







Edit-History Vis:An Interactive Visual Exploration and Analysis on Wikipedia Edit Histor
1.概要
维基百科是最大的在线百科全书,其目标是能够免费获取和传播全面的知识。维基百科允许开放协作,这意味着任何人,无论是领域专家还是公众,都可以通过直接编辑页面做出贡献。因此,维基百科的文章可能有大量的修订,这些记录在维基百科的修订历史记录中。这些记录的修订对研究人员和一般公众都是有价值的。对于研究人员来说,他们反映了维基百科作为一个开放的知识平台的效率和质量,以及在线协作的潜在机制。对于一般用户来说,探索文章是如何形成的,以及对协作过程的认识促进了对所显示内容的批判性思考是很有趣的。但是,由于编辑内容、编辑时间和编辑者等属性,修订数据非常复杂,这给理解编辑历史记录带来了挑战。
Edit-History,对于维基百科编辑历史的可视化探索与分析,显示了动态的观点及编辑者之间的互动。
2.设计原理
1.数据描述
MediaWiki提供了一个API来获取wiki格式中给定文章的修订版本。
修订的数据:编辑时间、编辑内容和编辑者是修订数据的基本属性。这三个异构维度导致了编辑历史的复杂性,而将它们集成到可视化视图中是我们面临的主要挑战。
句子级的演化:编辑历史可以分解为句子级的演化。每个句子的修订都是文章修订的一个子序列,同样地,它包括编辑时间、编辑内容和编辑者维度。编辑内容可分为四种类型,即插入新句子、删除旧句子、将句子移到另一个位置、修改旧句子中的一些单词。
编辑者的立场和关系:编辑可能对文章的主题有不同的观点,这些观点反映在他们编辑的文本中。例如,还原和恢复编辑表示编辑者之间的冲突。在我们的语境中,两个编辑者之间的关系是由他们编辑了同一个句子以及他们编辑行为体现的观点来定义的。相似的句子编辑表明了类似的观点。
2.任务分析
我们的目标是基于句子级演化来进行全面的分析
