







目录
支持向量机(SVM)
与逻辑回归和神经网络相比,在学习复杂的非线性方程时,能够提供一种更为清晰的和更加强大的方式。因此讲解花费的视频是最长的的。
优化目标
逻辑回归通过一系列改变变为支持向量机。我尽量保存了每张讲解截图。


图中粉色的直线,会使支持向量机拥有计算上的优势,并使得之后的优化问题变的简单,更易解决给图中粉色的线取一个新的名字左边的为cost_1(z),右边的为cost_0(z),<cost的下标 1:y=1;0:y=0>
有了上面的cost下面来构造支持向量机。(用直线代替原来的曲线)相比于逻辑回归,第一处变化,去掉前面的常数项1/m,不影响最小化的结果。第二处不同:控制权重的方式不同。用A表示原来式子中的第一项,B表示去掉m后的第二项:A+λB(首先考虑的不是计算,而是通过设定不同的正则化参数λ的值,以便能够权衡我们想在多大程度上去适应训练集:即最小化A还是更多的去保持λ足够小)对SMV,不再用λ,按照惯例用C表示成:C*A+B。

最终SVM的最终优化目标为,并且SVM最后不会输出概率,我们得到的是通过优化代价函数,得到一个参数θ,SVM直接预测y=1/0。因此SVM的假设函数与代价函数如下图所示。

直观上对"大间隔"的理解
有时人们会把SVM叫做“大间隔分类器”。
当我们有一个正样本(即y=1),当保证>=0是就能保证分类正确,但通常我们会设一个安全间离,让它大于等于1。同样的,当得到一个负样本是,我们通常让
<-1。

接下来考虑一种情况:将常数C设成一个非常大的值,如C=10w,看SVM会做什么?
把最小化代价函数转变为,通过选择参数θ,使得第一项=0,则优化问题将变成如下图所示,st(表示受小面这些情况约束)。将得到一个有趣的决策边界。如第二张图所示

SVM会选择黑色的决策边界(图中黑色线与蓝色线的间距叫做"支持向量机的间距")这使得SVM具有鲁棒性(鲁棒是Robust的音译,也就是健壮和强壮的意思。它也是在异常和危险情况下系统生存的能力),因为你他在分离数据时,会尽量用大的间距去分离(即尽量将正负样本以最大的间距分开)。因此被称为"大间距分类器"。

实际上SVM比这个大间距的视图更加复杂。尤其当只使用SVM时,这是学习算法对异常点会很敏感,如下图,如果C很大,一个异常点会将决策边界编程粉色的那一条;如果C较小,最后得到的还是黑色的决策边界。如果正样本中有几个负样本,负样本中也有几个正样本,这是SVM仍然可以正确的分类。当C很大时,能够帮助人更直观的理解SVM,这里的C类似于1/λ。在实际应用SVM时,当C不是非常大时,他可以忽略这样的异常点,来得到正确的分类结果,甚至当数据不是线性可分时SVM也能做的很好 。

*大间隔分类器的数学原理
向量内积的性质
设u,v为两个向量,u^Tv(向量内积)=||u||*p=u1v1+u2v2=v^Tu
||u||:表示u的欧几里得长度(也叫u的范数),根据毕达哥拉斯定理(名字听着像没见过一样)=sqrt(u1^2+u2^2)
图中p:即v在u上的投影的长度
注意:当两个向量的夹角大于90度时,p为负的

理解SVM 中的优化目标函数

SVM是通过最小化参数θ来实现决策,因此,如下图所示,它会选择间距大的边界来减小θ的值。

θ0=0是为了让它过原点,即使不等于0,SVM也能的得到大间距的边界
核函数1
非线性分界线
下面用fi(i=1,2,3...)表示特征(xi)

