







在使用华为的 ModelArts 平台时,我注意到一个关键性能瓶颈,即数据在从 NPU(神经处理单元)传输到 CPU 后,仍然依赖于 CPU 进行计算。
[W VariableFallbackKernel.cpp:51] Warning: CAUTION: The operator 'aten::isin.Tensor_Tensor_out' is not currently supported on the NPU backend and will fall back to run on the CPU. This may have performance implications. (function npu_cpu_fallback)
[W VariableFallbackKernel.cpp:51] Warning: CAUTION: The operator 'aten::isin.Tensor_Tensor_out' is not currently supported on the NPU backend and will fall back to run on the CPU. This may have performance implications. (function npu_cpu_fallback)这个问题的原因是华为官方目前没有适配aten::isin.Tensor_Tensor_out这个算子,具体来说是没有适配torch.isin()这个pytorch的内部方法。它是 PyTorch 中用于判断张量元素是否在另一个张量中的函数。具体来说,它的作用是比较两个张量,返回一个布尔型张量,指示每个元素是否存在于给定的输入张量中。这个函数的典型用途包括:
-
集合运算:
torch.isin()可以用来判断一个张量的元素是否属于另一个张量,类似于数学中的集合包含关系。这对于数据筛选和条件判断非常有用。 -
条件选择:通过与其他张量结合使用,
torch.isin()可以帮助从数据集中选择满足特定条件的元素。例如,如果你有一个包含多个类别的张量,你可以使用torch.isin()选择特定类别的数据。 -
逻辑操作:与逻辑运算结合使用时,
torch.isin()可以在深度学习模型中用于实现复杂的逻辑条件,帮助调整模型的输入和输出。
示例代码
以下是一个简单的示例,展示了如何使用 torch.isin():
import torch
# 定义两个张量
a = torch.tensor([1, 2, 3, 4, 5])
b = torch.tensor([3, 4, 5, 6, 7])
# 使用 isin() 方法判断 a 中的元素是否在 b 中
result = torch.isin(a, b)
print(result) # 输出: tensor([False, False, True, True, True])在这个例子中,result 张量的每个元素对应于 a 张量中元素是否存在于 b 张量中的结果,返回的形状应该和 a 张量是一致的。
但是在华为的NPU上面就会出错:
NPU代码
import torch
from torch_npu.contrib import transfer_to_npu