T1:得到编辑历史记录的概览
T2:理解句子级的编辑过程
T3:检测和分析有争议的内容
T4:观察和分析编辑事件(比如破坏、编辑战争)
我们根据时间和观点对修订进行聚合和排序,链接相关的修订,并指明主要的变化来表示一个句子的发展
3.修订图(Revision Graph)
在修订图中,节点表示修订,链接表示修订之间的编辑关系。我们将句子设置为生成关系的基本单位,并构建修正图
1.数据处理
我们将MediaWiki API 的每个修订版本与其后续版本进行比较来对齐句子,这样我们就可以得到每个句子的修订版本。对于句子的每一次编辑,我们将比较旧文本和新文本,以得到token级别的更改。我们对破坏性的编辑进行了粗略的检测,并计算了句子的争议和象征性的争议。
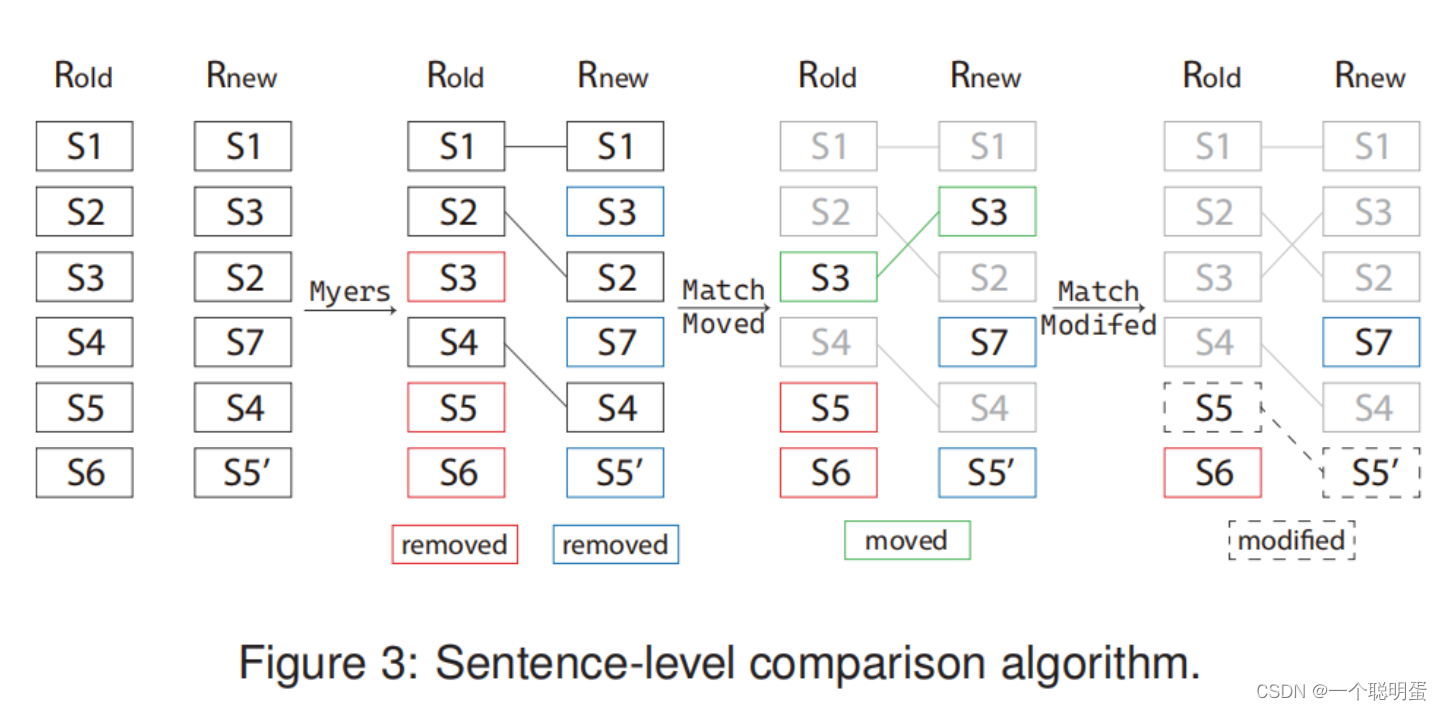
Sentence-level comparison(句子级比较)
我们将修订版本(记为{r0、r1、r2、r2、···})按句子进行分割,并将每个修订版本 ri 与前一个 ri−1 进行比较,得到句子的变化。一个句子的编辑可以分为四类:插入、删除、移动和修改。如图3,首先,运行Myers算法来对齐句子。Myers算法不识别移动的句子和修改后的句子,会返回未改变的句子、插入的句子和被删除的句子的列表。然后,匹配插入和删除的句子,得到移动的句子 (S3). 最后,遍历剩余的插入和删除的句子,得到修改后的句子——具体来说,使用一个句子转换器来计算句子之间的相似性。如果一个被删除的句子和一个被插入的句子之间的相似性超过了阈值(这里设置为0.9),就将后者设置为前者的修改结果(图3中的S5,S5‘)。剩下的就是插入和删除的句子。
Token-level comparison(Token级比较)
对于修改后的句子,我们将其旧版本和新版本进行比较,以得到token的变化。token有三种类型的更改:插入、删除和移动。与句子级比较类似,我们使用Myers算法,以获得未更改的token、插入的token和被删除的token。然后,我们比较插入的token和被删除的token,以获得移动的token。
