







Pandas库的基本使用方法
生成二维数组
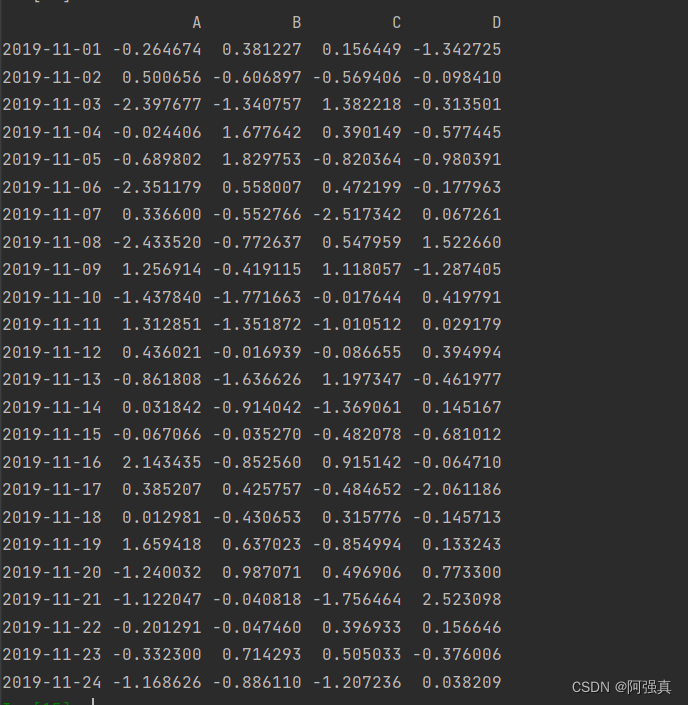
例:生成服从标准正态分布的24乘4随机矩阵,行名为20191101到20191124,列名为A,B,C,D并保存为dataframe数据结构
import pandas as pd
import numpy as np
dates=pd.date_range(start="20191101",end="20191124",freq="D")#生成一组时间序列数据
a=pd.DataFrame(np.random.randn(24,4),index=dates,columns=list('ABCD'));a
文件的读取与写入
文件的写入
这里有csv和xlsx两种格式
a.to_excel("dataframe.xlsx")
a.to_csv("dataframe1.csv")
或者:
f=pd.ExcelWriter("data.xlsx")
a.to_excel(f,'sheet1')
b=a+1
b.to_excel(f,'sheet2')
f.save()
这样就能在一个excel中看到两个表格:

文件的读取
c=pd.read_csv("dataframe1.csv",usecols=range(1,5))#读取文件并展示行名
d=pd.read_excel("data.xlsx",'sheet2',usecols=range(1,5))#读取文件的第二个表格并展示行名
数据的一些预处理
1.拆分,合并和分组计算
import pandas as pd
import numpy as np
dates=pd.date_range(start="20191101",end="20191124",freq="D")#生成一组时间序列数据
d=pd.DataFrame(np.random.randn(24,4),index=dates,columns=list('ABCD'));a
d1=d[:4]#获取数据的前四行数据
d2=d[4:]#读取数据五行以后的数据
d3=pd.concat([d1],[d2])#合并行数据
s1=d.groupby("A").mean()#数据分组求均值
s2=d.groupby("A").apply(sum)#s数据分组求和
2.数据的选取与清洗
import pandas as pd
import numpy as np
data=pd.DataFrame(np.random.randint(1,3,(3,3)),index=["m","v","p"],columns=["one",'two','three'])
data.loc['m','one']=np.nan#修改第一行第一列的数据为空值
data.iloc[1:3,0:2]#提取数据的第2到3行,第1到2列
data["four"]="shit"#增加第四列数据
a2=data.reindex(["m",'v','p'])
a2.dropna()#删除有不确定的值
a2
参考文章:https://book.douban.com/subject/35066598/















 3523
3523











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









