






《Attention Is All You Need》论文精读
(本文是方便自己学习做的笔记,原文来自:【Transformer系列(1)】encoder(编码器)和decoder(解码器)_encoder和decoder的区别-CSDN博客)
【Transformer系列(2)】注意力机制、自注意力机制、多头注意力机制、通道注意力机制、空间注意力机制超详细讲解-CSDN博客
感谢大佬做的笔记
Transformer是一种基于注意力机制的序列转换模型,完全摒弃了循环和卷积操作。模型由编码器和解码器组成,使用多头自注意力机制,提高了并行计算能力和训练效率。在机器翻译任务和其他序列任务中表现出色。 (总结 就是放弃了循环和卷积操作,使用编码器和解码器以及注意力机制作为模型)
1.编码器
1.1编码器基本概念
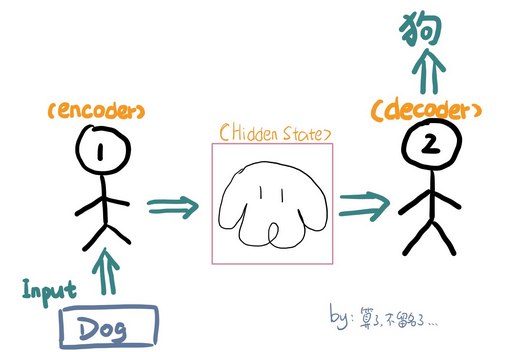
encoder,就是编码器,负责将输入序列压缩成指定长度的向量,这个向量就可以看成是这个序列的语义,然后进行编码,或进行特征提取。 (图片翻译成向量)
简单来说就是机器读取数据的过程,将现实问题转化成数学问题。如下图所示:
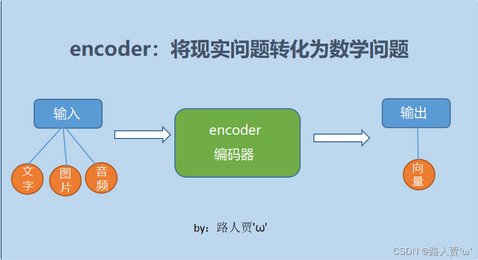
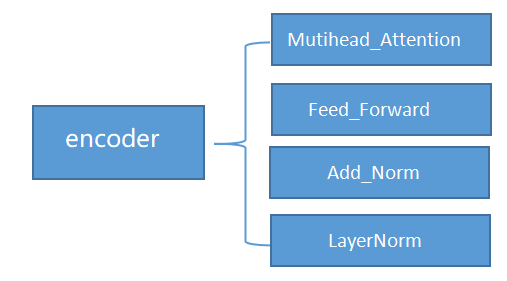
编码器常常由四个部分组成:多头注意力模块,前馈神经网络模块(两个linear中链接Relu 目的是增加非线性信息,提高模型拟合能力),加法归一化以及层归一化。
1.2 编码器的结构
transformer 中 encoder 由 6 个相同的层组成,每个层包含 2 个部分:Multi-Head Self-Attention(多头自注意力),Position-Wise Feed-Forward Network(位置感知前馈网络) 。
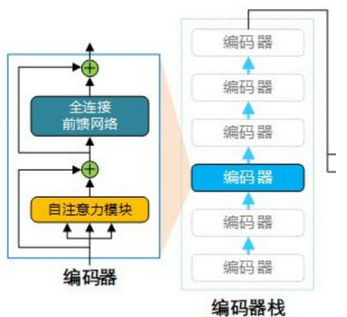
1.3 BLOCK结构
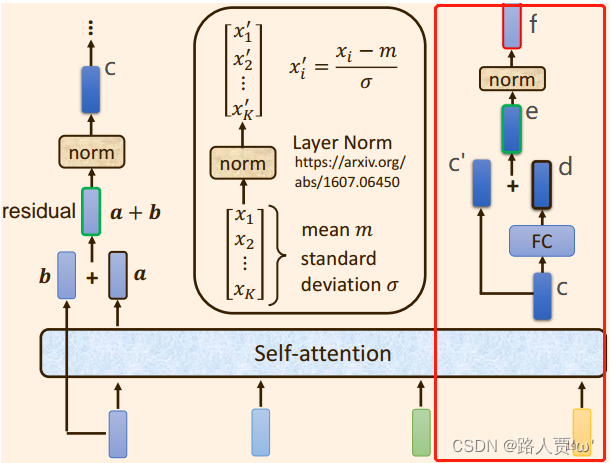
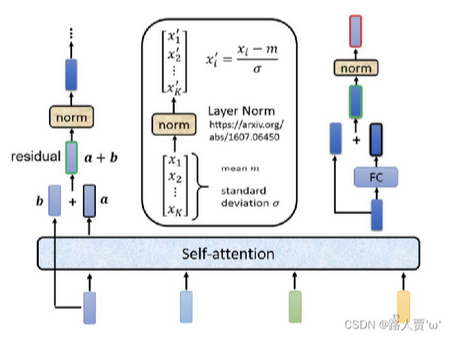
每个block由自注意力机制,残差链接,LayerNorm,FC,残差链接 ,layer Norm组成,此时BLOCK的输出也就是一个Block 的输出。
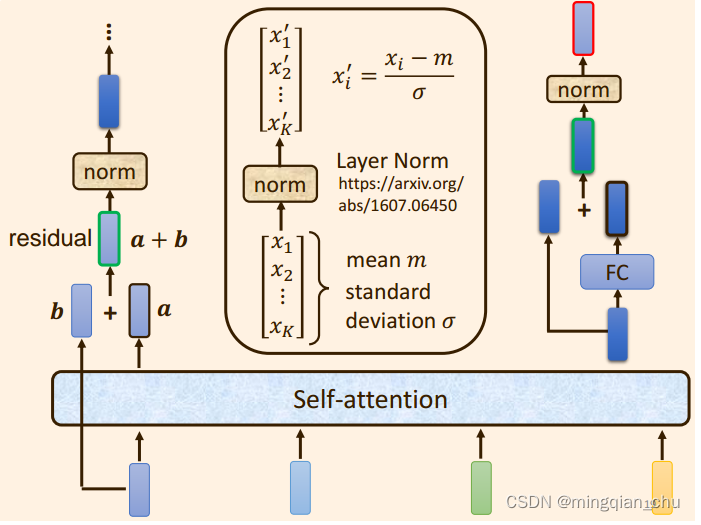
计算方式:
1.原始的输入向量b 与输出向量a残差相加,得到向量a+b;
(b是原始的输入向量,下图中输出向量a是考虑整个序列的输入向量得到的结果)
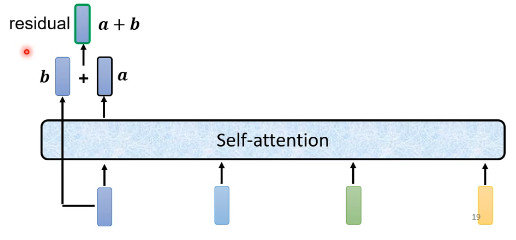
2.将向量 a+b 通过 Layer Normation 得到向量c ;
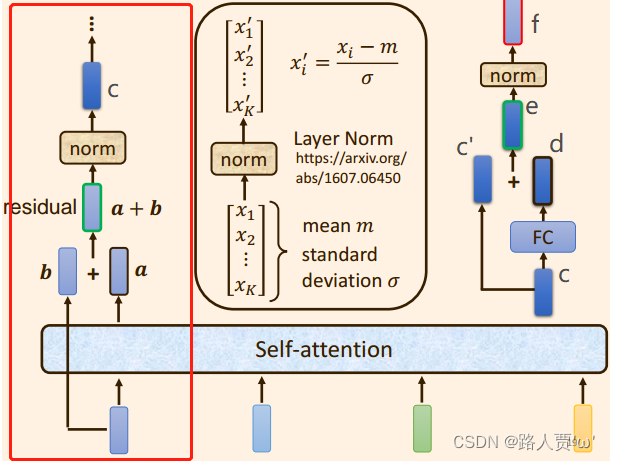
(3)将向量c 通过 FC layer 得到向量d ;
(4)向量c 与向量d 残差相加 ,得到向量e ;