Vandalism detection(破坏性检测)
对破坏性编辑进行了粗略的检测,以过滤掉大量的删除和插入,否则在测量争议时会带来噪声。设μ为平均页面大小,σ为页面大小的标准差,对于每个修订版ri,让size(ri)表示其页面大小。如果|size(ri)−μ| > λ·σ,其中λ是一个阈值,我们认为该修订是破坏。我们设置了λ = 3,这是离群值检测的常用设置。
Sentence controversy and token controversy(句子和token争议)
用句子和token的变化次数来表示争议。由于破坏行为不会影响争议,所以我们在计算句子和象征性争议时过滤掉了破坏行为的编辑。
2.图构建和可视化
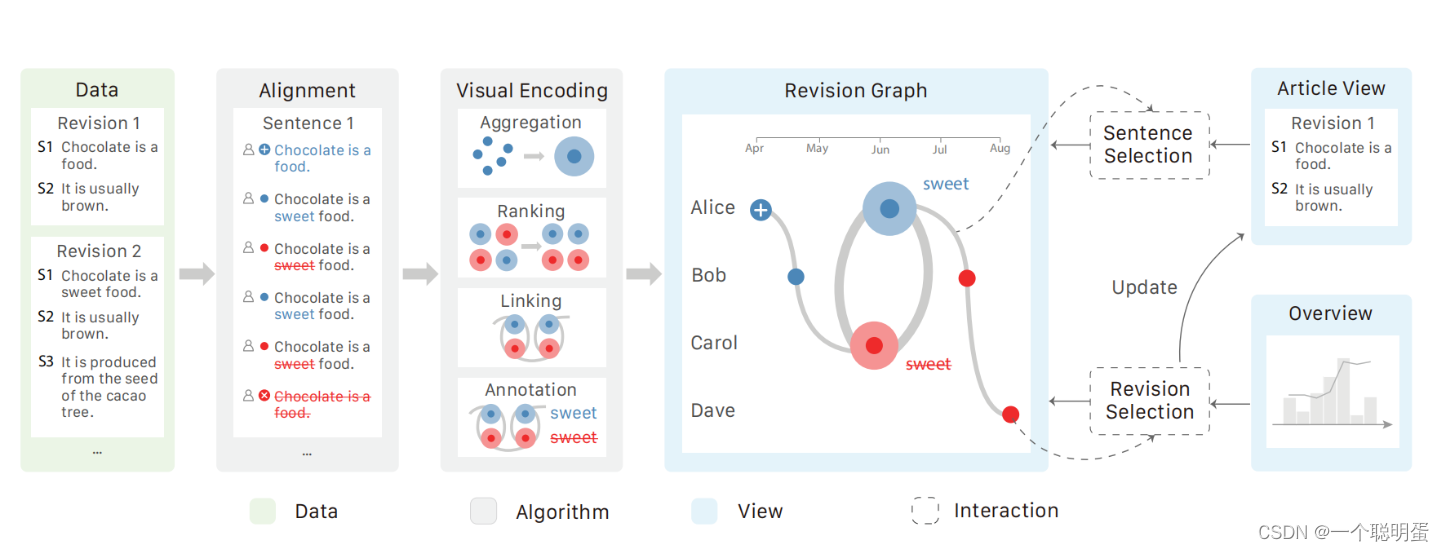
修订图:句子的每一次修改都用一个点来表示。通过四个可视化的编码模块来布局这些点:聚合(aggregation)、排序(ranking)、链接(linking)和注释(annotation),
为了减少对一个有争议的句子的大量修改而造成的重叠,我们将相邻的点聚合。采用力导向算法来优化修订的垂直排序,使具有相同立场的修订在垂直方向上更接近
我们将修订用曲线联系起来,以增加时间顺序,和重复修改,这表明可能的编辑战争。聚合的修订用修订的关键字进行注释。
Aggregation:
修订点通常在时间上分布不均匀。有时会爆发大量的编辑,导致点的严重重叠,特别是在出现编辑战时。因此,我们聚合了在时间上相近且具有相同编辑结果的点。聚合的修订版本用符号表示。
1.聚合算法:聚类半径d由窗口大小决定,设置聚类半径为视图的宽度除以该点的最大半径(不懂)。最初,每个修订都是一个集群。如果集群外的一个修订与集群中的另一个修订之间的距离小于集群半径,则将前一个修订合并到集群中,并重新融合坐标。

