







- 学习:知识的初次邂逅
- 复习:知识的温故知新
- 练习:知识的实践应用
目录
一,原题力扣链接
二,题干
表:
Users+----------------+---------+ | Column Name | Type | +----------------+---------+ | user_id | int | | join_date | date | | favorite_brand | varchar | +----------------+---------+ user_id 是该表的主键(具有唯一值的列)。 表中包含一位在线购物网站用户的个人信息,用户可以在该网站出售和购买商品。表:
Orders+---------------+---------+ | Column Name | Type | +---------------+---------+ | order_id | int | | order_date | date | | item_id | int | | buyer_id | int | | seller_id | int | +---------------+---------+ order_id 是该表的主键(具有唯一值的列)。 item_id 是 Items 表的外键(reference 列)。 buyer_id 和 seller_id 是 Users 表的外键。表:
Items+---------------+---------+ | Column Name | Type | +---------------+---------+ | item_id | int | | item_brand | varchar | +---------------+---------+ item_id 是该表的主键(具有唯一值的列)。编写一个解决方案,为每个用户找出他们出售的第二件商品(按日期)的品牌是否是他们最喜欢的品牌。如果用户售出的商品少于两件,则该用户的结果为否。保证卖家不会在一天内卖出一件以上的商品。
以 任意顺序 返回结果表。
返回结果格式如下例所示:
示例 1:
输入: Users table: +---------+------------+----------------+ | user_id | join_date | favorite_brand | +---------+------------+----------------+ | 1 | 2019-01-01 | Lenovo | | 2 | 2019-02-09 | Samsung | | 3 | 2019-01-19 | LG | | 4 | 2019-05-21 | HP | +---------+------------+----------------+ Orders table: +----------+------------+---------+----------+-----------+ | order_id | order_date | item_id | buyer_id | seller_id | +----------+------------+---------+----------+-----------+ | 1 | 2019-08-01 | 4 | 1 | 2 | | 2 | 2019-08-02 | 2 | 1 | 3 | | 3 | 2019-08-03 | 3 | 2 | 3 | | 4 | 2019-08-04 | 1 | 4 | 2 | | 5 | 2019-08-04 | 1 | 3 | 4 | | 6 | 2019-08-05 | 2 | 2 | 4 | +----------+------------+---------+----------+-----------+ Items table: +---------+------------+ | item_id | item_brand | +---------+------------+ | 1 | Samsung | | 2 | Lenovo | | 3 | LG | | 4 | HP | +---------+------------+ 输出: +-----------+--------------------+ | seller_id | 2nd_item_fav_brand | +-----------+--------------------+ | 1 | no | | 2 | yes | | 3 | yes | | 4 | no | +-----------+--------------------+ 解释: id 为 1 的用户的查询结果是 no,因为他什么也没有卖出 id为 2 和 3 的用户的查询结果是 yes,因为他们卖出的第二件商品的品牌是他们最喜爱的品牌 id为 4 的用户的查询结果是 no,因为他卖出的第二件商品的品牌不是他最喜爱的品牌
三,建表语句
import pandas as pd
data = [[1, '2019-01-01', 'Lenovo'], [2, '2019-02-09', 'Samsung'], [3, '2019-01-19', 'LG'], [4, '2019-05-21', 'HP']]
users = pd.DataFrame(data, columns=['user_id', 'join_date', 'favorite_brand']).astype({'user_id':'Int64', 'join_date':'datetime64[ns]', 'favorite_brand':'object'})
data = [[1, '2019-08-01', 4, 1, 2], [2, '2019-08-02', 2, 1, 3], [3, '2019-08-03', 3, 2, 3], [4, '2019-08-04', 1, 4, 2], [5, '2019-08-04', 1, 3, 4], [6, '2019-08-05', 2, 2, 4]]
orders = pd.DataFrame(data, columns=['order_id', 'order_date', 'item_id', 'buyer_id', 'seller_id']).astype({'order_id':'Int64', 'order_date':'datetime64[ns]', 'item_id':'Int64', 'buyer_id':'Int64', 'seller_id':'Int64'})
data = [[1, 'Samsung'], [2, 'Lenovo'], [3, 'LG'], [4, 'HP']]
items = pd.DataFrame(data, columns=['item_id', 'item_brand']).astype({'item_id':'Int64', 'item_brand':'object'})四,分析
思路
表格大法:
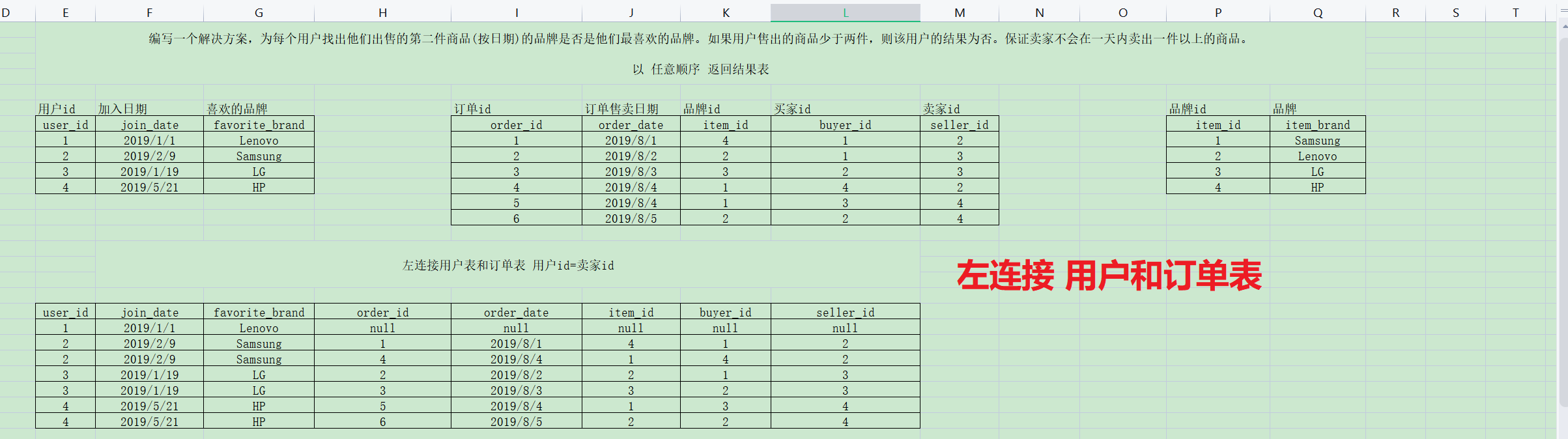
第一步:左连接用户表和订单表 左连接的原因:有用户但是用户每下单也需要统计; 连接条件:用户id和卖家id
