请求
- 获取响应数据
- 数据解析
- 持久化存储
3.数据解析方式分类:
- 正则表达式正则表达式的语法汇总_神奇洋葱头的博客-CSDN博客_正则表达式 结束符
- bs4模块Python中BeautifulSoup库的用法_阎_松的博客
- xpath模块
4.bs4数据解析原理概述:
解析的局部的文本内容都会在标签之间或者标签对应的属性中进行存储,列如图片在<img>标签中,列表数据在<li>标签中
bs4数据解析的原理;
1.实例化一个BeautifulSoup对象,并且将页面源码数据加载到该对象中
2.通过调用BeautifulSoup对象中相关的属性或者方法进行标签定位和数据提取
5.bs4安装
(1)终端输入
pip install bs4
pip install lxml#数lxml据解析(2)pycharm包管理器安装
6.bs4数据解析步骤
(1)导入bs4的BeautifulSoup模块
from bs4 import BeautifulSoup(2)对象的实例化:
1.将本地的html文档中的数据加载到该对象中;
soup=BeautifulSoup(filePath,‘lxml’)
2.将互联网上获取的页面源码加载到该对象中;
soup=BeautifulSoup(page_text,‘lxml’)
(3)bs4查找 标签定位
(4)标签内容的处理保存
7.bs4代码API
#导入bs4的BeautifulSoup模块
from bs4 import BeautifulSoup
#BeautifulSoup对象实例化 html文档解析
soup=BeautifulSoup(response,‘lxml’)
soup:实例化对象
response: html数据 本地文件或者爬虫爬取的页面
#标签定位
soup.tagName#返回第一个tagName标签的整体html
tagName:标签的名称可以为a,p,img,div等
soup.find(‘tagname’,attrName=‘value’)#返回第一个找到标签的整体html
tagname:标签名
attrName:标签属性名
value:标签属性值
list=soup.find_all(‘tagname’,attrName=‘value’)#返回所有找到标签的整体html
list=soup.select(‘CSS格式选择器’)’)#返回所有找到标签的整体html
#获取标签内的文本
获取该标签中所有内容
soup.tagName.text
soup.tagName.get_text()
获取该标签中直系内容
soup.tagName.string
#获取标签中的属性值
soup.tagName['attrName']
8.bs4应用 爬取笔趣阁文章的所有内容
网站网址:饲养全人类最新章节无弹窗_小说饲养全人类免费阅读全文_笔趣阁
(1)目标:爬取目录下的每个章节超链接组成的整篇文章
(2)打开F12 查看目录页的每一篇目录格式
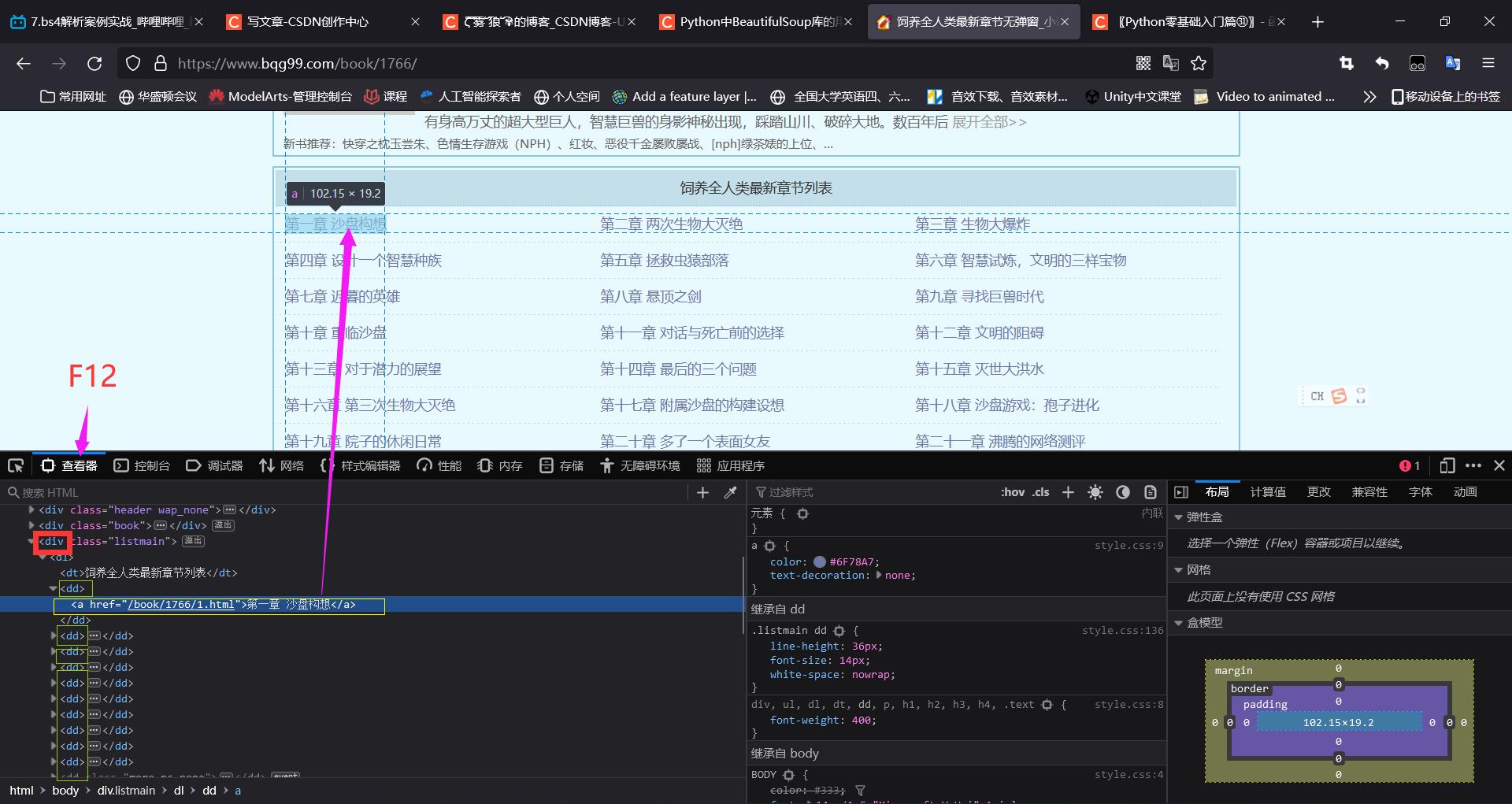
<div class="listmain">
<dl>