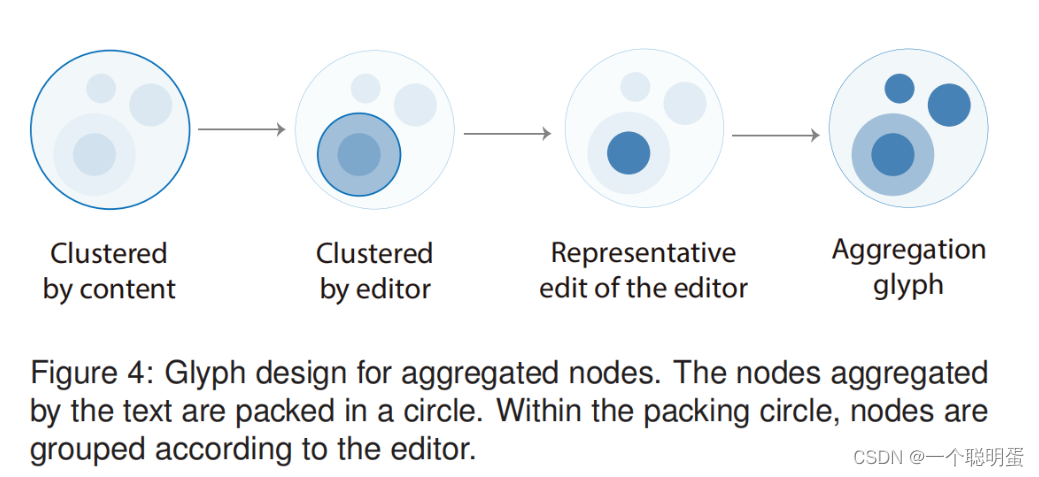
2.字形设计
我们用圆圈来表示修订版本,圆的大小对字节变化进行编码,水平坐标表示时间,和概览图的时间轴是一致的,编辑的类型同时用颜色和中心图标进行编码。绿色代表移动操作。红色代表字节数减少,蓝色代表字节数增加,insert操作会额外加一个加号符号,deleted额外加一个叉符号,中间没有符号的代表是修改,对于聚合的版本,通过编辑者组合他们,每一组用一个内圈(表示代表性修订)和一个晕圈(表示修订数量)表示。.这些组被打包在一个更大的圆圈中来表示集群,集群的水平坐标表示其中修订的编辑时间的平均值。
Ranking
将观点编码到垂直维度中,在文章背景中,观点的定义如下:(D1)观点表现为类似的编辑行为;(D2)一个编辑者通常有一个一致的观点。为了可视化观点的动态,我们使用一个力导向算法来优化垂直坐标,使垂直位置可以表示立场。我们根据编辑行为的相似性和编辑者意见的一致性来设置力量。优化目标(G)和约束条件为(C),如下:
(注意都是在垂直方向上)
G1:将相同修订文本之间的总距离最小化。
其中T表示句子所有版本的集合,Rt表示其编辑结果等于句子版本t的句子修订版本集,y (r)表示修订版本r所属的节点的垂直坐标。
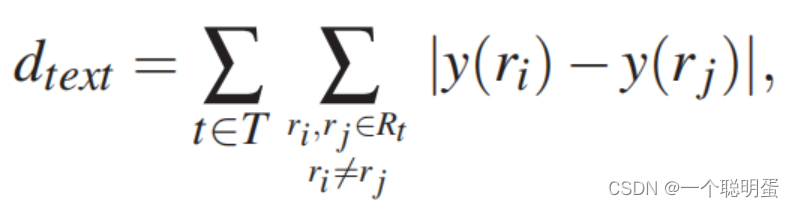
G2:由同一编辑者编辑的修订本应接近垂直方向(D2)。我们最小化与相同编辑者之间的总距离。
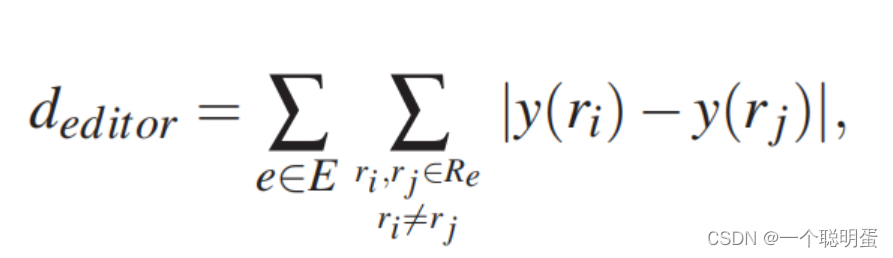
其中,E表示修改句子的所有编辑者,Re表示编辑者e修改句子的编辑。
具有更常见观点的修订应该放得更高。我们根据每个版本的出现次数对句子版本T进行排序,rank(t)表示版本t的排名。我们最小化修正的垂直坐标和期望排名之间的总距离。
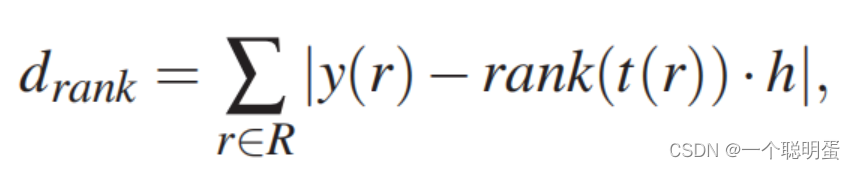
