







进程地址空间是OS保证进程独立性的重要手段之一,也由此带来了很多好处。在学习操作系统之前,我们可能了解过程序地址空间。本文将解释它们的区别与联系,并阐述引入进程地址空间所带来的好处。
目录
C/C++程序地址空间
在学习C/C++的过程中,我们了解过程序地址空间的概念,它规定了不同的数据在‘内存’中的分布规则。这里的‘内存’加上了双引号,其实它并不是内存,而是本文讲解的进程虚拟地址空间。在正式讲解之前,先来复习一下程序地址空间的概念。
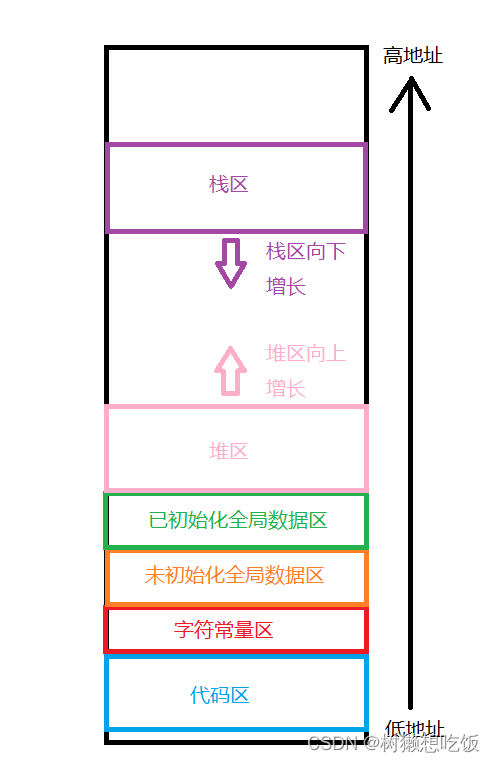
程序地址空间如上图所示,下面编写一段代码来验证程序地址空间的真实性:
#include <iostream>
#include <malloc.h>
int unval;
int val = 0;
int main()
{
const char* str = "Hello Linux";
int* heap = new int(10);
int a = 0;
int b = 0;
std::cout << "code addr:" << (int*)main << std::endl;
std::cout << "string rdonly addr:" << (int*)str << std::endl;
std::cout << "uninit addr:" << &unval << std::endl;
std::cout << "init addr:" << &val << std::endl;
std::cout << "heap addr:" << heap << std::endl;
std::cout << "stack addr1:" << &str << std::endl;
std::cout << "stack addr2:" << &heap << std::endl;
std::cout << "stack addr3:" << &a << std::endl;
std::cout << "stack addr4:" << &b << std::endl;
return 0;
}运行结果:
code addr:0x40086d
string rdonly addr:0x400b10
uninit addr:0x601194
init addr:0x601198
heap addr:0x1e76c20
stack addr1:0x7ffe26d5ab28
stack addr2:0x7ffe26d5ab20
stack addr3:0x7ffe26d5ab1c
stack addr4:0x7ffe26d5ab18
