






时间:2021
期刊:CVPR
论文地址:[2103.02406] Multi-attentional Deepfake Detection
代码: GitHub - yoctta/multiple-attention: The code of multi-attention deepfake detection
摘要
目前常见的深度伪造检测就是用一个模型去提取真图片和假图片的全部特征然后进行二分类,它并不能关注图片细微的变化。
在本文中作者将深度伪造检测当做一个细粒度分类的问题,并且提出了一个新的多注意力深度伪造检测网络。它包含三个部分:
1.多个空间注意头:关注不同的局部区域。
2.纹理特征增强模块,放大浅层特征中的细微伪影。
3.注意力图:聚合低级纹理特征和高级予以特征。
作者还引入了一个新的区域独立损失函数和一种注意力引导的的数据增强策略。
1.引言
目前大多数将深度伪造检测建模为一个简单的二元分类问题(真/假)。基本上,它们通常首先使用一个主干网络提取嫌疑图像的全局特征,然后将这些特征输入到二元分类器中以区分真实和伪造的图像。
随着伪造技术越来越成熟,真图片和假图片之间的差异变得越来越微妙和局部,这让基于全局特征的简单解决方案变得效果不佳。我们必须建立一个微小和局部的差异来解决真伪性检测的细微性差异的问题。
本文提出了一种新的多注意力网络用于深度伪造检测,其核心内容包括:
-
设计多个注意力头:利用深度语义特征预测多个空间注意力图,使网络能够关注图像中不同的潜在伪造区域。
-
增强纹理特征:为了防止细微差异在深层网络中消失,从浅层提取并增强纹理特征,然后将这些低级纹理特征与高级语义特征结合,形成每个局部区域的表示。
-
双线性注意力池化:通过双线性注意力池化层独立池化每个局部区域的特征表示,并将它们融合为整个图像的表示。
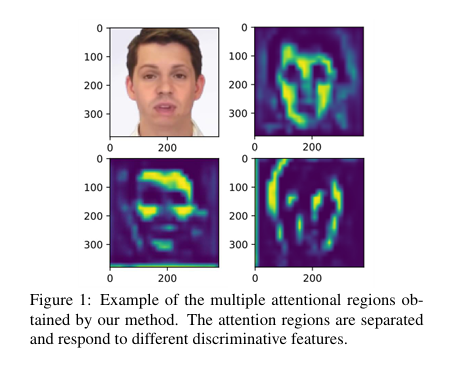
图 1:我们方法获得的多个注意力区域的示例。注意力区域是分开的,并且响应不同的区分特征。
训练一个多注意力网络很难,因为单注意力网络可以使用视频级标签进行明确监督指导,多注意力机制只能用无监督或者弱监督去进行训练,并且经过训练,多注意力头会退化为单注意力头(即只有一个注意力区域产生强烈反应,其他所有的注意力头全部被抑制,无法捕获有效信息),作者使用了一种基于新的注意力引导的数据增强机制,就是在训练期间,故意模糊一些高反应注意力区域(软注意力丢弃),迫使网络从其他注意力区域去进行学习,并且引入一种新的区域独立性损失。
实验证明,作者的思路效果很好。
2.相关工作
大多数深度伪造检测方法将这个问题解决为一个简单的二元分类问题,然而,伪造面部的细微和局部修改使得它更像是一个细粒度的视觉分类问题。
2.1深度伪造检测
早期的深度伪造检测通过视觉生物特征来进行检测,例如不自然的眨眼或者头部姿势。
随着技术的发展,目前很多的方法在深度伪造检测方面实现了很好的效果。
2.2细粒度分类
细粒度分类通过捕捉局部区分特征以区分不同的细粒度类别。
目前已经有一些工作在多注意力框架中被提出,他们的核心思想是同时学习多个尺度或图像部分中的区分区域,并鼓励融合来自不同区域的这些特征。
目前已经有人设计了注意力裁剪和注意力丢弃,以获得更平衡的注意力图
在本文中,搜门首次将深度伪造检测建模为一个特俗的细粒度分类问题。
3.方法
3.1概述
人脸的伪造十分巧妙,并且只发生在局部区域,他并不易被单注意力结构捕获。我们认为将注意力分解为多个区域可以有效收集深度伪造检测任务的局部特征。同时,我们框架中使用局部注意力池化来取代全局平均池化。(原因:不同区域的纹理模式差异很大,不同区域提取的特征肯会被平均池化给平均,会噪声区分度的损失,并且伪造方法引起的细微伪影倾向于在浅层特征中的纹理信息中保留。纹理信息代表了浅层的高频分类,所以我们应该努力去保留浅层纹理信息)
我们提出了一个多注意力框架,它将深度伪造检测当做一个细粒度分类问题。
他主要包含三个组件:
-
我们使用一个注意力模块来生成多个注意力图。
-
我们使用密集连接的卷积层作为纹理增强块,它可以从浅层特征图中提取并增强纹理信息。
-
我们用双线性注意力池化(BAP)替换了全局平均池化。我们使用BAP从浅层收集纹理特征矩阵,并保留深层的语义特征。我们方法的框架如图2所示。
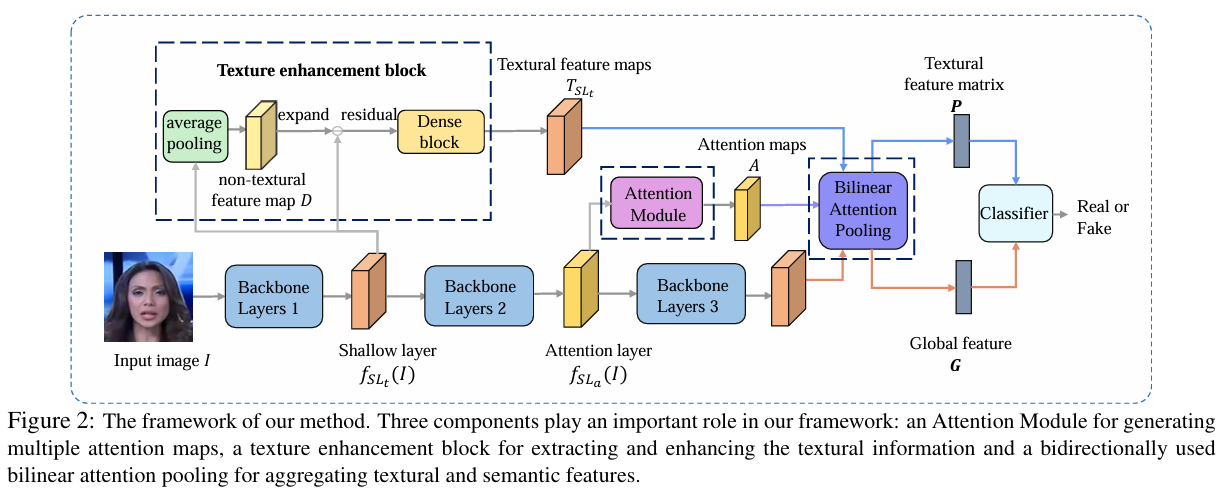
图 2:我们方法的框架。在我们的框架中,有三个组件扮演着重要的角色:一个注意力模块用于生成多个注意力图,一个纹理增强块用于提取和增强纹理信息,以及一个双向使用的双线性注意力池化用于聚合纹理和语义特征。
(