<dt>饲养全人类最新章节列表</dt>
<dd><a href="/book/1766/1.html">第一章 沙盘构想</a></dd>
<dd><a href="/book/1766/2.html">第二章 两次生物大灭绝</a></dd>
<dd><a href="/book/1766/3.html">第三章 生物大爆炸</a></dd>
<dd><a href="/book/1766/4.html">第四章 设计一个智慧种族</a></dd>
<dd><a href="/book/1766/5.html">第五章 拯救虫猿部落</a></dd>
<dd><a href="/book/1766/6.html">第六章 智慧试炼,文明的三样宝物</a></dd>
<dd><a href="/book/1766/7.html">第七章 迟暮的英雄</a></dd>
此处省略无数章节
</dl>
</div>可以看到所有的超链都在.listmain>dl>dd内
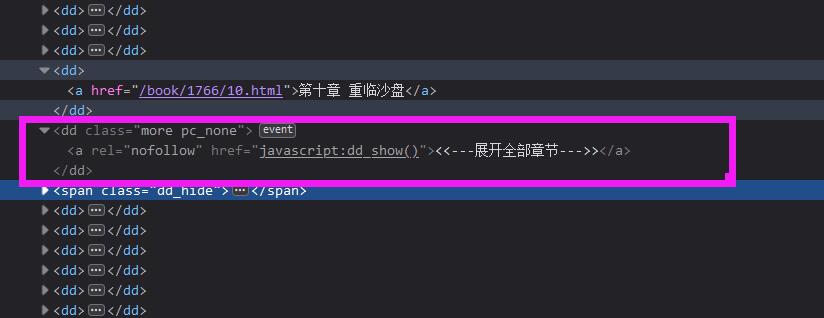
但也有特殊情况,里面没有章节的超链接,而是函数的超链接,需要剔除,防止无法请求:
(2)打开每一个章节,找到章节内容的标签
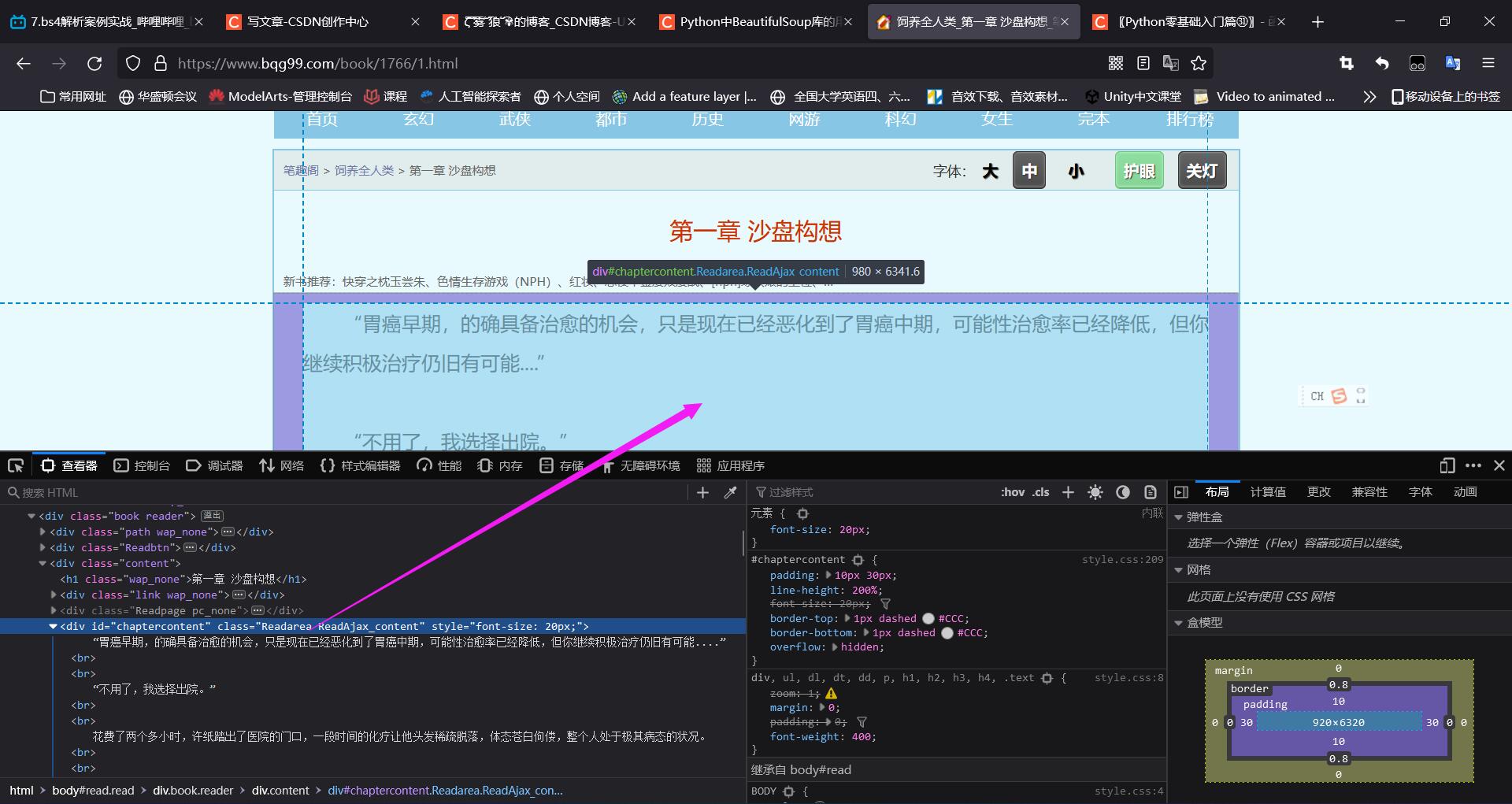
<div class="content">
<h1 class="wap_none">第一章 沙盘构想</h1>
<div class="link wap_none">新书推荐:<a href="/book/11271/">快穿之枕玉尝朱</a>、<a href="/book/57055/">色情生存游戏(NPH)</a>、<a href="/book/4750/">红妆</a>、<a href="/book/8503/">恶役千金屡败屡战</a>、<a href="/book/14480/">[nph]绿茶婊的上位</a>、<a href="/book/96882/">rou文短篇合集Ⅲ(双xing大nai,BDSM,高H,原名《坏掉的我之rouyu横liu》)</a>、<a href="/book/50879/">高H之校园制服类</a>、<a href="/book/7764/">水蜜桃</a>、<a href="/book/119686/">奴宠(古言 SM 1V1)</a>、<a href="/book/31374/">【快穿】媚肉生香</a></div>
<div class="Readpage pc_none">
<a href="/book/1766/" id="pb_prev" class="Readpage_up">上一章</a>
<a href="/book/1766/" id="pb_mulu" class="Readpage_up">目录</a>
<a href="/book/1766/2.html" id="pb_next" class="Readpage_down js_page_down">下一章</a>
</div>