式中,R表示句子的修订,t (r)表示修订r的修订文本,h表示行高。
G4:每个节点与其后继节点之间的垂直跨度应该很小,这样曲线就不会很混乱。我们最小化总垂直距离。
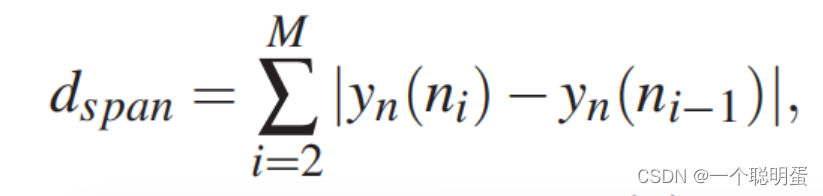
C1:应避免节点的重叠,其中,N为节点的集合,ci为节点ni的中心点,radi为节点ni的半径。
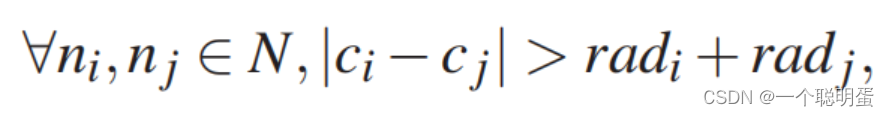
C2:节点应该在包含没有重叠的所有修订的最小区域的边界内。
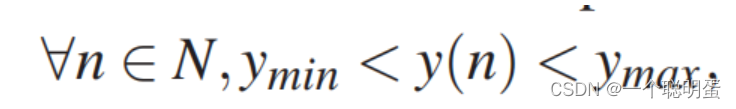
其中ymin和ymax表示下界和上界
相应地设置力,并使用d3力导向算法来得到修正的优化排序。由于只优化了垂直尺寸,所以在模拟过程中固定了水平坐标,并根据力定制了垂直速度和位置的更新(一共6个力)。
F1. Text gravitation: gravitation between every two revisions with the same editing result (G1).
F2. Editor gravitation: gravitation between every two revisions by the same editor (G2).
F3. Gravity: the weight of the versions (G3).
F4. Adjacent gravitation: gravitation between each adjacent pair of points (G4).
F5. Collision force: repulsion between points (C1).
F6. Boundary: limitation on the range of the coordinates of the revisions (C2).
