







- 学习:知识的初次邂逅
- 复习:知识的温故知新
- 练习:知识的实践应用
一,原题力扣链接
二,题干
表:
Activity+--------------+---------+ | Column Name | Type | +--------------+---------+ | player_id | int | | device_id | int | | event_date | date | | games_played | int | +--------------+---------+ (player_id,event_date)是此表的主键(具有唯一值的列的组合) 这张表显示了某些游戏的玩家的活动情况 每一行表示一个玩家的记录,在某一天使用某个设备注销之前,登录并玩了很多游戏(可能是 0)玩家的 安装日期 定义为该玩家的第一个登录日。
我们将日期 x 的 第一天留存率 定义为:假定安装日期为
X的玩家的数量为N,其中在X之后的一天重新登录的玩家数量为M,M/N就是第一天留存率,四舍五入到小数点后两位。编写解决方案,报告所有安装日期、当天安装游戏的玩家数量和玩家的 第一天留存率。
以 任意顺序 返回结果表。
结果格式如下所示。
示例 1:
输入: Activity 表: +-----------+-----------+------------+--------------+ | player_id | device_id | event_date | games_played | +-----------+-----------+------------+--------------+ | 1 | 2 | 2016-03-01 | 5 | | 1 | 2 | 2016-03-02 | 6 | | 2 | 3 | 2017-06-25 | 1 | | 3 | 1 | 2016-03-01 | 0 | | 3 | 4 | 2016-07-03 | 5 | +-----------+-----------+------------+--------------+ 输出: +------------+----------+----------------+ | install_dt | installs | Day1_retention | +------------+----------+----------------+ | 2016-03-01 | 2 | 0.50 | | 2017-06-25 | 1 | 0.00 | +------------+----------+----------------+ 解释: 玩家 1 和 3 在 2016-03-01 安装了游戏,但只有玩家 1 在 2016-03-02 重新登录,所以 2016-03-01 的第一天留存率是 1/2=0.50 玩家 2 在 2017-06-25 安装了游戏,但在 2017-06-26 没有重新登录,因此 2017-06-25 的第一天留存率为 0/1=0.00
三,建表语句
import pandas as pd
data = [[1, 2, '2016-03-01', 5], [1, 2, '2016-03-02', 6], [2, 3, '2017-06-25', 1], [3, 1, '2016-03-01', 0], [3, 4, '2018-07-03', 5]]
activity = pd.DataFrame(data, columns=['player_id', 'device_id', 'event_date', 'games_played']).astype({'player_id':'Int64', 'device_id':'Int64', 'event_date':'datetime64[ns]', 'games_played':'Int64'})
四,分析
t0:其实也需要考虑去重; 去除掉同一天 用一个用户,同一个设备重复登陆的行数;第一步:计算用户首次登陆日期;第二步:打标:日过首次登陆日期 == 用户登录日期 给他打上标记:他为首次登陆的人;第三步:打标:如果次日登陆日期==用户登录日期 给他打上标记: 他为次日登陆的人; -- ps: 这里的次日登陆的人 其实是首次登陆又次日登陆的人,而非新增的人; --如果是新增的用户,那么他的登陆日期== 首日登陆日期; 除非他第二天又登陆了,否则他就不会等于第二天的登陆日期;第四步:计算首日活跃用户数量;第五步:计算次日活跃用户数量; -- ps 这里的次日活跃用户 === 昨天有登陆的,且今天也登陆了的用户;第六步:合并两个表;第七步:对nan和nat值处理 转为0;第八步:计算留存率 引入np包 处理精度问题 解决四舍五入的问题;第九步:映射指定的列,改名,并且输出



pandas代码实现上述表格的逻辑
t0:其实也需要考虑去重; 去除掉同一天 用一个用户,同一个设备重复登陆的行数;

第一步:计算用户首次登陆日期;

第二步:打标:日过首次登陆日期 == 用户登录日期 给他打上标记:他为首次登陆的人;

第三步:打标:如果次日登陆日期==用户登录日期 给他打上标记: 他为次日登陆的人;

-- ps: 这里的次日登陆的人 其实是首次登陆又次日登陆的人,而非新增的人; --如果是新增的用户,那么他的登陆日期== 首日登陆日期; 除非他第二天又登陆了,否则他就不会等于第二天的登陆日期; 第四步:计算首日活跃用户数量;

第五步:计算次日活跃用户数量; -- ps 这里的次日活跃用户 === 昨天有登陆的,且今天也登陆了的用户;

第六步:合并两个表;