)
与视频超级标签作为明确训练指导的单注意力网络结构不同,多注意力结构只能以无监督或者弱监督进行训练,多个注意力图可能会聚集在同一区域而忽略其他区域,这可能导致网络性能下降。为了解决这个问题,作者提出了区域独立性损失,他合格损失函数可以确保每一个注意力机制区域独立不发生重叠,并且所关注一个特定区域并且不发生重叠,并且作者采用了注意力引导的数据增强机制,它可以降低据分形特征的显著性,并迫使其他注意力图挖掘更多的信息。.
3.2 概述多注意力框架
如上所述,给定一张真实/伪造的人脸图像 I 作为输入,我们的框架首先使用一个注意力块为 I 生成多个注意力图。如图 3 所示,注意力块是一个轻量级模型,由一个 1 x1 的卷积层、一个批量归一化层和非线性激活层组成,
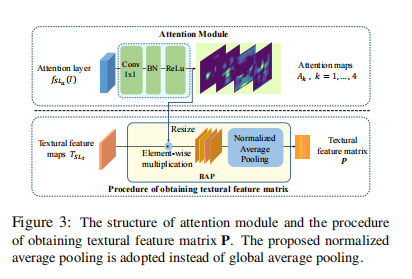
图 3:注意力模块的结构以及获取纹理特征矩阵 P 的过程。这里采用了提出的归一化平均池化,而不是全局平均池化。
(



