







01猫狗识别
简介:手动搭建LeNet实现猫狗识别
参考链接:https://mtyjkh.blog.csdn.net/article/details/121263237
代码链接:01猫狗识别 (github.com)
注:建议初学一定要会敲所有代码,因为这像是一个模板,不管如何,都要能熟练地敲出来(知道有哪些步骤,每一步的核心是做什么?如何做?涉及到了哪些函数?如何将这些函数连接起来?……),刚开始不会没关系,多敲几遍就会了,敲的时候可以思考为什么要这样做,但有些基本性的东西,不要非要探究为什么,先记住再说,就像学算术一定要先会背九九乘法表一样,刚开始的背诵是必要的,到后面就会深刻体会到为什么,一定要动手!!!
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor,Lambda,Compose
import matplotlib.pyplot as plt
import torchvision.transforms as transforms
import numpy as np
1.数据读取与预处理
train_datadir='/content/1-cat-dog'
test_datadir='/content/1-cat-dog'
train_transforms=transforms.Compose([
transforms.Resize([224,224]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485,0.456,0.406],
std=[0.229,0.224,0.225]
)
])
test_transforms=transforms.Compose([
transforms.Resize([224,224]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485,0.456,0.406],
std=[0.229,0.224,0.225]
)
])
train_data=datasets.ImageFolder(train_datadir,transform=train_transforms)
test_data=datasets.ImageFolder(test_datadir,transform=test_transforms)
train_loader=torch.utils.data.DataLoader(train_data,batch_size=4,shuffle=True,num_workers=1)
test_loader=torch.utils.data.DataLoader(test_data,batch_size=4,shuffle=True,num_workers=1)
数据处理步骤:
处理数据-读取数据-包装数据
- transforms.compose
- datasets.ImageFolder
- torch.utils.data.DataLoader
🤔问题:
transforms.ToTensor()的作用?
- 归一化
- torchvision.transforms.ToTensor,其作用是将数据归一化到[0,1](是将数据除以255),transforms.ToTensor()会把HWC会变成C *H *W(拓展:格式为(h,w,c),像素顺序为RGB)
transforms.Normalize()中的mean和std是如何确定的?
[0.485, 0.456, 0.406]这一组平均值是从imagenet训练集中抽样算出来的。
那么归一化后为什么还要接一个标准化呢?
Normalize()是对数据按通道进行标准化,即减去均值,再除以方差
别人的解答:数据如果分布在(0,1)之间,可能实际的bias,就是神经网络的输入b会比较大,而模型初始化时b=0的,这样会导致神经网络收敛比较慢,经过Normalize后,可以加快模型的收敛速度。
因为对RGB图片而言,数据范围是[0-255]的,需要先经过ToTensor除以255归一化到[0,1]之后,再通过Normalize计算过后,将数据归一化到[-1,1]。
是否可以这样理解:
[0,1]只是范围改变了,并没有改变分布,mean和std处理后可以让数据正态分布😂
此题参考链接:https://cloud.tencent.com/developer/article/2102114
for X,y in test_loader:
print("shape of X [N,C,H,W]:",X.shape)
print("shape of y:",y.shape,y.dtype)
break
数据经过DataLoader长啥样?DataLoader的作用?
DataLoader相当于给数据打包,将数据包装成一捆一捆(batch-size)的
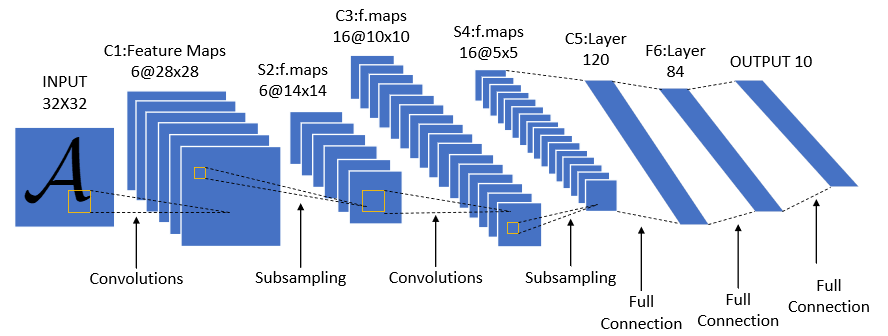
2.定义模型