<div id="chaptercontent" class="Readarea ReadAjax_content" style="font-size: 20px;"> “胃癌早期,的确具备治愈的机会,只是现在已经恶化到了胃癌中期,可能性治愈率已经降低,但你继续积极治疗仍旧有可能....”<br><br> “不用了,我选择出院。”<br><br> 花费了两个多小时,许纸踏出了医院的门口,一段时间的化疗让他头发稀疏脱落,体态苍白佝偻,整个人处于极其病态的状况。<br><br> 癌症初期,积极配合治疗,是有具备的治愈可能性,进入了中期就生还率极低。<br><br> 已经没有治疗的必要了。<br><br> 他默念着。<br><br> 许纸能力不低,在一家大型外企工作,可现在四五年积蓄的五六十万存款已经消耗了大半,忙忙碌碌了好几年,到头来还是一场空。<br><br> 他买高铁车票,拖着行李箱,一路回到了老家侗城的乡下。<br><br> 有一年没有回来的大山故乡,家里有一片独立门户的果园庭院。<br><br> 他们家在村里原先算是有矿,院子后面承包了一百多亩种植果树。<br><br> 但半年前荔枝市价太低,压仓烂了太多,又被人坑了一把,说能有渠道解决滞销,结果花钱请帮忙又被骗了太多钱,导致前前后后赔了近百万,血本无归,父母半年前也气得倒下,再也爬不起来了。<br><br> 现在果园没有人打理,请来的工人也已经走光,果树林变得荒芜,树木早已砍光,地面只剩杂草。<br><br> 开锁,推开房门,一股扑来的灰尘。<br><br> 从小到大熟悉的农居生活映入眼帘,他在房间里放下行李,打算在故土度过他最后的余生,重归乡村生活。<br><br> 窸窸窣窣...<br><br> 他忽然听到了一片诡异声音。<br><br> “谁?貌似院子里有东西在响?”他站起身,来到了空旷的果园院落里,在一堆杂草之中,看到了一只碗口大小的黑色甲壳虫。<br><br> “真黑,这是什么虫类?”<br><br> 许纸伸手。<br><br> 刷——<br><br> 一瞬间,他的思维被吸进了虫的黑壳中,带进了一段浩瀚种族历史。<br><br> 那是一段虫族的漫长崛起历史,从一颗绿色星球相当于我们地球寒武纪时代的生物大爆炸,便出现的一种远古虫类。他们诞生了自己的智慧,发展科技,巨大的繁衍能力和潜能让他们走向星空,当科技抵达顶端时,虫族知道自己生活的是贫瘠低等世界。<br><br> 最终,他们突破了某个维度,进入了一片更高层的匪夷所思奇幻世界,长生界,却瞬间溃败,输得像是理所当然。<br><br> 虫巢里中,上一代虫巢母皇,最后留下一片信息,满是遗憾:<br><br> “生物的进化,不是越庞大就越厉害,自身的强大才是正途。”<br><br> “我们一开始就走错了,越进化越巨大是条歧路,越渺小的身躯,越具备能量质变的基础.....我们败了,不管是谁成为了下一代虫巢母皇,替我再度打上长生界去!”<br><br> .......<br><br> 很快,许纸发现自己竟然接掌了这个虫巢,从他得到的虫族记忆里,这种侵略性极强的伟大种族,竟然只有一个种族能力。<br><br> “超高速细胞分裂?”<br><br> 虫族的能力,是能让自己的种族在短短时间内,缩短寿命,加速生物的细胞分裂速度,使得自己的种族像是花蕊一样瞬间,出生,绽放、成长,凋零,死亡。