当输入是一张图片时,即很多像素点组成,计算量将是很巨大的。
高斯核函数
 对于特征x_1,x_2,手动选取一些点,然后将这些点叫做L(1),L(2),L(3),把这些点叫做标记(标记1,2,3),我们要做的是,像这样定义新的特征:给定一个实例x,我们将第一个特征f_1定义为一种相似度的度量(即度量训练样本x与第一个标记的相似度)。这个用于度量的公式定义为exp(如图中所示:分子:即欧氏距离取平方)相似度函数用数学的术语说就是核函数,记为k(x,l^(i))这里用到的核函数实际上是高斯核函数。
对于特征x_1,x_2,手动选取一些点,然后将这些点叫做L(1),L(2),L(3),把这些点叫做标记(标记1,2,3),我们要做的是,像这样定义新的特征:给定一个实例x,我们将第一个特征f_1定义为一种相似度的度量(即度量训练样本x与第一个标记的相似度)。这个用于度量的公式定义为exp(如图中所示:分子:即欧氏距离取平方)相似度函数用数学的术语说就是核函数,记为k(x,l^(i))这里用到的核函数实际上是高斯核函数。

输入x由相似度函数计算得到的记为新的特征f(1/2/3) :f_1:表示x与标记1之间的距离
例子

下图这个例子是标记点和核函数来训练出非常复杂的非线性决策边界的方法。例子中当接近l1和l2时,预测y=1,远离时,y=0。

核函数2
怎样选取标记点?
我们的数据中有一些正样本和一些负样本,直接将训练样本点作为标记点。

如何使用简单的SVM

已知参数θ时,怎么做预测的过程如下图的前两行,后一部分中,当你最小化时,用θ转置*f来代替x预测。式子第二项的求和符号上面的n是特征量=f的维度。实际应用中,后面这一项会不同,但不需要了解太多。用表示另一种距离度量方法,可以使得SMV更有效率的运行,并且这个修改可以使SVM应用于更大的训练集。如果将核函数应用在逻辑回归上,将会很慢。

怎么选择参数C(1/λ)与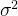 ?
?
如果C过小,相当于λ过大,此时会出现高偏差低方差;相反,会出现高方差低偏差。
偏大时,相似度函数相对平滑(变化缓慢,会给模型带来高偏差第方差) ,相反变化很剧烈。

使用SVM
使用软件库来解决参数θ的计算。需要做的是:首先选择参数C的选择,第二选择内核参数或者你想用的相似度函数。
一种选择是线性内核函数也可以说是一种没有内核参数的SVM:可以想成只是给你一个标准的线性分类器。另一种核函数选择即高斯核函数。(这是两个最常用的)

实现核函数
在使用高斯核函数之前,对特征范围差别较大的数据进行缩放比例使得SVM考虑到所有不同的特征变量,避免出现某个特征影响较大。

不是所有的核函数都是有效的。这些函数都需要满足一个技术条件,即默塞尔定理。这个定理是保证所有SVM包,所有SVM软件包都能用大量的优化算法并从而迅速得到参数θ。可能会遇到有人要多项式核函数如下图(通常x和l都是非负的保证内积值永远不为负)
比较难懂的核函数如:字符串核函数、卡方核函数。直方相交核函数等等用来测量不同目标间的相似度。(很少使用)
输出多类别分类的判定边界
大多数SVM库内置了多分类的函数

逻辑回归vsSVM
当特征数n>=m相对较小的训练集时,选逻辑回归或者用不带核函数的SVM;
如果n很少和一个适中的训练样本数量,通常线性SVM工作的很好;
如果n很小,m很大,这时带有高斯核函数的SVM运算会很慢,这时通常会手动的选择一些特征然后使用逻辑回归或者不带核函数的SVM。
在这里,神经网络可能比SVM慢的多。SVM具有的优化问题是一种凸优化问题
可以看出逻辑回归和不带核函数的SVM很相似。但对具体问题,其中一个可能效果更好。