# import new_torch
# torch.isin = new_torch.isin
# 定义两个张量
a = torch.tensor([1, 2, 3, 4, 5]).cuda()
b = torch.tensor([2, 4, 6]).cuda()
# 使用 isin 操作
result = torch.isin(a, b)
print(result) # 输出: tensor([False, True, False, True, False])输出结果:
warnings.warn(msg, ImportWarning)
/usr/local/Ascend/ascend-toolkit/8.0.RC3.alpha001/python/site-packages/tbe/tvm/contrib/ccec.py:861: DeprecationWarning: invalid escape sequence '\L'
if not dirpath.find("AppData\Local\Temp"):
<frozen importlib._bootstrap>:671: ImportWarning: TBEMetaPathLoader.exec_module() not found; falling back to load_module()
/usr/local/Ascend/ascend-toolkit/latest/python/site-packages/tbe/dsl/classifier/transdata/transdata_classifier.py:222: DeprecationWarning: invalid escape sequence '\B'
"""
<frozen importlib._bootstrap>:914: ImportWarning: TEMetaPathFinder.find_spec() not found; falling back to find_module()
/usr/local/Ascend/ascend-toolkit/latest/python/site-packages/tbe/dsl/unify_schedule/vector/transdata/common/graph/transdata_graph_info.py:143: DeprecationWarning: invalid escape sequence '\c'
"""
<frozen importlib._bootstrap>:914: ImportWarning: TEMetaPathFinder.find_spec() not found; falling back to find_module()
<frozen importlib._bootstrap>:671: ImportWarning: TBEMetaPathLoader.exec_module() not found; falling back to load_module()