<br><br> 记忆里,虫族母巢是战争堡垒。<br><br> 只要母巢生产出细胞——孢子,投放在一个荒芜星球里,开启“超高速细胞分裂”,不到几年,那些细胞会疯狂繁衍,进化出一个个全新的新物种,成为母巢的部队之一。<br><br> “这个种族,有无限可能。”<br><br> 想到这里,许纸心思不平静起来。<br><br> 长久的病痛、化疗的折磨,让许纸感觉身心疲惫,甚至开始怀疑自己无聊的人生是为了什么,现在临死前,忽然有了好奇的事情。<br><br> 生物的演化与进程。<br><br> “上一代的虫族母皇,在一个个荒芜星球里投放孢子,繁衍进化无数种族,建造一个个世界,不过我没有星球,却能用这个能力,在我家的果园里,搞个小型进化沙盘来玩一玩?”<br><br> “拥有这个虫族母巢,战争堡垒,我完全可以在这个果园里,建立山川、海洋、河流,创造一个超小型沙盘,让无数虫族孢子,单细胞生物,在其中演化无数物种....”<br><br> “感觉像是沙盘游戏——我的世界,并且,如果能创造一个世界,演化一个文明、无数的种族,或许能从这个文明世界中,寻找解决我癌症的办法?”<br><br> 许纸激动起来:这大概就是奇遇??<br><br> 癌症,现代无法治愈,这或许是他最后活命的希望。<br><br> “我得快点建一个沙盘,去买耕地用的工具!”许纸在老家的农园里,翻出了角落里满是灰尘的三轮脚踏车,气喘吁吁的如秃顶老爷子,被化疗掏空的身体吃力开向外面的城镇里。<br><br> 然后花了自己三四万积蓄,拉回来了一堆农园整理设备和仪器,回到院落里,满心欢喜的开始布置。<br><br> 他没有一个星球,只有一个一百多亩的果园给他建造沙盘世界,<br><br> 他又一批工人帮忙清除果园里的杂草和杂树,变成一片泥土平地之后,自己拿起锄头,像是一位农夫挖坑,随手塑造超小型的土壤山川、淡水河流、山洞、各种荒芜沙盘地形。<br><br> 又把拿出买来的高温喷射器,一寸寸的高温烧烤整片沙盘,清理潜在的植物与动物,免得现成的地球生物影响孢子的物种演化....<br><br> 而微生物不必理会,也很难理会,它们将会被虫族基因吞噬,进化成新的地球物种。<br><br> “物种的起源是海洋,我得建造一个巨大海洋,海水。”<br><br> 果园里,本来父母原先就建有一片小鱼塘,他想了想,又花了大价钱请几个工人来帮忙,继续开阔鱼塘,挖土灌水,建立一片人造浅水池塘,倒进买来的盐,按照盐水比例做成海洋。<br><br> 但是,一个棘手的问题出现了。<br><br> 这不是一颗圆形的巨大星球,而是一百亩的正方形平面沙盘,这片土地的构造,是古老神话里的地形结构:<br><br> 天圆地方。<br><br> “神话中的土地吗?”<br><br> 许纸身体大不如前,艰难的整理了一个星期,才准备好果园里整片一百亩的巨大沙盘。<br><br> 这天上午,他才控制虫巢副脑,开始生产大片属于虫族的初始演化单细胞:孢子,被注入他塑造的沙盘,中央海洋里。<br><br> 进化开始了。<br><br> 他对母巢下达指令:<br><br> “细胞分裂加速:一万倍!”