高斯内核的SVM应用ex6
线性SVM--数据1
# 线性SVM
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
from scipy.io import loadmat
raw_data = loadmat('E:/Python/machine learning/data/ex6data1.mat')
data = pd.DataFrame(raw_data.get('X'), columns=['X1', 'X2'])
data['y'] = raw_data.get('y')
data.head()| X1 | X2 | y | |
|---|---|---|---|
| 0 | 1.9643 | 4.5957 | 1 |
| 1 | 2.2753 | 3.8589 | 1 |
| 2 | 2.9781 | 4.5651 | 1 |
| 3 | 2.9320 | 3.5519 | 1 |
| 4 | 3.5772 | 2.8560 | 1 |
# 数据可视化
def plot_init_data(data, fig, ax):
positive = data[data['y'].isin([1])]
negative = data[data['y'].isin([0])]
ax.scatter(positive['X1'], positive['X2'], s=50, marker='x', label='Positive')
ax.scatter(negative['X1'], negative['X2'], s=50, marker='o', label='Negative')
fig, ax = plt.subplots(figsize=(12,8))
plot_init_data(data, fig, ax)
ax.legend()
plt.show()
# 令C=1
from sklearn import svm
svc = svm.LinearSVC(C=1, loss='hinge', max_iter=1000)
print(svc)
svc.fit(data[['X1', 'X2']], data['y'])
print(svc.score(data[['X1', 'X2']], data['y']))LinearSVC(C=1, loss='hinge') 0.9803921568627451

# 令C=100
svc2 = svm.LinearSVC(C=100, loss='hinge', max_iter=1000)
svc2.fit(data[['X1', 'X2']], data['y'])
print(svc2.score(data[['X1', 'X2']], data['y']))
x1, x2 = find_decision_boundary(svc, 0, 4, 1.5, 5, 2 * 10**-3)
fig, ax = plt.subplots(figsize=(12,8))
ax.scatter(x1, x2, s=10, c='r',label='Boundary')
plot_init_data(data, fig, ax)
ax.set_title('SVM (C=100) Decision Boundary')
ax.legend()
plt.show()0.9411764705882353

# 高斯内核的SVM
def gaussian_kernel(x1, x2, sigma):
return np.exp(-(np.sum((x1 - x2) ** 2) / (2 * (sigma ** 2))))
x1 = np.array([1.0, 2.0, 1.0])
x2 = np.array([0.0, 4.0, -1.0])
sigma = 2
gaussian_kernel(x1, x2, sigma)0.32465246735834974
非线性数据2
# 高斯内核函数SVM
raw_data = loadmat('E:/Python/machine learning/data/ex6data2.mat')
data = pd.DataFrame(raw_data['X'], columns=['X1', 'X2'])
data['y'] = raw_data['y']
fig, ax = plt.subplots(figsize=(12,8))
plot_init_data(data, fig, ax)
ax.legend()
plt.show()
svc = svm.SVC(C=100, gamma=10, probability=True)
print(svc)
svc.fit(data[['X1', 'X2']], data['y'])
print(svc.score(data[['X1', 'X2']], data['y']))
x1, x2 = find_decision_boundary(svc, 0, 1, 0.4, 1, 0.01)
fig, ax = plt.subplots(figsize=(12,8))
plot_init_data(data, fig, ax)
ax.scatter(x1, x2, s=10)
plt.show()SVC(C=100, gamma=10, probability=True) 0.9698725376593279