进程地址空间
一、概念
在正式讲解进程地址空间之前,先运行一段小小的测试代码:
#include <iostream>
#include <unistd.h>
int main()
{
int a = 10;
pid_t id = fork();
if(id == 0)
{
a = 20;
std::cout << "a = " << a << ", &a = " << &a << std::endl;
}
else
{
std::cout << "a = " << a << ", &a = " << &a << std::endl;
}
return 0;
}
运行结果:
a = 10, &a = 0x7ffd7a2c0408
a = 20, &a = 0x7ffd7a2c0408
在这段代码中,我们利用子进程写时拷贝,最终使得父子进程打印出了不同的a的值,然而,它们的地址居然是一模一样的!同一地址中的值怎么会不同呢,这显然是不可能的。因此,此时打印出的地址绝非物理地址,而是虚拟地址。
内存中的每个进程,都有一个进程地址空间,操作系统在管理这些进程地址空间时,同样需要采用先描述再组织的策略。而描述进程地址空间,使用的也是结构体,在Linux中被具体为struct mm_struct结构体。
struct mm_struct
{
//进程地址空间
};mm_struct描述进程地址空间,实际上就是对地址空间进行区域划分,对应的线性位置就是虚拟地址。进行区域划分也非常简单,只需要记录每个区域的开始和结束位置即可,如下:
struct mm_struct
{
unsigned int code_start;
unsigned int code_end;
unsigned int init_data_start;
unsigned int init_data_end;
……
};
如此一来,每个进程都认为自己是独占系统内存的,如何理解这句话?就好比进程认为内存都属于自己,当需要内存时只需要向操作系统申请。一般情况下申请的内存相对来说是很少的,操作系统都会把内存分配给这个进程。而如果内存不够了,操作系统会拒绝这个进程的请求。此时这个进程会认为只是操作系统不想给他分配内存,那些内存没被使用。而实际上,可能是由于其它的进程使用了内存,导致内存不足,而每个进程却意识不到。
二、页表映射
我们知道了进程拥有地址空间,在语言层上使用的地址是虚拟地址。那么操作系统是如何根据虚拟地址找到对应的物理地址的呢?这是因为每个进程都拥有一张页表,配合MMU,使得能通过虚拟地址找到物理地址。
首先我们可以将页表想象成下面的形式:
| 虚拟地址 | 物理地址 |