第七步:对nan和nat值处理 转为0;
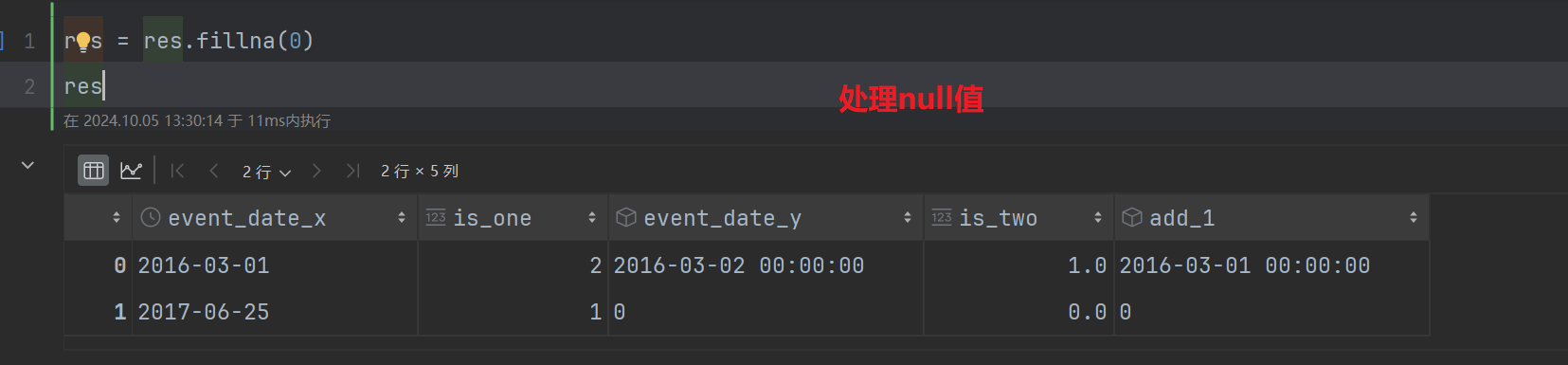
第八步:计算留存率 引入np包 处理精度问题 解决四舍五入的问题;

第九步:映射指定的列,改名,并且输出

五,Pandas解答
import pandas as pd
def gameplay_analysis(activity: pd.DataFrame) -> pd.DataFrame:
#去重:
activity = activity[['player_id','device_id','event_date']].drop_duplicates()
# 计算用户首次登陆日期
activity['min_date'] = activity.groupby('player_id')['event_date'].transform('min')
#如果用户登录日期=首次登陆日期 打上一个标签 首次登陆
activity['is_one'] = activity.apply(lambda x : '首次登陆' if x['event_date'] == x['min_date'] else None,axis=1)
activity['is_two'] = activity.apply(lambda x : '第二天重复登陆' if x['event_date'] == x['min_date']+ pd.Timedelta(days = 1) else None,axis=1)
# 统计第一天登陆的人数
df1 = activity[activity['is_one'] =='首次登陆']
df2 = df1.groupby('event_date')['is_one'].count().reset_index()
#统计第二天登陆的人数
df3 = activity[activity['is_two'] == '第二天重复登陆']
df4 = df3.groupby('event_date')['is_two'].count().reset_index()
df4['add_1'] =df4['event_date']- pd.Timedelta(days = 1)
# 左连接两个表
res = pd.merge(df2,df4,how='left',left_on='event_date',right_on='add_1')
def custom_round(x):
from decimal import Decimal, ROUND_HALF_UP
num = Decimal(str(x))
return float(num.quantize(Decimal('0.01'), rounding = ROUND_HALF_UP))
res['ciri_liucun'] = res.apply(lambda row: custom_round(row['is_two'] / row['is_one']) if row['is_one']!= 0 else 0, axis = 1)
#映射对应的列
res1 = res[['event_date_x','is_one','ciri_liucun']]
#改名
res1.columns = ['install_dt','installs','Day1_retention']
#输出
return res1.fillna(0)
gameplay_analysis(activity)
六,验证

七,知识点总结

- 留存率计算:
- 次日登陆+首日登陆 = 留存用户
- 第二日留存用户的数量/第一天用户的数量 得到留存率;
- Pandas中去重API的运用 drop_duplicates
- Pandas中 开窗函数的运用 transform
- Pandas中自定义函数的运用 apply
- Pandas中条件过滤的运用
- Pandas中分组聚合的运用
- Pandas中重置索引的㛚 reset_index
- Pandas中左连接的运用 merge
- Pandas中 解决精度问题,消除四舍五入带来的精度损失的运用
- Pandas中处理null值的运用
- Python中匿名函数的运用
- python中三目表达式的运用
- python中函数的运用
- 学习:知识的初次邂逅
- 复习:知识的温故知新
- 练习:知识的实践应用
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