(5)向量e 通过 Layer Norm 输出 向量f;
(6)此时得到的输出向量f 才是 encoder中每个Block中的一个输出向量;
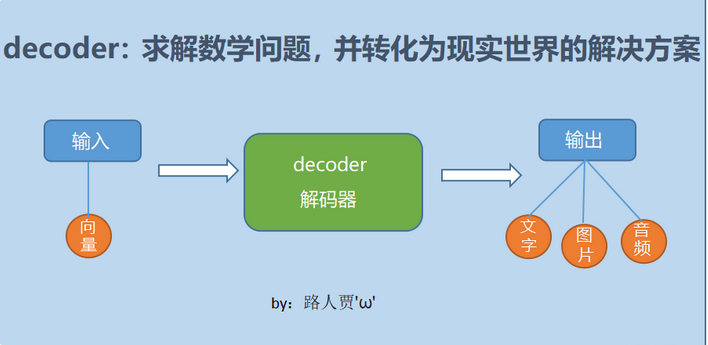
2.解码器
2.1解码器的基本概念
decoder,也是解码器,负责根据encoder部分输出的语义向量c来做解码工作。以翻译为例,就是生成相应的译文。(向量翻译成图片)
decoder的Muti_head_Attention引入了Mask机制
decoder与encoder中模块的拼接方式不同
2.2解码器的结构
在transformer中decoder 也是由 6 个相同的层组成,每个层包含 3 个部分:
分别为Multi-Head Self-Attention(多头自注意力),Multi-Head Context-Attention(多头上下文注意力),Position-Wise Feed-Forward Network(位置感知前馈网络)
加入Multi-Head Context-Attention的作用是防止在当前位置放入后续位置的单词。 我是薛 :i am xue 他不会把i的位置放xue
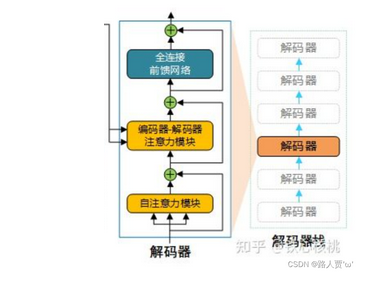
2.3编码器解码器的区别
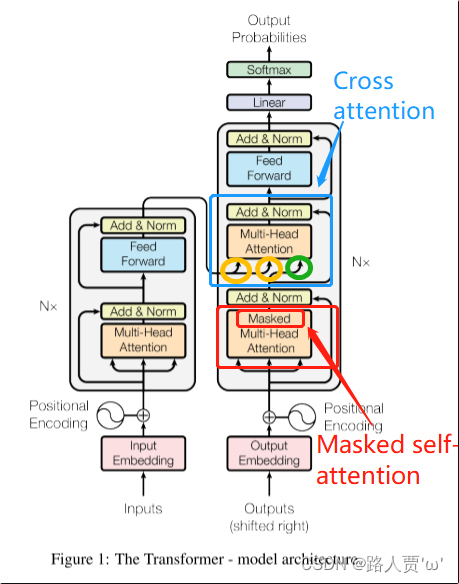
(1)第一级中:解码器比编码器在自注意力模块多加入了一个Masked self-attention,加入这个模块之后,我们就只需要考虑解码器当前的输入和当前输入的左侧部分,不需要考虑右侧部分。(就是我们只注意已经完成翻译的部分即可) (2)第二级中:引入了 Cross attention 交叉注意力模块, 在 masked self-attention 和全连接层 之间加入;
(3)Cross attention 交叉注意力模块的输入 Q,K,V 不是来自同一个模块,K,V 来自编码器的输出, Q来自解码器的输出;
(说简单点:和编码器相比,解码器在第一级引入了Mask操作。这个操作就是帮助我们在翻译过程中,我们在使用当前词之前,不能使用未来还没生成的词语进行提示
第二层加入了交叉注意力模块,他可以把解码器中的信息与编码器中的信息进行交互,在解码器输出时,它能够结合编码器对输入序列的编码信息。)
2.3.1 Masked self attention模块
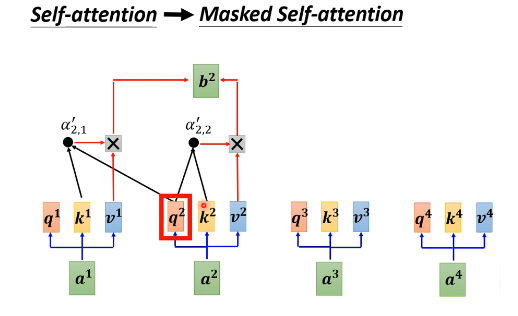
举例:翻译:


就是在加入marked self attention后,模型只考虑输入向量本身和输入向量的之前向量,而不考虑后面的向量。(也就是他只会考虑先生成i 再生成am 再生成jia 而不会先生成jia)
2.3.2 Cross attention模块
Cross attetion模块称为交叉注意力模块,是因为向量 q , k , v 不是来自同一个模块。(Q:查询,K:键,V:value值)
而是将来自解码器的输出向量q 与来自编码器的输出向量 k , v运算。