<frozen importlib._bootstrap>:914: ImportWarning: TEMetaPathFinder.find_spec() not found; falling back to find_module()
[W VariableFallbackKernel.cpp:51] Warning: CAUTION: The operator 'aten::isin.Tensor_Tensor_out' is not currently supported on the NPU backend and will fall back to run on the CPU. This may have performance implications. (function npu_cpu_fallback)
tensor([False, True, False, True, False], device='npu:0')
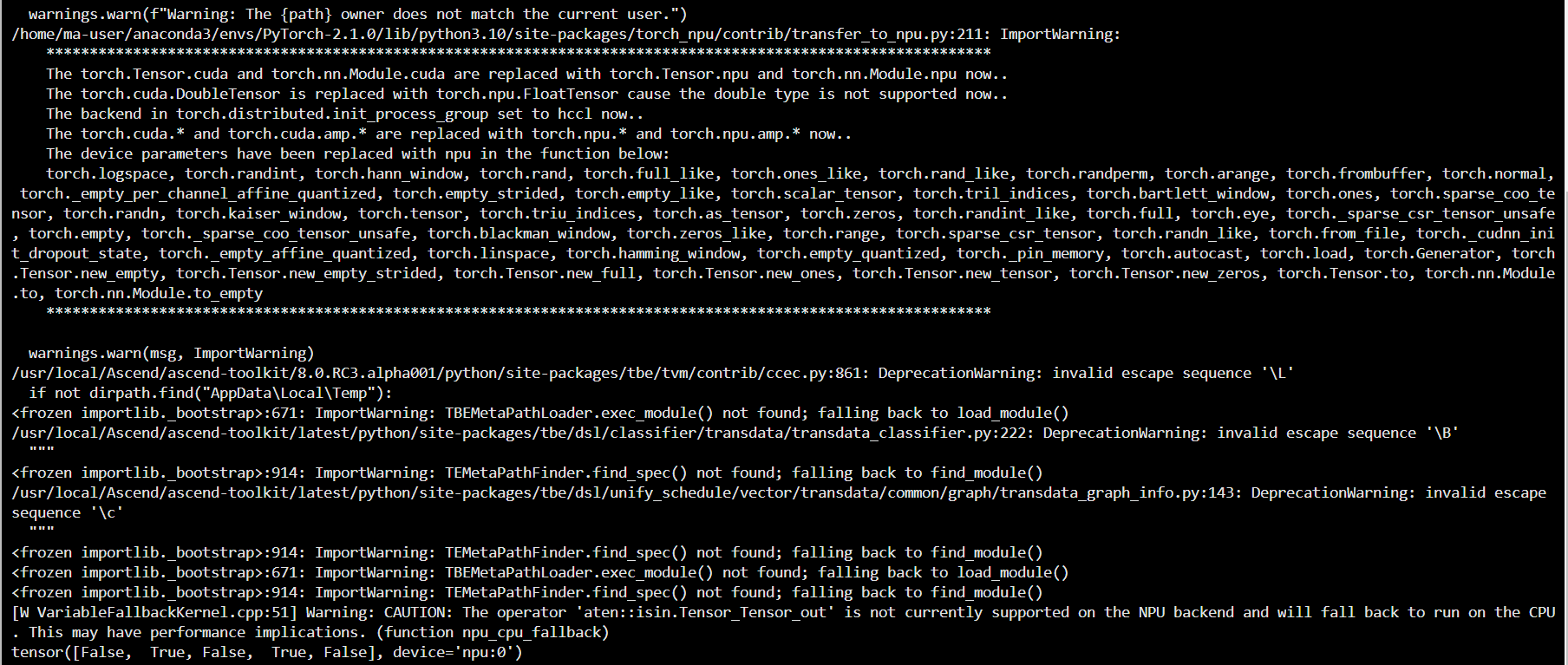
虽然也输出了结果,但是大家一定要注意 这个问题:
[W VariableFallbackKernel.cpp:51] Warning: CAUTION: The operator 'aten::isin.Tensor_Tensor_out' is not currently supported on the NPU backend and will fall back to run on the CPU. This may have performance implications. (function npu_cpu_fallback)
我以 Qwen2.5-Coder-7B 为例,尝试实现冒泡排序算法,结果耗时超过 10 小时,这显然是不可接受的。当然我没有用vllm,而且华为的Ascend目前也不支持vllm。
解决方案:
1. 开发适应NPU的算子,这个华为官方目前也在跟进,大家可以时刻关注动态aten::isin.Tensor_Tensor_out算子不支持 · Issue #I9JGYU · Ascend/pytorch - Gitee.com
2. 自己写一种能替代torch.isin()方法的代码,然后在使用的地方替换掉。首先是要找到在你的大模型里面那里调用了这个代码,一般这个代码是在transformers这个包下面,可以通过
grep -rnw 'your_directory_path' -e 'torch.isin'
这种方式来查询在transformers库文件夹下面(这个文件夹一般在Anaconda3/envs/(你的环境名)/lib/site-packages里面能找到,然后在这里查询到底哪些函数用了 torch.isin这个方法,我查到的结果:
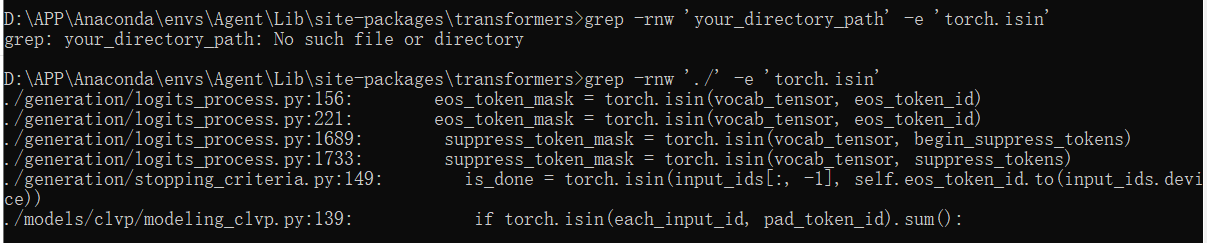
然后我就在这6个包的对应行进行相应的修改,我修改的主要是在低5个代码中间,因为 input_ids[:, -1]和self.eos_token_id的size都是1,因此可以直接用==链接,但是我不太敢轻易就这么弄了,于是我就问chatgpt能否等效替换成另一种代码?答案见下图: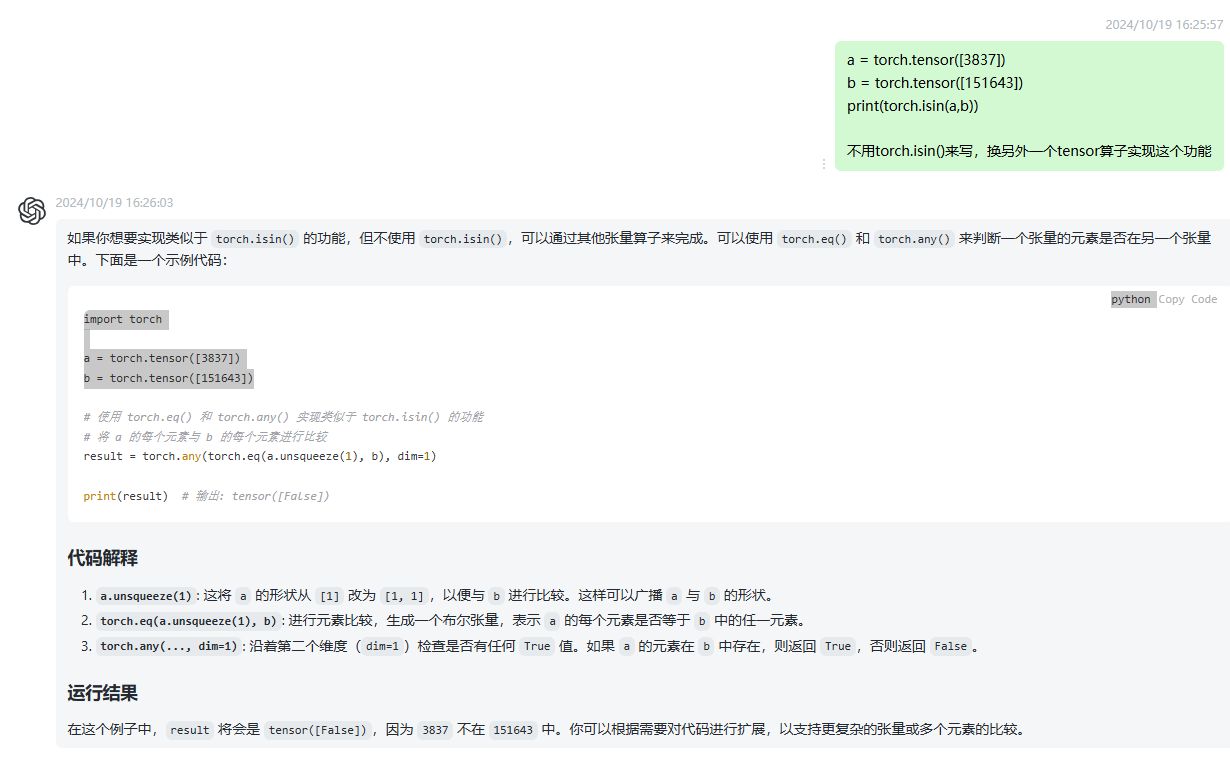