Linking
链接方法的基本思想是画一条曲线,按时间顺序将句子的每次修订连接起来。如果在两个集群之间进行重复的修改,就会出现混乱的圆形曲线,表明之间存在冲突。为了减少混乱,我们聚合了两个冲突集群之间的曲线。首先,枚举集群,并记录集群之间存在重复修改的所有集群对。对于每一对,我们在两个簇之间画一条圆形曲线,曲线的宽度表示重复的次数。
Anitation
对于句子上的每一次编辑,我们都使用token级的比较方法来获得更改后的token。对于每一种类型的变化,我们选择了单词频率最高的两个标记(排除了没有真正意义的标记),并使用颜色和文本装饰对该类型进行编码。
在垂直空间上加上了编辑者标注(左侧)。选择编辑次数最多的编辑者作为代表。
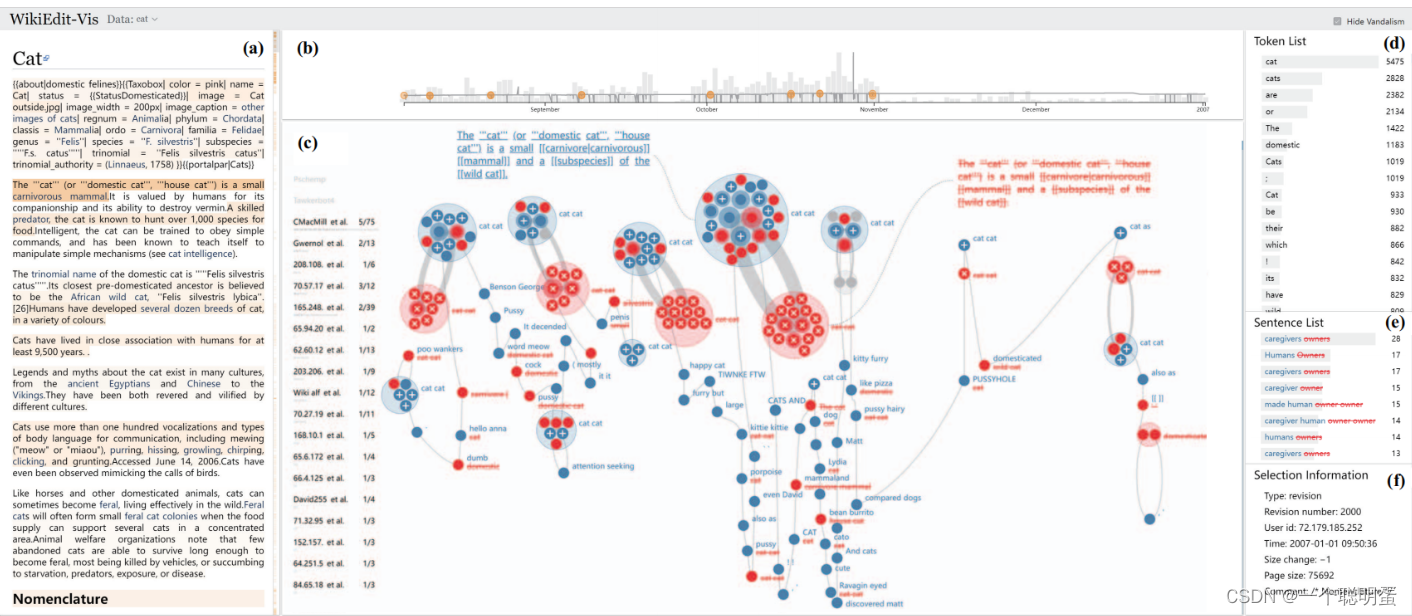
4.系统界面
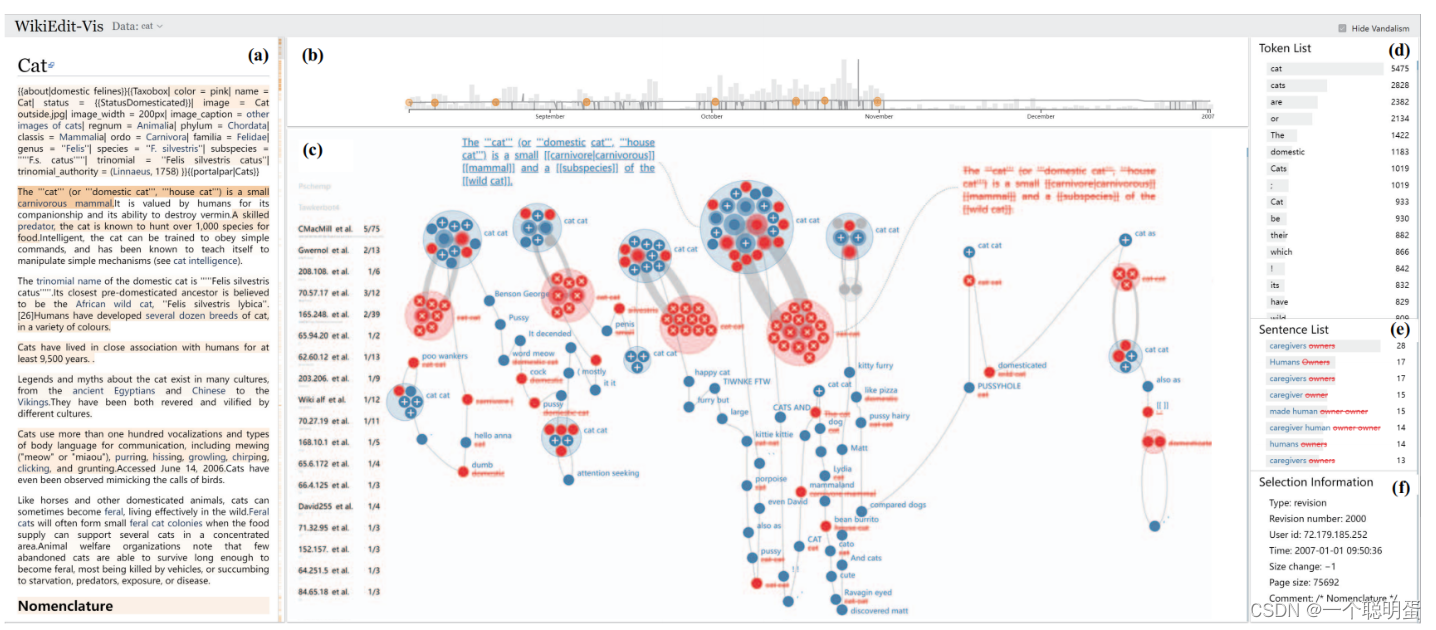
article view(a):显示了修订的文本内容。这些句子的颜色阴影表明了争议。我们在滚动条上标记了这些有争议的句子,并改变了句子。用户可以浏览文章,并选择有趣的句子来查看其修订历史记录。
overview(b):概述显示了编辑的次数(柱形图)和文章的大小(折线图)的时间分布。我们在折线图上标出了这些有争议的修改
information list Panel(d、e、f):信息列表面板包括token list、sentence list和selection information,token list显示频繁的文本标记,它们按频率排序。sentence list显示了关于所选修订或标记的已更改的句子,允许用户直接在此视图上选择句子。由于空间的限制,每个句子都由插入或删除的最频繁的标记来表示。selection information显示有关当前选择的基本信息。