import torch.nn.functional as F
#GPU
device="cuda" if torch.cuda.is_available() else "cpu"
print("using {} device".format(device))
#定义模型
class LeNet(nn.Module):
#定义网络结构所需要的具体操作算子
def __init__(self):
super(LeNet,self).__init__()
# Conv2d的第一个参数是输入的channel数量,第二个是输出的channel数量,第三个是kernel size
self.conv1=nn.Conv2d(3,6,5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2=nn.Conv2d(6,16,5)
self.fc1=nn.Linear(16*53*53,120)
self.fc2=nn.Linear(120,84)
self.fc3=nn.Linear(84,2)
#网络结构
def forward(self,x):
x=F.relu(self.conv1(x))
x=self.pool(x)
x=F.relu(self.conv2(x))
x=self.pool(x)
x=x.view(-1,16*53*53) # 这步把二维特征图变为一维,这样全连接层才能处理,因为全连接层是一维
x=F.relu(self.fc1(x))
x=F.relu(self.fc2(x))
x=self.fc3(x)
return x
model=LeNet().to(device)
print(model)
为啥fc1是16 * 53 * 53?
16是通道数
卷积公式:
output_size=(input_size+2*padding-kernel_size)/stride +1
- conv1:(224+0-5)/1+1=220
- pool1:(220=0-5)/2+1=110
- conv2:(110+0-5)/1+1=106
- pool2:(106=0-5)/2+1=53
3.定义损失函数和优化器
loss_fn=nn.CrossEntropyLoss()
optimizer=torch.optim.SGD(model.parameters(),lr=1e-3)
4.定义训练函数
def train(dataloader,model,loss_fn,optimizer):
size=len(dataloader.dataset)
model.train()
for batch,(X,y) in enumerate(dataloader):
X,y=X.to(device),y.to(device)
#计算预测误差
pred=model(X)
loss=loss_fn(pred,y)#parameter:input,target
#反向传播
optimizer.zero_grad()# 清空参数梯度
loss.backward() # 计算参数的梯度
optimizer.step() # 更新参数梯度
if batch %100 ==0:
loss,current=loss.item(),batch*len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
训练函数需要哪些东西?
- 数据:dataloader
- 模型:model
- 损失函数:loss_fn
- 优化器:optimizer
数据的标签y是如何确定的?
在之前用torch.util.data.DataLoader包装数据时就已确定了y
model.train()的作用?
model.train()将模型设置为训练模式。
解释:
在进行深度学习PyTorch实战的过程中,我们时常需要在训练和评估两种模式间切换。训练模式对应了模型的学习阶段,评估模式则是为了检验模型的性能。在PyTorch中,我们通过调用model.train()和model.eval()来实现这种切换。这两个方法的使用至关重要,因为它们会影响到某些层的运作方式,例如Dropout和BatchNorm。
训练模式 vs 评估模式
| 模式 | 标志 | 前向传播 | 反向传播 | 参数更新 | Dropout 层行为 | BatchNorm 层行为 |
|---|---|---|---|---|---|---|
| 训练模式 | model.train() | 是 | 是 | 是 | 随机将一部分神经元关闭,以防止过拟合 | 使用每一批数据的均值和方差进行归一化处理 |
| 评估模式 | model.eval() | 是 | 否 | 否 | 关闭所有神经元,不再进行随机舍弃 | 使用在训练阶段计算得到的全局统计数据进行归一化处理。 |
-
训练模式(Training Mode):如表格所示,在此模式下,模型会进行前向传播、反向传播以及参数更新。某些层,如Dropout层和BatchNorm层,在此模式下的行为会与评估模式下不同。例如,Dropout层会在训练过程中随机将一部分输入设置为0,以防止过拟合。
-
**评估模式(Evaluation Mode):**如表格所示,在此模式下,模型只会进行前向传播,不会进行反向传播和参数更新。Dropout层会停止dropout,BatchNorm层会使用在训练阶段计算得到的全局统计数据,而不是测试集中的批统计数据
训练步骤?
计算损失-通过反向传播优化/更新参数
optimizer.zero_grad()# 清空参数梯度
loss.backward() # 计算参数的梯度
optimizer.step() # 更新参数梯度
5.定义测试函数
def test(dataloader,model,loss_fn):
size=len(dataloader.dataset) #数据集中样本的总数
num_batches=len(dataloader) #迭代器的批量大小
model.eval()
test_loss,correct=0,0
with torch.no_grad():
for X,y in dataloader:
X,y=X.to(device),y.to(device)
pred=model(X)
test_loss+=loss_fn(pred,y).item()
correct+=(pred.argmax(1)==y).type(torch.float).sum().item()#正确的个数
test_loss/=num_batches #每个batch的平均损失
correct/=size #整个数据集的平均正确率
print(f"Test Error:\n Accuracy:{(100*correct):>0.1f}%, Avg loss:{test_loss:>8f}\n")
测试函数需要哪些东西?
- 数据:dataloader
- 模型:model
- 损失函数:loss_fn
没有优化器,因为它不需要优化
model.eval()的作用?
model.eval()会将模型设置为评估模式,用于确保模型在评估模式下以一致且确定的方式运行,以获得准确和可靠的评估预测结果。
具体见上表格!
pred.argmax(1)==y是什么意思?
argmax()
(1)针对一维数组:返回数组中最大值元素的索引位置,
这里指的是预测的种类与真实值种类数值一样,也就是预测值=真实值
核心?
计算损失和准确率
6.训练
epochs=20
for epoch in range(epochs):
print(f"Epoch {epoch+1}\n----------------------------")
train(train_loader,model,loss_fn,optimizer)
test(test_loader,model,loss_fn)
print("Done!")















 3659
3659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