<br><br> 按照虫族的计数单位,一倍是一年。<br><br> 加速一万倍,这些单细胞演化的一天相当于漫长一万年.....但能不能诞生新的物种,在小小的院落沙盘里,实现地球当年的寒武纪大爆炸,还未可知。<br><br> 孢子投放的第一天里,中央清澈见底的海洋没有变化,没有任何变化。<br><br> 第二天,整个沙盘也静悄悄的。<br><br> 第三天。<br><br> 第四天。<br><br> 终于到了第五天,他设计的整个中央海洋,单细胞开始进化出一些浮游生物,水开始肉眼可见的浑浊。<br><br> 请收藏本站:https://www.bqg99.com。笔趣阁手机版:https://m.bqg99.com <br><br>
<p class="readinline"><a class="ll" rel="nofollow" title="章节错误,点此举报[免注册]" href="javascript:chapter_error('178','1','饲养全人类','第一章 沙盘构想','1631502204');">『点此报错』</a><a class="rr" rel="nofollow" title="加入书签,方便阅读" href="javascript:addBookMark('1766','1','饲养全人类','第一章 沙盘构想');">『加入书签』</a></p></div>
<script src="https://zz.bdstatic.com/linksubmit/push.js"></script><script src="https://hm.baidu.com/hm.js?816fc91a7843e2ae01fe367d0d91cc9c"></script><script type="text/javascript" src="https://apps.bdimg.com/libs/jquery/1.8.3/jquery.min.js"></script>
<script type="text/javascript" src="/js/common.js"></script>
<script type="text/javascript" src="/js/read.js"></script>
<script>read2();</script>
<div class="Readpage pagedown">
<a href="/book/1766/" id="pb_prev" class="Readpage_up">上一章</a>
<a href="/book/1766/" id="pb_mulu" class="Readpage_up">目录</a>
<a href="/book/1766/2.html" id="pb_next" class="Readpage_down js_page_down">下一章</a>
</div>
<script>read3();</script>
</div> 内容全在class=“Readarea”里面
(3)代码实现
#3.1
