







在深度学习中,归一化是将输入数据调整到一个标准范围内的过程,这有助于模型训练的稳定性和收敛速度。以下是一些常见的归一化函数:
最小-最大归一化(Min-Max Normalization)
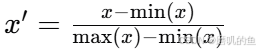
其中 x 是原始数据, x’ 是归一化后的数据。
Z分数归一化(Z-score Normalization)
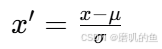
其中 μ 是数据的均值,σ 是数据的标准差。
小数定标归一化(Decimal Scaling)
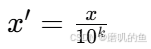
其中 k 是一个常数,使得 x’ 的绝对值小于1。
对数归一化(Logarithmic Normalization)
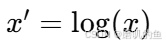
适用于正数数据,可以减少数据的尺度差异。
幂律归一化(Power Normalization)
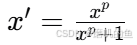
其中 p 是一个常数,用于调整归一化的效果。
正切双曲归一化(Hyperbolic Tangent Normalization)

将输入值映射到(-1, 1)区间。
批量归一化(Batch Normalization)
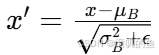
其中 μ_B 和 σ_B 分别是当前批次数据的均值和方差, ϵ 是一个很小的常数,用于防止除以零。
层归一化(Layer Normalization)
![[ x' = \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} ]](https://i-blog.csdnimg.cn/direct/f79cda85a1a0447a800a6ddc29ca4440.png)
与批量归一化类似,但是是在单个样本的特征上进行归一化,而不是整个批次。
组归一化(Group Normalization)
![[ x' = \frac{x - \mu_G}{\sqrt{\sigma_G^2 + \epsilon}} ]](https://i-blog.csdnimg.cn/direct/73c7908654ea41abbec7fa61290b72e2.png)
类似于层归一化,但是将输入数据分成多个组,然后在每个组内进行归一化。
实例归一化(Instance Normalization)
![[ x' = \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} ]](https://i-blog.csdnimg.cn/direct/290649e817c645f5b8ce25b1e0136824.png)
与层归一化类似,但是是针对单个样本进行归一化,而不是整个批次。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









