







YOLOv7项目运行
代码里面也含有论文
推理
On video:
python detect.py --weights yolov7.pt --conf 0.25 --img-size 640 --source yourvideo.mp4
On image:
python detect.py --weights yolov7.pt --conf 0.25 --img-size 640 --source inference/images/horses.jpg
detect.py:
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='yolov7.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='inference/images', help='source') # file/folder, 0 for webcam
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
解释:weights:训练好的模型路径 source:测试图片的路径。 img-size:图片输入的大小。 conf-thres:置信度的下线。 iou-thres:IOU的阈值 device:GPU的编号,或者设置为cpu。 然后就可以运行detect.py脚本了。
具体见YOLOv7项目的readme
demo:Google Colab

训练
项目来源:【安全帽识别-新手任务】-视觉算法打榜-极市开发者平台 (cvmart.net)
自带数据集
1.数据集制作
由于该项目自带数据集,不用做特别处理,直接运行脚本/project/train/src_repo/run.sh
#训练脚本 -->执行数据集划分、转换脚本,执行YOLOV5训练模块。
#run.sh
rm -r /project/train/src_repo/dataset
#创建数据集相关文件夹
mkdir /project/train/src_repo/dataset
mkdir /project/train/src_repo/dataset/Annotations
mkdir /project/train/src_repo/dataset/images
mkdir /project/train/src_repo/dataset/ImageSets
mkdir /project/train/src_repo/dataset/labels
mkdir /project/train/src_repo/dataset/ImageSets/Main
cp /home/data/831/*.xml /project/train/src_repo/dataset/Annotations
cp /home/data/831/*.jpg /project/train/src_repo/dataset/images
#执行数据集划分、转换
python /project/train/src_repo/split_train_val.py --xml_path /project/train/src_repo/dataset/Annotations --txt_path /project/train/src_repo/dataset/ImageSets/Main
cp /project/train/src_repo/voc_label.py /project/train/src_repo/dataset
python /project/train/src_repo/dataset/voc_label.py
得到:
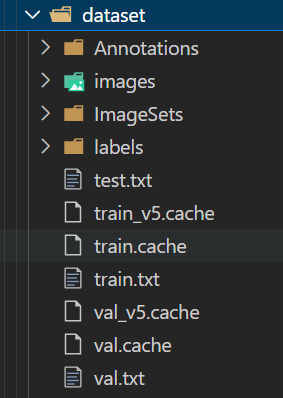
Annotations文件夹存放的是之前的xml标注文件,images存放的是所有图片,labels文件夹存放的是所有yolov7需要的标注文件,以.txt文件呈现,test.txt trian.txt val.txt都是划分的数据集,里面存放的是相应的图片数据位置,剩下的ImageSets放的是划分文件的名字,.cache文件存放的是运行过程中产生的缓存,不重要