具体讲来: 向量 q 与向量 k之间相乘求出注意力分数α1 ' 注意力分数α1 '再与向量 v 相乘求和,得出向量 b (图中表示为向量 v ) ;

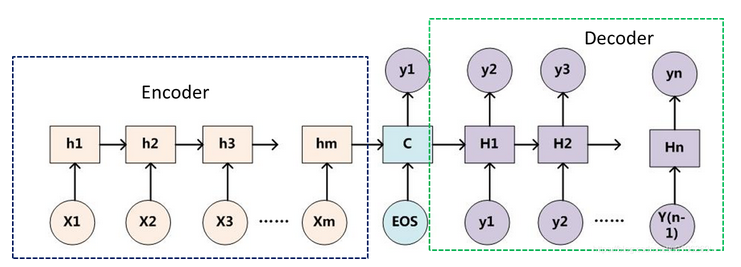
3. encoder-decoder模型
在NLP 领域里的概念里,encoder-decoder并不特值某种具体的算法,而是一类算法的统称。encoder-decoder 算是一个通用的框架,在这个框架下可以使用不同的算法来解决不同的任务。
4.注意力机制
4.1 什么是注意力机制?
注意力机制其实是源自于人对于外部信息的处理能力。人在处理信息的时候,会将注意力放在需要关注的信息上,对于其他无关的外部信息不在乎,这种处理方式被称为注意力机制。(就是只关注重点信息,不在乎细节信息)
4.2什么是注意力机制?
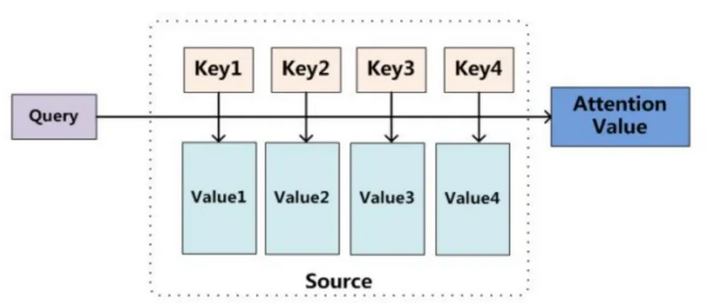
首先我们要认识 Query&Key&Value
-
查询(Query): 指的是查询的范围,自主提示,即主观意识的特征向量
-
键(Key): 指的是被比对的项,非自主提示,即物体的突出特征信息向量
-
值(Value) : 则是代表物体本身的特征向量,通常和Key成对出现
(注意力机制是通过Query与Key的注意力汇聚(给定一个 Q,计算Q与 K的相关性,然后根据Q与K的相关性去找到最合适的 V实现对V的注意力权重分配,生成最终的输出结果。)
我们找一件衣服 我们输入(显瘦)即为需求(查询)q
淘宝根据我们的q 生成一系列的k (例如 商品名称,图片等)
最后系统会把相应的v推送给我们 (具体的衣服)
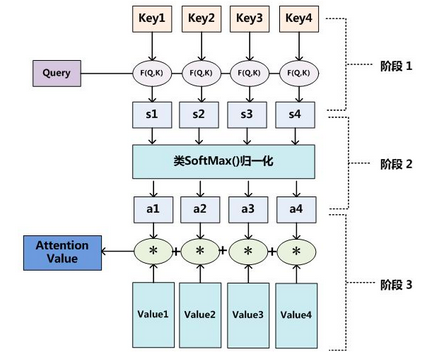
4.3 注意力机制计算过程
输入Query、Key、Value:
阶段一:根据Query和Key计算两者之间的相关性或相似性(常见方法点积、余弦相似度,MLP网络),得到注意力得分;(和孪生网络类似 算出K与Q的距离,获得注意力得分)

阶段二:对注意力得分进行缩放scale(除以维度的根号),再softmax函数,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过softmax的内在机制更加突出重要元素的权重。一般采用如下公式计算:(将注意力得分进行缩放,使用softmax寒素技术暗处权重和为1的概率分布)
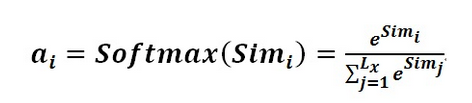
阶段三:根据权重系数对Value值进行加权求和,得到Attention Value(此时的V是具有一些注意力信息的,更重要的信息更关注,不重要的信息被忽视了); (根据概率分布算出权重系数对Value的加权求和,把关键信息重点关注,对于不重要信息选择忽略不计)
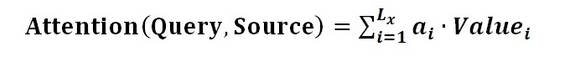
这三个阶段可以用下图表示
5.自注意力机制
5.1 什么是自注意力机制?