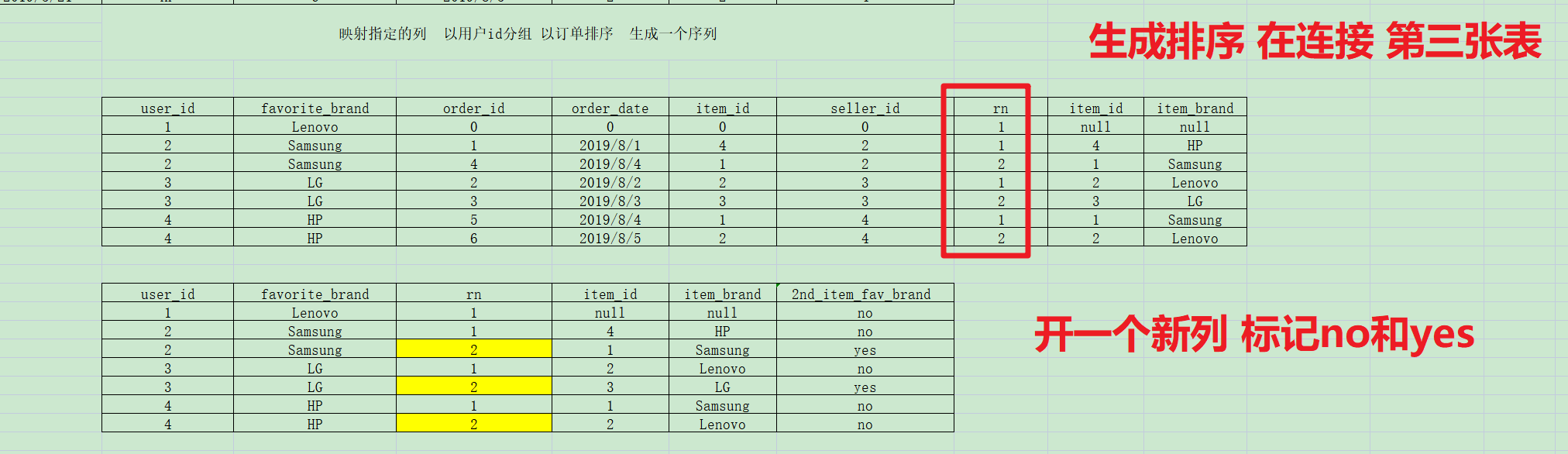
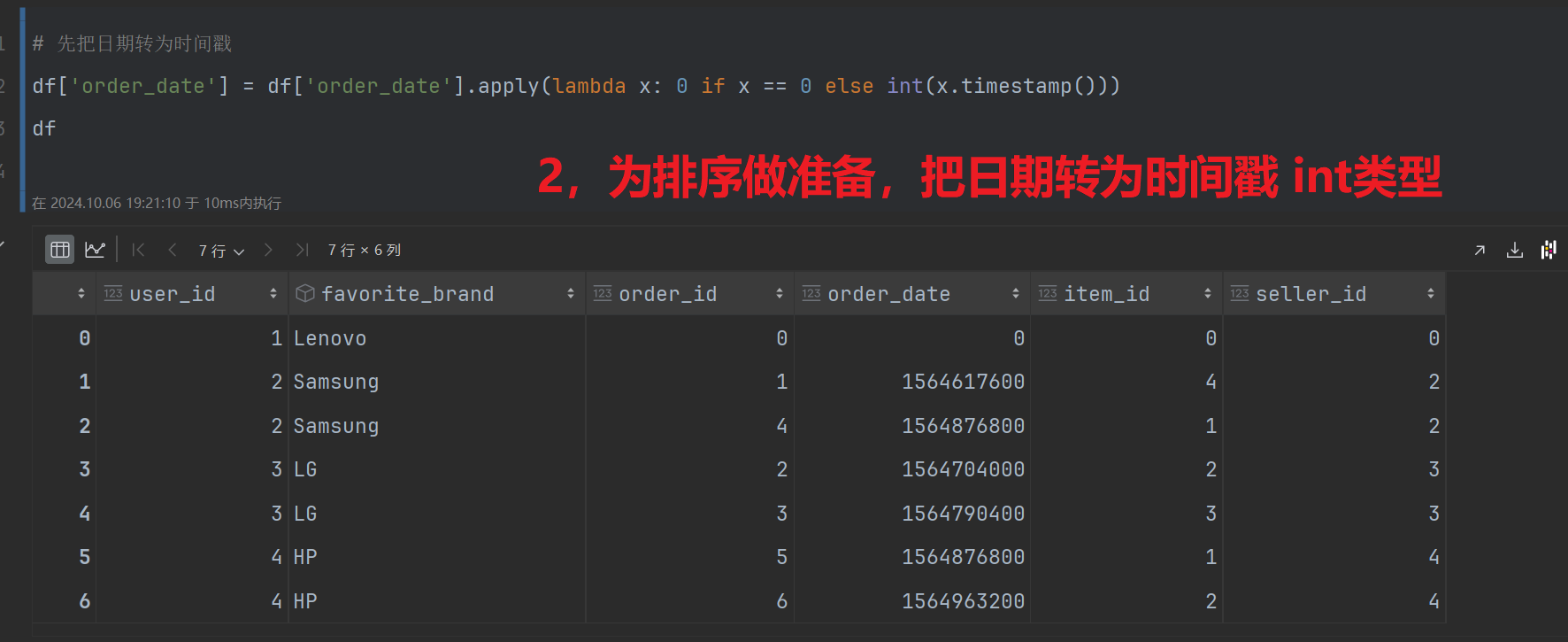
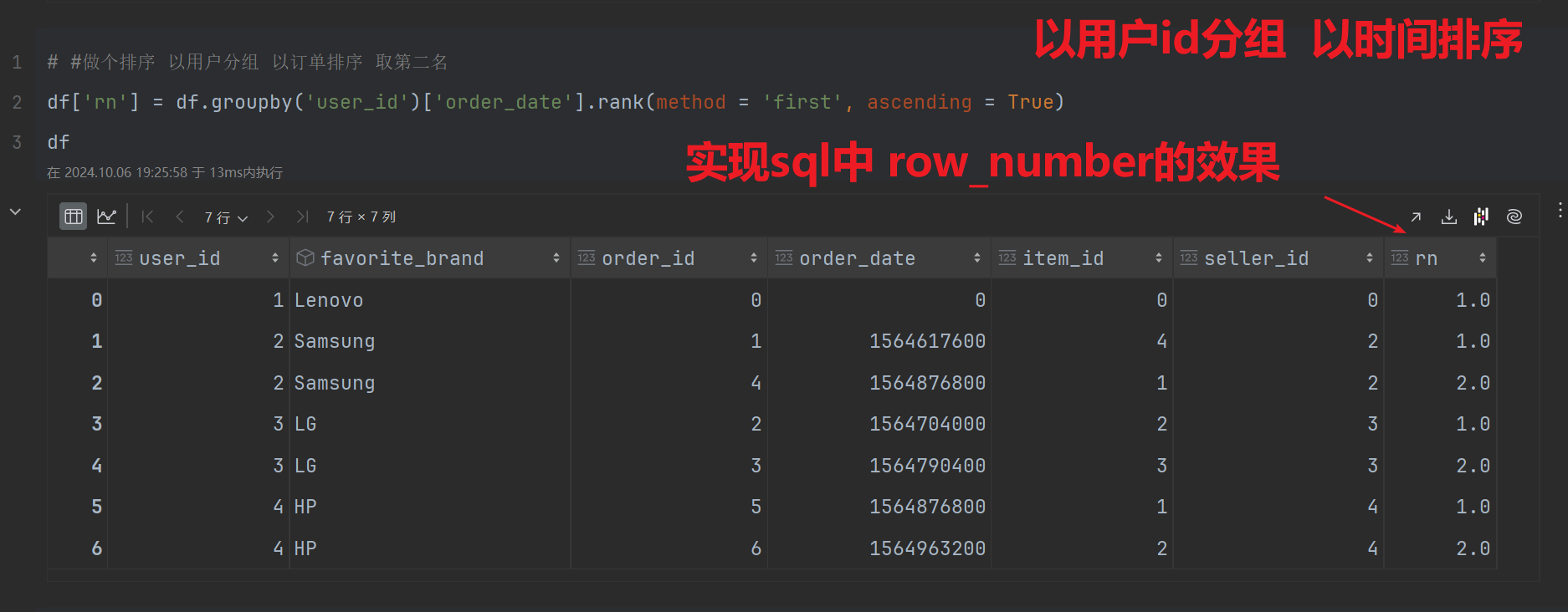
第二步:以用户分组,以下单日期排序 pandas中需要转为时间戳 msql不需要;
第三步:左连接连接第三张表 品牌表。左连接的原因是:item_id有null值的原因
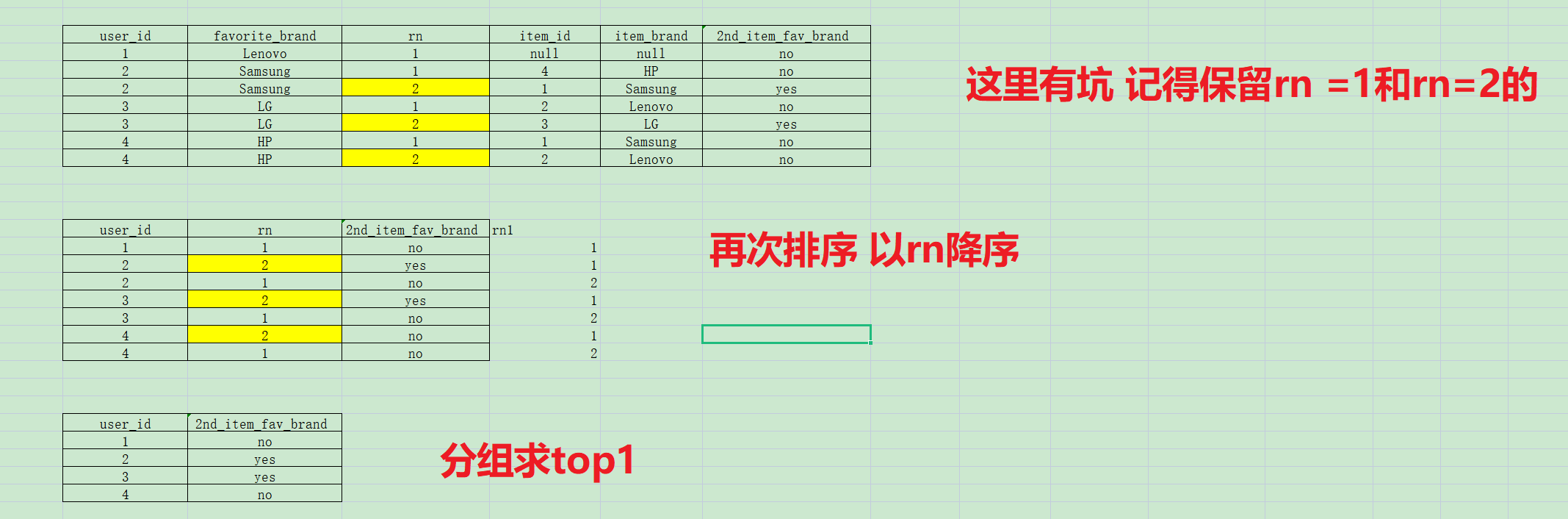
第四步:过滤掉大于排序列2的行数 并且扩一个新的列,如果rn=2且用户出售的品牌是他们喜欢的品牌 就给yes,反之都都给no
第五步:再次排序 以rn降序,分组求top1
第六步:映射指定的列,改名,并输出
解题过程
分别用mysql和pandas实现以上表格的代码逻辑
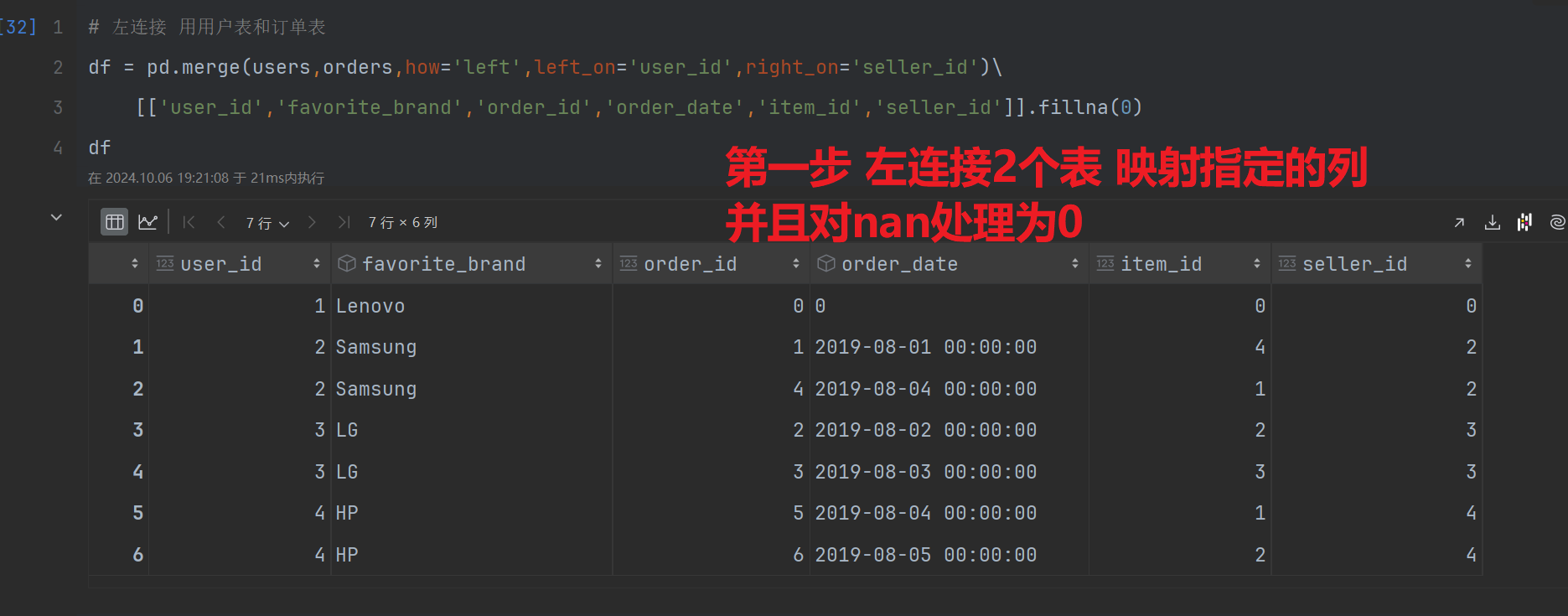
第一步:左连接用户表和订单表 左连接的原因:有用户但是用户每下单也需要统计; 连接条件:用户id和卖家id
在pandas
第二步:以用户分组,以下单日期排序 pandas中需要转为时间戳 msql不需要;
在pandas
第三步:左连接连接第三张表 品牌表。左连接的原因是:item_id有null值的原因
在pandas

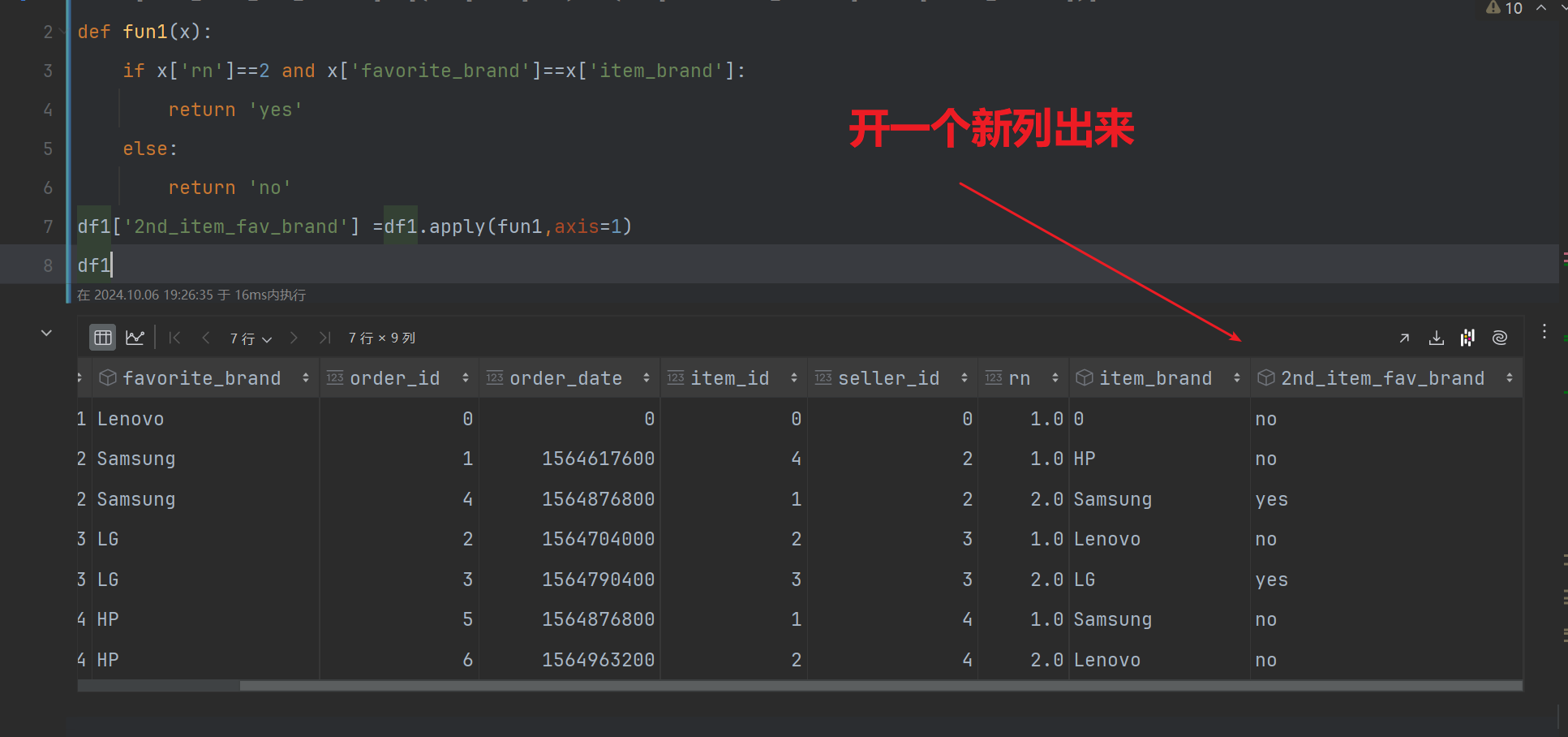
第四步:过滤掉大于排序列2的行数 并且扩一个新的列,如果rn=2且用户出售的品牌是他们喜欢的品牌 就给yes,反之都都给no
在pandas
第五步:再次排序 以rn降序,分组求top1
在pandas
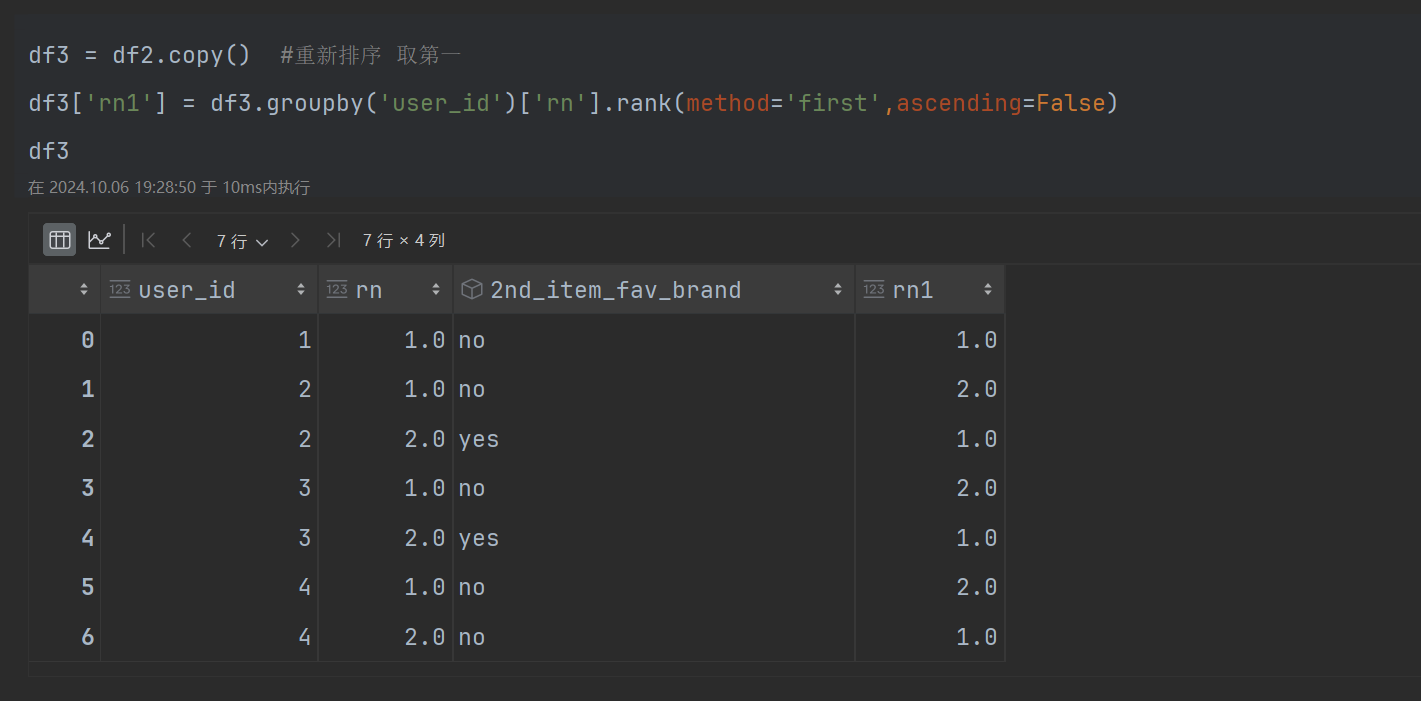