import requests from bs4 import BeautifulSoup import lxml # 指定主目录网址url url = "https://www.bqg99.com/book/1766/" # UA伪装 headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:105.0) Gecko/20100101 Firefox/105.0", } # 发起请求 r_text = requests.get(url=url, headers=headers).text #实例化soup soup=BeautifulSoup(r_text,'lxml') #获取所有a超链接标签 a_list_tag=soup.select(".listmain>dl dd>a")#有些章节不止是dl的一级子标签里,还在二级子标签的dd里所以用空格 for a_tag in a_list_tag: url=a_tag["href"]#获取标签属性值即超链接地址 if('html' not in url):#剔除超链接不指向网页html的特殊情况 continue title=a_tag.string#获取标题 #由于地址是相对地址,需要拼接地址,将主页地址加上 a_url="https://www.bqg99.com"+url a_text=requests.get(url=a_url,headers=headers).text #实例化当前页面soup soup=BeautifulSoup(a_text,"lxml") content=soup.select(".Readarea")[0].text with open("./book.txt","a",encoding="utf-8") as f: f.write(title+"\n"+content+"\n") print("已保存"+title)
总结,这节课我们学了什么?
#导入bs4的BeautifulSoup模块
from bs4 import BeautifulSoup
#BeautifulSoup对象实例化 html文档解析
soup=BeautifulSoup(response,‘lxml’)
#标签定位
soup.tagName#返回第一个tagName标签的整体html
soup.find(‘tagname’,attrName=‘value’)#返回第一个找到标签的整体html
list=soup.find_all(‘tagname’,attrName=‘value’)#返回所有找到标签的整体html
list=soup.select(‘CSS格式选择器’)’)#返回所有找到标签的整体html
#获取标签内的文本
soup.tagName.text
soup.tagName.get_text()
soup.tagName.string
#获取标签中的属性值
soup.tagName['attrName']


















 363
363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