自注意力机制实际上是注意力机制中的一种,也是一种网络的构型。
它想要解决的问题:神经网络接收的输入是很多大小不一的向量,并且不同向量向量之间有一定的关系,但是实际训练的时候无法充分发挥这些输入之间的关系而导致模型训练结果效果极差。(比如在机械翻译中 的语言顺序问题,无法分辨每个单词之间的联系)
自注意力机制实际上是想让机器注意到整个输入中不同部分之间的相关性。
自注意力机制是注意力机制的变体,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。自注意力机制的关键点在于,Q、K、V是同一个东西,或者三者来源于同一个X,三者同源。通过X找到X里面的关键点,从而更关注X的关键信息,忽略X的不重要信息。不是输入语句和输出语句之间的注意力机制,而是输入语句内部元素之间或者输出语句内部元素之间发生的注意力机制。
5.2 自注意力机制与注意力机制的区别?
(1)注意力机制的Q和K是不同来源的。在中译英模型中,中文句子通过编码器被转化为一组特征表示K,这些特征表示包含了输入中文句子的语义信息。解码器在生成英文句子时,会使用这些特征表示K以及当前生成的英文单词特征Q来决定下一个英文单词是什么。 (2)自注意力机制的Q和K则都是来自于同一组的元素。也可以理解为同一句话中的词元或者同一张图像中不同的patch,这都是一组元素内部相互做注意力机制,因此,自注意力机制(self-attention)也被称为内部注意力机制(intra-attention)。
5.3注意力机制使用方式

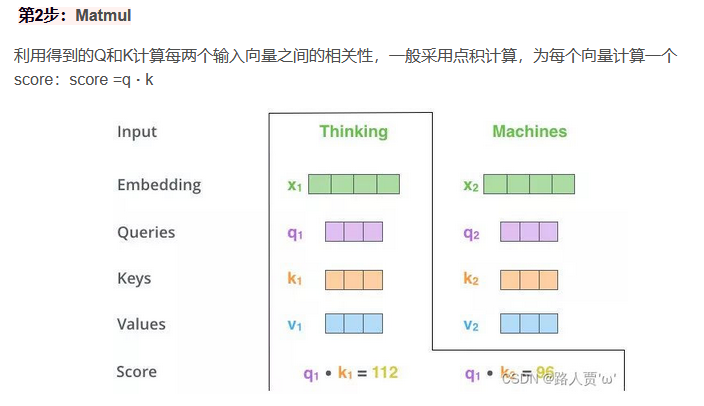

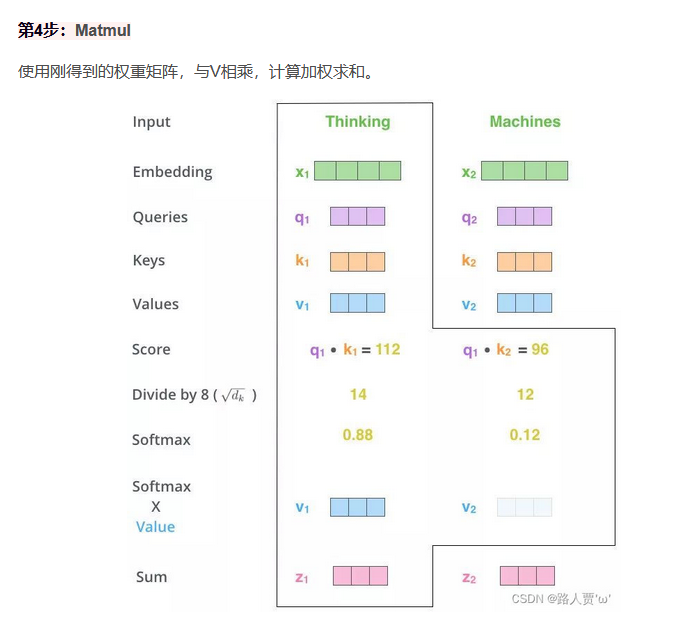
5.4多头注意力机制
自注意力机制存在一定的缺陷即:在对当前位置的信息进行编码时,会过度的将注意力集中于自身的位置,有效信息抓取能力就差一些。为了改进这一缺陷,大佬们设计出了多头注意力机制。
在实践中,当给定相同的查询、键和值的集合时, 我们希望模型可以基于相同的注意力机制学习到不同的行为, 然后将不同的行为作为知识组合起来, 捕获序列内各种范围的依赖关系 (例如,短距离依赖和长距离依赖关系)。 因此,允许注意力机制组合使用查询、键和值的不同 子空间表示可能是有益的。 多头注意力: 我们可以用独立学习得到的h组(一般h=8)不同的线性投影来变换查询、键和值。 然后,这h组变换后的查询、键和值将并行地送到注意力汇聚中。 最后,将这h个注意力汇聚的输出拼接在一起, 并且通过另一个可以学习的线性投影进行变换, 以产生最终输出。 这种设计被称为多头注意力。
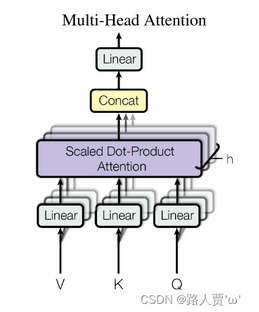
多头注意力运行方式:
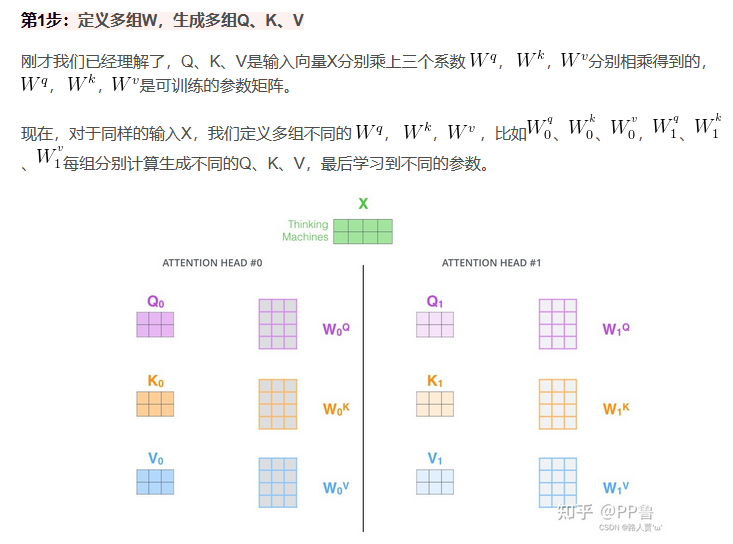
