







二、AAGCN
1、与ST-GCN相比的创新点。
在说本篇论文的创新前,先说明一下ST-GCN的缺点。ST-GCN的注意力机制灵活性不够,掩码 𝑀𝑘 是与邻接矩阵直接相乘,这里说的相乘是按元素相乘,并不是矩阵相乘。这就造成一个现象,就是如果邻接矩阵 𝐴𝑘 里面部分元素为0,那么无论 𝑀𝑘 对应元素为何值,最后结果都是0。换句话说就是不会创造不存在的连接,比如对于“行走”动作,手和腿的联系很大,但是手和腿没有直接相连,所以效果不好。ST-GCN的第二个缺点就是没有利用骨骼数据的第二特征,这里第一特征就是关节坐标,第二特征就是骨骼的长度和方向。直觉上,第二特征也包含了丰富的行为信息。
在AAGCN中,(1)提出了自适应的图卷积网络,也就是引入了两个额外的参数化(可学习)的邻接矩阵,这两个矩阵分别用来:Bk学习所有数据中的共同模式(也就是所有数据中统一的共性关注点);Ck 学习单个数据中独有的模式(也就是每个数据中独有的关注点);(2)注意力机制的改进;(3)二阶信息的提取和多流机制。
2、自适应图卷积神经网络
自适应图神经网络与ST-GCN的区别之一在于引入了参数化,可学习的邻接矩阵𝐵𝑘与𝐶𝑘。这样的邻接矩阵可以解决STGCN中骨架拓扑结构固定的问题。
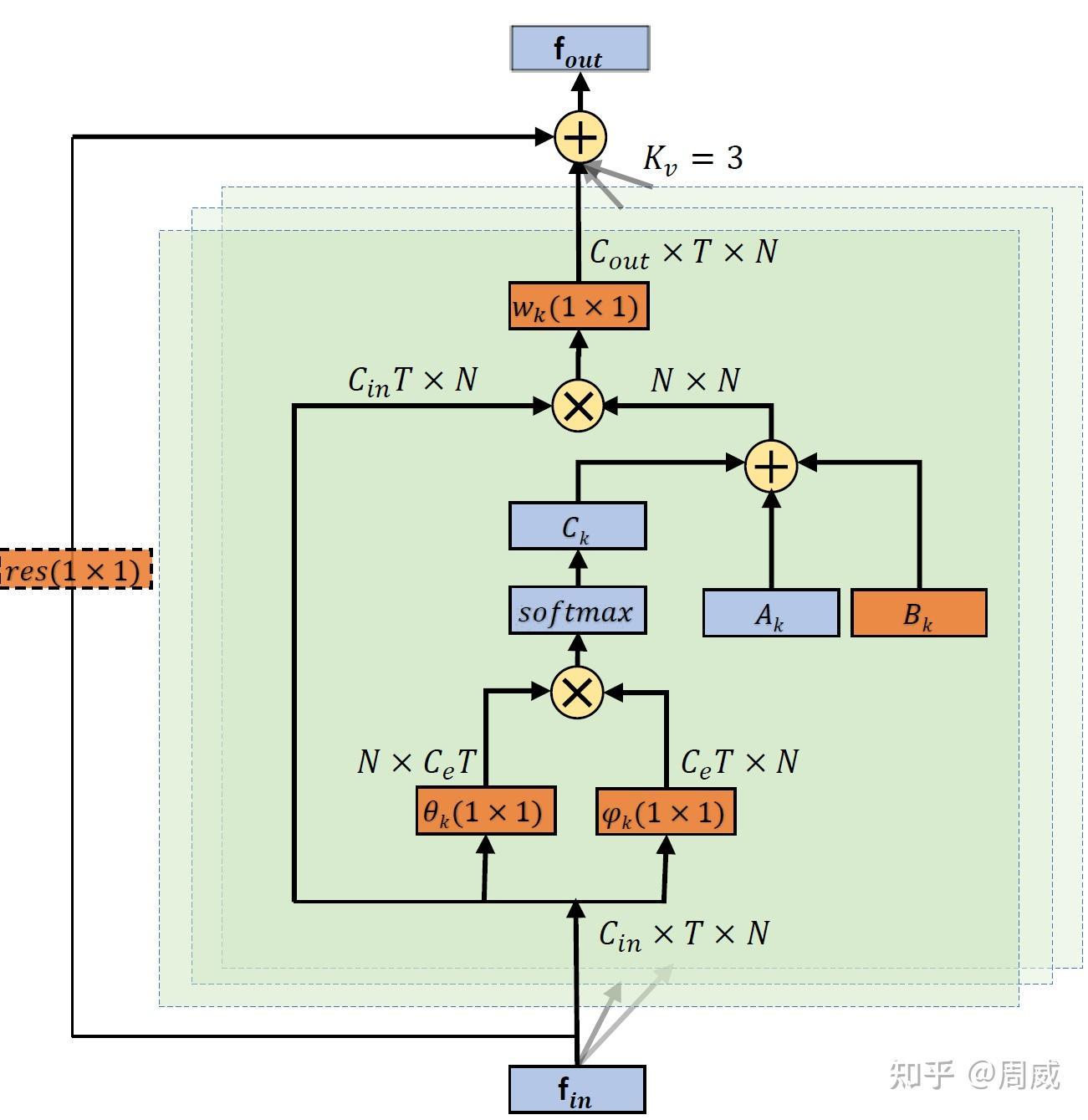
可见,除了最基本的邻接矩阵𝐴𝑘外,作者还引入了两个可学习的邻接矩阵𝐵𝑘与𝐶𝑘。这里的𝐵𝑘与STGCN中的Learnable edge importance weight相似,是一个参数化的𝑁×𝑁
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1066
1066

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









