






 本文详细介绍了如何在PyCharm中设置Python环境,通过AutoDL租用GPU,上传文件至远程服务器,以及在Xftp上进行高效上传。重点讲述了使用yolov7模型的训练过程,包括不同epoch下的性能评估和错误解决方案。
本文详细介绍了如何在PyCharm中设置Python环境,通过AutoDL租用GPU,上传文件至远程服务器,以及在Xftp上进行高效上传。重点讲述了使用yolov7模型的训练过程,包括不同epoch下的性能评估和错误解决方案。
写在前面
这个主要是python课设
我使用的pycharm是2023.2.2版本
目录
1. 创建实例
AutoDL网址:
AutoDL算力云 | 弹性、好用、省钱。租GPU就上AutoDL
(1)选择租用新实例

(2)选择镜像
上面的按需选择,这里选择的是大佬上传的“yolov7-v2“的”社区镜像”,在此感谢大佬,省去了我在网上看半天怎么搞租用GPU后配置GPU版本pytorch的麻烦。(当然可能也不麻烦,只是涉及知识盲区,我就会一头雾水。)

2. 上传文件
2.1 打包成zip上传
将整个项目文件打包成zip,在“我的网盘”上传。
参考AutoDL上传数据详细步骤(自己用的步骤,可能没有其他大佬用的那么高级)-CSDN博客
也可以用Xftp。
Note:你要租用哪个地区的GPU就创建哪个地区的网盘,免费存储空间20G
(先进行这一步是因为上传的太慢,实例运行过程要钱,当然也可以先创建再关机)
好吧实在太慢了,我还是用Xftp吧
2.2 Xftp上传(推荐)
下载地址:家庭/学校免费 - NetSarang Website (xshell.com)

安装过程参考:Xftp的下载和安装教程(图文教程)_技术员网 (jishuy.com)
Note:亲测不注册登陆也可以用,直接回车就行
2.2.1 打开Xftp,点击新建

2.2.2 输入信息连接主机
从Autodl复制登陆指令

复制后在别的窗口或者文件粘贴,可以得到形为
ssh -p xxxxx root@xxxxxxxxx
其中,
主机为@后面的所有东西
端口号为-p和root中间的数字
用户名为root
密码在autodl网页上登陆指令的下面
将上述内容填入Xftp新建会话中,名称随便填,别搞混就行。

点击连接。
2.2.3 上传文件
在右侧打开autodl-nas文件夹,开始上传文件。

传的快多了,我传2.37G的文件夹大概5-6分钟。

搞定!
3. 连接pycharm
如果第二步是用的Xftp且是无卡模式开机,咱们就先关机重新开机。
如果你的GPU被占用了开不了也不要慌,重新租一台,只要还是原来的区,原来的镜像就可以。
两种连接方式:
3.1 通过setting里面的编译器(推荐)
(1)“File”->"Settings..."

(2)"Python Interpreter"->"Add Interpreter"->"On SSH"

(3)然后就是正常的输入Host,Port,Username和password的过程

(4)这一步选择“System Interpreter”,然后默认值即可,点击“Create”

3.2 通过Tool 里的 Deployment
(1)选择“Deployment” -> "Confiuration..."

(2)添加SSH

(3)从AutoDL已经开机的实例复制SSH和密码,配置pycharm。Host是@之后的部分,Port为前面的数字,Username为root。
Note:最好点“Save possword”!

(4)点击“OK”后:
取消勾选“Visible only for this project”
测试连接:点击“Test Connect”,大概率都没问题,我是没有遇到的。
设置root path:按图中设置即可
点击“OK”

4. 查看代码并运行
(1)点击“Tools”->"Deployment"->"Browse Remote Host"

(2)然后可在右侧查看云上文件,找到自己上传的文件夹,我的文件夹如图所示。

(3)勾选终端(忽略一下我的内容,因为我已经开始运行了)

(4)运行代码
在右侧自己上传的文件夹中打开要运行的文件,我的是train.py
!!!!!!Note(特别重要,含泪踩坑):
运行代码一定要在终端打开你的project所在的文件夹,再在终端运行
例如我的文件夹上面那张可以看到,所以我需要在终端输入
cd autodl-nas/yolov7-main/
python train.py对于你们,就要输入
cd autodl-nas/你的文件夹/
python 你要运行的文件更改代码之后一定要点右上角的upload,且改一个文件就要upload一次
(可以设置自动unload但我没设置,因为我也没改什么东西)
或者在tools里一键upload(嗯我也没用过你们可以试试)