第六步:映射指定的列,改名,并输出
在pandas
五,Pandas解答
import pandas as pd
def market_analysis(users: pd.DataFrame, orders: pd.DataFrame, items: pd.DataFrame) -> pd.DataFrame:
# 左连接 用用户表和订单表
df = pd.merge(users,orders,how='left',left_on='user_id',right_on='seller_id')\
[['user_id','favorite_brand','order_id','order_date','item_id','seller_id']].fillna(0)
# 先把日期转为时间戳
df['order_date'] = df['order_date'].apply(lambda x: 0 if x == 0 else int(x.timestamp()))
# #做个排序 以用户分组 以订单排序 取第二名
df['rn'] = df.groupby('user_id')['order_date'].rank(method = 'first', ascending = True)
# 连接第三张表 nan值处理为0
df1 = pd.merge(df,items,how='left',on='item_id').fillna(0)
#保留 第一和第二 其他都不要 因为一会儿还要降序排序
df1=df1[df1['rn']<=2]
def fun1(x):
if x['rn']==2 and x['favorite_brand']==x['item_brand']:
return 'yes'
else:
return 'no'
df1['2nd_item_fav_brand'] =df1.apply(fun1,axis=1)
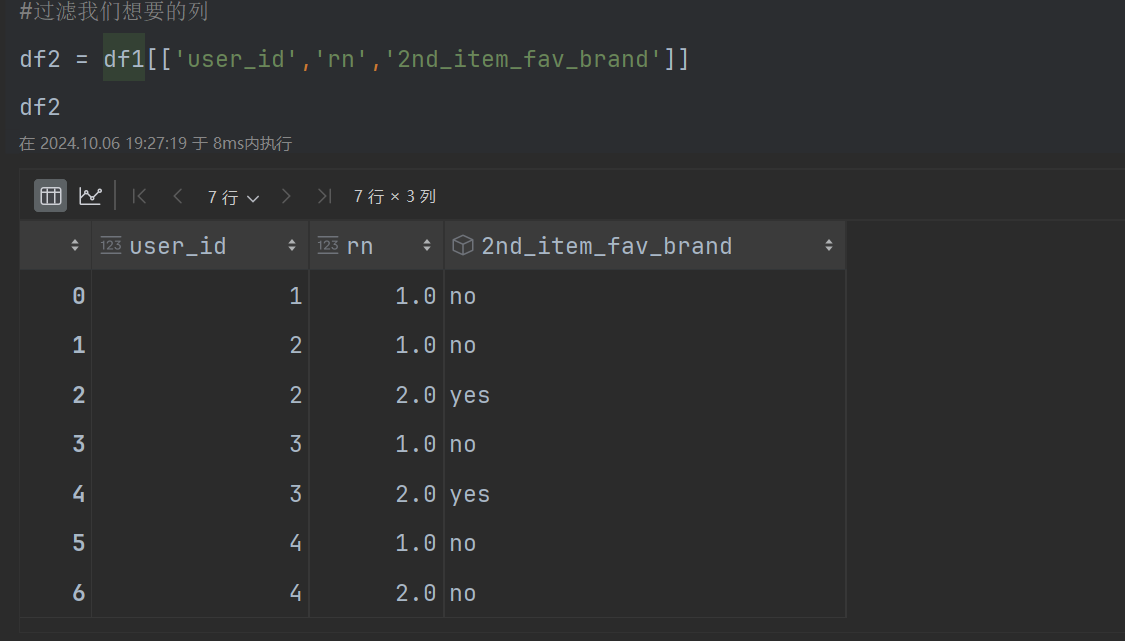
#过滤我们想要的列
df2 = df1[['user_id','rn','2nd_item_fav_brand']]
df3 = df2.copy() #重新排序 取第一
df3['rn1'] = df3.groupby('user_id')['rn'].rank(method='first',ascending=False)
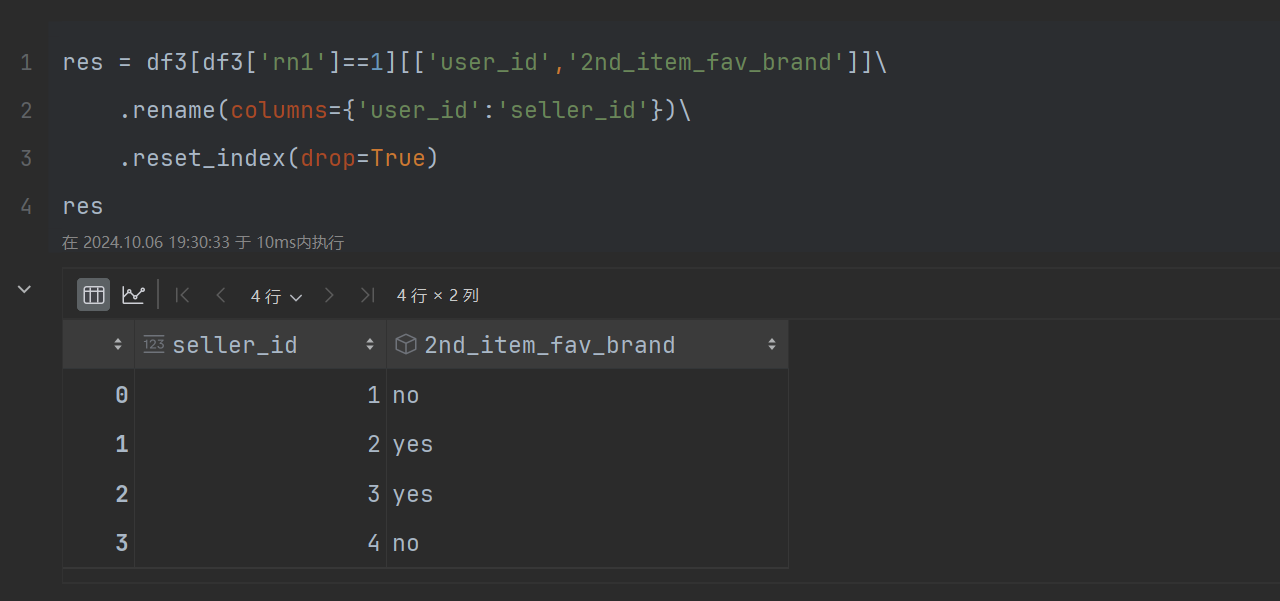
res = df3[df3['rn1']==1][['user_id','2nd_item_fav_brand']]\
.rename(columns={'user_id':'seller_id'})\
.reset_index(drop=True)
return res
market_analysis(users,orders,items)六,验证

七,知识点总结
- Pandas中左连接的运用 merge
- Pandas中对nan值的处理 fillnan(0)
- Pandas中自定义行数的运用
- Pandas中 对时间转为时间戳的运用 timstamp()
- Pandas中 实现row_number的效果的运用 groupby...rank
- Pandas中 自定义行数的运用 apply axis=1是行
- Pandas中 实现排序的运用 method等于的值 的综合运用
- Pandas中 重置索引的运用 reset_index
- Pandas中 改名的运用 columns
- Pandas汇总 链式调用换行的运用
- Python中匿名函数的运用