revision graph(c):修订图是编辑-历史可见信息系统的主要视图,该系统将关于用户选择的编辑可视化。如果选择了一个句子,修订图将可视化该句子的编辑过程。用户可以与修订图进行交互,以查看这些编辑的详细信息,或选择他们在修订图上检测到的其他有趣的对象。修订图支持选择一个句子(通过单击相应的曲线)和选择一个修订(通过单击节点)。
个人总结
1.这个idea还是想的比较好,维基百科的修订历史数据,我之前都没有了解过维基百科是什么东西
2.这个数据挺庞大的,他们做了一个细分,显示的是句子级别的修改可视化,然后抓住四种修改方式:插入,删除、修改、移动(这个没怎么见到过),用图形来代表含义,主要抓住一个可以分析编辑冲突,让用户去交互探索发现有趣的规律(比如编辑者是怎么样去争执一些名词的,或者一个正常的渐进完善过程)
3.横轴表示时间,纵轴结合了6个力(这个感觉搞得有点复杂,反而有点看不懂,大致是将观点比较多的放在上面一些,所以会发现那种打的聚类主要集中在上方)
4.聚类的应用,聚类在这篇文章里面用的还是比较多的,相近时间相同文本聚类在一起(它中间还根据编辑者分了组),将循环修改的link聚类在一起(我感觉加入了编辑者这个维度还是让这个系统的阅读难度增加了一些,主要是聚类中间多了很多圈,但是又有点难分析,然后批注也有点难懂)
5.这篇文章是投在了PVis上的,我感觉找一个idea,第一点要有一个数据,而且这个数据要有一定的维度给你分析,第二点就是要想明白要可视化的内容是什么,然后怎么样设计他们的形式,让它具有那种可以深入去探索分析的功能,以及易懂(这个项目可视化的内容是:修订的时间、内容、编辑者、修订的操作,抽象出来的观点)有实有虚


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