数据集3
给出了训练和验证集,并且基于验证集性能为SVM模型找到最优超参数。
现在需要寻找最优C和σ,候选数值为[0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30, 100]
raw_data = loadmat('E:/Python/machine learning/data/ex6data3.mat')
X = raw_data['X']
Xval = raw_data['Xval']
y = raw_data['y'].ravel()
yval = raw_data['yval'].ravel()
fig, ax = plt.subplots(figsize=(12,8))
data = pd.DataFrame(raw_data.get('X'), columns=['X1', 'X2'])
data['y'] = raw_data.get('y')
plot_init_data(data, fig, ax)
plt.show()
C_values = [0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30, 100]
gamma_values = [0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30, 100]
best_score = 0
best_params = {'C': None, 'gamma': None}
for C in C_values:
for gamma in gamma_values:
svc = svm.SVC(C=C, gamma=gamma)
svc.fit(X, y)
score = svc.score(Xval, yval)
if score > best_score:
best_score = score
best_params['C'] = C
best_params['gamma'] = gamma
best_score, best_params
(0.965, {'C': 0.3, 'gamma': 100})
svc = svm.SVC(C=best_params['C'], gamma=best_params['gamma'])
svc.fit(X, y)
x1, x2 = find_decision_boundary(svc, -0.6, 0.3, -0.7, 0.6, 0.005)
fig, ax = plt.subplots(figsize=(12,8))
plot_init_data(data, fig, ax)
ax.scatter(x1, x2, s=10)
plt.show()
使用SVM来构建垃圾邮件过滤器
# 直接读取预先处理好的数据
spam_train = loadmat('E:/Python/machine learning/data/spamTrain.mat')
spam_test = loadmat('E:/Python/machine learning/data/spamTest.mat')
spam_train
{'__header__': b'MATLAB 5.0 MAT-file, Platform: GLNXA64, Created on: Sun Nov 13 14:27:25 2011',
'__version__': '1.0',
'__globals__': [],
'X': array([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 1, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]], dtype=uint8),
'y': array([[1],
[1],
[0],
...,
[1],
[0],
[0]], dtype=uint8)}
X = spam_train['X']
Xtest = spam_test['Xtest']
y = spam_train['y'].ravel()
ytest = spam_test['ytest'].ravel()
print(X.shape, y.shape, Xtest.shape, ytest.shape)
# 每个文档已经转换为一个向量,其中1,899个维对应于词汇表中的1,899个单词。 它们的值为二进制,表示文档中是否存在单词
svc = svm.SVC()
svc.fit(X, y)
print('Training accuracy = {0}%'.format(np.round(svc.score(X, y) * 100, 2)))
print('Test accuracy = {0}%'.format(np.round(svc.score(Xtest, ytest) * 100, 2)))(4000, 1899) (4000,) (1000, 1899) (1000,) SVC() Training accuracy = 99.32% Test accuracy = 98.7%
# 可视化结果
kw = np.eye(1899)
kw[:3,:]
spam_val = pd.DataFrame({'idx':range(1899)})
spam_val['isspam'] = svc.decision_function(kw)
spam_val['isspam'].describe()count 1899.000000 mean -0.110039 std 0.049094 min -0.428396 25% -0.131213 50% -0.111985 75% -0.091973 max 0.396286 Name: isspam, dtype: float64
decision = spam_val[spam_val['isspam'] > -0.55]
print(decision)idx isspam 0 0 -0.093653 1 1 -0.083078 2 2 -0.109401 3 3 -0.119685 4 4 -0.165824 ... ... ... 1894 1894 0.101613 1895 1895 -0.016065 1896 1896 -0.151573 1897 1897 -0.109022 1898 1898 -0.091970 [1899 rows x 2 columns]
path = 'E:/Python/machine learning/data/vocab.txt'
voc = pd.read_csv(path, header=None, names=['idx', 'voc'], sep = '\t')
voc.head()| idx | voc | |
|---|---|---|
| 0 | 1 | aa |
| 1 | 2 | ab |
| 2 | 3 | abil |
| 3 | 4 | abl |
| 4 | 5 | about |
spamvoc = voc.loc[list(decision['idx'])]
print(spamvoc)idx voc 0 1 aa 1 2 ab 2 3 abil 3 4 abl 4 5 about ... ... ... 1894 1895 your 1895 1896 yourself 1896 1897 zdnet 1897 1898 zero 1898 1899 zip [1899 rows x 2 columns]
















 1225
1225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