)
这里3.3主要就是公式的内容了,:
这里的拓展残差其实就是把 通过平均池化后的浅层特征-原浅层特征=我们的重点突出特征。

在双线性注意力池化模块,我们把纹理特征F和每一个注意力图进行元素级乘法,得到部分纹理特征图F,然后再把部分纹理特征图送到分类器。
为了考虑到不同范围的差异,我们不能使用全局平均池化,(全局平均池化会导致池化后的特征受注意力图的影响,他违反了我们关注纹理信息的目的)
在BAP池化层内,注意力和纹理进行融合的公式 ,也是我们的深层特征和注意力图总和Asum融合的计算公式如下:

全局平均特征G怎么来的?

3.3 注意力图正则化区域独立损失
一个多注意力网络可以能很容易缺乏细粒度级别的标签陷入网络退化,
(具体来说:不同的注意力图更倾向于关注相同的区域,这不利于我们的网络模型,我们想让我们的模型关注不同的语义区域,例如A1只关注眼睛,A2只关注嘴巴,A3只关注鼻子)

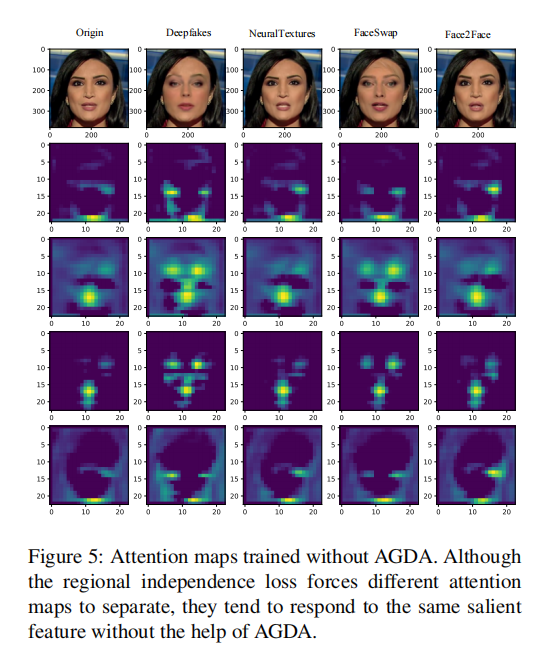
图 4:在没有区域独立性损失(RIL)和注意力引导的数据增强(AGDA)的情况下训练的注意力图。没有RIL和AGDA,网络很容易退化,多个注意力图定位到输入的相同区域。
为了实现目标,我们提出区域独立损失,来减少注意力图之间的重叠,区域独立损失的中心损失如下:
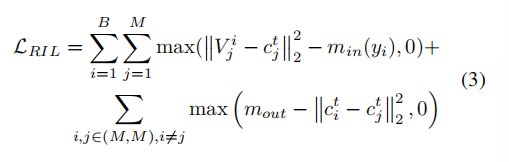
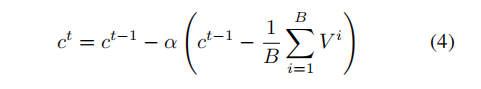

为了实现我们框架的目标函数,我们将区域独立性损失与传统的交叉熵损失结合起来:
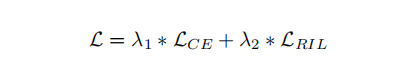

3.4 注意力引导的数据增强

我们虽然以及使用了区域独立性损失,但是多个注意力图仍然可能会对相同的区域进行重叠捕捉。为了更好的解决这个问题,作者提出了注意力引导的数据增强。他的具体工程如下:

对于每个训练样本,随机选择一个注意力图来指导数据增强,生成一个归一化的增强图。然后,使用高斯模糊生成降级图像,并结合原始图像和降级图像,其中增强图作为权重。这样,数据增强有助于模型学习更鲁棒的特征,防止单个注意力区域过度扩展,并鼓励探索不同的注意力区域划分方式。
4.实验
4.1实验细节
实验参数如下:
(对于所有真实和虚假视频帧,我们使用最先进的面部检测器RetinaFace[8]来检测面部,并将对齐后的面部图像保存为380×380大小的输入图像。我们在公式4中设置超参数α=0.05,并在每个训练周期后将其衰减0.9倍。公式3中的类别间间隔mout设置为0.2。真实图像和虚假图像的类别内间隔min分别设置为0.05和0.1。我们通过实验选择了注意力图的数量M、SLa和SLt。在AGDA中,我们将缩放因子设置为0.3,高斯模糊σ设置为7。我们的模型使用Adam优化器[20]进行训练,学习率为0.001,权重衰减为1e-6。我们在4块RTX 2080Ti GPU上以48的批量大小训练我们的模型。)
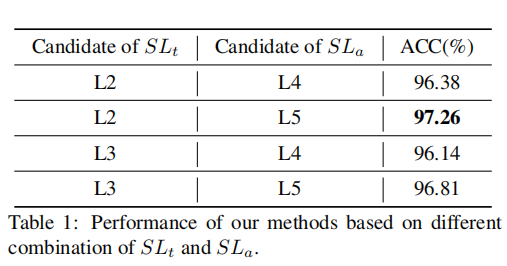
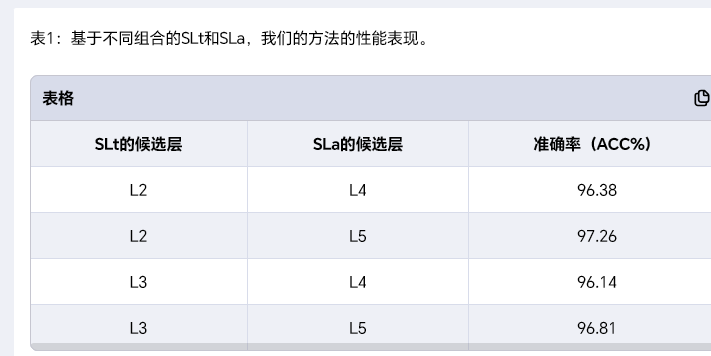
4.2确定SLa层和SLt层
EfficientNet-b4为骨干网络。
默认注意力图数量为1
FF++(HQ)数据集上训练了四种组合的模型。
4.3与先前方法的比较
数据集是FF++和DFDC,并且对Celeb-DF也进行了评估,准确率(ACC)和接收者操作特征曲线下面积(AUC)作为评估指标.
4.3.1FaceForensics++上的评估
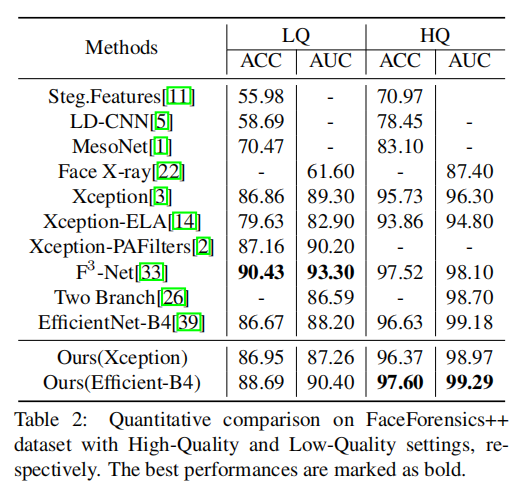
表2:分别在高质量和低质量设置下,对FaceForensics++数据集进行的定量比较。最佳性能以粗体显示。
4.3.2 DFDC数据集上进行评估
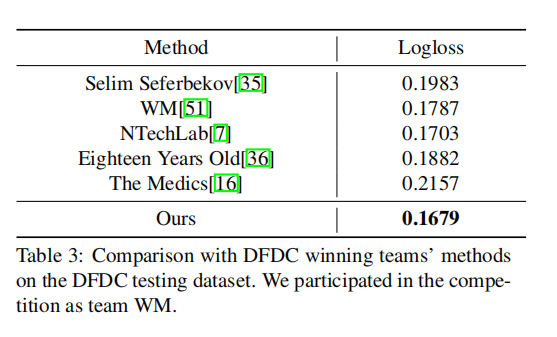
表3:在DFDC测试数据集上与DFDC获胜团队的方法进行比较。我们作为WM团队参加了比赛。(这些方法是团队的名字,他们队伍提交的logloss比我们高)
4.3.3Celeb-DF上的跨数据集评估
在FF++上训练对Celeb-DF进行的跨数据集评估。接收者操作特征曲线下面积(AUC)