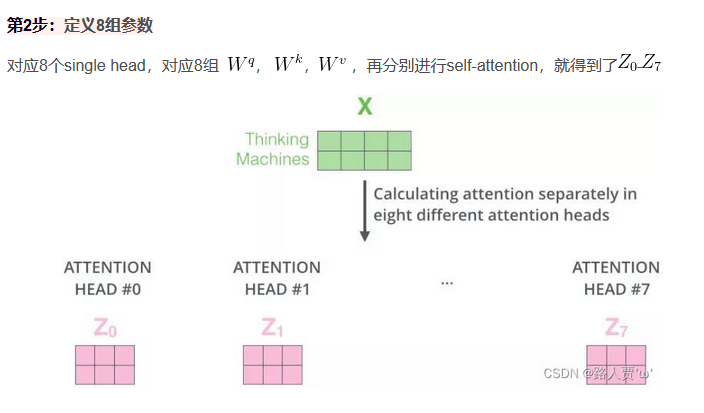
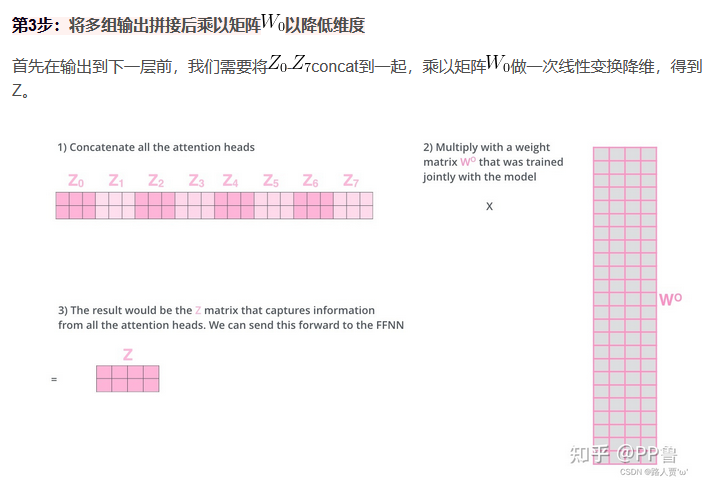
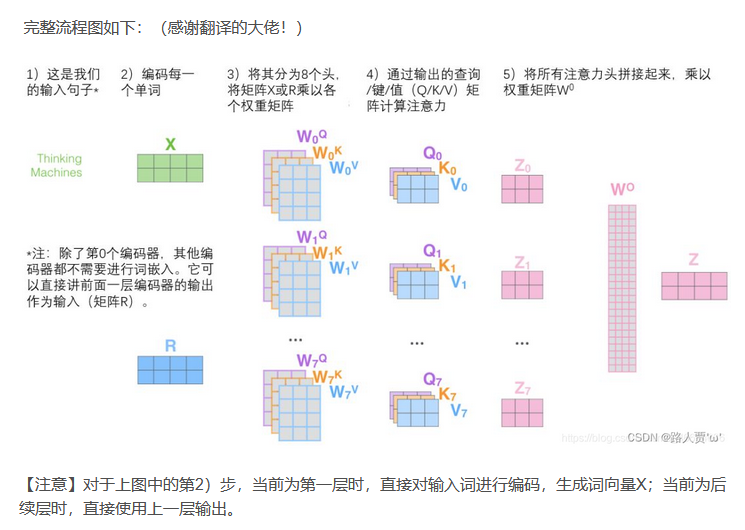
5.5通道注意力机制
对于输入2维图像的CNN来说,一个维度是图像的尺度空间,即长宽,另一个维度就是通道,因此通道注意力机制也是很常用的机制。
通道注意力旨在显示的建模出不同通道之间的相关性,通过网络学习的方式来自动获取到每个特征通道的重要程度,最后再为每个通道赋予不同的权重系数,从而来强化重要的特征抑制非重要的特征。
使用通道注意力机制的目的:为了让输入的图像更有意义,大概理解就是,通过网络计算出输入图像各个通道的重要性(权重),也就是哪些通道包含关键信息就多加关注,少关注没什么重要信息的通道,从而达到提高特征表示能力的目的。
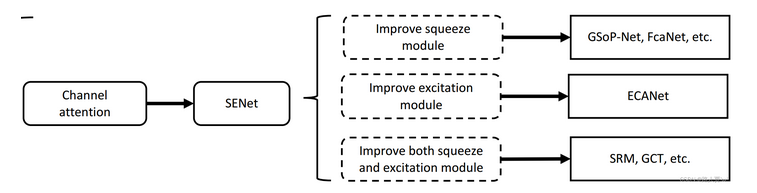
5.6 SENet注意力机制
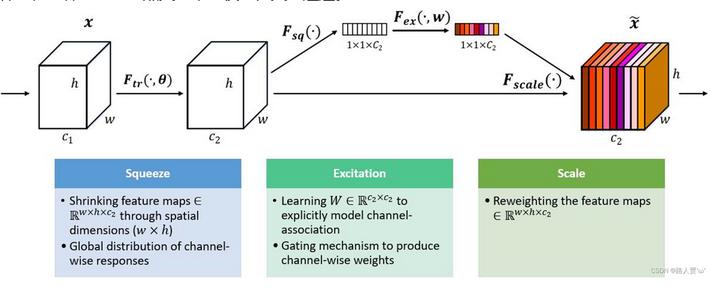
SE注意力机制在通道维度增加注意力机制,关键操作是squeeze(压缩)和excitation(激发)。
通过自动学习的方式,即使用另外一个新的神经网络,获取到特征图的每个通道的重要程度,然后用这个重要程度去给每个特征赋予一个权重值,从而让神经网络重点关注某些特征通道。提升对当前任务有用的特征图的通道,并抑制对当前任务用处不大的特征通道。
如下图所示,在输入SE注意力机制之前(左侧白图C2),特征图的每个通道的重要程度都是一样的,通过SENet之后(右侧彩图C2),不同颜色代表不同的权重,使每个特征通道的重要性变得不一样了,使神经网络重点关注某些权重值大的通道。
6.论文 《Attention Is All You Need》
6.1摘要
目前的主流序列转换模型为循环卷积神经网络和卷积神经网络,他们很牛逼,他们都用了编码器 解码器,还把注意力机制结合了进去。作者设计了一个Transformer,它基于单独的注意力机制,避免使用卷积和循环。他很牛逼。
以前的方法:主流序列转导模型 基于CNN/RNN,包括编码器,解码器。
有的模型使用注意力机制连接编码器和解码器,达到了最优性能。
缺点:
①难以并行
②时序中过早的信息容易被丢弃
③内存开销大
本文方法:提出了Transformer完全摒弃了之前的循环和卷积操作,完全基于注意力机制,拥有更强的并行能力,训练效率也得到较高提升。在翻译效果上表现牛逼。
6.1引言
目前RNN,LSTM,等等序列建模和转换任务已经到达了极限,很难进步。
这些模型在面对一些长句子时,很难进行并行化处理,计算资源消耗严重。
注意力机制允许关系建模。作者提出了transformer,可以避免使用循环的模型结构。完全依赖注意力机制来描绘输入与输出之间的关系。并且效果牛逼。
