python 爬虫及数据可视化展示
学了有关python爬虫及数据可视化的知识,想着做一些总结,加强自己的学习成果,也能给各位小伙伴一些小小的启发。
1、做任何事情都要明确自己的目的,想要做什么,打算怎么做,做到什么样的程度,自己有一个清晰的定位,虽然计划永远赶不上变化,但是按计划走,见招拆招或许也是不错的选择。
2、本项目是爬取豆瓣的250部电影,将电影名,电影链接,评分等信息爬取保存到本地。将相关信息以列表的形式展示在网页上,访问者可通我的网站直接挑转到豆瓣查看电影,将评分制作评分走势图,将电影制作成词云图在网页上展示,共有五个网页,可相互跳转。
项目流程图:
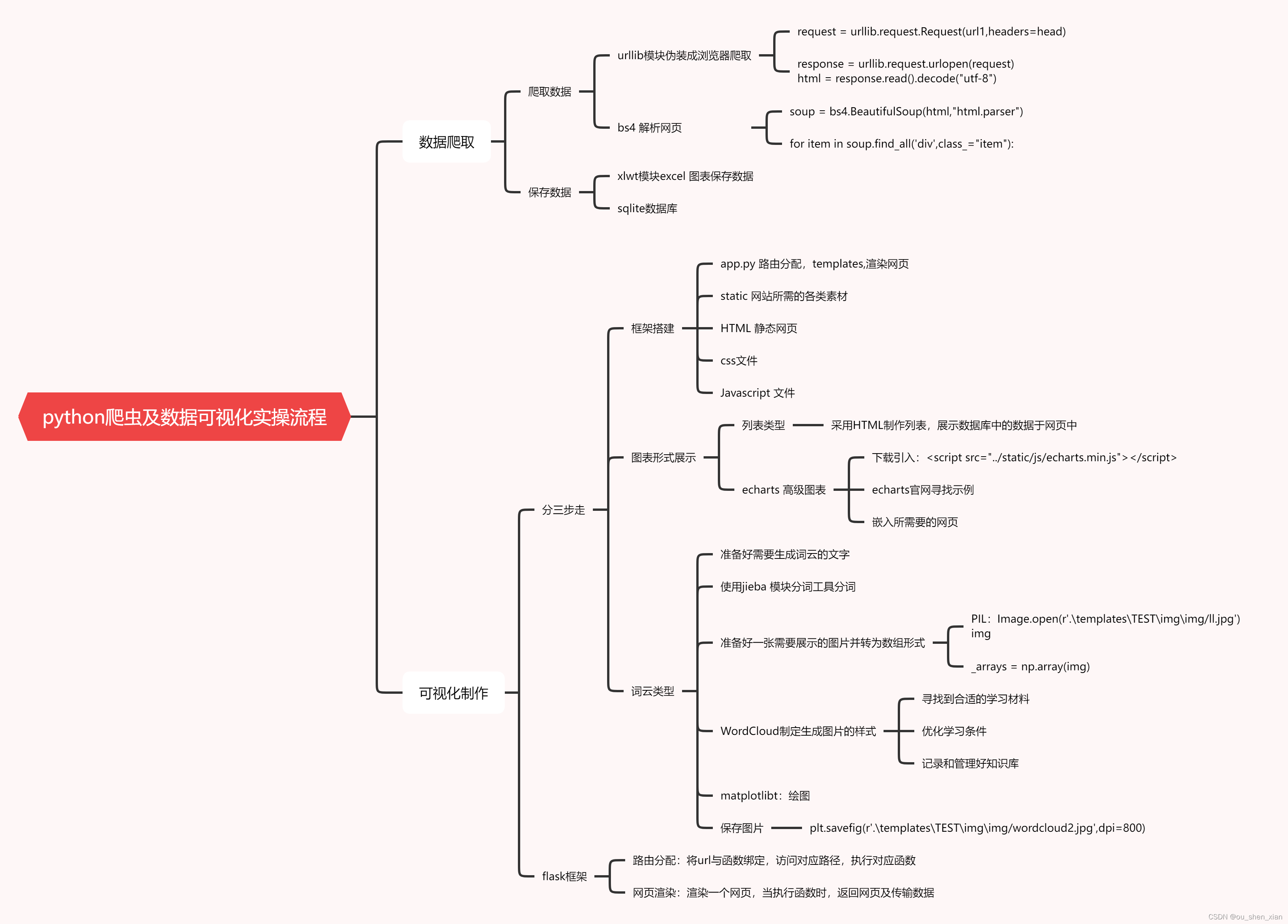
数据爬取:
import bs4
import re
import urllib.request,urllib.error
import xlwt
import sqlite3
import time
def main():
url = "https://movie.douban.com/top250?start="
datalist1 = allData(url)
dbpath = "move.db"
savedatasql(datalist1,dbpath)
linkpattern = re.compile(r'<a href="(.*?)/">')
imagepattern = re.compile(r'<img .*src=".*"/>',re.S)
namepattern = re.compile(r'<span class="title">(.*)</span>')
gradepattern = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
peoplepattern = re.compile(r'<span>(\d*)人评价</span>')
thinkpattern = re.compile(r'<span class="inq">(.*)</span>')
contentpattern = re.compile(r'<p class="">(.*?)</p>',re.S)
def getData(url1):
head = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0"}
request = urllib.request.Request(url1,headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
def allData(url):
datalist = []
for i in range(0, 10):
url1 = url + str(i * 25)
html = getData(url1)
time.sleep(1)
soup = bs4.BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="item"):
data = []
item = str(item)
link = re.findall(linkpattern,item)[0]
data.append(link)
image = re.findall(imagepattern,item)[0]
data.append(image)
name = re.findall(namepattern,item)
if(len(name)==2):
chinaname = name[0]
data.append(chinaname)
outername = name[1].replace("/","")
data.append(outername)
else:
data.append(name[0])
data.append(' ')
grade = re.findall(gradepattern,item)[0]
data.append(grade)
people = re.findall(peoplepattern, item)[0]
data.append(people)
think = re.findall(thinkpattern, item)
if len(think) != 0:
think = think[0].replace("。","")
data.append(think)
else:
data.append(" ")
content = re.findall(contentpattern, item)[0]
content = re.sub('<br(\s+)?/>(\s+)?'," ",content)
content = re.sub('/'," ",content)
data.append(content.strip())
datalist.append(data)
return datalist
def savedatasql(datalist1,dbpath):
init_db(dbpath)
conn = sqlite3.connect(dbpath)
cur = conn.cursor()
for data in datalist1:
for index in range(len(data)):
if index == 4 or index == 5:
continue
data[index] = data[index].replace("'", "")
data[index] = "'"+data[index]+"'"
sql =








 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9825
9825











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