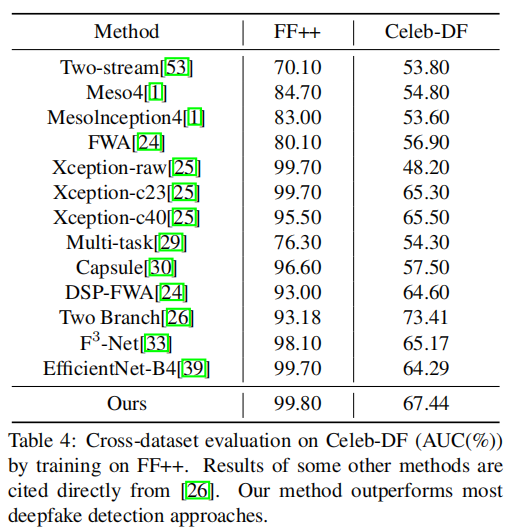
(这些AUC准确率是通过在FF++数据集上训练模型,并在Celeb-DF数据集上测试模型得到的,以评估模型的跨数据集泛化能力。)
4.4消融实验
4.4.1多重注意力的有效性
在FF++(HQ)上的准确率结果和在Celeb-DF上的AUC结果报告在表5中。在某些情况下,基于多重注意力的模型比单一注意力模型表现更好,我们发现M=4提供了最佳性能。
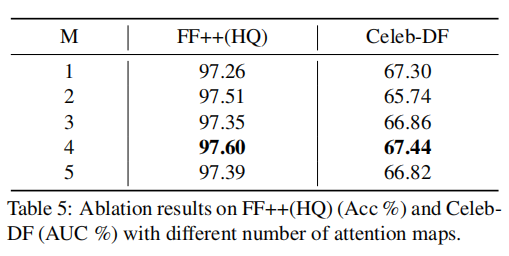
表格5:使用不同数量的注意力图在FF++(HQ)(准确率 %)和Celeb-DF(AUC %)上的消融结果。
4.4.2 区域独立损失和AGDA的消融研究
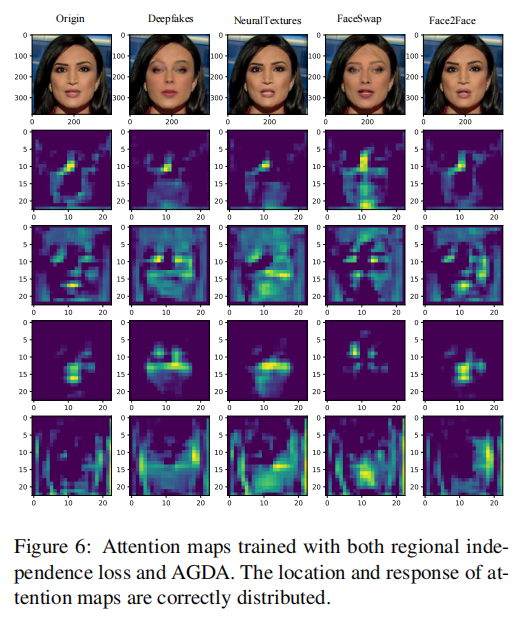
区域独立损失和AGDA在多注意力图训练的正则化过程中起着重要作用。我们进行了定量实验并提供了一些可视化结果来证明这两个组件是必要的.
这里就是显示了,使用区域独立性损失以及注意力引导数据增强对结果的影响。(和图4 5对比)
5.结论
作者从一个新的角度研究深度伪造检测,即将深度伪造检测任务制定为一个细粒度分类问题。我们提出了一个多重注意力深度伪造检测框架。该框架通过多个注意力图探索辨识性的局部区域,并从浅层增强纹理特征以捕获更细微的伪造痕迹。。然后,低级纹理特征和高级语义特征在注意力图的指导下进行聚合。引入了区域独立损失函数和注意力引导的数据增强机制,以帮助训练解耦的多重注意力。我们的方法在广泛的指标上取得了良好的改进。
总结
就是在真伪性鉴定时,很多模型都是提取全局特征,而忽略细粒度的差异,这对真伪性鉴定的任务非常不利,
(全局特征会把那些篡改部分区域的信息给平均掉,这非常不利于真伪性鉴定)
作者为了解决这个问题,就想把真伪性鉴定当作一个细粒度的任务去处理。
为了不去做全局平均池化,作者想用多注意力机制去解决问题,为了让多注意力关注的区域不怎么集中,作者设计了区域独立正则化损失函数。
然后为了更加强化数据,作者又创建了基于注意力的数据增强。
作者提出了多注意力深度伪造检测,并且做了一个模型。
最后取得不错的效果。


















 2358
2358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