| …… | …… |
| …… | …… |
这样操作系统通过查询页表就可以找到物理地址。同时页表中也存在一些读写信息。如果父子进程对一段数据是只读的,那么它们就共享这段数据的物理地址。如果发现子进程要对标记为读的数据进行写操作,操作系统就能够知道此时应该进行写实拷贝。
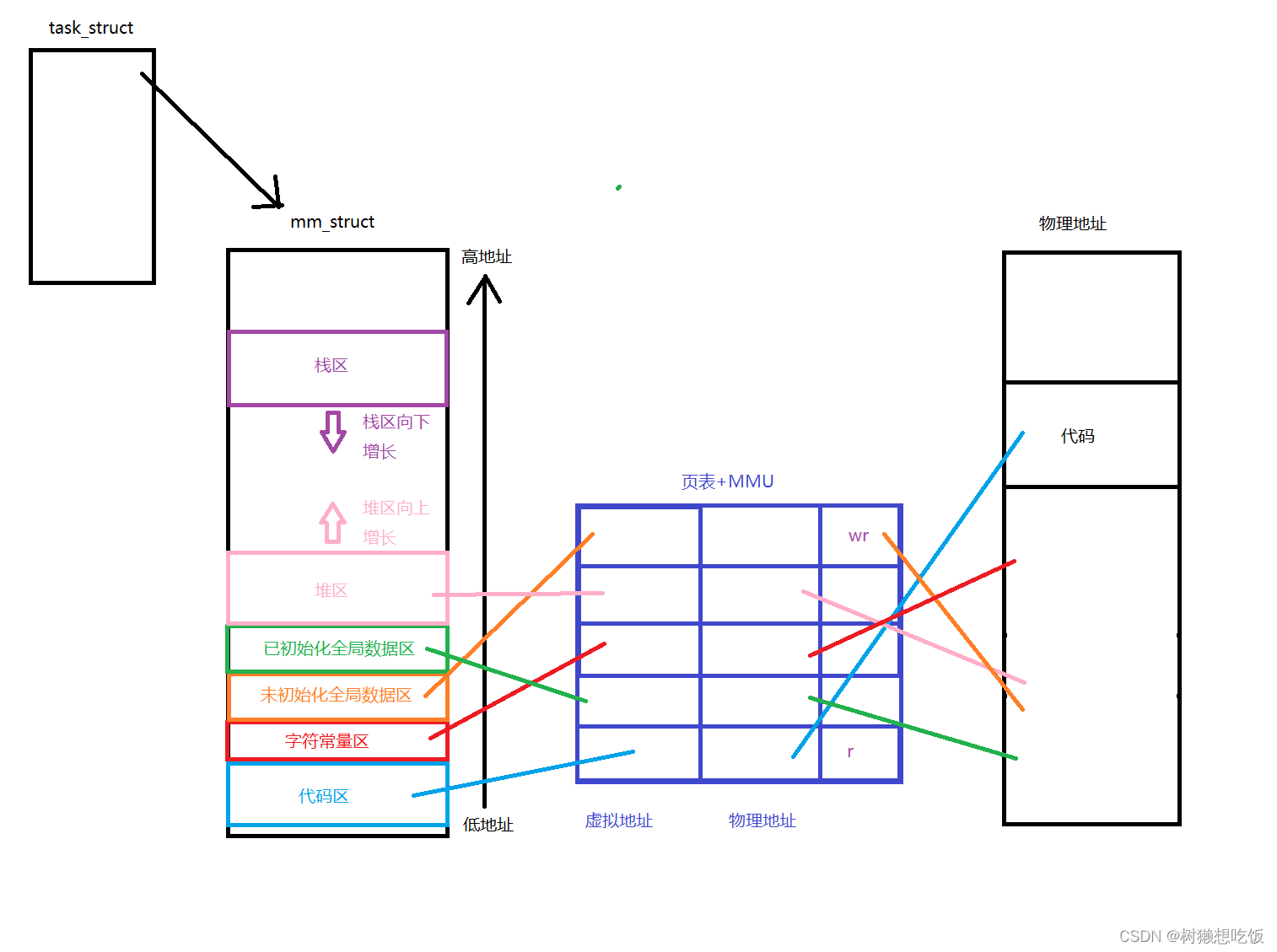
此时我们就可以解释引入代码中,为什么父子进程打印出了不同的a的值,但它们的地址却是一样的:由于子进程的相关内核数据结构是以父进程为模板创建的,因此mm_struct和页表也同样是如此,当子进程对a的值进行修改时,操作系统在物理内存中重新申请了一块空间,并将子进程页表中a映射的物理地址修改成新的地址,更改了映射关系。由于虚拟地址没有变,因此它们打印出的地址是完全一样的。
三、使用地址空间的理由
(1) 通过添加一层软件层,完成有效的对进程操作内存进行风险管理(权限管理),本质目的是为了保护物理内存以及各个进程的数据安全。
如我们不能对字符常量区的内容进行修改,如果强行进行修改,那么在进行物理内存的映射时,OS就会发现对这块空间只有r权限,从而拒绝修改的请求。
(2) 将内存申请和使用的概念在时间上划分清楚,通过虚拟地址空间,来屏蔽底层地址申请内存的过程,达到进程读写内存和OS进行管理操作上的分离。
我们想象一下,如果我们向OS申请10000字节,我们会马上使用吗?实际上我们可能会一点一点地使用甚至不使用。如果OS立刻给了10000字节,就显得有些浪费了,可能导致其它真正需要内存的进程无内存可用。
因此OS中存在一套内存管理算法,语言层上使得你申请空间通过,在地址空间的角度,进程确实认为自己有了那么多的内存。实际上在进程需要使用内存时才真正分配内存。这也依靠于基于缺页中断的物理内存申请。
(3)站在CPU和应用层的角度,进程统一可以看作使用4GB的空间,而且每个空间区域的相对位置是比较确定的。
举个例子,main函数是程序的入口,CPU运行进程时是如何找到main函数的地址的呢?如果每个进程main函数地址各不相同,那么找起来就很费劲。但有了虚拟地址就使得这个问题很好解决了,每个进程的main函数可以拥有相同的虚拟地址。那么CPU每次只要通过这个固定的虚拟地址查找对应的物理地址就可以了。当然具体的实现需要看OS的选择。
总得来说,OS最终这样设计达到一个目标:每个进程都认为自己是独占系统资源的,也保证了进程的独立性。
















 236
236











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