5.报错记录
至此,教程已经全部结束,记录一下我遇到的几个报错:
1. 大部分的报错是因为我改了代码没点upload,这里不再赘述
2. Illegal char at index 0 SSH pycharm
这个报错主要还是路径问题,我用终端的办法打开project所在文件夹然后在终端运行,问题解决。
还是把上面的步骤搬下来。
在终端输入
cd autodl-nas/yolov7-main/
python train.py即输入
cd autodl-nas/你的文件夹/
python 你要运行的文件3. AutoDL CUDA out of memory. Tried to allocate 400.00 MiB (GPU 0; 10.75 GiB total capacity; 8.61 GiB already allocated; 26.50 MiB free; 9.43 GiB reserved in total by PyTorch)
这个我一开始以为是batch_size的锅,改成4了还是报错,最后点“实例监控”看了一下,发现CPU的
占用率都超过1000%了(轻轻趋势),我才想起来好像是我把workers搞成8了,依稀记得workers是用来加速的CPU数量吧,直接改成0(应该是使用1个cpu加速的意思,说错算了,懒得查了),问题解决。

4. yolov7自动停止训练且再次运行报错内存不足
通过实例监控发现代码没运行但GPU还在工作,于是直接把GPU关了重启,再接着没训练完的训练完就ok
5. yolov7自动停止训练怎么继续
找到train.py中的参数‘--resume’,修改为default=True,再次运行代码就会接着train里最新的exp继续训练到上次要求的epoch。
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
静候我的训练结果再更新
6. 运行结果
6.1 50 epoch的yolov7模型


