






1、AAGCN
在AAGCN中,下面的图用到了Self-Attention注意力机制。Self-Attention自注意力机制是Transformer中的一部分,因此本次需要学习一下Transformer模块。

2、Self-Attention
超强动画,一步一步深入浅出解释Transformer原理!_哔哩哔哩_bilibili
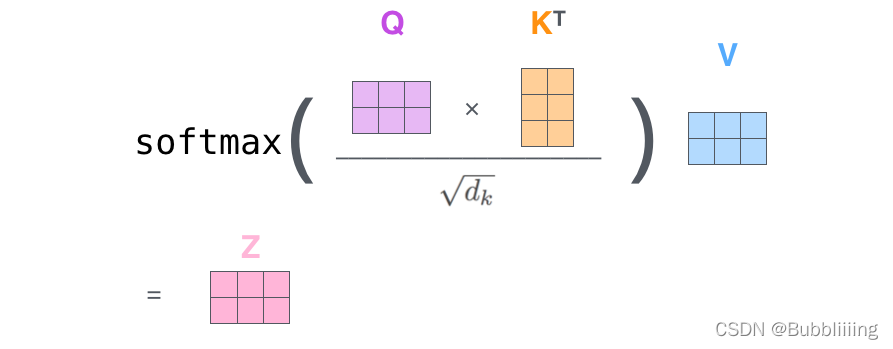
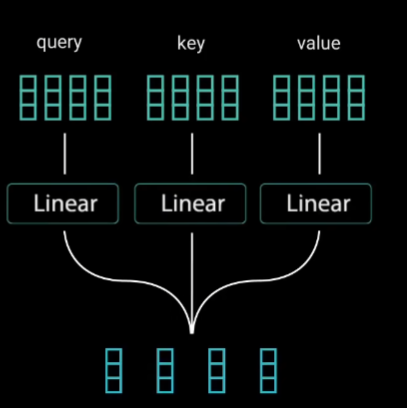
Transformer常用于语言识别、语言生成等语言方面相关的处理。Self-Attention允许模型将输入中的每个单词与输入中的其他单词关联起来。这里我们输入英文句子:“Hi how are you” ,来进行举例说明。
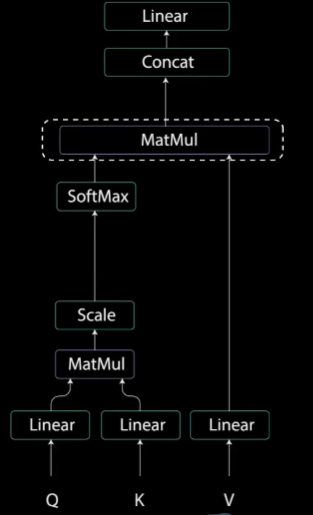
(1)Linear(全连接)
首先将单词输入到3个全连接层,得到3个相应的向量数据(Query是查询向量、Key是键向量、Value值向量)。在AAGCN中:Query---k ,Key---
k ,Value---Cin×T×N
(2)MatMul(矩阵乘法)

注:上图中的query和key表示的矩阵是概念性的,与真实的矩阵大小有差别。
这里的按照每个单词有3个数据的索引,得到的Q和K、
应该如下:
Q和K:
由Q×

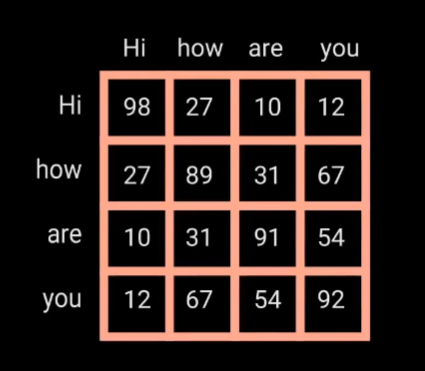
Sorce分数矩阵确定了每个单词应该如何关注其他单词,分数越高,关注度越高。
(3)Scale(归一化)
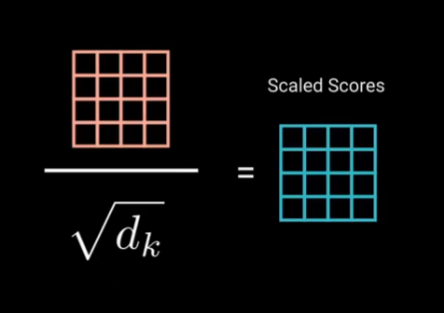
这样可以使梯度更稳定,因为乘法可能产生爆炸效果。
(4)Softmax(激活函数)
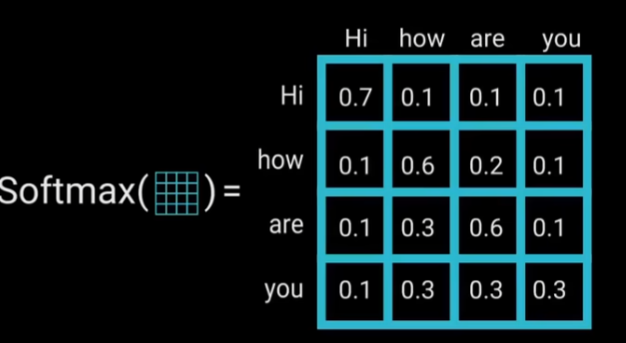
将数据控制在0-1之间,较高的得分会得到增强,而较低的得分会被抑制。
(5) MatMul(矩阵乘法)

(6)Concat(矩阵连接)
(7)linear(全连接)
3、Transformer总体架构

首先进行编码器(2.Encoder block),得到对应的矩阵数据。对于解码器(3.Decoder block),将矩阵数据和由解码器产生的数据作为输入,得到下一步的输出,重复进行,直到结束。
“hi how are you” ---->"嗨 你好"
E_date = [] 编码器输出
D_data = [] 解码器输出
inputs --->E_data 由输入得到编码矩阵
def output_Probabilitires(E_data , D_data)有解码器递归输出结果
outputs = D_data + E_data
output_Probabilitires(E_data,outputs)















 802
802











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