于是我就把对应的代码换成了:
@add_start_docstrings(STOPPING_CRITERIA_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> torch.BoolTensor:
# print('6'*100)
# print(input_ids[:, -1].shape, self.eos_token_id.to(input_ids.device).shape)
# print(input_ids[:, -1],self.eos_token_id.to(input_ids.device))
is_done = torch.any(torch.eq(input_ids[:, -1].view(-1, 1), self.eos_token_id.to(input_ids.device).view(1, -1)), dim=1)
print(is_done.device)
# is_done = torch.isin(input_ids[:, -1], self.eos_token_id.to(input_ids.device))
return is_done结果确实不报这个问题了,而且能够正常运行在NPU上:
3. 利用猴子补丁,利用补丁太覆盖掉原本torch.isin方法。猴子补丁详细解释在这儿:python的猴子补丁(Monkey Patching) - 知乎 (zhihu.com)
我的补丁代码如下:
# new_torch.py
import torch
def isin(elements, test_elements, *, assume_unique=False, invert=False, out=None):
# 检查输入类型
if not isinstance(elements, torch.Tensor) or not isinstance(test_elements, torch.Tensor):
raise TypeError("Both elements and test_elements must be torch tensors.")
# 如果 assume_unique 为 True,确保 test_elements 是唯一的
if assume_unique:
test_elements = test_elements.unique()
# 使用 torch.isin 实现
result = torch.tensor([elem in test_elements.tolist() for elem in elements.flatten()])
# 根据 invert 参数反转结果
if invert:
result = ~result
# 如果指定了 out 参数,赋值给 out
if out is not None:
if out.shape != result.shape:
raise ValueError("Output tensor must have the same shape as the result.")