6.2 70 epoch的yolov7模型
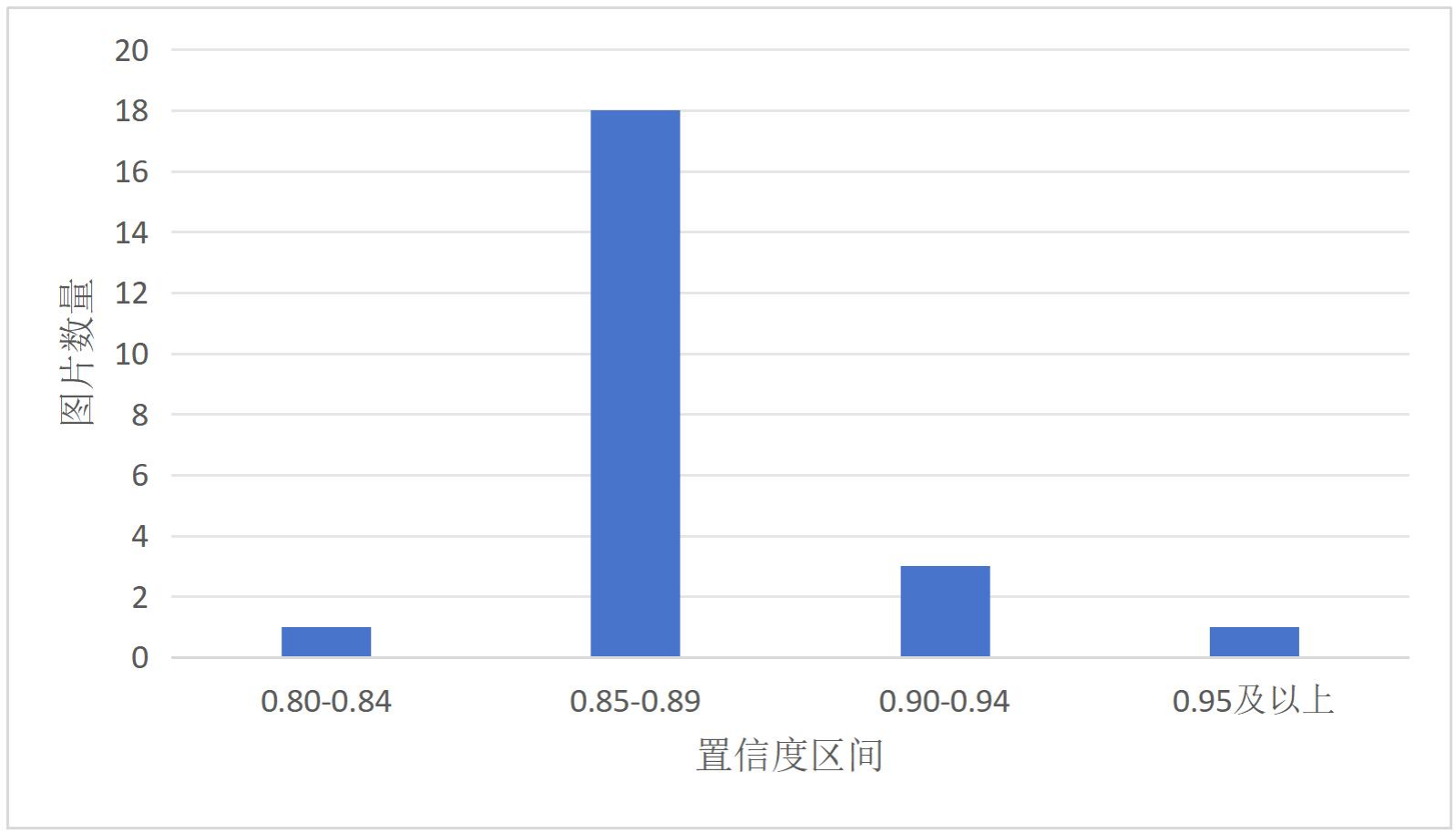

6.3 100 epoch的yolov7模型

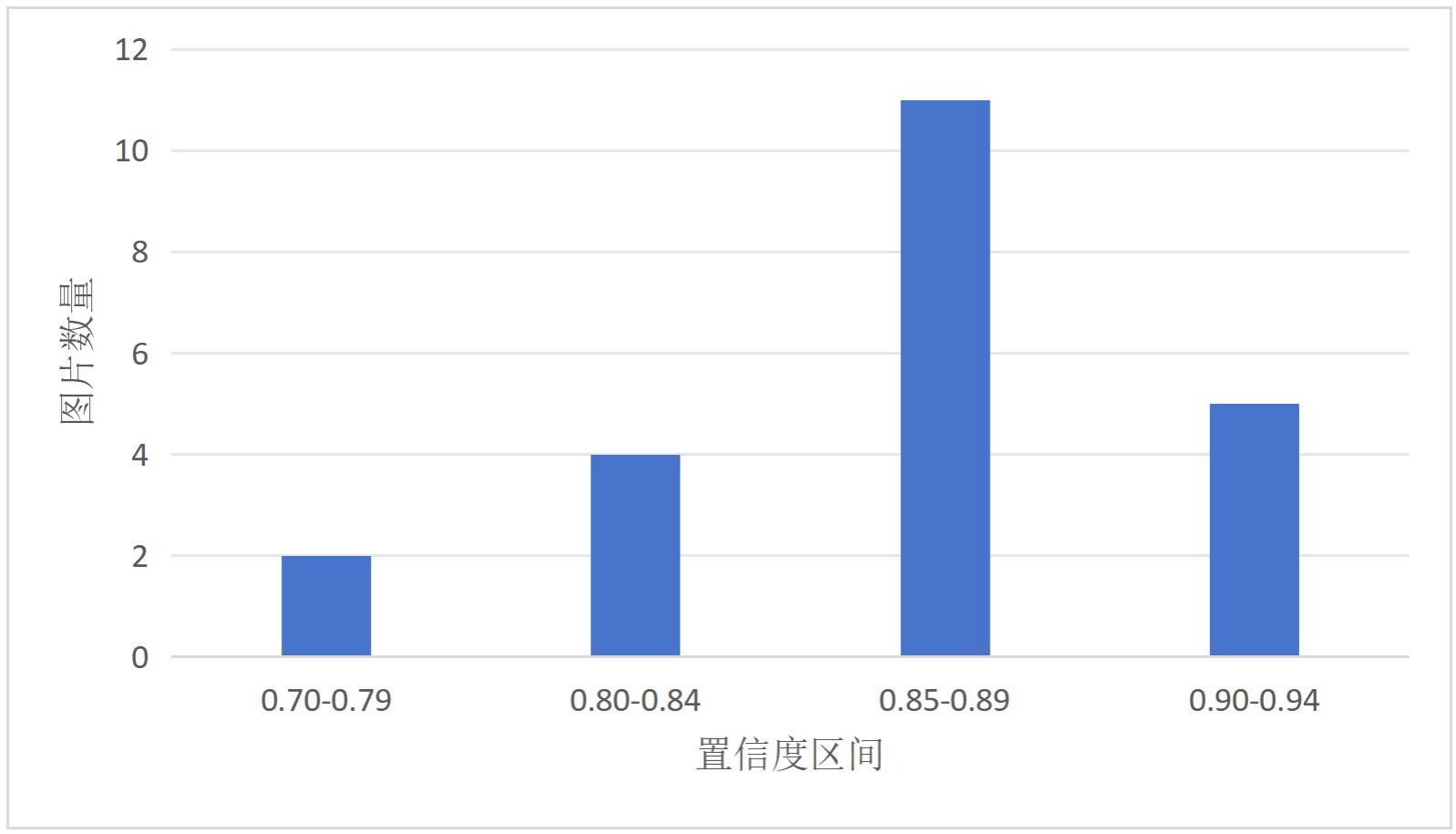