- Python中函数的运用
- Python中选择分支的运用
附录:
rank方法中的method参数取值及含义
average(默认值)
- 含义:当存在相同值时,将相同值的排名设为这些值的平均排名。
- 例如:如果有一组数据
[1, 2, 2, 3],对于值2,会有两个相同的值。它们的排名会被计算为平均排名,即(2 + 3)/2= 2.5,所以这组数据的排名结果为[1, 2.5, 2.5, 4]。min
- 含义:当存在相同值时,将相同值的排名设为这些相同值可能的最小排名。
- 例如:对于数据
[1, 2, 2, 3],值2的排名为2(而不是平均排名2.5),所以这组数据的排名结果为[1, 2, 2, 4]。max
- 含义:当存在相同值时,将相同值的排名设为这些相同值可能的最大排名。
- 例如:对于数据
[1, 2, 2, 3],值2的排名为3,这组数据的排名结果为[1, 3, 3, 4]。first
- 含义:按照值在数据中的出现顺序排名。如果有相同值,先出现的值排名靠前。
- 例如:对于数据
[2, 1, 1, 3],第一个1的排名为2,第二个1的排名为3,这组数据的排名结果为[1, 2, 3, 4]。dense
- 含义:类似于
min,但排名是连续的,不会出现像average那样的小数排名。相同值共享同一个排名,下一个不同的值的排名是上一个排名加 1。- 例如:对于数据
[1, 2, 2, 3],值2的排名为2,这组数据的排名结果为[1, 2, 2, 3]。
- 学习:知识的初次邂逅
- 复习:知识的温故知新
- 练习:知识的实践应用















 619
619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