总之,得到以下格式的数据集就行:
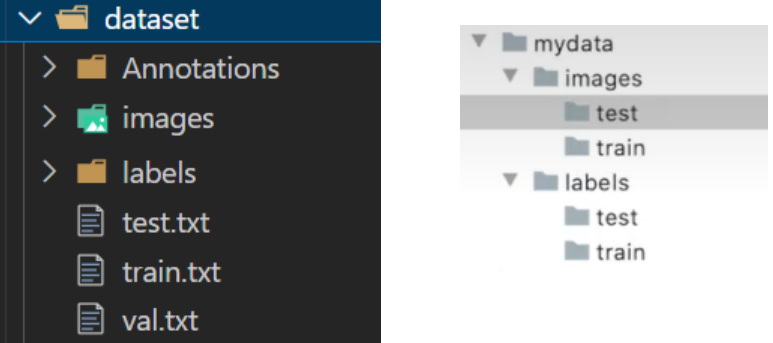
左边是所有图片和标签在一个文件夹下,用文档进行划分;右边是将图片和标签直接划分到对应文档下(注意images-labels/test-train,图片标签在上级目录,而不是test和train)
2.创建yaml文件
将标签数据、类别数量及名称按以下格式写好:
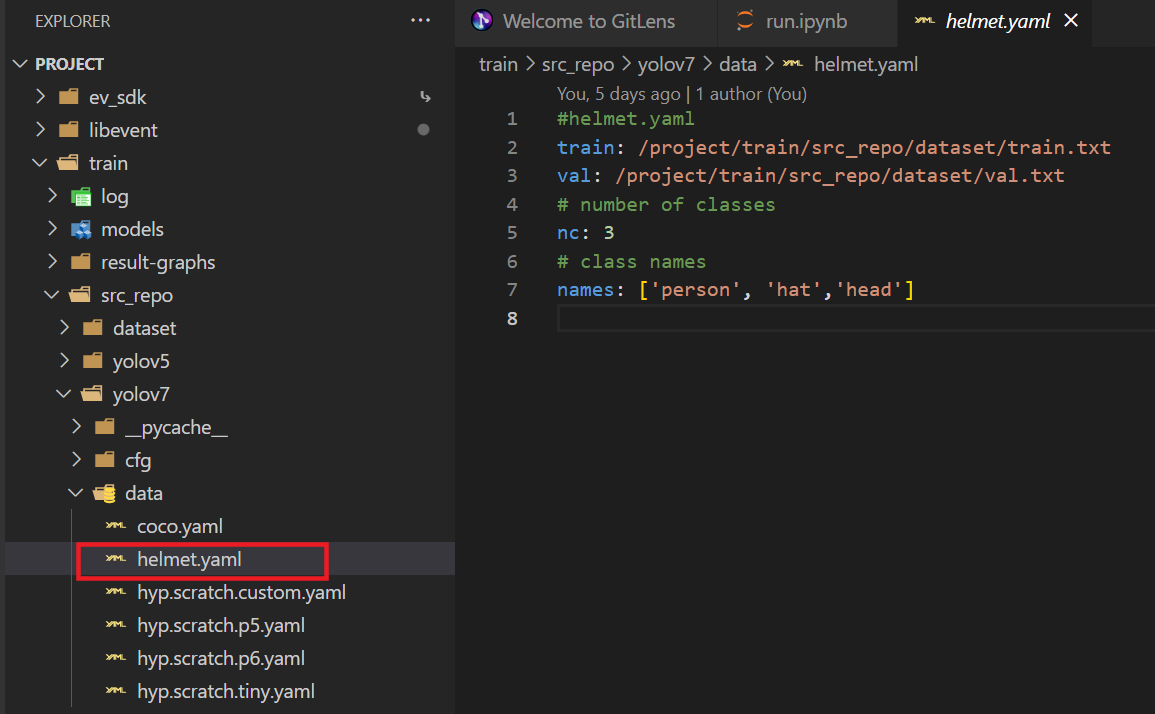
3.运行脚本训练
# train p5 models
!python train.py --weights '' --cfg cfg/training/yolov7.yaml --data data/helmet.yaml --epochs 300 --batch-size 16
YOLOv7比YOLOv5参数更多,训练速度相比要慢,而且由于网络原因,我这还没训练完就断了
还好有继续训练机制,使用–resume参数,从上次最后一个开始:
!python train.py --weights 'train/src_repo/yolov7/runs/train/exp6/weights/last.pt' --cfg cfg/training/yolov7.yaml --data data/helmet.yaml --epochs 300 --batch-size 16 --resume
完成:
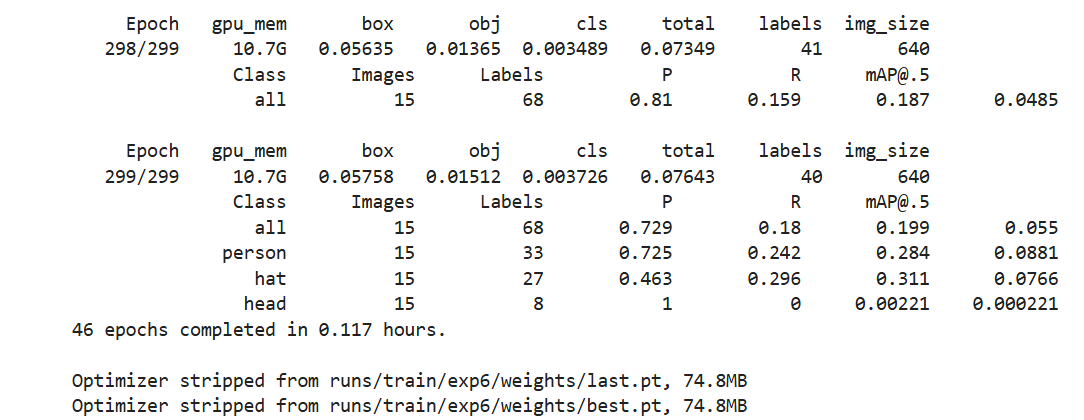
遇到的问题
Traceback (most recent call last):
File "train.py", line 616, in <module>
train(hyp, opt, device, tb_writer)
File "train.py", line 248, in train
image_weights=opt.image_weights, quad=opt.quad, prefix=colorstr('train: '))
File "/project/train/src_repo/yolov7/utils/datasets.py", line 78, in create_dataloader
prefix=prefix)
File "/project/train/src_repo/yolov7/utils/datasets.py", line 392, in __init__
cache, exists = torch.load(cache_path), True # load
File "/usr/local/lib/python3.7/dist-packages/torch/serialization.py", line 608, in load
return _legacy_load(opened_file, map_location, pickle_module, **pickle_load_args)
File "/usr/local/lib/python3.7/dist-packages/torch/serialization.py", line 777, in _legacy_load
magic_number = pickle_module.load(f, **pickle_load_args)
_pickle.UnpicklingError: STACK_GLOBAL requires str
数据标签的cache的原因
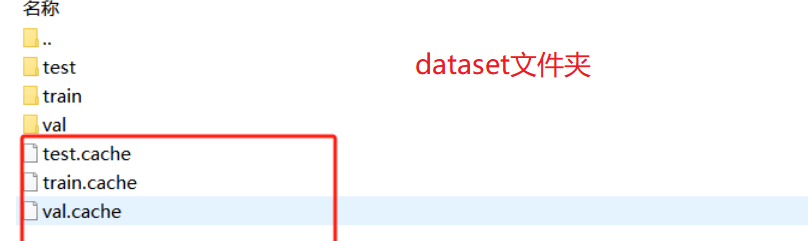
因此删除.cache文件















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