out.copy_(result)
return out
return result.view_as(elements)应用:
import torch
from torch_npu.contrib import transfer_to_npu
import new_torch
torch.isin = new_torch.isin
# 定义两个张量
a = torch.tensor([1, 2, 3, 4, 5]).cuda()
b = torch.tensor([2, 4, 6]).cuda()
# 使用 isin 操作
result = torch.isin(a, b)
print(result) # 输出: tensor([False, True, False, True, False])结果: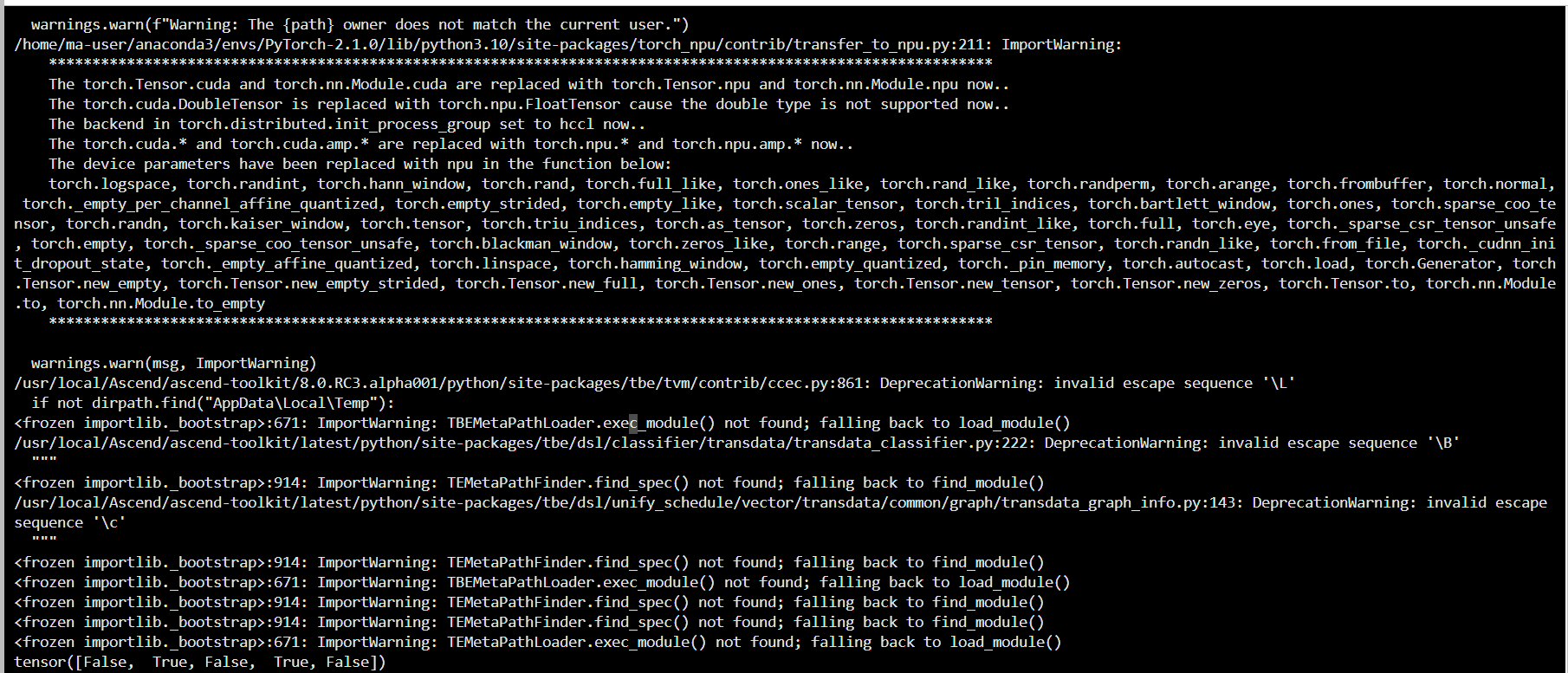
但是,这并没有解决运行慢的问题,盲猜可能是上面这个警告:
[W AddKernelNpu.cpp:82] Warning: The oprator of add is executed, Currently High Accuracy but Low Performance OP with 64-bit has been used, Please Do Some Cast at Python Functions with 32-bit for Better Performance! (function operator())
[W AddKernelNpu.cpp:82] Warning: The oprator of add is executed, Currently High Accuracy but Low Performance OP with 64-bit has been used, Please Do Some Cast at Python Functions with 32-bit for Better Performance! (function operator())
导致的问题, 这个错误表明:程序在使用某个加法操作时,当前使用的算子是一个具有高精度但低性能的 64 位版本。这通常会导致性能问题,尤其是在进行大规模计算时,尤其是涉及深度学习模型的推理或训练。原因是因为华为Ascend只支持32位运算,不支持64位运算。这个感觉需要从加载数据的角度来考虑,这个我下去之后再谈,有发现会持续反馈。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