6.4 70 epoch的yolov7x模型
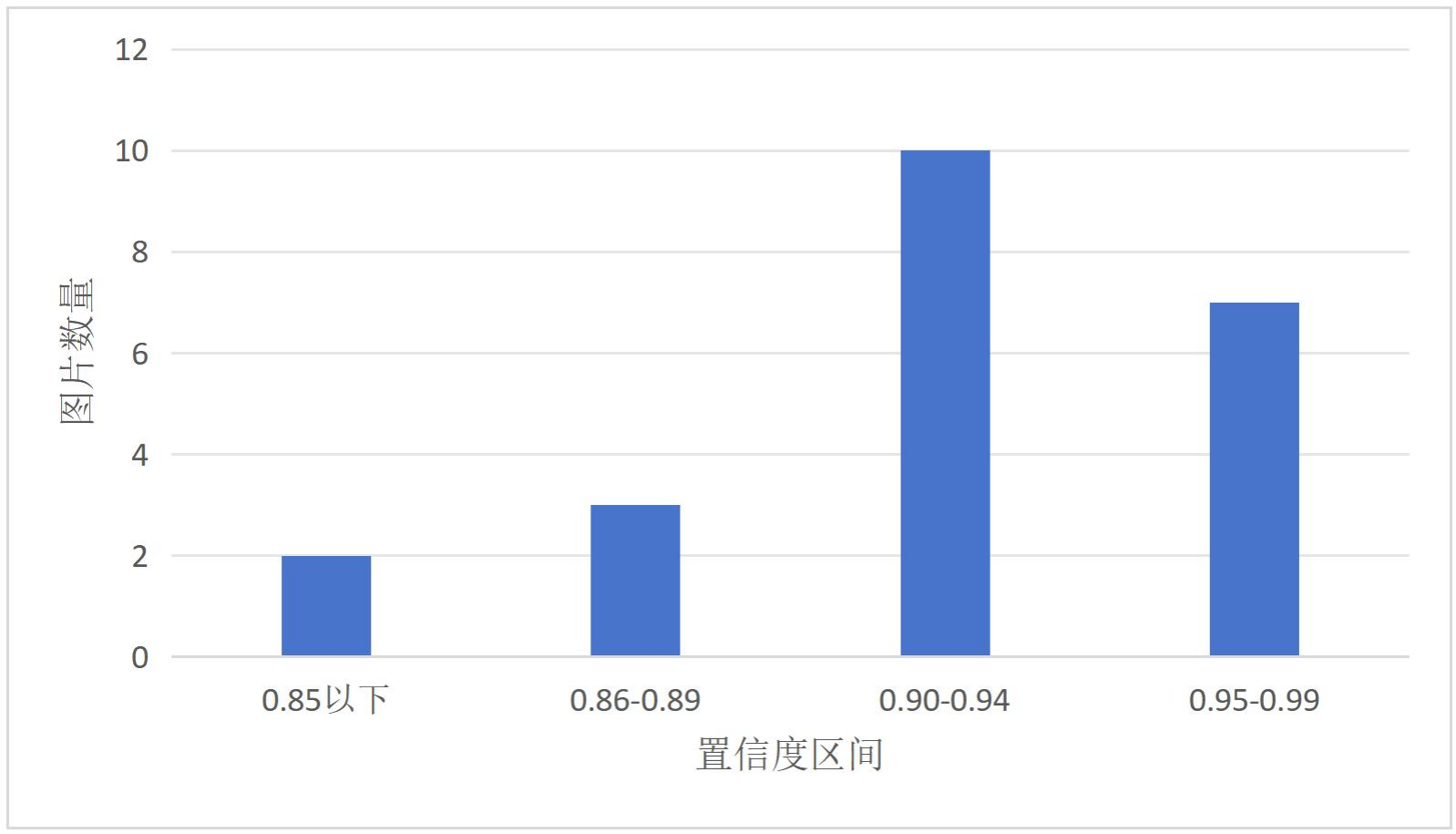
















 3998
3998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