目前存在的问题:
方法: RNN、LSTM、GRU、Encoder-Decoder
不足:
①从左到右一步步计算,因此难以并行计算(不能并行)
②过早的历史信息可能被丢弃,时序信息一步一步向后传递
③内存开销大,训练时间慢
本文改进
(1)引入注意力机制: 注意力机制可以在RNN上使用,通过注意力机制把encoder的信息传给decoder,可以允许不考虑输入输出序列的距离建模。
(2)提出Transformer : 本文的 Transformer 完全不用RNN,这是一种避免使用循环的模型架构,完全依赖于注意机制来绘制输入和输出之间的全局依赖关系,并行度高,计算时间短。
目前存在的 Extended Neural GPU [16],ByteNet[18],和ConvS2S,他们都使用了卷积神经网络作为基础模块,任意两个输入或输出位置的信号关联起来需要操作数随着时间的距离而增长,折让学习远距离位置之间的依赖性变得困难。作者设计Transformer把一个序列中不同位置联系起来。并用计算序列表示。
6.3CNN代替RNN
为啥要CNN代替RNN呢
优点:
①减小时序计算
②可以输出多通道
问题:
卷积的感受野是一定的,距离间隔较远的话就需要多次卷积才能将两个远距离的像素结合起来,所以对长时序来讲比较难。
自注意力
有时也称为内部注意力,是一种将单个序列的不同位置关联起来以计算序列表示的注意机制。
端到端记忆网络
基于循环注意机制而不是序列对齐循环。
循环注意机制:是在每个时间步上应用注意力机制,计算当前时间步与序列中其他时间步之间的相关性,计算加权,最后告诉我们哪些部分需要重点注意。
序列对齐机制:有一个循环结构来逐步处理序列中的元素,并在每个时间步上计算和更新对齐分数。
Transformer优点
用注意力机制可以直接看一层的数据,就规避了CNN的那个缺点。
6.4 Model Architecture—模型结构
Transformer遵循编码器解码器的总体架构。类似下图。编码器去处理图像,并把图像转化为向量,然后解码器再去吧向量翻译成另一个图片输出结果。
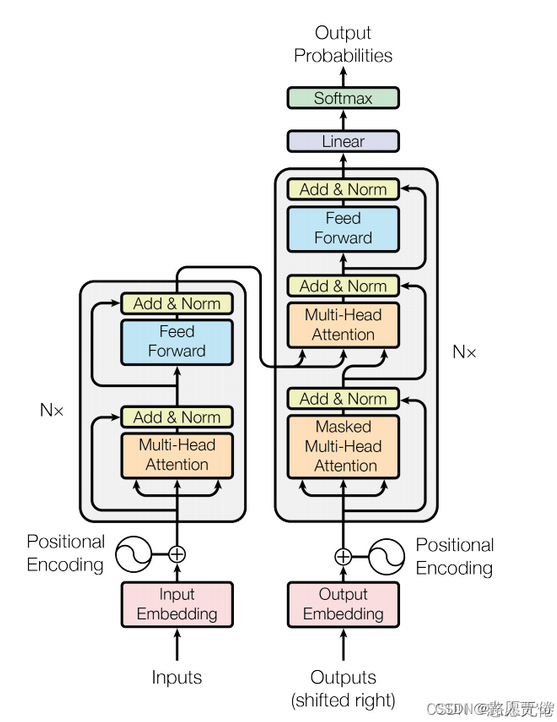
6.4.1 编码器
将一个长为n的输入(如句子),序列(x1, x2, … xn)映射为(z1, z2, …, zn)(机器学习可以理解的向量)
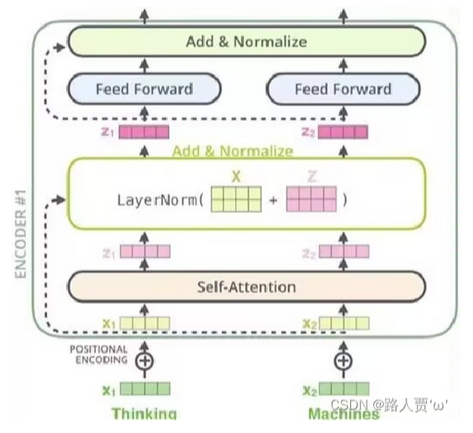
encoder由n个相同层组成,重复6个layers,每个layers会有两个sub-layers,每个sub-layers里第一个layer是多头注意力机制,第二个layer是全连接前馈网络,简称 MLP。如下图
每个sub-layer的输出都做一个残差连接和layerNorm。计算公式:LayerNorm( x + Sublayer(x) ),Sublayer(x) 指 self-attention 或者 MLP。
与CNN不一样的是,MLP的空间维度是逐层下降,CNN是空间维度下降,channel维度上升。
6.4.2 解码器
ecoder 拿到 encoder 的输出,会生成一个长为 m 的序列(y1, y2, … , ym)。编码时可以一次性生成,解码时只能一个个生成
decoder同样由n个相同层组成。
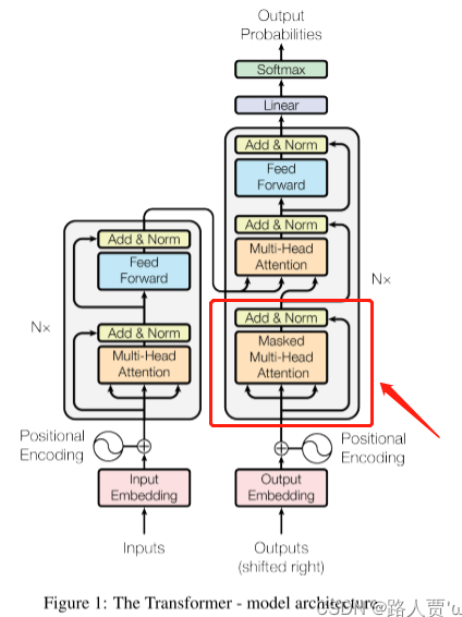
除了encoder中的两个子层外,decoder还增加了一个子层:对encoder层的输出执行多头注意力。
另外对自注意力子层进行修改(Mask),防止某个position受后续的position的影响。确保位置i的预测只依赖于小于i的位置的已知输出。
输出就是标准的 Linear+softmax。
6.4.3 注意力机制
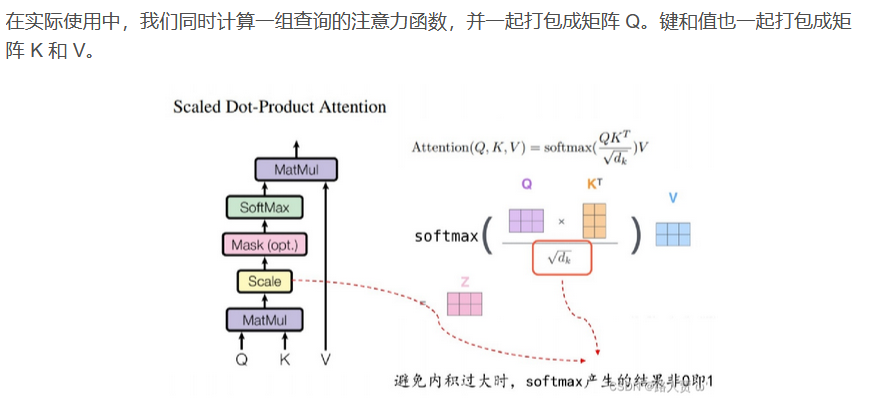
Attention机制可以描述为将一个query和一组key-value对映射到一个输出,其中query,keys,values和输出均是向量。输出是values的加权求和,其中每个value的权重 通过query与相应key的兼容函数来计算。
概念
注意力机制是对每个 Q 和 K做内积,将它作为相似度。
当两个向量做内积时,如果他俩的 d 相同,向量内积越大,余弦值越大,相似度越高。
如果内积值为0,他们是正交的,相似度也为0。
相关参数
Q: query(查询) K: key(键) V: value(值)
Q就在目标 target区域,就是decoder那块,K和V都在源头 ,就是encoder区域。 我是张 i am zhang Q在我是张这里,而K和V在i am zhang这里。
自注意力则是QKV都在一个区域,要么都在decoder要么都在encoder。 目的就是为了能够发现一句话内部或者一个时序内部的关联信息。
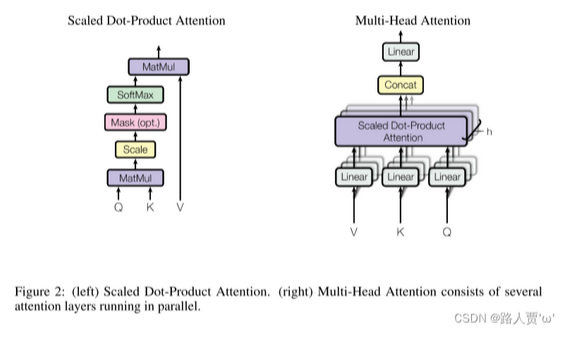
6.4.4 Scaled DotProduct Attention—缩放的点积注意力机制
翻译
我们设计了Scaled Dot-Product Attention(缩放点积注意力机制)。输入由query、
![]()
的key和
![]()
的value组成。我们计算query和所有key的点积,再除以
![]()
然后再通过softmax函数来获取values的权重。
加性attention和点积(乘性)attention区别
①点积attention与我们的算法一致,除了缩放因子
![]()
②加性attention使用带一个单隐层的前馈网络计算兼容函数
点积attention在实践中更快、空间效率更高,因为它可以使用高度优化的矩阵乘法代码。
为什么用softmax?
对于一个Q会给 n 个 K-V 对,Q会和每个K-V对做内积,产生 n 个相似度。传入softmax后会得到 n 个非负并且和为 1 的权重值,把权重值与 V 矩阵相乘后得到注意力的输出。
为什么除以
![]()
?
虽然对于较小的 dk 两者的表现相似,但在较大的 dk 时,加法注意力要优于没有缩放机制的点乘注意力。我们认为在较大的 dk 时,点乘以数量级增长,将 softmax 函数推入梯度极小的区域,值就会更加向两端靠拢,算梯度的时候,梯度比较小。为了抵抗这种影响,我们使用 \frac{1}{\sqrt{d_{k}}}缩放点乘结果。
6.4.5 MultiHead Attention—多头注意力机制
方法
不再使用一个attention函数,而是使用不同的学习到的线性映射将queries,keys和values分别线性投影到 dq、dk 和 dv 维度 h 次。
然后在queries,keys和values的这些投影版本中的每一个上并行执行注意力功能,产生h个注意力函数。
最后将这些注意力函数拼接并再次投影,产生最终输出值。
目的
一个 dot product 的注意力里面,没有什么可以学的参数。具体函数就是内积,为了识别不一样的模式,希望有不一样的计算相似度的办法。
本文的点积注意力先进行了投影,而投影的权重w是可学习的。多头注意力给h次机会学习不一样的投影方法,使得在投影进去的度量空间里面能够去匹配不同模式需要的一些相似函数,然后把 h 个头拼接起来,最后再做一次投影。这种做法有一些像卷积网络 CNN的多输出通道。
Transformer用了三种不同的注意力头:
(1)Encoder 的注意力层: 输入数据在经过 Embedding+位置encoding 后,复制成了三份一样的东西,分别表示 K Q V。同时这个数据既做 key 也做 query 也做value,其实就是一个东西,所以叫自注意力机制。输入了n个 Q,每个Q会有一个输出,那么总共也有n个输出,输出是 V 加权和(权重是 Q 与 K 的相似度)
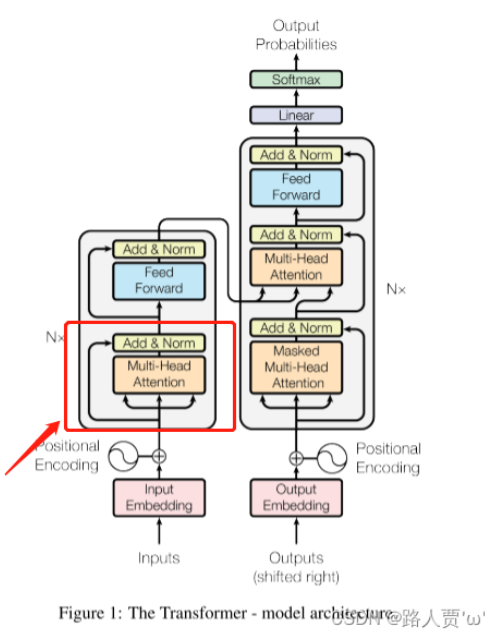
(2)Decoder 的注意力层: 这个注意力层就不是自注意力了,其中 K 和 V 来自 Encoder的输出,Q来自掩码多头注意力输出。
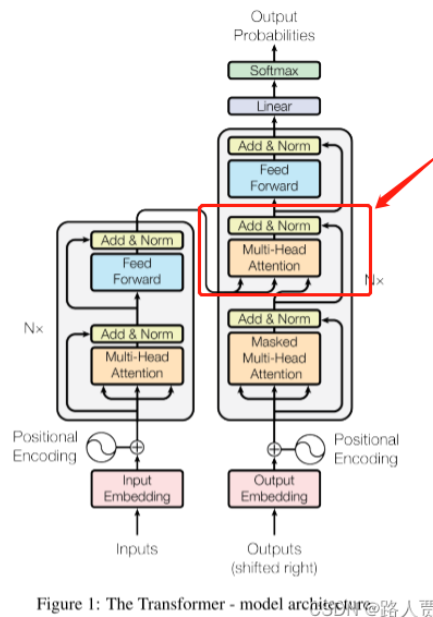
(3)Decoder 的掩码注意力层: 掩码注意力层就是将t时刻后的数据权重设置为 0,该层还是自注意力的。
6.4.6 Position-wise Feed-Forward Networks—基于位置的前馈神经网络
除了attention子层,我们encoder-decoder框架中每一层都包含一个全连接的前馈网络,它分别相同地应用于每个位置。它由两个线性变换和中间的一个ReLU激活函数组成
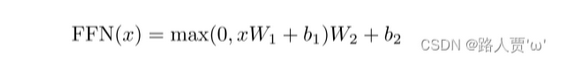
6.4.7 Embeddings and Softmax —词嵌入和 softmax
Embedding: 特征嵌入,embedding是可以简单理解为通过某种方式将词向量化,即输入一个词输出该词对应的一个向量。(embedding可以采用训练好的模型如GLOVE等进行处理,也可以直接利用深度学习模型直接学习一个embedding层,Transformer模型的embedding方式是第二种,即自己去学习的一个embedding层。)
本文方法
embeddings将输入和输出tokens转换为向量,线性变换和softmax函数将decoder输出转换为预测的写一个token概率。
6.5.8 Positional Encoding——(用于确定单词的位置)
原因
transformer模型不包含循环或卷积,输出是V的加权和(权重是 Q与K的相似度,与序列信息无关),对于任意的K-V,将其打乱后,经过注意力机制的结果都一样,他无法确定顺序。
但是它顺序变化而值不变,在处理时序数据的时候,一个序列如果完全被打乱,那么语义肯定发生改变,而注意力机制却不会处理这种情况。
方法
在注意力机制的输入中加入时序信息,位置在encoder端和decoder端的embedding之后,用于补充Attention机制本身不能捕捉位置信息的缺陷,我们把这个模块成为位置编码。
后面躺平了 放弃了

















 2211
2211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









